






ComfyUI基本
这里使用的是秋叶大佬的整合包,有需要的可以去找找资源,网上有人有百度或者夸克的网盘链接。
将整合包安装好在本地的机器中后,直接点击文件里面的exe文件,就可以直接启动ComfyUI应用
下面我给出2025.的ComfyUI整合包(百度网盘的可以自行去网上查找)
2025.2.4 更新 v1.6: Python 3.11 Pytorch 2.5.1 ComfyUI 内核 v0.3.13 插件新增部分常用节点,删除大量无用/过时节点 总插件数量精简 28 -> 21
【下载链接】 网盘:夸克网盘分享 解压密码:bilibili-秋葉aaaki
【报错解决】 遇到报错请前往启动器的 “疑难解答” 页面进行扫描
【ComfyUI-aki-v1.6.7z】SHA1校验码:C70C920D545FE479BC416115657238CA2BA0F761
简介
节点式AI绘画工具
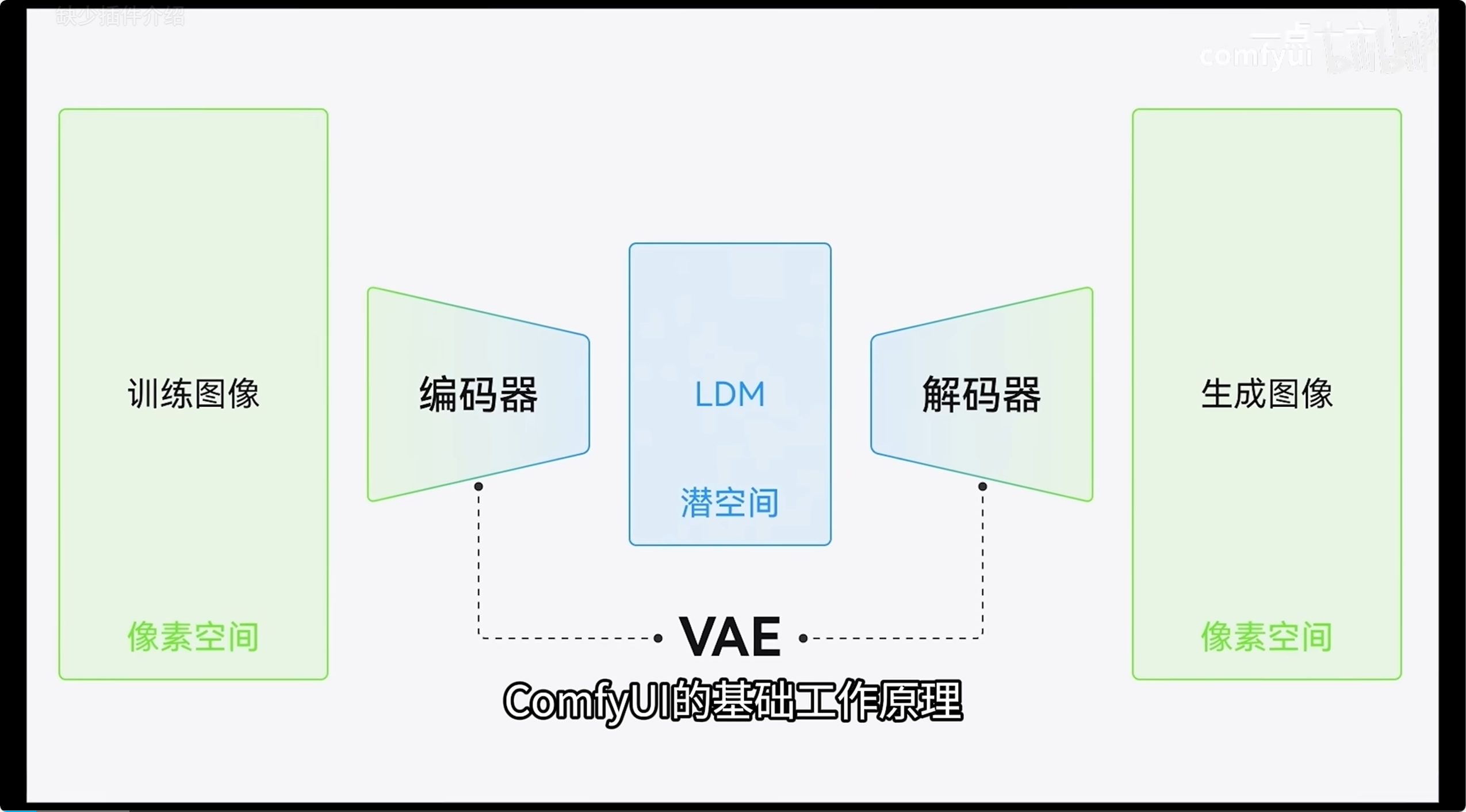
ComfyUI是基于Stable Diffusion的图形化界面工具,通过节点(Nodes)和工作流(Workflow)管理AI图像生成过程。用户通过连接不同功能的节点(如加载模型、编码提示词、采样解码等)构建定制化生成流程,实现高度灵活的控制
