






1.各类头文件作用
1.stdio.h文件的常见函数
1)printf用于将要输出的内容输出到屏幕上
例如:
printf("Hello World");这段代码就会在运行时将"Hello World"输出到屏幕上。
此处不需要占位符,因为这已经是一个完整的格式字符串。
i)格式字符串作为直接参数
所以只想打印一个固定的字符串时,可以直接将字符串作为格式字符串传递给 printf,而不需要任何占位符或额外的参数。但是想要打印一些变量值或除字符串外的其他数据时,就需要在格式字符串中使用占位符,并在调用 printf 时提供相应的参数来替换这些占位符。占位符指明了后续参数的类型和格式。
除此之外,还有一些注意点:
ii)printf可以输入两个参数,第一个参数是占位符,第二个就是对应类型的数值。
常见的占位符如下:
#include <stdio.h>
int main() {
printf("%d\n", -1234);//%d用于输出带符号的十进制整数
printf("%u\n", 1234);//%d用于输出无符号的十进制整数
printf("%o\n", 8);//%o用于八进制
printf("%x\n", 16);//%x用于十六进制
printf("%c\n", 'H');//%c用于输出单个字符
char arr[] = "Hello World" ;
printf("%s\n", arr);//%s用于输出字符串
printf("%f\n", 1.25);//%f用于输出浮点数
int a = 10;
printf("%p\n",&a);//%p用于输出地址
printf("%e\n", 2e-3);//%e用于科学计数法
return 0;
}所以分类如下:
对于整形常见的有十进制(有符号的%d和无符号的%u),八进制(%o),十六进制(%x或%X)。
对于串有字符(%c)和字符串(%s)。
对于浮点型有(%f或%lf打印双精度浮点型)和科学计数法(%e)。
以及取地址的(%p)。
#include <stdio.h>
int main() {
printf("%o\n", 010);//%o用于八进制
printf("%x\n", 0x10);//%x用于十六进制
printf("%x\n", 0b1111);//%x用于十六进制
return 0;
}对于八进制和十六进制,我们还能直接使用前缀0表示八进制,前缀0x表示十六进制,0b表示二进制。

输出结果与上方是相同的。
iii)在占位符中间加上数值来对齐
例如打印123
#include <stdio.h>
int main() {
printf("%5d\n", 123);//%o用于八进制
return 0;
}![]()
运行结果如图,可见%5d指的是123三个数字右对齐
同理,如果我们写上%-5d就是左对齐
#include <stdio.h>
int main() {
printf("%-5d", 123);
printf("%s", "结束位置");
return 0;
} ![]()
iiii)转义字符
1)\\转义反斜杠
可用于打印地址,例如:
#include <stdio.h>
int main() {
printf("C:\\Cdocument\\源.c");
return 0;
}![]() 这样打印出来的结果只有一条反斜杠
这样打印出来的结果只有一条反斜杠
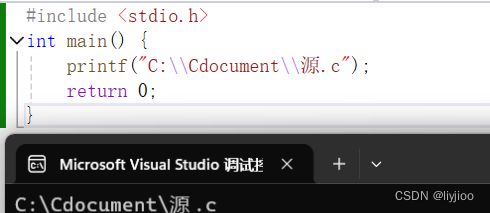 如果只有一条反斜杠就会输出其他不确定的字符
如果只有一条反斜杠就会输出其他不确定的字符
2)\'转义单引号
#include <stdio.h>
int main() {
printf("I\'m ...");
return 0;
}这样的写法实际上就等价于I'm代码里需要转义单引号
3)??x三字母词
用于在一些特殊字符集例如七位代码集(七位ASCII码)中,虽然字符存在但因为硬件等原因无法直接输入而引入三字母词。
三字母词列举如下:
| 三字母词 | 三字母词所对应的字符 |
| ??= | # |
| ??( | [ |
| ??) | ] |
| ??< | { |
| ??> | } |
| ??/ | \ |
| ??! | | |
| ??’ | ^ |
| ??- | ~ |

输入如图代码,就会发现原本的??=被替换了,并被改为了#。
但由于编译器的原因,并不是所有的编译器会将??=看为#,例如:
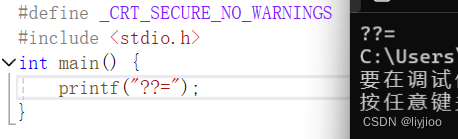
在Embarcadero Dev-C++中,我们可以通过工具---编译选项---编译时加入以下命令中加入-ansi来识别三字母词。
值得注意的是,编译器遇到?后会先进行判断是否是三字母词,如果不是就输出原来的字符,所以遇到如下代码
#include <stdio.h>
int main(){
printf("Eh???/n");
return 0;
}实际上输出的是Eh?,因为一开始的???不在三字母词里面,所以输出一个?,往后运行时遇到??/就被翻译为\,和后面的n结合被识别为换行。所以运行结果如下:

4)\n,\t换行符与制表符
\n就是直接换行,输出在下一行开始,\t制表符在文本中通常用于创建一个比空格更宽的间隔,以使得文本更易于阅读或对齐。
这个比空格更宽实际上就是指8的倍数。
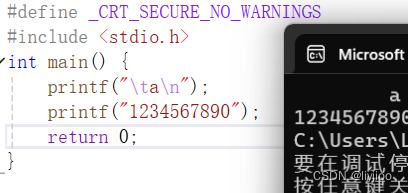 如图,a前面空了8格空格。
如图,a前面空了8格空格。
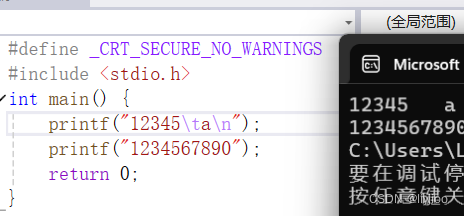 此时在前面加上不大于8格的字符,a的位置还是不会变。
此时在前面加上不大于8格的字符,a的位置还是不会变。
 如图,前面便空出了16个即2*8的格数。
如图,前面便空出了16个即2*8的格数。
总之,\t可以空出8的倍数次的空格数,一旦前面的字符数大于8*n格,那就\t后的字符的位置为8*(n+1)+1的位置,小于8*n格但大于8*(n-1)格,那就放置在8*n+1的位置上。
5)\ddd用于将八进制转为十进制,\xdddd十六进制转十进制,再用这个十进制到ASCII表中查找。
#include <stdio.h>
int main() {
printf("\12");//12变为十进制的10也就是ASCII的换行符
printf("\101");//101在十进制是65也就是A的ASCII码
printf("\1281");//8超过八进制最大值7,前面的12换行,于是就输出\n81
printf("\1011");//101代表ASCII的A,后面的1不被包括在八进制转换里,所以最后输出A1
//printf("\401");//报错257对于字符来说太大的错误
printf("\12a11");//12先换行,然后后面输出a11
return 0;
}总结以下,实际上\ddd就是把八进制转为对应ASCII码的值。
如果长度大于3位时,取前三位,后面的就都当作正常字符,如\1011看作\101和‘1’的组合。
如果输入的字符不在0-7之内,或是出现非8进制字符例‘a’等,进行截断,前面视作8进制,后面视作字符。
如果输入八进制大于400,超出ASCII的范围,就会直接报错。
6)转义字符小测
#include <stdio.h>
int main() {
printf("12\101\t12\n");
printf("%d",strlen("12\101\t12\n"));
return 0;
} 获取的值是
长度为7是因为长度看的是字符的个数,在这里面\101看作一个字符,因为\101就是八进制转换的一个ASCII字符,\t和\n也是如此。
2)scanf用于读取数据
如下代码用于存储输入的数值并输出输入的值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int choice;
printf("请输入你选择的数字");
scanf("%d", &choice);
printf("你选择了%d", choice);
return 0;
}注意点如下:
i)使用_CRT_SECURE_NO_WARNINGS
scanf是由C语言提供的读取数据的方法,但是在Visual Studio中使用的是scanf_s,所以Visual Studio认为这是不安全的,但是使用scanf_s就没有跨平台的性质了,所以使用_CRT_SECURE_NO_WARNINGS
ii)存储数据时需要取地址符号
但是由于数组名称实际上就可以看作首元素的地址,所以直接写一个数组不加取地址符号也可以
2.stdlib.h文件的常见函数
1)随机数生成
i)rand生成0到32767大小的随机数。
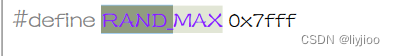 如图是RAND的define定义。
如图是RAND的define定义。
ii)srand(x)中的x随机数种子用于初始化随机数生成器
srand中的x默认是1,所以每次使用都会产生相同的随机数,为了能让每一次生成的随机数都不相同,就可以使用不断变化的时间作为随机数种子,即使用srand((unsigned int)time(NULL));
后面的(unsigned int)表示类型转换为无符号整形,time函数的作用是返回自1970年1月1日0时0分0秒以来的秒数,这个函数不接受任何参数,所以直接加上(NULL)即可。
iii)srand和rand都需要调用stdlib.h的头文件,time(NULL)需要调用time.h的头文件。
2)system操作
i)关机和终止关机
1)shutdown /s /t 60
这个指令的shutdown和/s(shutdown)共同表示关机指令
/t 60表示延迟60秒关闭计算机。
2)shutdown /a
a表示abort,终止之前的shutdown命令
ii)清屏和暂停程序
system("pause");暂停和system("cls");清屏
iii)获得命令帮助,可以使用这个命令帮助查询相关命令
system("HELP");
大致输出如下:

