



众所周知,C语言阶段,指针是大家公认的较为困难的一部分内容,其主要难在以下几点:
- 抽象难懂(地址、指向关系绕);
- 操作危险(越界、野指针易导致崩溃);
- 用法复杂(多级指针、函数指针等嵌套难理清);
- 需手动管理(和内存绑定,错用易引发泄漏或混乱)。
实际上,兼容C语言的C++也存在一个类似于指针的概念:“引用”。其在形式以及使用方法上与指针都有很多相似性,接下来我们就一起先领略一下引用的魅力:
一.初识 C++ 引用
引用并不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。举个形象易懂的例子:李逵,在家称为"铁牛",江湖上人称"黑旋风"。
#include<iostream>
using namespace std;
void TestRef()
{
int a = 10;
int& ra = a;//<====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
printf("%d\n", a);
printf("%d\n", ra);
}
int main()
{
TestRef();
return 0;
}
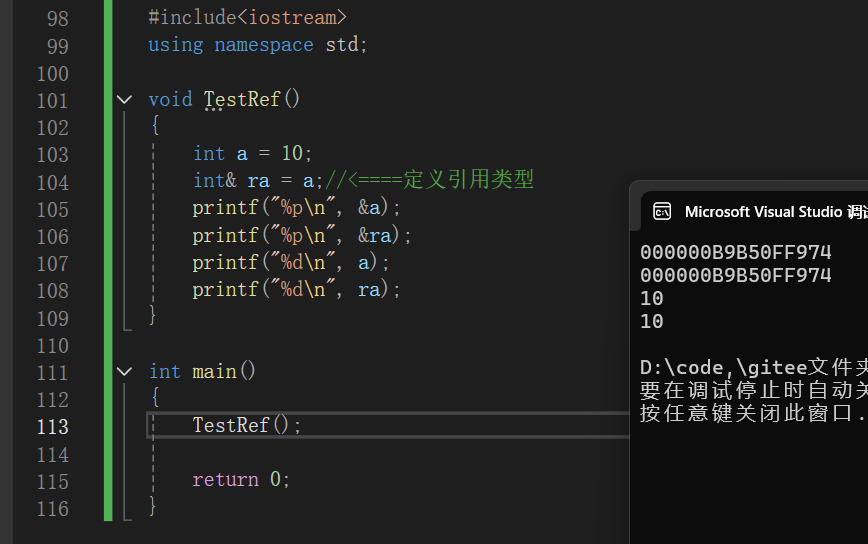
通过上述一个简单的代码可以看出:
核心结论:引用的本质
- 引用(
int& ra = a)是变量a的别名,它与a指向同一块内存空间。 - 引用本身不占用额外内存(或说编译器将其处理为与原变量完全绑定),因此
&a和&ra地址相同。 - 对引用的操作(如
ra = 20)等价于对原变量的操作(a也会变为 20)。
这段代码直观地证明了:引用不是新变量,而是原变量的 “另一个名字”。
二.深入剖析
我们从函数的角度切入,进一步剖析C++引用:
实例1:
#include<iostream>
using namespace std;
void Swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 0;
