







目录
什么是内存接口 ?
我们可以从最直觉的问题入手:
❓ CPU 要处理数据,那它是怎么和内存沟通、传输数据的?
这就像人要和外界沟通,需要“语言”和“通道”,那么 CPU 也需要某种“协议”或“机制”来访问 memory(内存)。这个“语言和通道”就是:
Memory Interface(内存接口)——它是连接 CPU 和 Memory(内存)之间的通信桥梁。
它解决的本质问题是:
CPU 访问数据的速度 vs 内存响应的速度 严重不匹配,怎么办?
为什么需要特别设计“接口”?
我们可以回到最基础的现实限制:
| 组件 | 执行速度(Cycle) |
|---|---|
| CPU | 几 GHz(1 纳秒级) |
| Memory | 100 纳秒甚至更慢 |
于是你会发现:
❗ CPU 每执行一条指令,可能得等几十个时钟周期才能从内存中拿到数据!
那么问题来了:
怎么让 CPU 不至于“饿死在等待内存数据”时钟周期中?
这就是 Memory Interface(内存接口)设计的出发点。
什么是 MIPS?为什么它和内存接口有关?
我们先解释这个术语:
MIPS(Million Instructions Per Second)中文叫“每秒百万条指令数”,是衡量 CPU 执行速度的指标。
BUT❗ 注意:
MIPS 只反映 CPU 的潜力,不考虑它是否在等待内存!
所以现实中你可能看到:
CPU 有 2 GHz、理应执行 2 Billion 条指令/秒,但实际 MIPS 远低于理论值。
为什么?因为……
🔁 CPU 经常被 慢速 memory interface 拖慢了节奏。
这就说明:
内存接口的效率,直接影响 CPU 的真实性能表现(有效 MIPS)!
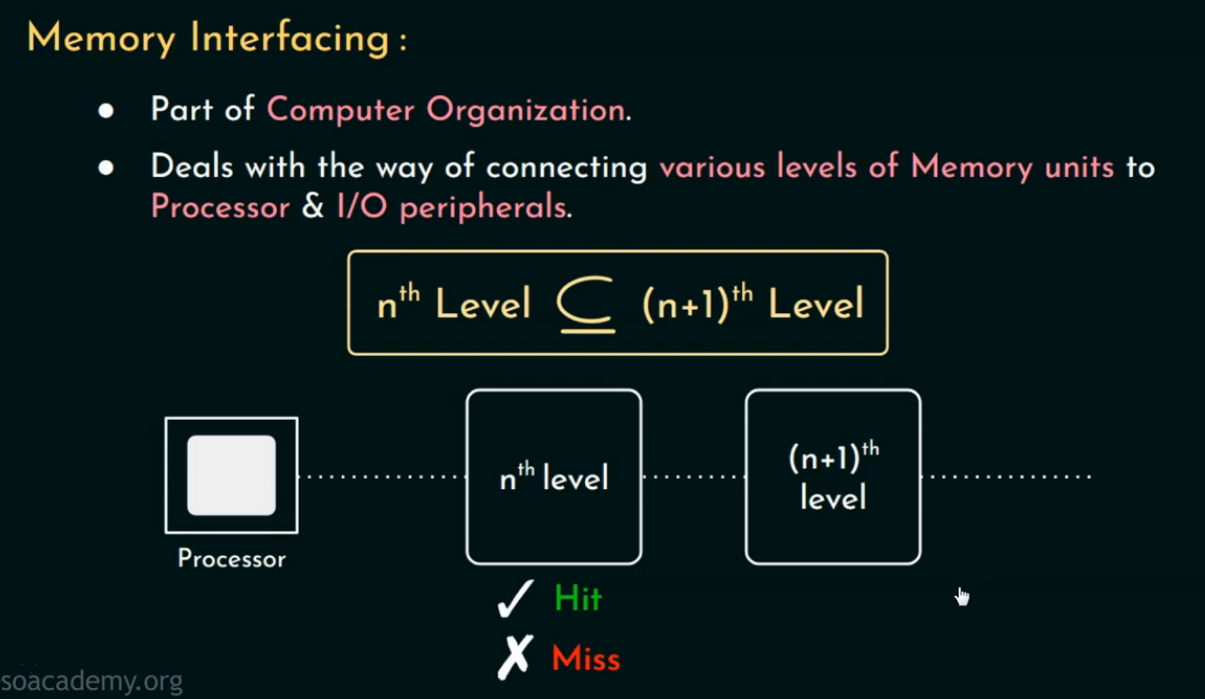
内存接口的两种访问方式
什么是 AMAT?