iiii)设置和控制窗口
system("title 名称");
注意,一旦退出程序即main的return 0或者main的结束,这个标题就会变回原来的名称。
system("mode 行数,列数");
或者system("mode con cols=宽度(单位:字符) lines=高度");
iiiii)显示当前日期和时间
system("DATE /t");:显示当前日期,包括年月日和星期。
system("TIME /t");:显示当前时间,包括时分。
iiiiii)文件操作
system("dir")获取当前目录的文件和文件夹
system("type 文件名")获取指定文件名的内容
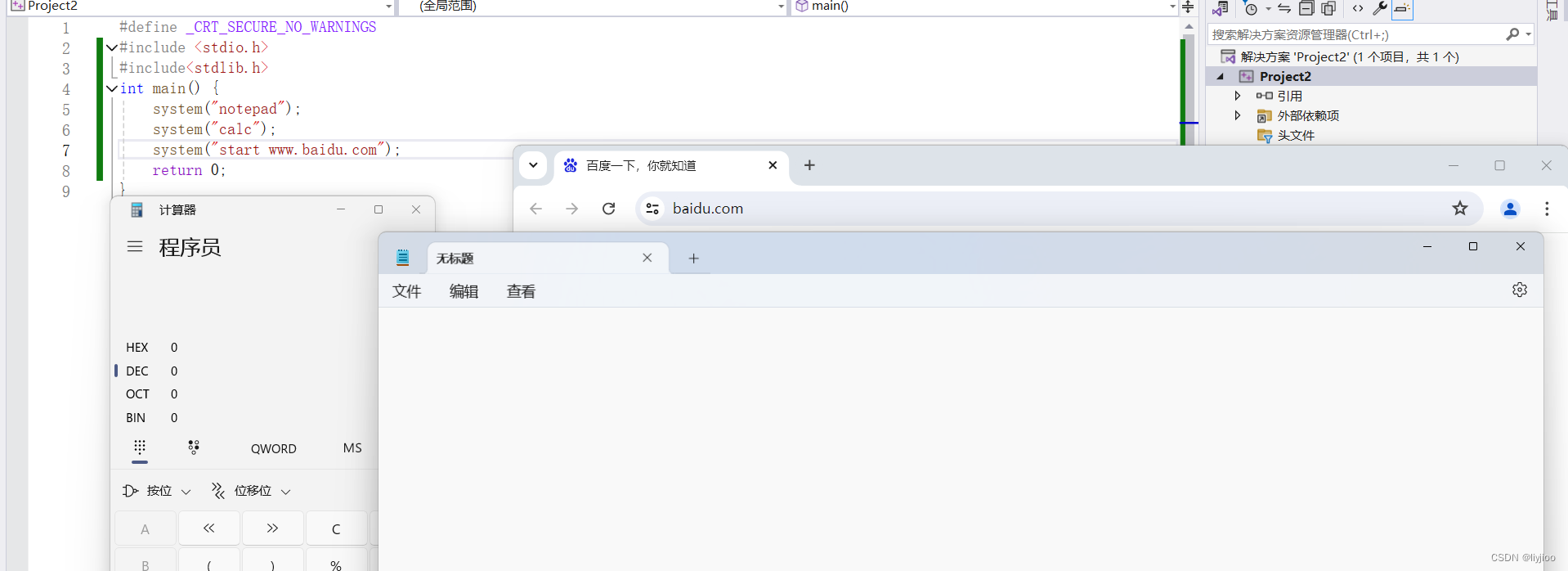
iiiiiii)打开应用程序
system("notepad");:打开记事本(Notepad)。
system("calc");:打开计算器。
system("start 地址");:打开指定地址(如URL、文件路径等)的程序或文件。
具体操作效果如图:
2.常见数据类型
1)整形
分为short(短整型),int(整形),long(长整型),long long(长整型)
在Visual Studio中所占字节数分别是2,4,4,8
(int和long的大小相同其实没任何问题,因为在C语言中规定的是long的大小不小于int即可。)
short的范围为-32,768 ~ 32,767
int的范围为-2,147,483,648 ~ 2,147,483,647
long的范围为-2,147,483,648 ~ 2,147,483,647
long long的范围为-9223372036854775808~9223372036854775808
2)浮点型
分为float(单精度)和double(双精度)
字节数分别为4,8
3)字符型
char字节数为1字节
3.数据运算
1)数据运算之除法运算
i)除法运算在整数除以整数时会返回整数。
#include <stdio.h>
int main() {
printf("%d\n", 5/3);
return 0;
}这段代码返回的是1,即5/3=1......2,只输出商而不输出余数
ii)但是一旦除数与被除数之一变为浮点数,返回的值也是浮点数
#include <stdio.h>
int main() {
printf("%f\n", 5.0/3);
return 0;
}返回了1.666667,说明返回了更精确的浮点数。
这样的特性可以用在如下情景:
1)计算1/1+1/2+3/1+1/4+...+1/100的最终值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += 1 / i;
}
printf("%d", sum);
return 0;
}假设使用如图所示的方法解决这个数学问题,会发现这个最终输出的答案是1,但是第一位已经是1了,后面都是正的数,但是加上去却没有变化,这是因为后面的1/n中n大,从而返回0,所以后面的99项都是0。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
float sum = 0;
for (int i = 1; i <= 100; i++) {
sum += 1.0 / i;
}
printf("%f", sum);
return 0;
}所以只需要带上小数即可,最终答案是5.187378
2)计算1/1-1/2+1/3+...-1/100计算交错的和
对于计算交错的数,我们可以提取出(-1)^(n-1),所以我们可以使用math库中的math的pow(x,y)算x的y次幂,这里的x使用-1替代,y使用n-1或n+1等替代。
#include <stdio.h>
#include<math.h>
int main() {
float sum = 0;
for (int i = 1; i <= 100; i++) {
sum += 1.0 / i * pow(-1,i-1);
}
printf("%f", sum);
return 0;
}由此计算出来的结果是0.688172
除此之外,还可以使用flag交错相乘计算。
#include <stdio.h>
#include<math.h>
int main() {
float sum = 0;
int flag = 1;
for (int i = 1; i <= 100; i++) {
sum += 1.0 / i * flag;
flag = -flag;
}
printf("%f", sum);
return 0;
}还可以使用if分开求和然后正数减负数的绝对值
#include <stdio.h>
#include<math.h>
int main() {
float sum_pos = 0;
float sum_neg = 0;
for (int i = 1; i <= 100; i++) {
if (i % 2 == 1)
sum_pos += 1.0 / i;
if (i % 2 == 0)
sum_neg += 1.0 / i;
}
printf("%f", sum_pos - sum_neg);
return 0;
}2)数据运算之左右移运算符
i)左右移运算符都是在补码上的位移
,如下代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 1;//二进制表示就是00000000000000000000000000000001
int b = a << 2;//二进制表示就是00000000000000000000000000000100
printf("%d\n%d\n", a, b);
return 0;
}所以输出1和4。
但是左右移运算符也有不同的地方:
ii)左移运算符都是补0,无论正数还是负数。
假设a是-1,代码例子如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = -1;
//-1的原码是 10000000000000000000000000000001
//变为反码是 11111111111111111111111111111110
//补码是 11111111111111111111111111111111
int b = a << 2;
//左移后 11111111111111111111111111111100
//转为反码 11111111111111111111111111111011
//转为原码 10000000000000000000000000000100
printf("%d\n%d\n", a, b);//所以最后的a和b是-1和-4
return 0;
}图示可能缺乏对正负数的解释,接下来是对正负数的解析:
1)原码输出,补码存储运算
原码就是输入的值的二进制,例如上述代码的-1,符号位为1表示负数,所以(int)-1的二进制原码为
10000000000000000000000000000001
从原码到补码的存储需要经历反码的转换
反码就是除了符号位,其余位取反,即1111111111111111111111111111110
补码就是反码+1,所以-1在内存中存储的是1111111111111111111111111111111
补码用于运算,例如
先要算到补码再加减等运算,最后原码输出。
2)正数原反补相同,无符号数无原反补概念,负数需要注意
这句话比较好理解,就是说正数例如1的二进制存储就是00000000000000000000000000000001
在输出和存储时不太需要注意三者的转换
3)正数之差其实就是正负数之和
由于CPU里只有加法器,所以补码可以把加法和减法统一处理
例如:1-1实际上就是1+(-1)
00000000000000000000000000000001
11111111111111111111111111111111
100000000000000000000000000000000
去掉首位
00000000000000000000000000000000即0
4)右移运算符如果负数就补1,正数补0
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = -1;
//-1的原码是 10000000000000000000000000000001
//变为反码是 11111111111111111111111111111110
//补码是 11111111111111111111111111111111
int b = a >> 2;
//右移后 11111111111111111111111111111111
//转为反码 11111111111111111111111111111111
//转为原码 11111111111111111111111111111111
printf("%d\n%d\n", a, b);//所以最后的a和b是-1和-1
return 0;
}如图,-1的右移还是-1。
5)复合运算符>>=或<<=
操作数>>=/<<=右移或左移的位数
iii)位移运算符不能位移负数位,并且位移运算符也不能用于浮点数
由于浮点数的编码方法与整数不同,所以位移运算符仅适用于整数。如果位移运算符位移负数位,这就是不合法的。
iiii)使用左右移运算符打印某二进制奇数位或者偶数位
使用位移可以将一个二进制数的任意一位移到第一位,那此时将改位与1与就能获得该二进制位的值。
代码实现如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num;
printf("请输入数值>>");
scanf("%d", &num);
for (int i = 30; i >= 0; i -= 2) {
printf("%2d", (num >> i) & 1);
}
return 0;
}但是或0不行,因为每次进行与或运算时0表示00000000 00000000 00000000 00000000
虽然假设对num位移后如果最低位是1那就是1,最低为为0就是0
但是除了最低位以外如果不都改为0,输出的值就不一定会是1为1,0为0,当我们所希望的是排除其他位的干扰。
假设对-1计算奇数位,因为-1的二进制是11111111 11111111 11111111 11111111
一开始先位移30位,获得的是11111111 11111111 11111111 11111111
我们要取出最低位即原来的30位,就需要排除其余31位的影响,也就是把它们在打印时变为0
(00000000 00000000 00000000 00000001)
如果用或0,那就变为了11111111 11111111 11111111 11111111,这样打印出的奇数位是-1,不符合实际。
iiii)~按位取反将修改补码
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 0;
a = ~a;
printf("%d\n", a);//所以最后的a是-1
return 0;
}如图,int a = 0说明a的原码是00000000 00000000 00000000 00000000
反码补码都是如此
按位取反修改了补码,并全部取反为11111111 11111111 11111111 11111111
由上面的解释,可以知道这个补码代表的是-1
3)sizeof运算
sizeof用于计算占用空间大小,需要注意在字符串的使用时,{包括0}或"..."和{不包括0}是两个大小,因为sizeof是在看本质占用的空间,所以也会包括0。
i)sizeof有下列3种写法与1种错误写法:
正确写法:sizeof(int)/sizeof((int)a)/sizeof (int)a
错误写法:sizeof int
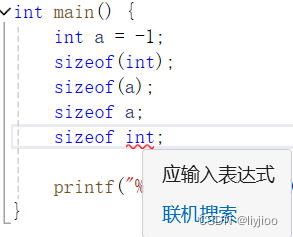 具体实现如图。
具体实现如图。
ii)sizeof不直接参与运算
即在sizeof中的运算,是不会影响到外部的,如以下代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
int c = 0;
printf("%d\n",sizeof(c = a + b));
printf("%d\n", c);
return 0;
}如图,该代码在sizeof中使用了赋值运算符把a+b的值赋值给c,并输出了c的大小,最后又打印了c的值。
 如图,可见c的值在sizeof外并不会因为sizeof中的赋值而改变
如图,可见c的值在sizeof外并不会因为sizeof中的赋值而改变
4)前置和后置自增自减
前置就是先计算,后使用
后置就是先使用,后计算
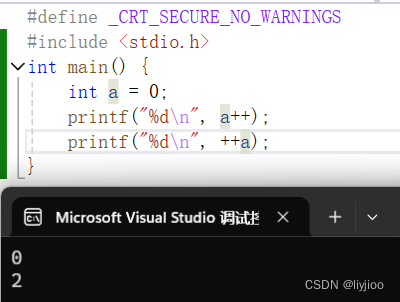 如图,先后置自增,打印出来的是自增之前的0,再进行一次前置自增,变为了2再输出。
如图,先后置自增,打印出来的是自增之前的0,再进行一次前置自增,变为了2再输出。
5)强制类型转换---(类型)名称
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
double a = 3.1415926;
printf("%d\n",(int)a);
return 0;
}最后输出3,即只保留个位
6)三目运算符 ---exp1?exp2:exp3;
i)这个运算符需要注意这三个组成部分都是表达式而不是变量什么的。
所以可以使用表达式来操作复杂的情况。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
int c = a > b ? a+20 :b+30;
printf("%d", c);
return 0;
}例如上述代码,假设要获取a和b中最大的值,并且将最大的值加上其对应的值并输出,这时候直接在后面的表达式中加上即可,不需要先 int c = a > b ? a :b;将最大值赋值给c,再if语句加上对应的值。
ii)三元运算符的期望是两边的表达式都返回一个值,而不是执行一个操作(如赋值)。
所以一旦我们希望a和b也和c一样在他为最大时加上对应的值,即a和b也会改变时,使用+=就不行,因为赋值操作是一个操作,三元运算符不能直接执行一个操作。
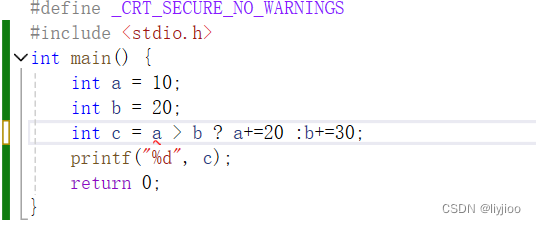 如图,+=就报错
如图,+=就报错
7)运算符优先级和结合性
优先级是指:优先级高的比优先级低的先运算,当并不是优先级高的运算完再算低的,详见运算之歧义表达式。
- 后缀运算符---函数调用()、数组索引[]、结构体成员访问./->、后缀自增
++、后缀自减-- - 一元运算符---前缀自增++、前缀自减
--、取反!、按位取反~、取地址&、解引用*、求大小sizeof、类型转换(type cast)、取正+、取负- - 乘法类运算符---乘法(
*)、除法(/)、取模(%) - 加法类运算符---加法(
+)、减法(-) - 移位运算符---左移(
<<)、右移(>>) - 关系运算符---小于(
<)、大于(>)、小于等于(<=)、大于等于(>=) - 相等运算符---等于(
==)、不等于(!=) - 位与运算符---按位与(
&) - 位异或运算符---按位异或(
^) - 位或运算符---按位或(
|) - 逻辑与运算符---逻辑与(
&&) - 逻辑或运算符---逻辑或(
||) - 条件运算符---条件(三目)运算符(
?:) - 赋值运算符---赋值(
=)、复合赋值(如+=,-=,*=,/=,%=,<<=,>>=,&=,^=,|=) - 逗号运算符---逗号(
,)
结合性:当运算符的优先级相同时,运算顺序在大多情况下是从左到右,单目,条件,赋值运算符是从右到左的,例如:
!a++ 先计算a的自增,再计算取反
a?b:c?d:e;先计算c?d:e;再计算外层a?b:...;
a=b=c先计算b=c再计算a=b。
8)取模运算
i)取模运算的左右操作数必须是整数
 如左图。
如左图。
9)位操作符
i)与用于添0,或用于添1
1)使用或添1的例子:
假设要对4的二进制的第2位添1,代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num = 4;// 00000000 00000000 00000000 00000100
printf("%d", num | (1 << 1));//| 00000000 00000000 00000000 00000010
// 00000000 00000000 00000000 00000110
return 0;
}2)使用与添0的例子:
假设对6第二位的1添0,代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num = 6; // 00000000 00000000 00000000 00000110
printf("%d", num & ~(1 << 1));//& 11111111 11111111 11111111 11111101
// 00000000 00000000 00000000 00000100
return 0;
}使用与来将1变为0,但是此时需要使用按位非,这样避免对其他位的影响。
ii)计算二进制数1或0的个数
1)使用%2来计算二进制中1和0的个数
二进制的手算方法就是除二取余,逆序排列,例如10的二进制,如图写法:
 逆着读取就是1010
逆着读取就是1010
实际上就是(((0*2+1)*2+0)*2+1)*2+0 = 10。即0*2^0+1*2^1+0*2^2+1*2^3=10
所以可以判断余数来看二进制中1或0的个数,代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 10;
int count_zero = 0;
int count_one = 0;
do{
if (a % 2 == 0) {
count_zero++;
}
else {
count_one++;
}
} while (a /= 2);
printf("1:%d 0:%d", count_one, count_zero);
return 0;
}如代码,当a=10的情况,输出是![]()
但是将a改为负数的话就会有有不同的结果,下面是对
i)负数取余和除法运算的分析:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
printf("%d", 5 / 2);
printf("%d", -5 / 2);
printf("%d", 5 / -2);
printf("%d", -5 / -2);
return 0;
}结果如右:![]() 可见
可见
- 如果两个数同号(同为正或同为负),则结果为正。
- 如果两个数异号(一个正一个负),则结果为负。
- 其绝对值就是不看正负直接相除,再带上上述的正负号情况。
除法并不难理解,接下来看取余操作