int y = 1;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}
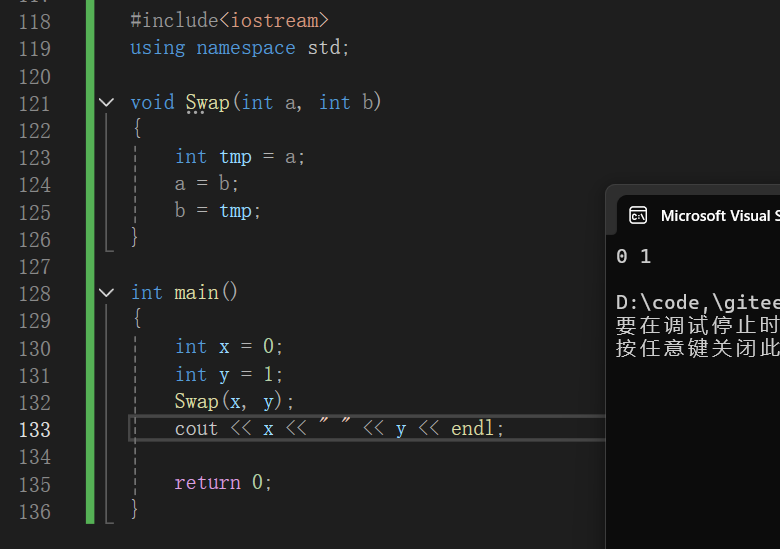
通过上述代码,我们可以看出,最终的运行结果并没有达到我们所预期的效果:实现两个数的交换,原因在于:形参的改变不影响实参,说的高级一点就是:因为是 “值传递”,函数参数只会接收变量的 “副本”,修改副本不会影响原始变量。
所以当我们写Swap函数想实现两个值的交换时,一般采用指针的方式或者数组接受的方式:
常规方式:
#include <stdio.h>
void Swap(int* a, int* b) {
int temp; // 临时变量,用于中转
temp = *a; // 把a指向的值存到temp
*a = *b; // 把b指向的值赋给a指向的变量
*b = temp; // 把temp(原来的a值)赋给b指向的变量
}
void Swap(int arr[]) {
int temp = arr[0]; // 访问数组第1个元素(对应原始变量x)
arr[0] = arr[1]; // 交换值
arr[1] = temp;
}
int main() {
int x = 10, y = 20;
printf("交换前:x = %d, y = %d\n", x, y);
Swap(&x, &y); // 传入x和y的地址
printf("交换后:x = %d, y = %d\n", x, y);
int arr[] = { x, y }; // 把x、y的值存到数组
printf("交换前:x = %d, y = %d\n", x, y);
Swap(arr); // 传数组名(本质是传数组首地址)
x = arr[0]; // 把交换后的值从数组写回原始变量
y = arr[1];
printf("交换后:x = %d, y = %d\n", x, y);
return 0;
}
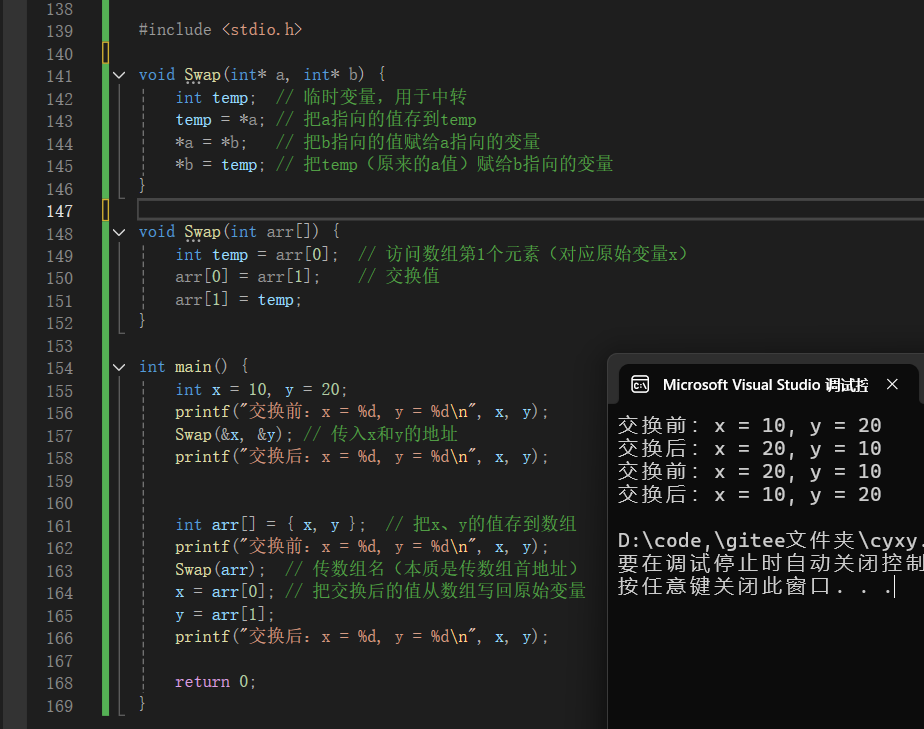
以上两种方法固然可行,但是代码相对繁琐,那么如果想使用值传递的方式实现呢?该怎么做?