AMAT(Average Memory Access Time):平均内存访问时间,它是衡量 每一次访问内存时,CPU 平均等待的总时间。由于内存系统通常是多级的(multi-level memory hierarchy,多级内存层次结构),所以我们需要计算一个综合延迟。
这两种公式,其实对应了两种不同的层级访问策略(memory access strategy)
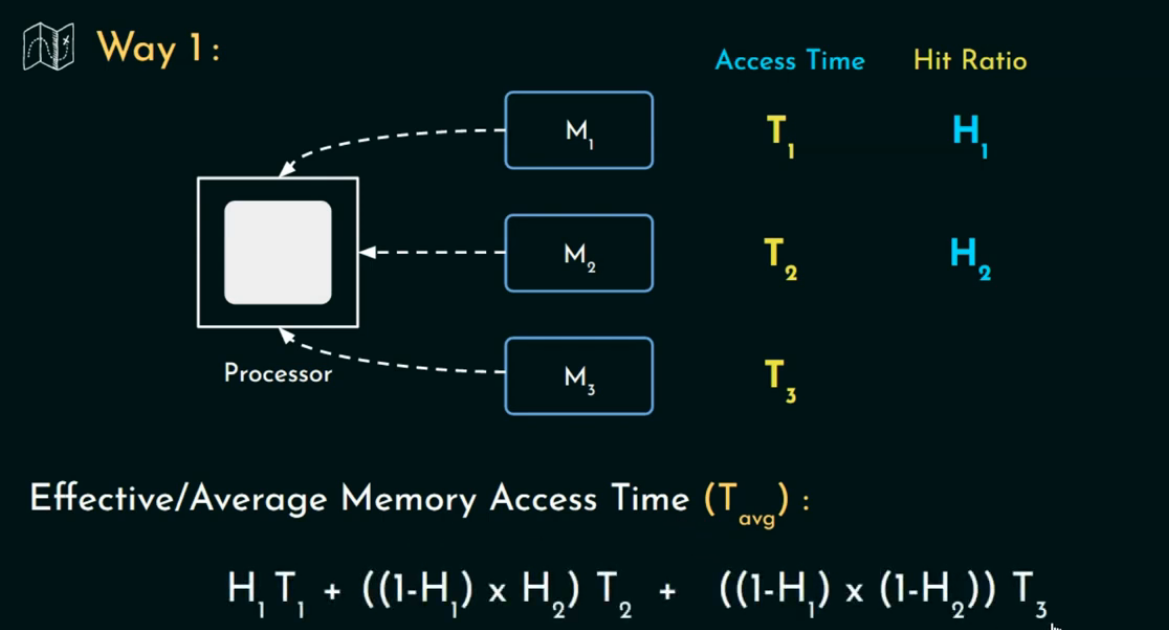
并行访问(Parallel Access Model)
在这个模型下:
-
所有层级同时开始访问(look-through),但只有命中最低层才使用它的数据。
-
每次你 miss 上一层,就会把前面“浪费掉的等待时间”也算上。
-
H1,H2:第1、2级缓存的命中率(hit rate)
-
T1,T2,T3:第1、2级缓存和主存的访问时间(access time)
注意这里每层访问时间是累加的,因为所有层是并发启动的,miss 时你还得等前面那几层“白白等的时间”。
通俗解释:
你像是在同时发送3个邮件请求给不同的图书管理员:
-
如果第一个管理员(L1)找到了,他最快回你;
-