取余运算中,先计算除法,第一个运算就不多作解释,第二个直到异号取负,所以-5/2=-2
取余可以看作-5-2*(-2) = -1,第三个也一样,5-(-2)*(-2) = 1 ,第四个-5-(-2)*2 = -1
2)使用位移和与1来计算二进制的1和0的个数
回到原题,假设我们算负数的二进制位1的个数,使用取余是不正确的,因为使用取余和除法的这种方法只能运用到正数,所以我们可以试想使用位移运算来计算二进制位1的个数,由于int占8字节为32位,所以可以使用for循环从位移31位到位移0位,然后使用1与,如果与了之后计算结果是1,那就说明位移后占在最低位的数值是1,不断循环就能得到1的个数。
简写代码如下:
...
for (int i = 31; i >= 0; i--) {
if (c >> i & 1)
count_one++;
else
count_zero++;
}
...3)还可以使用n和n-1的与来计算二进制中1和0的个数
十进制13的二进制为1101,而12的二进制为1100,比起13,12少去了最后一位的1,假设此时我们13&12,就可以得到1100,比起之前的13,1100少了一个最低位的1,这时候在对1100减去1,可以得到1011,将1100&1011,得到1000,对1000减一,得到111,1000&0111,得到0000,现在,我们就能大致推断出,将n&n-1,就能删去其二进制的最低位的1,直到删至为0,就能计算出其1的个数,所以代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 13;
int count = 0;
while (a != 0) {
a = a & a - 1;
count++;
}
printf("1:%d", count);
return 0;
}![]() 结果正好是3。
结果正好是3。
10)异或^
i)异或的概念:对运算符两侧数的每一个二进制位,同值取0,异值取1
ii)可以用于计算两个数二进制数相同或不同的个数
由于相同返回0,不同返回1,那根据以往按位与就能得到0或1即不同或相同数值个数。代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 10; //00000000 00000000 00000000 00001010
int b = 2; //00000000 00000000 00000000 00000010
int c = a ^ b;//00000000 00000000 00000000 00001000
int count_zero = 0;
int count_one = 0;
for (int i = 31; i >= 0; i--) {
if (c >> i & 1)
count_one++;
else
count_zero++;
}
printf("1:%d 0:%d", count_one, count_zero);
return 0;
}iii)使用异或不新创建变量互换两个值
一般的,如果我们要互换两个值,我们一般会选择创建一个临时变量来互换变量,如下所示:
...
int temp = a;
a = b;
b = temp;
...但是想要不互换变量,我们可以使用两个变量的其中一个变量存储两者的和,然后使用另一个变量存储和-这个变量,这样就完成了这一个变量的互换,然后将和-这个互换了的值,再赋值给最开始存储和的变量,就能完成互换,代码如下:
...
a = a + b;
b = a - b;
a = a - b;
...这样的互换其实就是依靠和的减法来互换,但是这样会有风险,假设我两个值的和超过了int的总值,这段代码就失效了。
所以使用异或的相同就为0,不同为1的特性,a^b^b = a
a^b^a = b(异或的运算顺序可变,想要证明可以使用穷举法,假设第一个操作数为0,后面为1,1/0,0改不改都是一样,如果是1,0,结果是1,互换两位为0,1,结果还是1,假设第一位为1,都是同理的)。
所以写代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 10;
int b = 8;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("a:%d b:%d", a, b);
return 0;
}![]() 结果如左。
结果如左。
11)逻辑操作符
分为与&&,或||
i)使用时需要注意,&&从左往右遇到第一个假,后面就不再进行运算了。
代码如图:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 0, b = 0;
int c = 1;
int i = ++a && b++ && c++;
printf("i:%d,a:%d,b:%d,c:%d", i, a, b, c);
return 0;
}按理来说,假设&&不管遇没遇到假,都要进行到底,那么i=0,a=1,b=1,c=2
但事实上,结果是![]()
这说明了,&&一旦遇到假,马上就终止了,导致c没有自增。
除了与,或也是一样的,只不过是或一旦遇到真就不再进行了
稍微修改刚才的代码,用代码验证如下:
 除了a自增和i变为1其他都不变。
除了a自增和i变为1其他都不变。
12)运算之算数转换和类型转换以及算数转换
i)对于char和short等范围小于int的数据类型,在进行整形运算时会被整形提升为int
整形提升的扩展是根据符号位和数据类型来进行的,分为符号扩展和零扩展。符号扩展主要是对于short和char来说,使用最高位的符号位来扩展,例如符号位为1,前面就都填上1,假设为0就全添0。零扩展主要是unsigned char和unsigned short,他就直接在前面添0即可。
整型提升的意义是:表达式的整形运算在CPU的相应运算器件中执行,CPU内整形运算器ALU的操作数字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。因此,两个char相加在CPU中也需要先转化为CPU内整形操作数的标准长度
ii)类型转换就是将范围大的数据类型转换为小的数据类型时发生截断,取低位
举例如下,
1)使用char a = 3和char b =127相加,赋值给char c,然后输出c,求c的值,代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char a = 3;
//3的二进制是00000000 00000000 00000000 00000011
//发生截断,获得0000011
char b = 127;
//127的二进制是00000000 00000000 00000000 01111111
//发生截断,获得01111111
char c = a + b;
//a整形提升为00000000 00000000 00000000 00000011
//b整型提升为00000000 00000000 00000000 01111111
//那么算出的c00000000 00000000 00000000 10000010
//发生截断为10000010
printf("%d", c);
//这个是负数的补码,所以取反码11111111 11111111 11111111 10000001
//原码为10000000 00000000 00000000 011111110
//所以结果为-(2+4+8+16+32+64)=-126
return 0;
}2)short或char与int比较,也需要整型提升
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char a = 0xb6;
short b = 0xb600;
int c = 0xb600000;
if (a == 0xb6)
printf("a");
//0xb6为00000000 00000000 00000000 10110110
//截断为10110110
//使用等号进行整型提升为11111111 11111111 11111111 10110110与00000000 00000000 00000000 10110110不同
if (b == 0xb600)
printf("b");
//0xb600为00000000 00000000 10110110 00000000
//截断为10110110 00000000
//整形提升后都是1所以肯定也不同
if (c == 0xb600000)
printf("c");
//由于是int所以不需要整型提升和截断,所以一定相等
return 0;
}3)单目运算符的应用
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a = 0;
printf("%d\n", sizeof(+a));
printf("%d\n", sizeof(-a));
printf("%d\n", sizeof(++a));
printf("%d\n", sizeof(--a));
printf("%d\n", sizeof(!a));
printf("%d\n", sizeof(~a));
return 0;
} 结果如图,可见除了逻辑取反,其他都会产生整型提升。
结果如图,可见除了逻辑取反,其他都会产生整型提升。
4)unsigned的整型提升使用
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
unsigned char a = 200;
//200的二进制00000000 00000000 00000000 11001000
//截断后为1100100
unsigned char b = 100;
//100的二进制00000000 00000000 00000000 01100100
//截断后为01100100
unsigned char c = a + b;
//a+b整形提升,由于都是unsigned,所以补0
//和为00000000 00000000 00000001 00101100
//c为 00101100
printf("%d,%d", a + b, c);
//a+b为00000000 00000000 00000001 00101100->300
//c为 00000000 00000000 00000000 00101100 ->44
return 0;
}iii)算数转换是指当两个操作数属于不同类型时,低位次的类型要先转换为高位次的类型再进行计算
具体为此关系如下:
long double
double
float
unsigned long int
long int
unsigned int
int从上到下为高到低
举例:一个int的a与一个float的b相加,a要先转换为float。
13)运算之歧义表达式
i)c+--c歧义---操作数的获取顺序歧义
操作符只能说明--计算在+之前,但并不能说明第一个c在什么时候获取,假设第一个c在--之前获取,那c就是原来的值,但如果是在--之后获取,第一个c的值就是原来的c-1,所以是有歧义的。
又如在函数中,如:
int fun()
{
static int count = 1;
return ++count;
}
int main()
{
int answer;
answer = fun() - fun() * fun();
printf( "%d\n", answer);
return 0;
}我们只知道计算顺序但不知道fun的调用顺序,就像c+--c,c一开始读到第一个c就调用了还是先算完后面才调用,是一个意思。
ii)a*b+c*d+e*f歧义---乘完先加还是继续乘
按照日常的想法,我们会先将a*b,c*d,e*f都先算出来,最后再相加。
但是如果说先看前面,由于乘法的优先级高于加法,所以从左向右读到a*b+c*d+...时,算加法之前先算乘法,乘法算完之后先算加法还是继续看后面的乘法,这就有歧义了。
所以有如下两种计算顺序:
- a*b ,c*d ,a*b+c*d ,e*f , a*b+c*d+e*f
- a*b ,c*d ,e*f ,a*b+c*d , a*b+c*d+e*f
如上的三个乘法是独立的,所以最终不会产生太大影响,但如果是如下的不独立的三个自增运算
#include <stdio.h>
int main()
{
int i = 1;
int ret = (++i) + (++i) + (++i);
printf("%d\n", ret);
printf("%d\n", i);
return 0;
}这样由于先算完自增和先算两个自增再加是不一样的,所以也是有歧义的,最终可以得到的ret为10=3+3+4和12=4+4+4。
4.变量
1)语法:类 名 = 值;
2)全局变量和局部变量
1)全局变量写在{}代码块之外,局部写在之内。
2)局部变量和全局变量同名,局部变量优先。
3)局部变量没有初始化时数据是不确定的,但是全局变量没有初始化默认为0。
#include <stdio.h>
#include<math.h>
int i;
int main() {
printf("%d\n", i);
return 0;
}该代码结果是0,但当将int i写入局部变量的{}之内后就会报错局部变量未初始化。
4)全局变量的作用域是整个工程,局部变量的作用域是代码所在的局部范围
值得注意的是全局变量的作用于整个工程而不是整个文件,说明我们可以通过外部文件来引入。
使用extern 类 名;引入外部文件的全局变量例子:

5)全局变量的生命周期是整个工程,局部变量的生命周期是代码所在的局部范围
5.常量
1)分类:
i)字面常量:1,2,3...
ii)const修饰常变量:归根结底还是变量,只不过不能修改
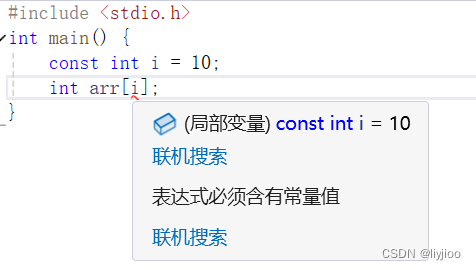 如图,const不能使用
如图,const不能使用
iii)define修饰的标识符常量
只需要四步# define 名 值
不需要=号或者是;号
iiii)enum枚举常量:编程时有时想让一个变量的值只在规定范围里取值,那么就会考虑使用enum类型。
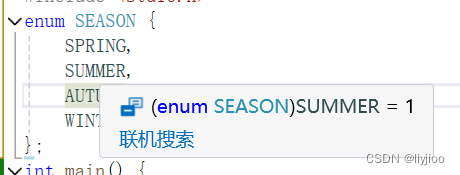 1)每个枚举常量都代表一个数
1)每个枚举常量都代表一个数
 还可以使用等号来给常量赋初始值
还可以使用等号来给常量赋初始值
后面的常量序号就延续着被修改的常量继续编号,但是赋值是不被允许的
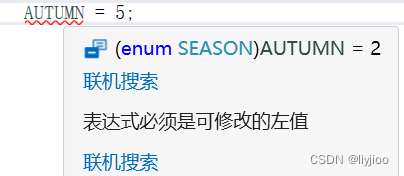
2)书写规范:里面是,号,外面是;号。
 3)可以创建该枚举的变量,变量值可以修改,但是只能修改为枚举内的元素,而且里面每个值对应的常数是不能修改的,如图:
3)可以创建该枚举的变量,变量值可以修改,但是只能修改为枚举内的元素,而且里面每个值对应的常数是不能修改的,如图:

4)define定义标识符常量和enum枚举的区别
1.枚举增强代码的可读性和可维护性(集中在枚举括号中)
2.枚举有类型检查,更严谨
3.放置命名污染,对于常量使用define可能会有重复,但是枚举封装了不会重复
4.便于调试,define在预编译阶段就被替换,但是枚举不会,所以在调试时define的与你看到的不一样,但是枚举还是枚举
5.方便使用,一次可以定义多个常量
5)大小通常是4
一旦超出4的范围
6.字符串操作
1)字符串的创建:
两种方法:
#include <stdio.h>
int main() {
char arr1[] = "abc";
char arr2[] = { 'a','b','c' };
printf("%s", arr2);
return 0;
}![]()
输出如上图,说明第二种方法有缺陷,读取了abc之后没停下来,那么就是说明在字符串中,有一个终止符可以用来表示字符串读取到底了,即‘\0’。
所以当把第二个改为
char arr2[] = { 'a','b','c' ,0};![]() 这样就能正常输出了
这样就能正常输出了
2)字符串大小的计算sizeof/strlen
i)strlen计算字符串到达0处时的大小,但是不包括0
#include <stdio.h>
int main() {
char arr1[] = "abc";
char arr2[] = { 'a','b','c' };
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
return 0;
} 从最终的答案可以看出,在计算有0的字符串中,例如abc就是获得3个字符,但是0在c之后但是不算进去
从最终的答案可以看出,在计算有0的字符串中,例如abc就是获得3个字符,但是0在c之后但是不算进去
42出现其实是一个随机值,创建的字符后面是一系列未初始化的内存区域,这些未初始化的内存区域可能包含任何值,这些值取决于之前的内存使用情况和内存分配器的实现。当strlen找到0就会停止。
当我修改完arr2之后,写为
char arr2[] = { 'a','b','c' ,0};之后
 就能获取正确值3
就能获取正确值3
ii)sizeof计算数组长度,也就是说假设有0就包括0
#include <stdio.h>
#include<string.h>
int main() {
char arr1[] = "abc";
char arr2[] = { 'a','b','c'};
printf("%d\n", sizeof(arr1));
printf("%d\n", sizeof(arr2));
return 0;
} 第一个4说明还包括0
第一个4说明还包括0
正因将字符串看成数组,所以
这样也是能访问到最后一个0。
iii)如果题目说长度,那么就直接看成sizeof
char acX[]=“abc”;
char acY[]={'a','b','c'};
以下说法正确的是()
题目内容:
A.数组acX和数组acY等价
B.数组acX和数组acY的长度相同
C.数组acX的长度大于数组acY的长度
D.数组acX的长度小于数组acY的长度
答案是C,由图可见acX是4,acY是3
例题:


 这里面需要注意,strlen的参数是指针而不是数值,所以第三条解引用后'a'为97,97是不可访问的内存,所以报错。传入的地址是整个数组的话是数组指针,而strlen需要传入字符指针,但使用const char*来接受char(*p)[7]会报警告但不会报错。演示如下:
这里面需要注意,strlen的参数是指针而不是数值,所以第三条解引用后'a'为97,97是不可访问的内存,所以报错。传入的地址是整个数组的话是数组指针,而strlen需要传入字符指针,但使用const char*来接受char(*p)[7]会报警告但不会报错。演示如下:


如果不使用数组,使用指针,那么sizeof怎么操作都不会影响到整个数组,而是一直在操作这个指针。
 对指针取地址,什么时候结束strlen就看其内存,什么时候有0什么时候结束。
对指针取地址,什么时候结束strlen就看其内存,什么时候有0什么时候结束。
 此处的a是首行地址而不是首行元素(首元素地址),所以a+1跳到第二行去了,与1不同(1是数组名,这里是数组地址),可以一起记忆。
此处的a是首行地址而不是首行元素(首元素地址),所以a+1跳到第二行去了,与1不同(1是数组名,这里是数组地址),可以一起记忆。

iiii)strlen的实现
strlen就是计算字符串的长度 ,直到计算到0且不包括0,所以可以使用while循环
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int my_strlen(char* ptr) {
int count = 0;
while (*ptr != '\0') {
count++;
ptr++;
}
return count;
}
int main() {
char* str = "abcdef";
printf("字符串的长度为%d", my_strlen(str));
return 0;
}除了这种计数器方法,还可以使用递归方法。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
int my_strlen(char* ptr) {
if (*ptr != '\0')
return 1 + my_strlen(++ptr);
else
return 0;
}
int main() {
char* str = "abcdef";
printf("字符串的长度为%d", my_strlen(str));
return 0;
}根据以往学过的指针运算,也能用末尾指针减去首元素指针来获取长度
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
int my_strlen(char* ptr) {
char* ptr_pre = ptr;
while (*ptr != '\0') {
ptr++;
}
return ptr - ptr_pre;
}
int main() {
char* str = "abcdef";
printf("字符串的长度为%d", my_strlen(str));
return 0;
}iiiii)sizeof的返回值size_t
![]()
size_t是一个无符号整形,所以这个类型的数值是没有正负的,假设我想比较两个字符串的长度,就不能使用加减法,这是因为加减法无论怎么加减都是只有正数(因为这个数值的类型是无符号整形),只能用大于小于这些比较操作符,但如果是自己实现strlen就可以使用int类型,这样就也能使用加减法来确定两个字符串的大小了。
3)字符串赋值strcpy
由于字符串是不可修改的左值,所以字符串不能直接使用=号来赋值,但是可以通过strcpy(原字符串,现字符串)来进行赋值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char arr1[] = "abc";
printf("%s\n", arr1);
strcpy(arr1, "def");
printf("%s\n", arr1);
return 0;
} 结果如图。
结果如图。
4)字符串比较strcmp
#include <stdio.h>
#include<string.h>
int main() {
char a[] = "abc";
char b[] = "abc";
printf("%d", a == b);
return 0;
}![]() 输出的却是0,说明==比较的不是字符串的内容,而是比较字符串的其他特征。在C语言中,字符串通常是以数组或者字符指针存在,所以比较的时候是以地址为依据进行比较,例如以下代码:
输出的却是0,说明==比较的不是字符串的内容,而是比较字符串的其他特征。在C语言中,字符串通常是以数组或者字符指针存在,所以比较的时候是以地址为依据进行比较,例如以下代码:
#include <stdio.h>
#include<string.h>
int main() {
char *a = "abc";
char *b = "abc";
printf("%d", a == b);
return 0;
}像这样的代码返回的就是1即真了,因为这两个指针同时指向同一个字符串。
但当我们想要进行内容的比较时,我们就要使用到strcmp来比较。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char a[] = "abc";
char b[] = "abc";
printf("%d", strcmp(a,b));
return 0;
}输出0,因为两者相等。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char a[] = "bbc";
char b[] = "abc";
printf("%d", strcmp(a,b));
return 0;
}输出1,因为前面比较大,同理,当前面比较小的时候,输出-1,如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char a[] = "Abc";
char b[] = "abc";
printf("%d", strcmp(a,b));
return 0;
}当然,1和-1都是在Visual Studio内的显示,当使用其他编译器时,会出现正数和负数。
5)字符串在数组和指针使用时的区别
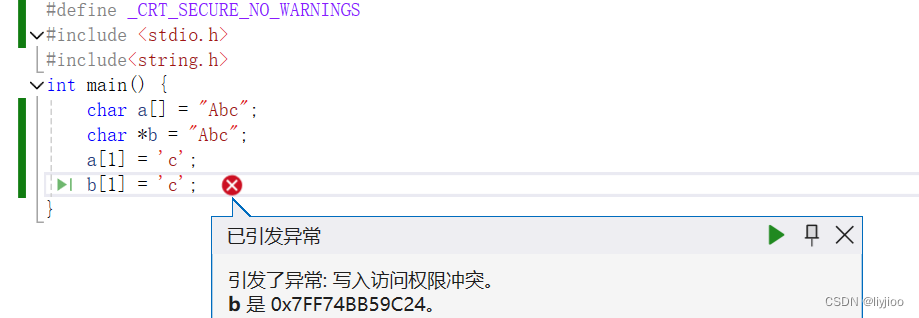
可见,数组是可以修改,但是一旦用在了指针就是修改字符串了,但是字符串创建后就不能修改。
6)getchar输入字符和putchar输出字符
1.getchar相关注意点
1)当getchar输入的是字符,所以打印的时候使用%d会输出ASCII值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int ch = getchar();
printf("%d\n", ch);
return 0;
}假设输入1,输出的是49,即字符1的ASCII值。
2)当getchar输入多个字符,只读取第一个字符,其他字符保留在输入缓冲区,等待下一次读取。
但是假设输入10,使用如下代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int ch = getchar();
printf("%d\n", ch);
ch = getchar();
printf("%d\n", ch);
ch = getchar();
printf("%d\n", ch);
return 0;
}会发现输入一个10,直接弹出三条输出,如图:
 输入1个10,getchar一个个从缓冲区读取,于是分了三次输入,输入的数据分别是‘1’,‘0’,‘\n’。
输入1个10,getchar一个个从缓冲区读取,于是分了三次输入,输入的数据分别是‘1’,‘0’,‘\n’。
利用这个能从缓冲区读取数据的性质,我们可以用来读取一片数据,直到读取到缓冲区末尾。
3)while循环持续读取数据,直到遇到EOF或是等价于EOF的操作(Windows中的ctrl+z)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char ch;
while ((ch = getchar())!=EOF) {
printf("%c", ch);
}
return 0;
}如图代码可以不断在输入缓冲区读取数据直到缓冲区为空,等待下一次输入,然后一直读取,如此循环,最后读入EOF才停止。
4)缓冲区为空≠文件读到EOF
用户输入数据到输入缓冲区,当遇到回车等结束符之后,数据会通过相应输入函数读取到程序中
 当然,这里的EOF并不是我们所指的英文EOF,而是文件结束符,这个符号需要按下特定的键(如Ctrl+D在Unix和Linux系统上,或者Ctrl+Z在Windows上,然后回车)来实现的。
当然,这里的EOF并不是我们所指的英文EOF,而是文件结束符,这个符号需要按下特定的键(如Ctrl+D在Unix和Linux系统上,或者Ctrl+Z在Windows上,然后回车)来实现的。
 Windows系统上如图。
Windows系统上如图。
5)易错点:不要写为while (ch = getchar()!=EOF)
根据赋值和比较运算符的优先级,这样回先使用EOF比较,返回0或1,然后这个赋值给ch,引发错误。
6)EOF实际上是-1,而不是0(字符串末尾)
 如图是在文件中的EOF的define定义。
如图是在文件中的EOF的define定义。
7)与之有相似作用的scanf在读取非字符时会略过空格,在读取字符时会读取空格,但在读取字符会读取换行符或者空格。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int num;
char ch;
scanf("%d", &num);
ch = getchar();
printf("ch读取了换行符");
return 0;
}该代码读取完数字之后会立刻getchar读取缓冲区多余的换行符,直接输出ch读取了换行符。
具体应用场景如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char password[20] = { 0 };
printf("请输入密码>>");
scanf("%s", password);
printf("确认密码?Y/N>>");
if (getchar() == 'Y')
printf("\n设置密码成功");
else
printf("\n退出密码设置");
return 0;
}如图是输入密码的代码,用户输入密码之后还有确认的选项,但是此时scanf会略过换行符,所以换行符直接被getchar读取,引发错误。
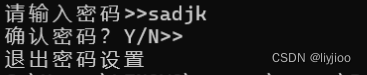 如图直接退出密码设置。
如图直接退出密码设置。
所以我们可以加上getchar来读取缓冲区数据。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char password[20] = { 0 };
printf("请输入密码>>");
scanf("%s", password);
printf("确认密码?Y/N>>");
getchar();
if (getchar() == 'Y')
printf("设置密码成功");
else
printf("退出密码设置");
return 0;
}  如图代码就能消除这个bug。
如图代码就能消除这个bug。
但是用户要输输入一堆空格再回车,这样还是会导致scanf读取到空格就结束,最后出现错误。
![]() 如图输入的是sadsdsq(空格)(回车)
如图输入的是sadsdsq(空格)(回车)
所以可以使用while和getchar来清空缓冲区。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char password[20] = { 0 };
printf("请输入密码>>");
scanf("%s", password);
printf("确认密码?Y/N>>");
while (getchar() != '\n') {
continue;
};
if (getchar() == 'Y')
printf("设置密码成功");
else
printf("退出密码设置");
return 0;
}这样就能将密码输入到数组中并且成功运行程序。
但是实际上这样的代码还是有些不足:例如对于密码之间有空格就直接不读取了,而且没有和用户交互,所以可以作如下代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i = 0;
char password[20] = { 0 };
printf("请输入密码>>");
scanf("%s", password);
while (i++,getchar() != '\n') {
if (i >= 2) {
printf("密码中不能包含空格");
return 0;
}
continue;
};
printf("确认密码?Y/N>>");
if (getchar() == 'Y')
printf("设置密码成功");
else
printf("退出密码设置");
return 0;
}  这样即可解决问题
这样即可解决问题
这段代码中易错点是:使用getchar() != '\n'发现不是\n之后就退出循环,但此时已经读取过\n了,所以不需要后面再加一个getchar再读取\n了。
2.gets和puts和fgets
1)char *gets(char *str)读取缓冲区字符到目标字符数组
但需要注意的是,gets由于其输入没有缓冲区保护(输入数据的大小可能超出数组大小,从而引发错误),并且不会对输入的字符串末尾加上0,留下了悬挂的字符串(即没有正确终止的字符串),所以已被废弃。
返回值是指针指向读取到的指针,如果读取失败返回NULL。
2)char *fgets(char *str, int n, FILE *stream);读取输入流stream的指定长度n大小的字符串到字符数组中str,所以可以从后往前记忆。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char arr[10] = { 0 };
fgets(arr, 5, stdin);
printf("%s", arr);
return 0;
}这里需要了解这个第二个参数n的意义,n就代表包括0的数组大小,也就是说这段代码的5就是指读取4个字符,然后在末尾加上个0。
 如图。
如图。
返回值是指针指向读取到的指针,如果读取失败返回NULL。
3)int puts(const char *str)用于从某字符串输出到标准输出流。
这里的int表示如果返回非负数为成功,返回EOF为读取失败
put系列只有puts会默认换行
7)反转字符串
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
void reverse(char* ptr) {
int str_len = strlen(ptr);
char* left = ptr;
char* right = ptr + str_len - 1;
while (right > left) {
*left = *left ^ *right;
*right = *left ^ *right;
*left = *left ^ *right;
left++;
right--;
}
}
int main() {
char arr[20];
printf("请输入字符串");
scanf("%s", arr);
reverse(arr);
printf("%s", arr);
return 0;
}反转字符串就是使用左右指针互换,但是这样使用scanf就不能读取空格了如下:

所以不使用scanf但用gets,就能解决这个问题
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
void reverse(char* ptr) {
int str_len = strlen(ptr);
char* left = ptr;
char* right = ptr + str_len - 1;
while (right > left) {
*left = *left ^ *right;
*right = *left ^ *right;
*left = *left ^ *right;
left++;
right--;
}
}
int main() {
char arr[20];
printf("请输入字符串");
gets(arr);
reverse(arr);
printf("%s", arr);
return 0;
}
8)常见字符串函数
1.长度不受限制但受'\0'限制的字符串函数
1)strlen函数计算字符串长度
代码实现 :
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
char* my_strcpy(char* dest,const char* src){
assert(dest != NULL);
assert(src != NULL);
char* ptr = dest;
while(*dest++ = *src++){}
return ptr;
}
int main() {
char arr1[] = "abcdef";
char arr2[] = "hello";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}该函数要注意,函数的结束条件是*src==0,所以假设src指向字符串内部没有’\0’,就会导致越界访问,
目标字符串也要足够大,不然也会越界
目标空间要可以修改,假如使用char* p =”abcdef”,这样字符串是不能被修改的。
2)strcat追加字符串
代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
char* my_strcat(char* dest,const char* src){
assert(dest && src);
char* ptr = dest;
while(dest++,*dest){}
while(*dest++ = *src++){}
return ptr;
}
int main() {
char arr1[] = "abcdef";
char arr2[] = "hello";
my_strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
}
由图,可知追加是先找到第一个字符串的0位置,然后向后追加第二个字符串,第二个字符串的0也会被追加过来。
该函数要注意,第一二个字符串都要有0,不然程序无法停止,
第一个参数要足够大能容纳两个字符串
3)strcmp字符串比较
代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
char* my_strcmp(char* ptr1,char* ptr2){
assert(dest && src);
while (*ptr1 == *ptr2) {
if (*ptr1 == 0)
return 0;
ptr1++;
ptr2++;
}
if (*ptr1 > *ptr2)
return 1;
else
return -1;
}
int main() {
char arr1[] = "abcdef";
char arr2[] = "abcdef";
printf("%d\n",my_strcmp(arr1, arr2));
return 0;
}判断两字符串的大小关系(str1,str2),如果str1大于str2就返回大于0的数字,在VS里返回1,其他入gcc编译器不一定,所以判断为了更通用,不能用1/-1/0来作为判断条件,如果想返回负数或正数就是简单的相减。
2.长度不受0限制的字符串函数
1)strncpy拷贝字符串,第三个参数用来限制拷贝的个数
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
int main() {
char arr1[] = "abcdef";
char arr2[] = "abasd";
strncpy(arr1, arr2, 4);
printf("%s\n",arr1);
return 0;
}如上代码拷贝arr2到arr1,输入第三个字符用于表示拷贝的个数,需要注意的是,假设第三个参数小于第二个字符串的大小,那么’\0’不会被赋值过去,但假设大于,那多出来的空间全部填上0
2)strncat拼接字符串,第三个参数限制拷贝的字符数
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
int main() {
char arr1[] = "ab\0cdef";
char arr2[] = "abasd";
strncat(arr1, arr2, 2);
printf("%s\n",arr1);
return 0;
}上述代码的结果是abab,因为strncat指定了赋值的个数是2之后,便会把arr2中的两个字符插入到arr1的0之后,并且带上0(这是与strcpy不同的,strcpy是不带上0的),假设第三个参数大于arr2的大小,那么后面的全部省略(这也是与strcpy不同的,strcpy是全部赋值为0,具体证明如下图:)


3)strcmp字符串比较,这样的比较可以指定大小。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
int main() {
char arr1[] = "abcdef";
char arr2[] = "az";
printf("%d\n",strncmp(arr1, arr2, 1));
printf("%d\n", strncmp(arr1, arr2, 2));
printf("%d\n", strncmp(arr1, arr2, 3));
return 0;
}结果分别是0,-1,-1,所以strncpy就是比较指定大小,假设超出指定大小就是正常的strcmp的效果。
3.其他字符串函数
1)strstr取字串
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<assert.h>
char* my_strstr(char* ptr1,char* ptr2) {
assert(ptr1 && ptr2);
char* s1 = ptr1;
char* s2 = ptr2;
if (*ptr2 == '\0')
return ptr1;
while (*ptr1) {
s1 = ptr1;
s2 = ptr2;
while (*s1 == *s2 && *s1 != 0 && *s2 != 0) {
s1++, s2++;
}
if (*s2 == 0)
return ptr1;
ptr1++;
}
return NULL;
}
int main() {
char arr1[] = "abcdef";
char arr2[] = "cd";
printf("%s\n", my_strstr(arr1, arr2));
return 0;
}strstr找字串是匹配第一个出现的位置而不是后面的
 2)strtok使用指定分隔符拆分字符串
2)strtok使用指定分隔符拆分字符串
char* strtok(char* str,const char* sep)
sep参数是个字符串,定义了用作分隔符的字符集合
例如:
char arr[] = "abc.def.ghi@xyz";
char* sep = ".@";将arr中的分割符改为0,并返回这一段字符串的地址,例如上述代码,将第一个分隔符.改为\0,并返回a的地址。下一次调用时,会根据上一次记录的.(改为0)后开始,并继续寻找分隔符,直到找到0,返回最后一个字串的首字符地址。
第一个参数传入数组,就从数组起始位置找第一个标记并保存位置,第一个参数传入NULL,strtok将在统一字符串被标记位置开始查找下一个标记。


由于strtok会修改原字符串,所以可以使用拷贝来避免影响原字符串。
如果字符串中不存在更多标记,则返回NULL
对于重复出现的分隔符,strtok会把这些分隔符全变为0,即当作同一个分隔符
根据上述的性质,我们就能使用for循环获得每一份分割的字串。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
#include<assert.h>
int main() {
char arr[] = "abc.@.def.ghi@xyz";
char* sep = ".@";
for (char* subs = strtok(arr, sep); subs != NULL; subs = strtok(NULL, sep)) {
printf("%s\n", subs);
}
return 0;
}
3)strerror 获得错误码对应的错误信息
可以配合errno.h头文件的全局变量errno来输出错误,C语言库函数执行过程中发生错误就会把错误码传到errno中,即char* p = strerror(errno)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<stdlib.h>
#include<string.h>
#include<errno.h>
int main() {
FILE* pf = fopen("text.txt", "r");
if (pf == NULL)
printf("%s\n", strerror(errno));
return 0;
}最后会输出报错信息 No such file or directory
4)is...判断字符类型
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char a = '1';
printf("%d\n", isdigit(a));
return 0;
}返回非0就代表判断正确。
 5)字符互换
5)字符互换
包括toupper和tolower
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
int main() {
char a[] = "hello world";
a[0] = toupper(a[0]);
printf("%s\n", a);
return 0;
}这两个函数只能一次修改一个字符
6)strcpy等字符串操作函数有局限性,mem操作如下:
 如图,如果想要拷贝非字符串的数据,可能会遇到0直接退出赋值了,这里的数组1是01 00 00 00 ,拷贝完第一个1后0就直接终止了strcpy函数,最后只能拷贝出一个1
如图,如果想要拷贝非字符串的数据,可能会遇到0直接退出赋值了,这里的数组1是01 00 00 00 ,拷贝完第一个1后0就直接终止了strcpy函数,最后只能拷贝出一个1
这里就需要使用内存拷贝memcpy
 具体实现是使用void*转为char*
具体实现是使用void*转为char*