答案是:引用!!!
引用改进:
#include<iostream>
using namespace std;
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0;
int b = 1;
Swap(a, b);
cout << a << " " << b << endl;
return 0;
}
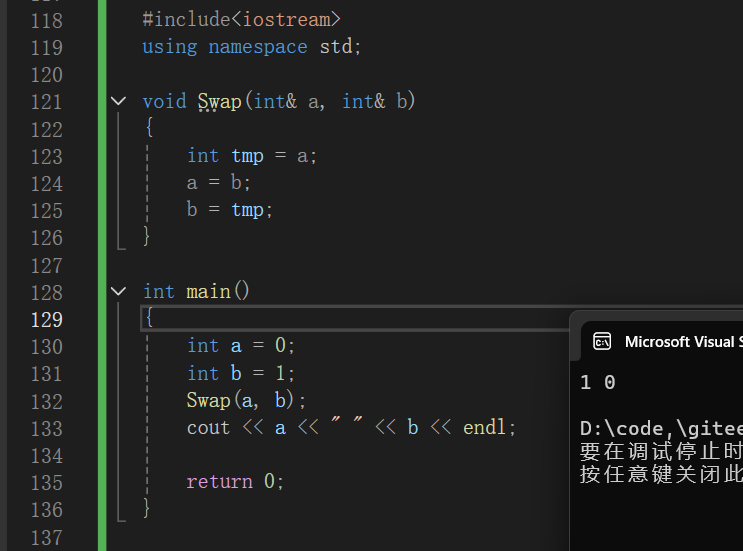
这样一来,形参就是实参的别名(a就是x的别名,b就是y的别名),也就摆脱了指针和数组的使用,使用起来舒服不少~
当然,我们也可以在指针的方法上加以验证和改进,使得指针法也可以变得浅显易懂,便捷好用:
指针法改进:指针+引用:
#include<iostream>
using namespace std;
void Swap(int*& a, int*& b)
{
int* tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 0;
int y = 1;
int* px = &x;
int* py = &y;
cout << px << " " << py << endl;
Swap(px, py);
cout << px << " " << py << endl;
cout << *px << " " << *py << endl;
Swap(px, py);
cout << *px << " " << *py << endl;
return 0;
}
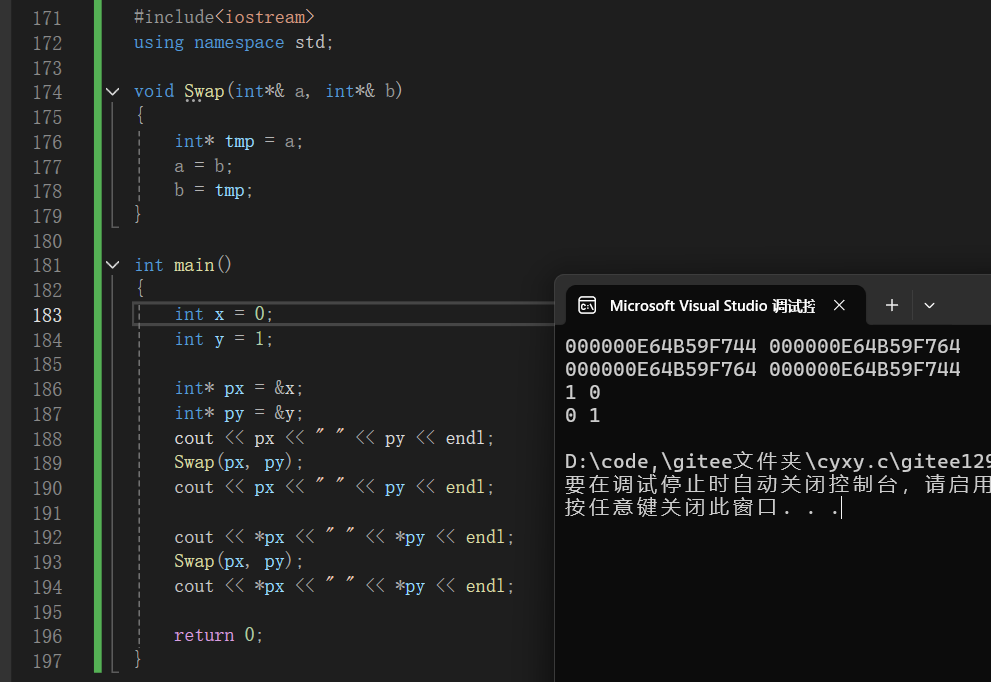
我们可以看到,当指针也加入了引用,整个代码逻辑变得通透许多,编译以后可以看出,无论是地址还是值,都进行了交换,达到了我们预期的效果。
引用特性:
引用具有以下几点特性:
1. 引用在定义时必须初始化;
2. 一个变量可以有多个引用;
3. 引用一旦引用一个实体,再不能引用其他实体;
三.引用-使用场景
1.引用做参数:
做参数有两层意义:
<1>.输出型参数;
<2>.提高效率;·
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