如果他没找到,而第二个找到了,你要等 L1 的时间 + L2 的时间;
-
如果前两个都没找到,那你得等 L1 + L2 + 内存 的时间。
每一层你都等了一遍,结果可能还是没拿到你要的书。
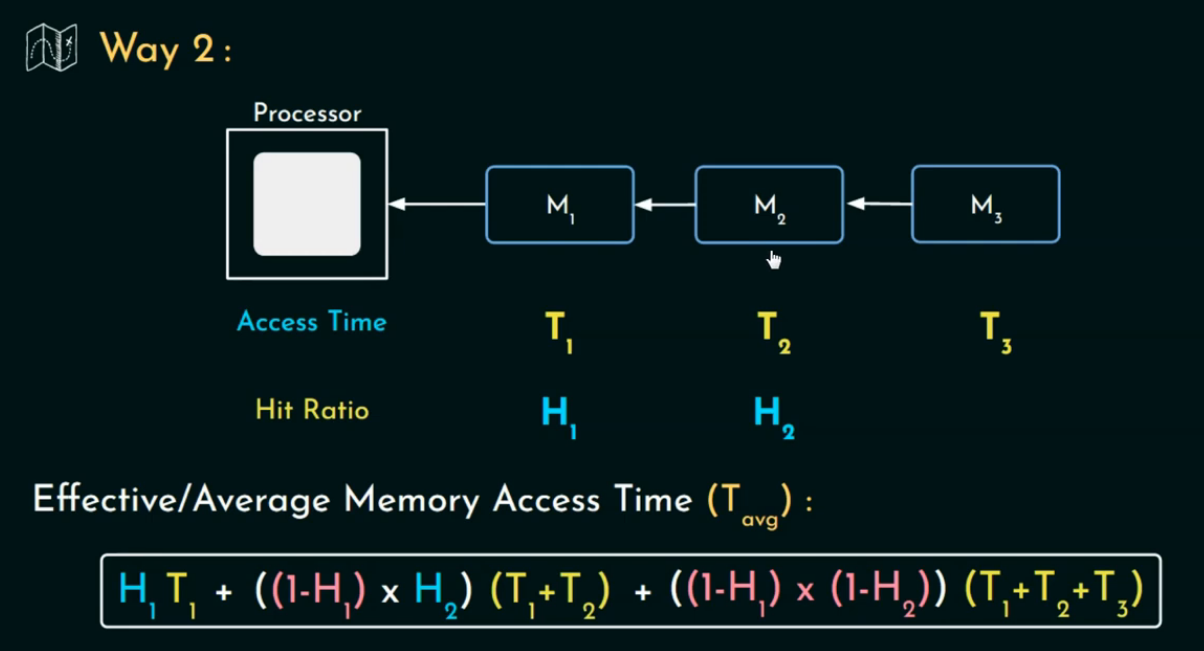
串行访问(Serial Access Model)
在这种模型下:
-
CPU 一级一级地访问内存层级:先查 L1 Cache → 如果 Miss 再查 L2 → 如果还 Miss 再查主存(Memory)。
-
每次只访问一个层次,如果命中了,就不继续往下找。
通俗解释:
就像你要在一个大图书馆找一本书:
-
你先去最近的书架(L1)找;
-
找不到再去二楼(L2);
-
如果还找不到,才去图书馆最深处(Memory)。
每次你只动一步,只有没找到才走下一步。
串行模型(Serial) 更接近实际硬件层级 Cache 的使用方式(大多数 CPU 是这样设计的);
并行模型(Parallel) 更适合某些流水线处理场景或预测式 prefetch 架构。
举例:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