但如果前往后找,dest在src后面且覆盖就会出现错误
如果后往前找,dest在src前面且覆盖也会出现错误
所以存在重合的区域时,memcpy就可能不能完美地处理,但是VS2022优化了,memcpy也会自主选择前后赋值, C语言标准规定,memcpy只需要处理不重叠的拷贝就行,memmove要处理重叠

所以分界点是src和dest的位置关系,先前往后,再后往前
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<assert.h>
#include<string.h>
void* my_memmove(void* dest, const void* src, int num) {
assert(dest && src);
if (dest < src) {
while (num--) {
*((char*)dest)++ = *((char*)src)++;
}
}
else {
while (num--) {
*(((char*)dest)+num) = *(((char*)src)+num);
}
}
}
int main() {
int arr1[] = { 1,2,3,4,5,6,7,8,9,0 };
my_memmove(&arr1[3], arr1, 6 * sizeof(int));
for (int i = 0; i < sizeof(arr1) / sizeof(arr1[0]); i++) {
printf("%3d", arr1[i]);
}
return 0;
}memcpy比较
 memset初始化
memset初始化

7.C语言中的注释
i)C语言的注释方法是\* 一系列代码*\
例如如图计算阶乘的代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
printf("请输入阶乘的n");
int choice = 0;/*获取用户选择*/
int sum = 0;
scanf("%d", &choice);
printf("您的选择是>>%d\n",choice);
if (choice <= 0) {
printf("输入n太小,请重新输入");
}
for (int i = 1; i <= choice; i++) {
sum += i;
}
printf("阶乘的结果是%d", sum);
}需要注意的是,一个开口配上两个闭口,这个注释会和最近的闭口组合,例如
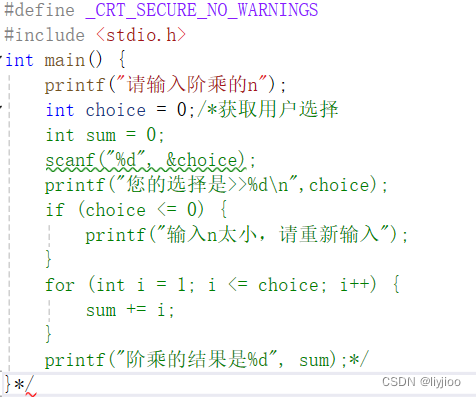 这段代码中最下面的*/报错了,这说明注释只与最近的*/组合。
这段代码中最下面的*/报错了,这说明注释只与最近的*/组合。
ii)C++中引入了单行注释,并且部分C语言中也引入了单行注释。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
printf("请输入阶乘的n");
int choice = 0;//获取用户选择
int sum = 0;
scanf("%d", &choice);
printf("您的选择是>>%d\n",choice);
if (choice <= 0) {
printf("输入n太小,请重新输入");
}
for (int i = 1; i <= choice; i++) {
sum += i;
}
printf("阶乘的结果是%d", sum);
}8.常见难理解关键字
1)auto表示使用完就删除,多用于局部变量的生命周期。
例如int的局部变量正常应当写作 auto int a = 10;
但是正常的局部变量的就是在生命周期结束后删除,所以auto可以不写。
2)register将变量放入寄存器中。
对于寄存器,在百度百科中是这样描述的:
寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。
在计算机领域,寄存器是CPU内部的元件,包括通用寄存器、专用寄存器和控制寄存器。寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
可见,寄存器拥有非常高的读写速度,但相应的他的存储区域也就小了。
除了寄存器是存储的硬件,还有高速缓存,内存(变量默认放在内存),硬盘 ,他们的运行速度依次降低,但是存储空间依次增加。并且CPU运算时,先在寄存器中查找,若是没有查找到,就不断向下查找直到找到待运算的数据。
同时,在代码中写上register int a = 10;这个a也不一定会存放到寄存器中,具体能不能放在寄存器中还是会由编译器决定。
i)变量默认存储至内存
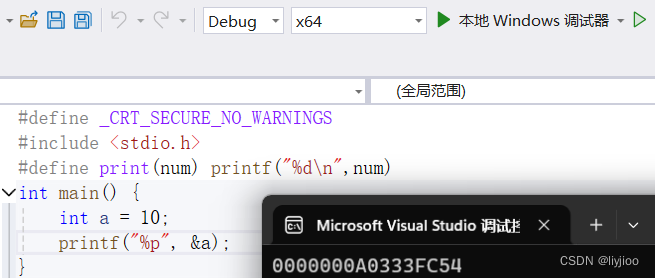
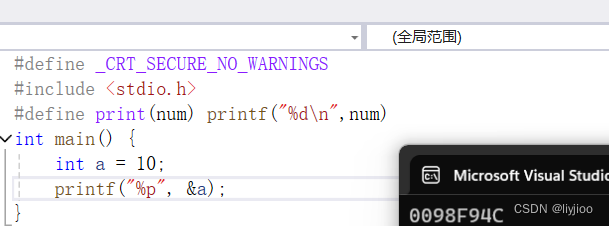
1)内存与位数的关系:
例如32位计算机,表示有32根地址线,那么32个地址线都0/1两种状态,组合起来就有2^32种可能,根据二进制转十六进制,每四位组成一位十六进制,所以32/4=8,在32位计算机下,使用%p输出的地址一般是8位,同理,64位下是16位。(在不考虑任何特定输出格式或平台差异的情况下)
如下图为64位下:
如下图为32位下:
2)内存单元
每个内存单元是1个字节
对于32位系统:
- 地址总线的宽度是32位,即可以表示2^32个不同的地址。
- 每个地址对应1字节的内存,所以32位系统理论上可以寻址的最大内存是 2^32 字节。
- 转换成GB,我们知道1GB = 230 字节,所以 232 字节 = 22 * 230 字节 = 4GB。
对于64位系统:
- 地址总线的宽度是64位,即可以表示2^64个不同的地址。
- 每个地址对应1字节的内存,所以64位系统理论上可以寻址的最大内存是 2^64 字节。
- 转换成GB,264 字节 = 234 * 230 字节 = 16 * 10244 GB,这是一个非常大的数字,远超过目前实际可用的内存容量。
虽然64位的内存容量很大,但目前市场上的主流内存条容量通常从几GB到几十GB不等,而主板上的内存插槽数量也有限,因此即使使用最大容量的内存条,实际可用的内存容量也远低于理论最大值。
3)内存解析方法
内存在解析的时候还需要与数据类型挂钩,例如我们使用上述的0098F94C这个内存,它实际上只是指一个内存单元,但是我们如果写上这个内存存储的数据是int类型,那么解析的时候就会解析4个字节的内存单元即0098F94C和0098F94D和0098F94E和0098F94F四个内存地址。即获取的内存实际上是起始点,但是具体内存的多少还需要看数据的类型是什么。
3)unsigned和signed
分别是无符号和有符号,对于int a = 10;实际上可以写作signed int a = 10;对于无符号整形,只能存入正数。
但是如果将负数存入无符号整形,编译器会发生截断
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
unsigned char a = -1;
printf("%u", a);//11111111 11111111 11111111 11111111
//截取最低8位 11111111
//所以打印出来的a是11111111 即255,最高位并不被视作符号位
return 0;
}如图,截取了最低的8位,并且无符号最高位不当作符号而当作数值。
所以两者最大的区别就是符号位的有无导致的存储空间的不同,并且有符号是以补码形式存放的,无符号是以原码的二进制形式直接存放的。
4)struct结构体
i)概念
结构是一些值的集合,其中的值被称为成员变量。
结构体的写法是struct 名称{...;...;...;...}variable1,variable2...;即中间分号外面也分号,这与原本的枚举enum是不同的,enum中间逗号,外面分号。variable list代表变量列表,这里创建的变量是全局变量。但出于模块的程序的模块性、可维护性和可测试性,最好少用全局变量。参数列表是逗号隔开。
typedef struct name1{
member list
} name2
使用typedef,可以在以后直接使用name2创建,也可以直接使用struct name1创建。
ii)结构体创建方法
使用.属性=xxx或者直接按顺序初始化都可以。
#include <stdio.h>
struct Person {
char name[50];
int age;
float height;
};
int main() {
//初始化方法一
struct Person person = {
.name = "Alice",
.age = 30,
.height = 5.6f
};
printf("Name: %s, Age: %d, Height: %.2f\n", person.name, person.age, person.height);
// 初始化方法2
struct Person person2 = { "Bob", 25, 5.9f };
printf("Name: %s, Age: %d, Height: %.2f\n", person2.name, person2.age, person2.height);
return 0;
}当遇到嵌套结构体时,初始化方法如下:
可以使用.属性逐个赋值:
#include <stdio.h>
typedef struct {
int age;
char name[50];
} Person;
typedef struct {
Person details;
float height;
} Student;
int main() {
// 初始化Student结构体,其中details是Person结构体
Student s = {
.details = {
.age = 20,
.name = "John Doe"
},
.height = 1.75f
};
printf("Age: %d, Name: %s, Height: %.2f\n", s.details.age, s.details.name, s.height);
return 0;
}也可以使用多层{}来赋值:
#include <stdio.h>
typedef struct {
int age;
char name[50];
} Person;
typedef struct {
Person details;
float height;
} Student;
int main() {
// 初始化Student结构体,其中details是Person结构体
Student s = {{20,"John Doe"},1.75f};
printf("Age: %d, Name: %s, Height: %.2f\n", s.details.age, s.details.name, s.height);
return 0;
}iii)结构体的定义不占用内存,但是创建占用内存
#include <stdio.h>
// 定义一个结构体,定义不会占用内存
struct Person {
char name[50];
int age;
float height;
};
int main() {
// 创建一个结构体变量,此时会占用内存
struct Person person1;
// 初始化结构体变量
strcpy(person1.name, "Alice");
person1.age = 30;
person1.height = 5.6;
// 输出结构体变量的内容,验证其已占用内存并存储了数据
printf("Name: %s, Age: %d, Height: %.2f\n", person1.name, person1.age, person1.height);
return 0;
}iiii)结构体传参,首选指针传参
因为:函数传参时,参数需要压栈,如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致性能的下降
如图:
iiiii)匿名结构体
实际上就是省略去结构体名,如:
struct {
int num;
char name[10] ;
}x;
但匿名结构体在改变指针指向,从一个匿名结构体类型指向另一个匿名结构体类型时会报警告,因为无法写出结构体的类别,所以无法强制类型转换。
iiiiii)typedef重命名在结构体中不能调用重命名的名字,而是使用struct tag来作为类型
例如typedef struct node{...;struct node ...}Node而不是typedef struct node{...;Node ...}Node
iiiiiii)结构体={0}将结构体每个成员变量赋初始值0

iiiiiiii)结构体的内存对齐
假设某结构体有三个变量,分别是char,int,char,
1)结构体内存对齐的规则
- 第一个成员放在结构体地址偏移量为0的地址处
- 其他成员要放置在对齐数整数倍的位置(对齐数是编译器(VS是8)默认对齐数和该成员大小的最小值)
- 结构体的总大小是最大对齐数的整数倍