下面提供一份代码来测试一下第二层意义:提高效率:
#include<iostream>
using namespace std;
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
}
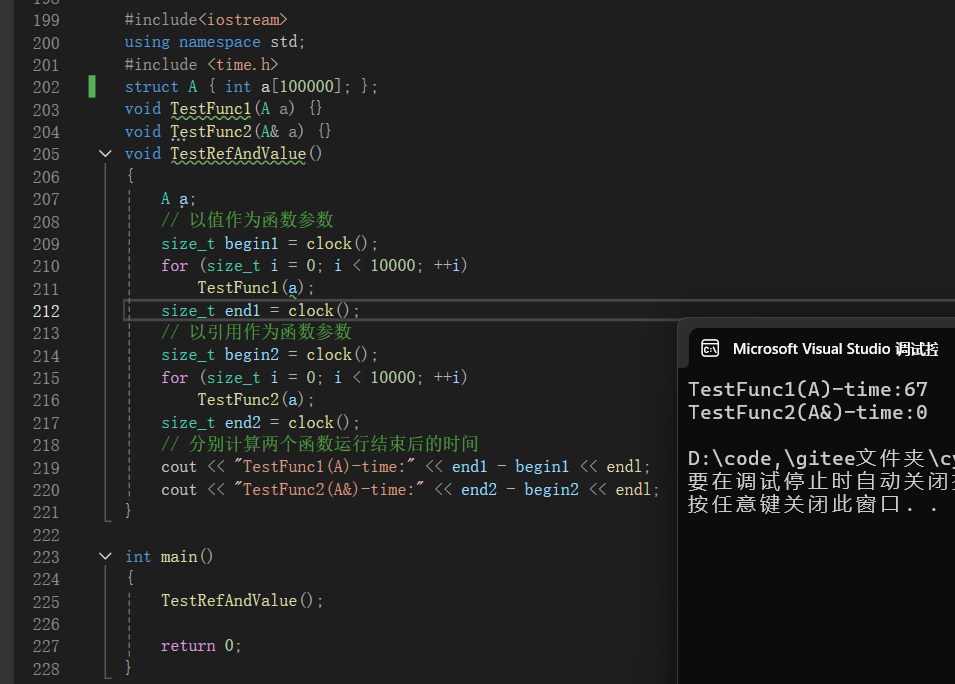
运行后我们可以看到,以引用作参数在运行时间上有着明显优势,特别是当字节数较大的时候,优势会更加明显。
2.引用做返回值:
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
引用做返回值的第一大价值就是不会再生成临时变量,常规的传值返回一般都会生成临时变量,而对于大对象来说,生成临时变量会导致很大的开销:
对临时变量的剖析:
在 C++ 中,函数返回值的方式(引用返回 vs 传值返回)本质区别在于:是否返回变量的 “原始实体” 还是 “副本”,这会直接影响性能和使用场景。
1. 传值返回(Return by Value)
- 行为:函数返回时,会创建返回对象的临时副本,将副本返回给调用者。函数内部的局部变量在返回后会被销毁。
- 示例:
int add(int a, int b) { int sum = a + b; return sum; // 返回sum的副本(sum会被销毁) } - 特点:
- 安全:返回的是副本,不会受原变量生命周期影响(原变量销毁不影响副本)。
- 开销:对于大型对象(如大结构体、类),复制副本会消耗内存和时间,性能较低。
2. 引用返回(Return by Reference)
- 行为:函数返回的是变量的引用(别名),本质是返回变量的内存地址,不会创建副本。
- 示例:
int& max(int& a, int& b) { return (a > b) ? a : b; // 返回a或b的引用(不创建副本) } - 特点:
- 高效:无需复制,直接返回原变量的引用,适合大型对象,性能更好。
- 风险:不能返回局部变量的引用(局部变量在函数结束后销毁,引用会变成 “野引用”,访问时行为未定义)。
- 可修改性:返回的引用可以被赋值,从而直接修改原变量(如