与Stable Diffusion WebUI的区别
-
灵活性:ComfyUI支持模块化设计,可自由组合节点,适合复杂创作需求;而WebUI界面固定,功能集成度高但可扩展性有限。
-
复现性:ComfyUI的工作流可保存为JSON文件,便于分享和批量生产;WebUI依赖手动配置,难以精确复现结果。
-
学习门槛:ComfyUI需理解Stable Diffusion底层原理(如潜空间、采样器),适合进阶用户;WebUI对新手更友好
关键技术与模型管理
-
模型类型与兼容性
-
主模型(Checkpoint):如SD1.5、SDXL,决定生成风格与质量。
-
LoRA:微调模型,用于特定特征(如人脸、画风)的调整。
-
VAE:图像解码器,影响色彩与细节表现。
-
ControlNet:控制图像结构(如姿势、线条),需与主模型版本匹配。
-
-
模型格式与安全
-
支持
.ckpt(PyTorch)、.safetensors(安全轻量格式)等,后者推荐用于最终部署
-
核心组成与工作流程
-
节点(Nodes) 每个节点代表一个功能模块,例如:
-
Load Checkpoint:加载Stable Diffusion基础模型(如SD1.5、SDXL)。
-
CLIP Text Encode:将文本提示词编码为向量,控制生成方向。
-
KSampler:核心采样器,通过反向扩散去噪生成潜空间图像。
-
VAE Decode:将潜空间数据解码为可见的像素图像。
-
-
工作流(Workflow)
-
通过连接节点的输入输出形成数据流,例如:
模型加载→提示词编码→采样→解码→保存。 -
支持复杂扩展,例如添加ControlNet(控制图像结构)、图生图、视频生成等节点
-
总结:ComfyUI通过节点式设计,将Stable Diffusion的生成过程透明化与模块化,兼顾灵活性与效率,适合追求深度定制和工业化生产的用户。其核心价值在于可复现的工作流与技术可控性,但需投入时间学习底层逻辑。未来随着社区生态完善,可能成为AI绘画领域的标准工具之一
文生图
先介绍一个简单的工作流(跟据提示信息生成对应的图片)
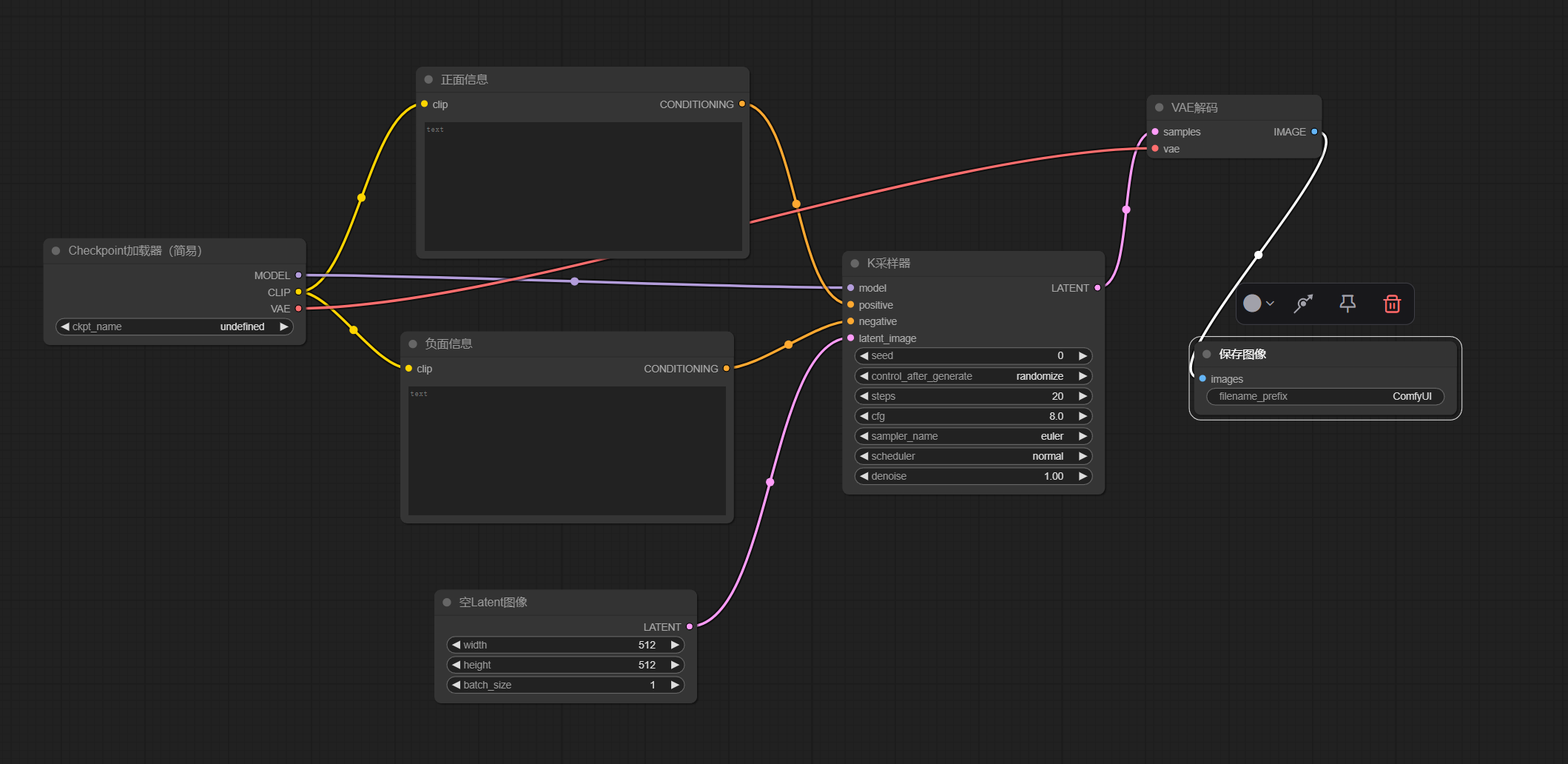
-
加载器:加载对应的大模型数据
-
文本编码器:输入正面或者负面信息提示词(正面信息就是对需要生成图片的正向条件,都会满足。负面信息则不会被满足)
-
空Latent;设置需要生成图片的长度宽度批次(一次性要生成几张)参数信息
-
K采样器:收集前面所定义的模型信息,正反面信息等为VAE解码做准备