max(x, y) = 100;会修改 x 或 y 中较大的那个)。
核心区别总结
| 对比维度 | 传值返回 | 引用返回 |
|---|---|---|
| 本质 | 返回变量的副本 | 返回变量的引用(内存地址) |
| 内存开销 | 有副本复制开销(尤其大对象) | 无副本,直接引用原变量 |
| 生命周期依赖 | 不依赖原变量(副本独立) | 依赖原变量(原变量必须存活) |
| 能否修改原变量 | 不能(操作的是副本) | 能(通过引用直接修改原变量) |
| 典型场景 | 返回局部变量、小型数据 | 返回全局 / 成员变量、大型对象 |
实例2:
#include<iostream>
using namespace std;
int& Count(int x)
{
int n = x;
n++;
return n;
}
int main()
{
int& ret = Count(10);
cout << ret << endl;
printf("sssss\n"); //甚至是rand()函数
cout << ret << endl;
return 0;
}
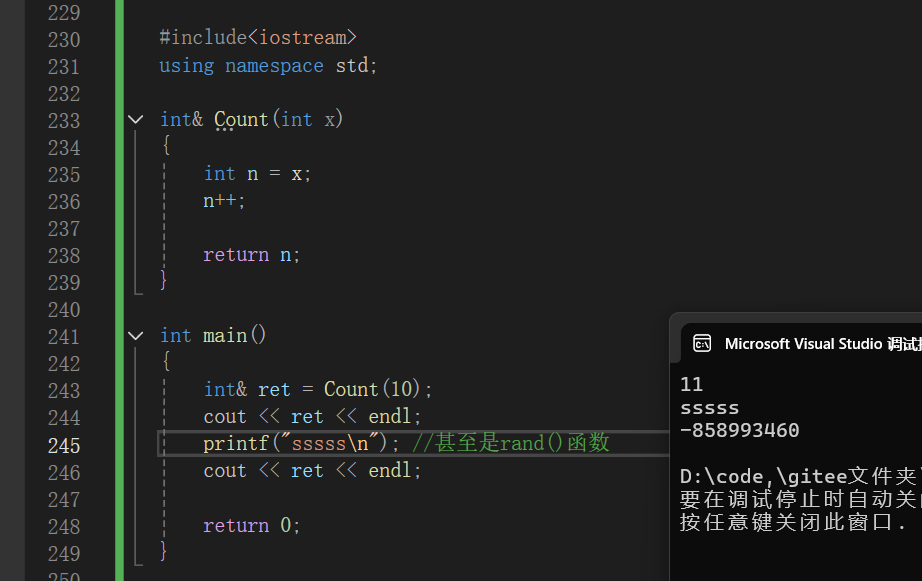
代码解析:
-
函数
Count的问题:int& Count(int x) { int n = x; // n是函数内部的局部变量,生命周期仅限于函数内部 n++; return n; // 错误:返回局部变量n的引用 }- 局部变量
n在函数Count执行结束后会被自动销毁(内存被释放)。 - 此时返回的引用本质是指向一块 “已释放内存” 的别名,称为野引用(类似野指针)。
- 局部变量
-
主函数中的问题:
int& ret = Count(10); // ret绑定到已销毁的n的内存 cout << ret << endl; // 第一次访问:可能侥幸输出11(内存未被覆盖) printf("sssss\n"); // 执行其他操作,可能覆盖原n的内存 cout << ret << endl; // 第二次访问:内存已被修改,输出随机值(未定义行为)- 第一次输出
ret时,n原来的内存可能还没被其他操作覆盖,可能 “碰巧” 输出11(但这是偶然的)。 - 执行
printf等操作后,原内存可能被新的数据覆盖,第二次输出就会变成随机值(如垃圾数据、负数等)。
- 第一次输出
原因如下:
- C++ 中,局部变量存储在栈区,函数执行结束后,栈帧被释放,局部变量的内存会被标记为 “可重用”。
- 引用
ret仍然指向这块内存,但内存中的数据已不再受保证(可能被后续函数调用、操作覆盖)。 - 访问已释放内存的引用属于未定义行为(UB),程序可能崩溃、输出错误值,或在不同编译器 / 环境下表现不同。
所以需注意:
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用 引用返回,如果已经还给系统了,则必须使用传值返回。
第二大价值还是提高效率:
#include<iostream>
using namespace std;
#include <time.h>
struct A { int a[100000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
}
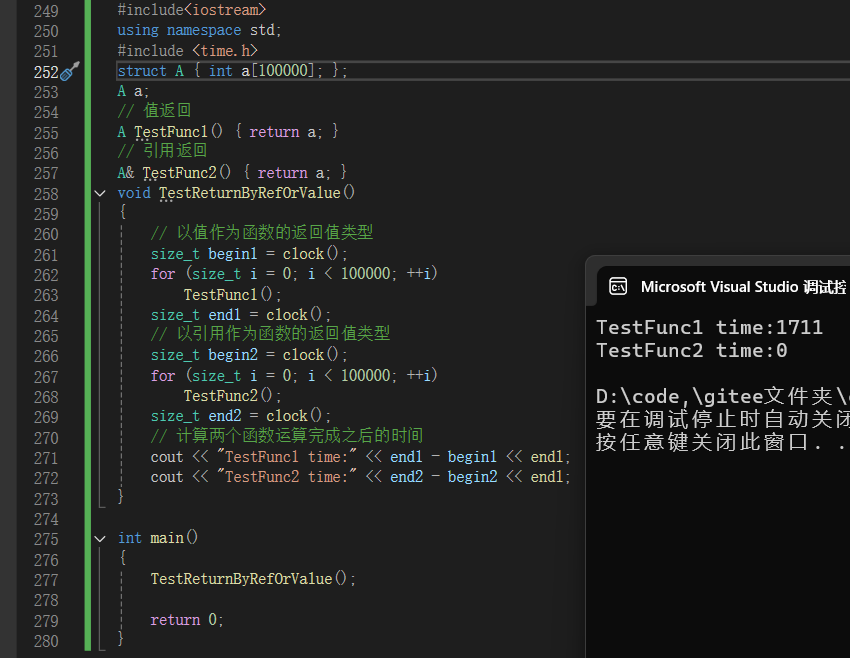
运行后明显可以看出,效率得到了明显的提高,特别是大对象时,效果更加显著。
四.引用和指针的区别
了解完C++引用之后,我们来看看引用与指针的区别:
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
我们来看下引用和指针的汇编代码对比:

引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何 一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
引用是指针的 “语法糖”
综合以上两点,引用在底层的实现机制和指针非常接近,它可以看作是对指针的一种封装和简化,为开发者提供了更简洁、更安全的语法。开发者不需要像使用指针那样显式地进行解引用操作(如 *pa),只需像使用普通变量一样使用引用,编译器会在底层自动完成类似指针的地址操作。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