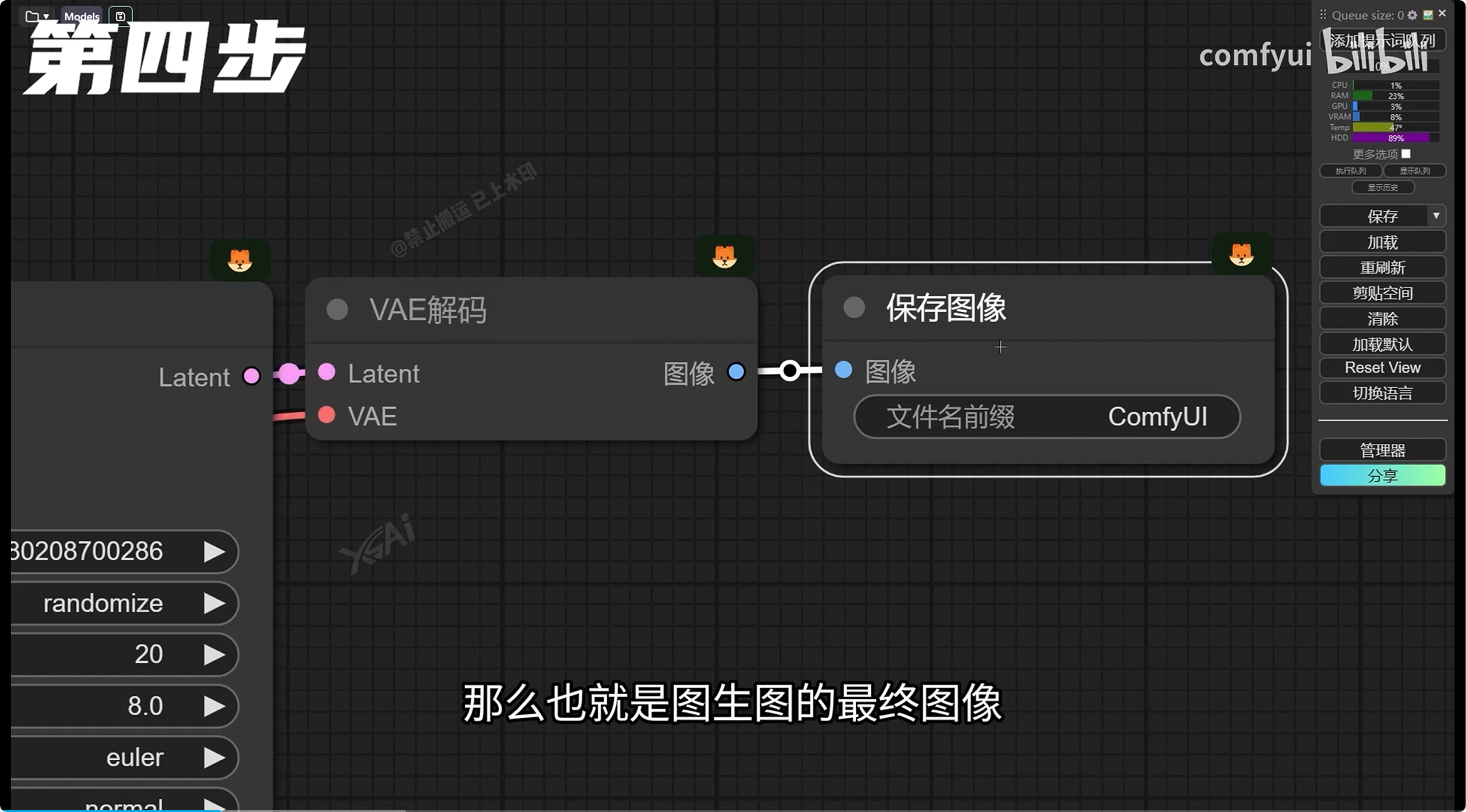
-
VAE解码:解析K采样器中的数据信息
-
图片保存:将生成的图片保存起来
提示词的权重
[]:代表0.9倍的权重 [[]]代表0.9*0.9=0.81倍的权重。以下同理
():代表1.1倍的权重
{}:代表1.05倍的权重
快捷键:
可以直接使用Ctrl+上键-----》提高权重
可以直接使用Ctrl+下键-----》降低权重
注意:权重可以设置很低的值,但是权重不可以过高,因为过高的权重容易导致生成的图片失真。

提示词的顺序也反映了权重的信息,越靠前的提示词权重就越大,同理越靠后面的提示词权重越小。下面给出提示词的书写顺序的建议:

短句与长句
在文本编辑器里面,虽然两种方式都可以对需要生成的图片进行描述,但是一般使用短句的形式(提示词)来进行描述,一般不使用长句。原因是:短句对图片的限制更加精确,长句则略显不足。以及在提示词的权重控制上短句更加具有优势。

注意:通过使用者的研究与测试,发现将提示词控制在75个以内是非常好的,因为这样通过提示词所生成的图片就更加精确,相反的是提示词超越75个后,可能会导致图片失真出现。
提示词污染
在使用一些提示词时可能会出现提示词的意思相互渗透的现象
解决方案:使用Break关键词将提示词分割开来

提示词融合
将两个提示词融合到一个事物的身上,条件是使用AND连接词或者使用_(下划线)链接。例如说:如果使用1girl,cat这两个提示词,那么工作流就会生成猫趴在女孩身上的图片。改成1girlANDcat,就会生成猫娘。

图生图
将图片与一组关键词同时作为输入,输出将会受到这一组关键词的共同调节
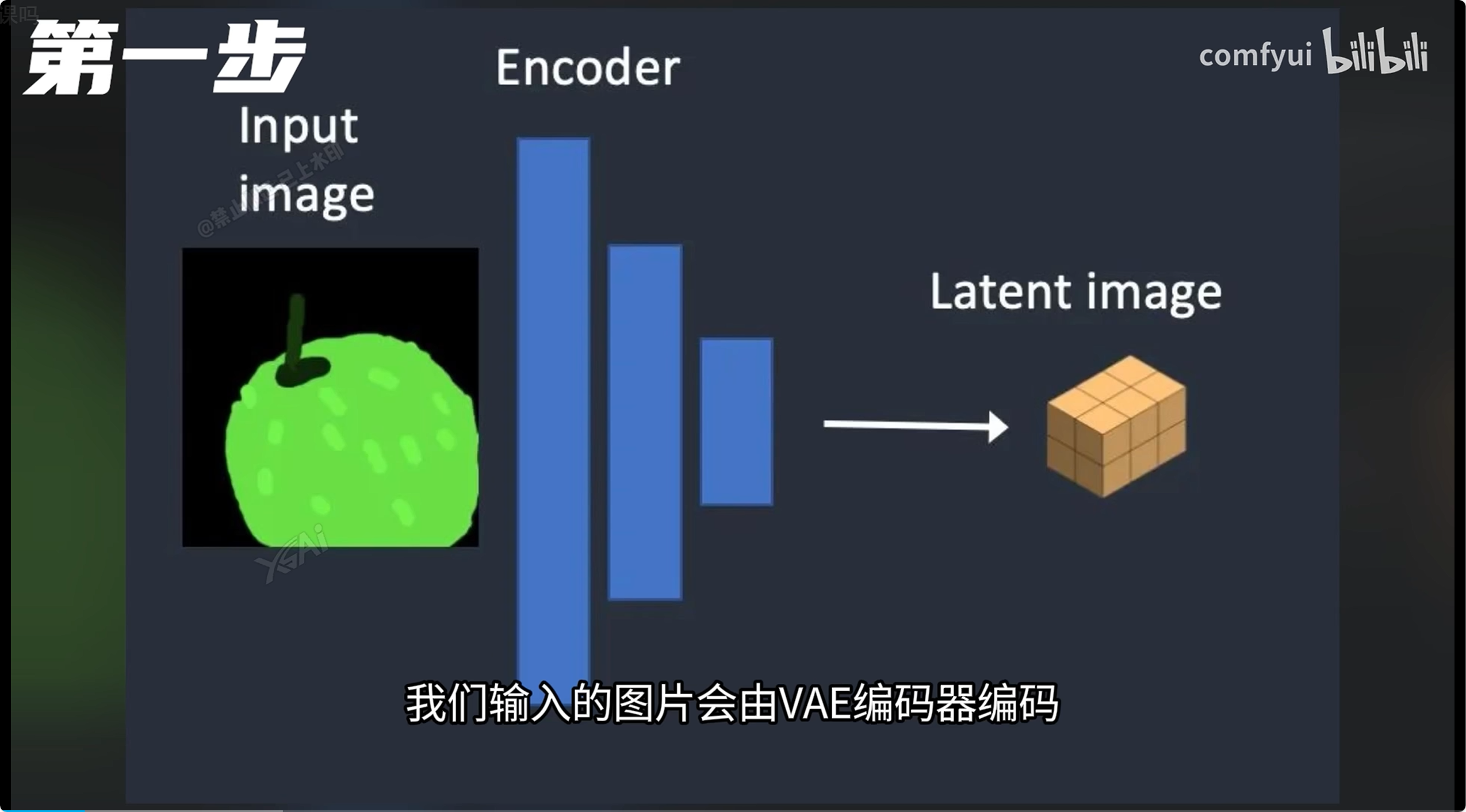
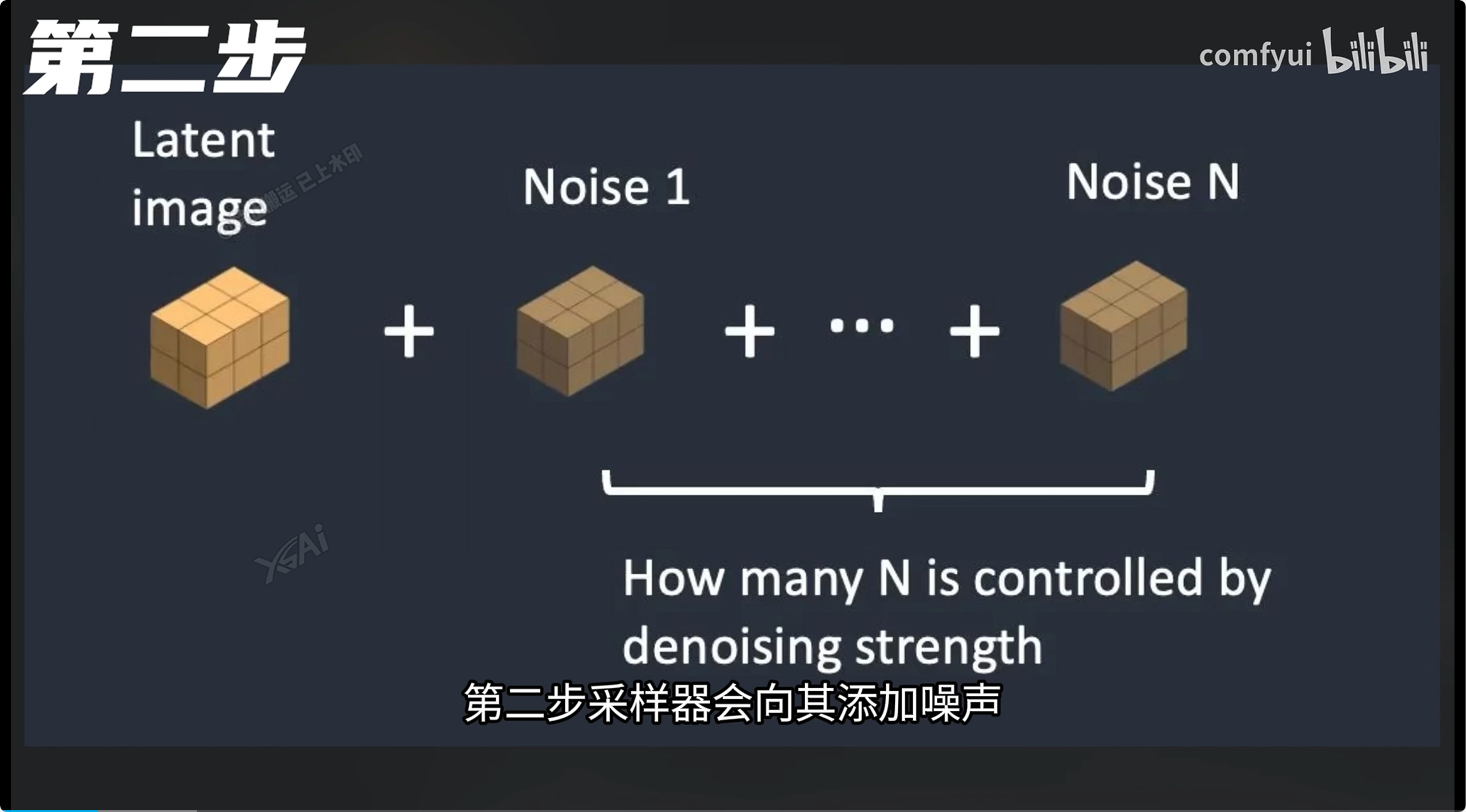
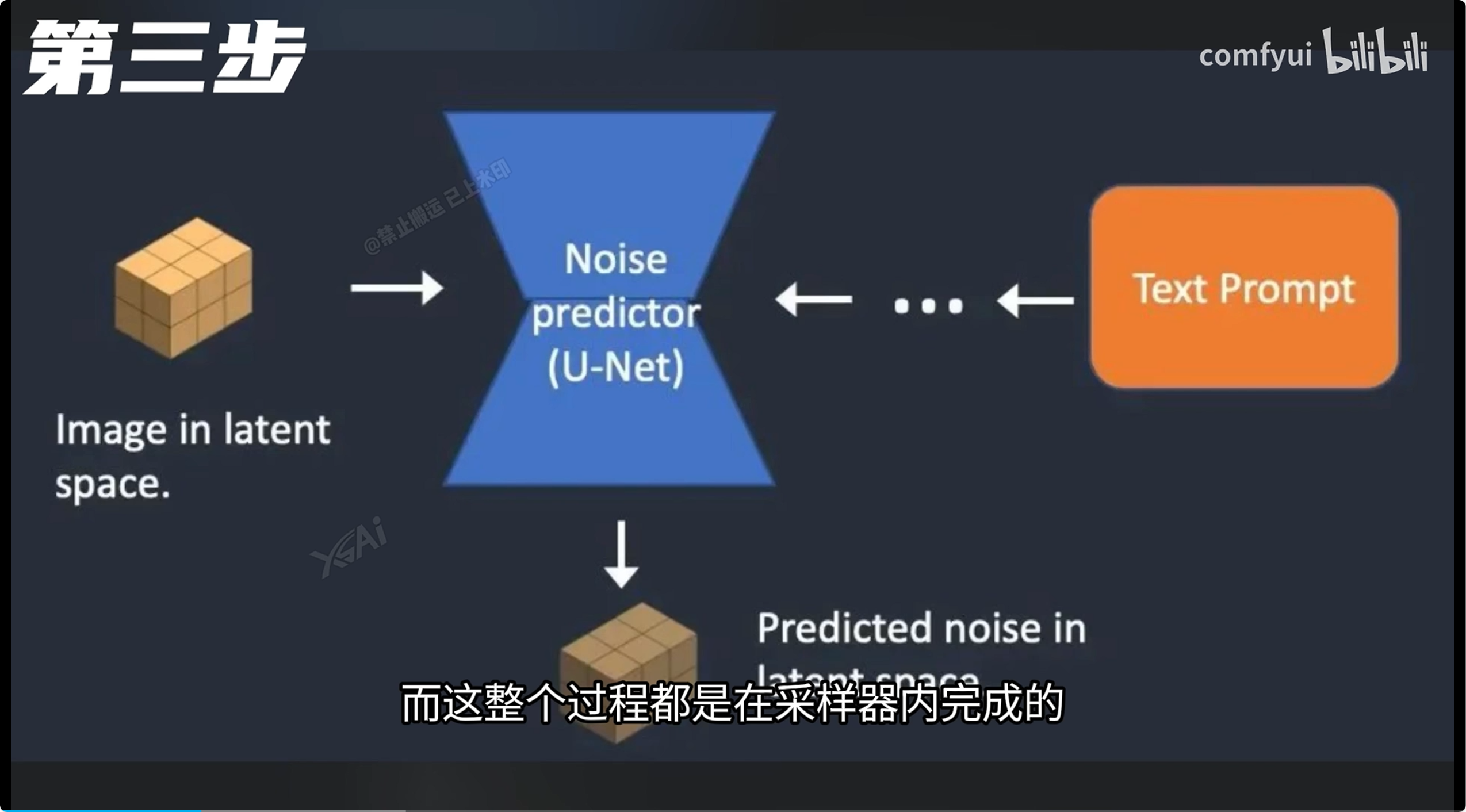
降噪 0.3~0.5:安全的重绘范围区间 0.5~0.7:赋予AI更多的想象与发挥空间 小于0.3:可能发生扭曲变形 大于0.7:可能发生扭曲变形
三重放大(提升图片的清晰度)

Controlnet
简介:ControlNet是一个用于图像生成控制的框架,通过不同的预处理方法来引导生成过程。
ControlNet 预处理模型
-
Canny
-
作用:通过检测图像中的强边缘生成清晰的轮廓(如物体边界、纹理)。
-
特点:边缘锐利,细节丰富,适合需要精准控制结构的场景(如建筑、机械设计)。
-
差异:预处理后图像为黑白线条图,保留高频细节,可能包含较多噪点。
-
-
SoftEdge
-
作用:提取柔和边缘,弱化细节噪点,保留整体结构。
-
特点:边缘过渡自然,减少锯齿感,适合生成柔和风格或需要自然过渡的图像(如人像、风景)。
-
差异:预处理图像线条较粗且模糊,类似铅笔素描,噪点较少。
-
-
Lineart
-
作用:生成简洁线稿,突出主体轮廓,忽略复杂纹理。
-
特点:线条干净利落,接近手绘线稿,适合艺术创作或动漫风格生成。
-
差异:预处理图像仅保留关键线条,细节简化,背景可能被省略。
-
总结差异
-
精细度:Canny > SoftEdge > Lineart
-
噪点:Canny 最多,Lineart 最少。
-
适用场景:
-
Canny:写实细节控制
-
SoftEdge:自然过渡需求
-
Lineart:艺术化线稿生成
-

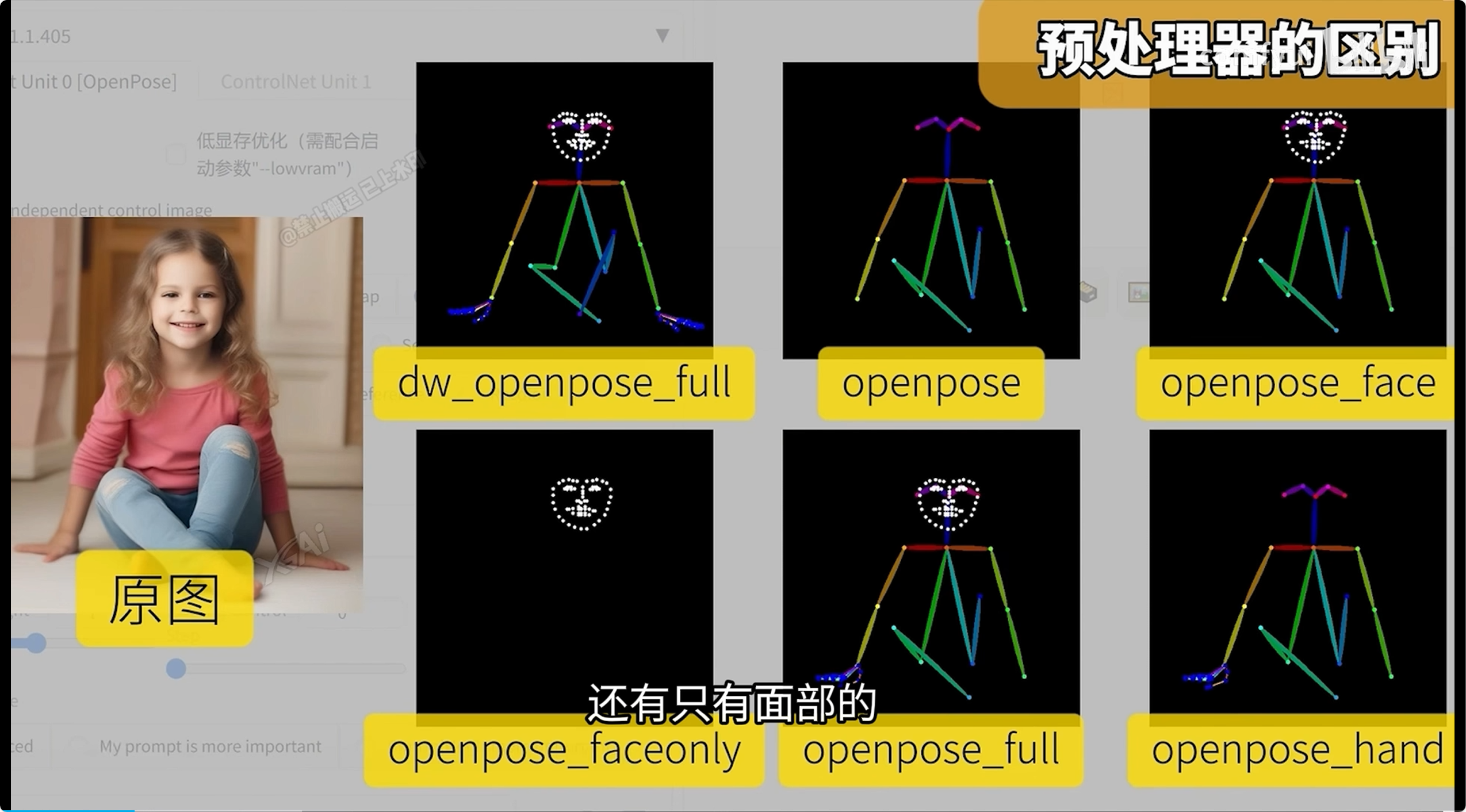
OpenPose
简介:识别图片中人物的身体姿态(如头部、四肢、关节位置),生成对应的骨架图。作用:
特点:
-
保留姿势结构,确保生成的新图像与原图动作一致。
-
支持多人检测,可同时处理多人物场景。
注意:与其他模型不同,OpenPose 不关注纹理或边缘,只专注于人体动作的“骨架”信息。
IPAdapter
简介:IPAdapter(Image Prompt Adapter)是 ComfyUI 的一个扩展插件,专为 图像驱动的 AI 生成控制 设计。它允许用户通过输入参考图像(如风格、构图或内容图)直接影响 Stable Diffusion 等模型的生成结果,实现更精准的图像控制,而无需复杂的参数调整。
核心功能
-
图像引导生成
-
通过输入参考图(如草图、风格图、实拍图),控制生成图像的 风格、构图、色调或细节。
-
示例:输入一张水彩画,生成相同风格的 AI 图像。
-
-
轻量级适配
-
相比 ControlNet,IPAdapter 模型体积更小(通常几百MB),对硬件要求更低,适合轻量化部署。
-
-
多模态控制
-
支持 文本+图像混合提示,结合文字描述和视觉参考,提升生成准确性。
-
示例:输入“森林中的城堡”+一张哥特式建筑草图,生成风格匹配的图像。
-
-
灵活的工作流集成
-
在 ComfyUI 中以节点形式接入,兼容其他插件(如 LoRA、ControlNet),支持复杂工作流设计。
-
作用:
-
人脸替换:IPAdapter 可以精确的识别参考图的面部特征,并引用该特征到结果图上
-
材质迁移:可以识别参考图的材质,并将参考图的材质运用到结果涂上
-
风格迁移:基于前两种功能的前提下,可以将参考图的风格迁移到结果图上
FLUX
FLUX 是 ComfyUI 中一个智能流程优化插件,能自动协调生成步骤、减少等待时间,让 AI 出图更快更流畅,尤其适合复杂工作流。
核心功能:
-
“红绿灯”调度: 自动安排生成任务的顺序,避免多个任务“堵车”,像交通信号灯一样让流程顺畅。
-
后台预加载: 提前准备下一步需要的模型和资源,减少卡顿(类似游戏加载时提前缓存地图)。
-
多任务并行: 边生成图片边处理其他任务(如放大、修复),不用干等每一步完成。
-
显存管家: 智能清理不再使用的临时数据,降低爆显存概率,尤其对低配显卡友好。
和 IPAdapter 的区别:
-
IPAdapter:用图片控制生成内容(比如“按这张画的风格画”)。
-
FLUX:不参与内容控制,专注提升整体生成效率(“让画画过程更快不卡顿”)。
有 FLUX:相同任务可能只需6-7分钟,显存波动更平稳
无 FLUX:复杂工作流可能需要10分钟,显存占用高

















 6801
6801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