结构体嵌套结构体,需要注意结构体大小可能会超过默认偏移量,此时就使用默认偏移量来偏移
例如:
S2的大小为8+1+3(舍弃)+4 = 16
S3的大小为1+7(舍弃)+16+8=32(32为最大偏移量8的倍数)
2)出现内存对齐的原因:
平台原因:并不是所有的硬件都能访问任意地址上的数据
性能原因:由于CPU访问内存时通常会以特定的块大小(如字长)为单位进行,如果数据没有对齐,CPU可能需要多次访问内存来获取完整的数据,这会导致性能下降。
所以,所以让占用内存小的数据尽量放在一起,这样能节省空间
3) 修改默认偏移量:
 4)获取偏移量
4)获取偏移量
修改默认偏移量:
使用stddef.h头文件中的offsetof(结构体,成员变量)
#include <stdio.h>
#include <stddef.h>
typedef struct {
int age;
char name[50];
float height;
} Student;
int main() {
Student s = {20,"John Doe",1.75f};
printf("%d",offsetof(Student,height));
return 0;
}
得到偏移量: ![]()
iiiiiiii)位段
1.位段就是为了节省空间
2.位段与结构体的区别:
1)位段的类型必须是整形类型如char,int,unsigned int等
2)位段成员名后要带上冒号和数值
3.位段的存储
int位段是以四个字节为单位,冒号后面的数值是bit,从上到下组合能容纳在四字节内就存放,放不了就重开四个字节,所以位段后面的数值大小不能大于32,即四字节
char位段是以一个字节为单位

如图,4字节就是32bit,2+5+10=17<32但17+30=47>32所以前三个成员放在第一个4个字节内,第四个成员放在第二个四个字节内,所以输出的是8,由于8也是4的倍数,所以结果就是8.
所以位段和结构体比起来就是多了一个可以在同个4/1字节(类型相同时)内放多个成员变量。
4.位段不能跨平台
 5.char位段在VS中的运用
5.char位段在VS中的运用
VS中字节数不够是低位向高位开辟,读取时高位向低位读取,对于超出比特长度的数字采用截断,获取低位
例如:


需要注意的是,位段假设没有写下大小默认就是该类型的最大内存,如:
 2的二进制是10,按照小端存储,10应该在低地址,但是图示在高地址处,所以应是第一个char a就等同于char a : 8;这样高地址向低地址存放
2的二进制是10,按照小端存储,10应该在低地址,但是图示在高地址处,所以应是第一个char a就等同于char a : 8;这样高地址向低地址存放
iiiiiiiii)易错点:
1)当结构体内有字符串类型的变量,不能直接使用等号赋值,需要使用strcpy来拷贝。
例如:
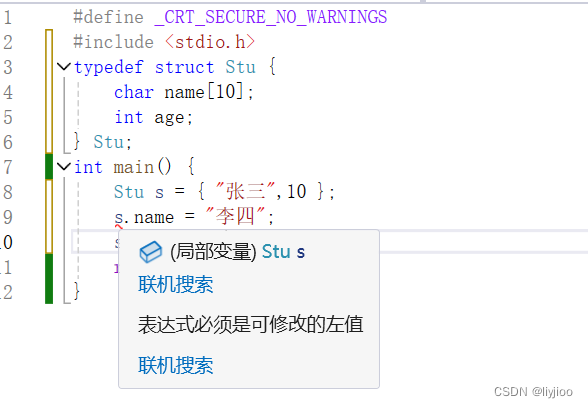
想要把该学生的名字改为李四, 但是由于字符串是不能修改的。
虽然可以一个个赋值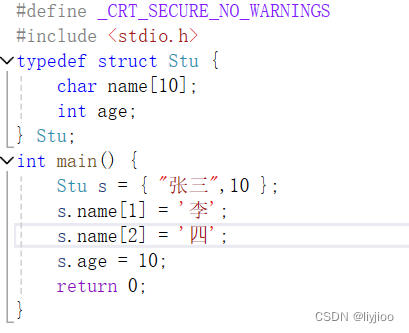
但是对于很长的名字(字符串)太难修改,所以可以使用strcpy,如下图:
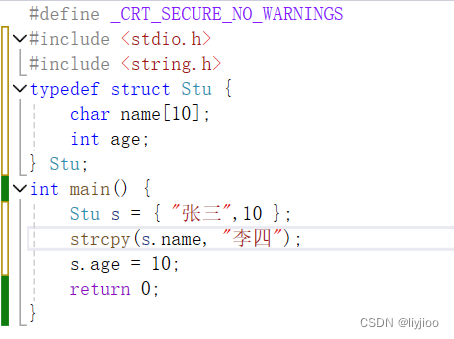 这样就可以对字符串修改。
这样就可以对字符串修改。
2)结构体想要有一个指向自身的指针的成员变量,必须写全
例如:
typedef struct node {
int data;
struct node* next;
}Node;中间的不能写成Node* next,因为编译器无法识别,必须写全struct node*。
5)union联合体
联合体也成为共用体
1.定义
内部元素共用空间
2.大小计算
#include <stdio.h>
union T {
char arr[5];
int num;
};
int main() {
printf("%d\n", sizeof(union T));
return 0;
}如上代码,由于arr大小为5,num大小为4,整个联合体的大小不能比成员最大值小,所以联合体的大小必须不能比5小,但是由于内存对齐,char的对齐数是1(虽然大小为5,但它是数组,对齐数是char的对齐数即1),int的对齐数为4,结构体大小为最大对齐数的整数倍,所以整个大小必须是4的倍数即8.
3.使用联合体可以很好地看是大端存储还是小端存储
#include <stdio.h>
union T {
char c;
int num;
}t;
void sys_test() {
t.num = 1;
if (t.c == 1)
printf("小端存储");
else
printf("大端存储");
}
int main() {
sys_test();
return 0;
}由于联合体共用一段存储空间,所以可以使用char和int的组合,先将int赋值为1,使用char取出int的最低位,最低位如果是1,那么就说明int的二进制低位就放在内存的低位上,也就是小端存储,否则就是大端存储。
6)typedef重定义,可以看作是别名
如改改的学生结构体,可以直接typedef重定义为别名Stu,在后来的初始化中,直接写Stu即可,不需要写struct Stu。
7)static增长生命周期,一次初始化,对于有全局属性的函数和变量,改变作用域。
对于局部变量,加上static,局部变量出了原来的生命周期外还是存在着,并且下一次进入函数就不再初始化该变量了。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
void test() {
int a = 1;
a++;
printf("%d\n", a);
}
int main() {
for (int i = 0; i < 5; i++) {
test();
}
return 0;
}该程序调用了5次test函数,但是函数在每一次进入和退出的时候a都被初始化和销毁,所以输出了五次2,如图:

为了a的每一次自增都被记录下来,可以加上static:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
void test() {
static int a = 1;
a++;
printf("%d\n", a);
}
int main() {
for (int i = 0; i < 5; i++) {
test();
}
return 0;
} 这下运行结果就是23456了,a只有在第一次输出2的那个时间被初始化吗,其他时候都是跳过,由于每次自增都是在其生命周期中,所以所得到的数值一直在增大。
这下运行结果就是23456了,a只有在第一次输出2的那个时间被初始化吗,其他时候都是跳过,由于每次自增都是在其生命周期中,所以所得到的数值一直在增大。
对于全局的函数和变量,使用static会减小他们的作用域为本文件。
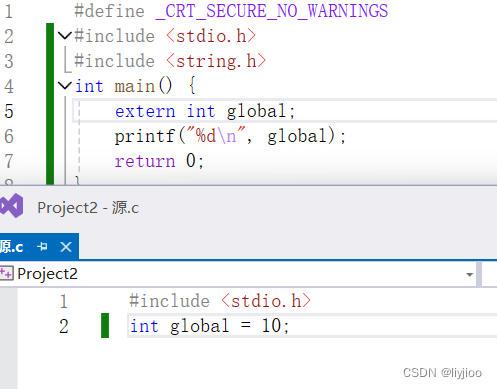 如果是正常使用extern是可以的
如果是正常使用extern是可以的
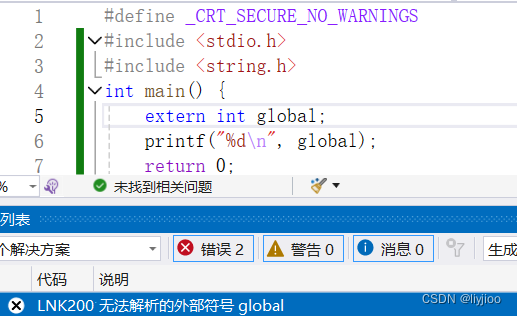 但使用static直接报错。
但使用static直接报错。
因为加上static作用域减小为本文件,外部文件访问不到。
函数也一样,使用extern 类 函数名(参数)即可使用,但是一旦加上static,函数的作用域也变为本文件。
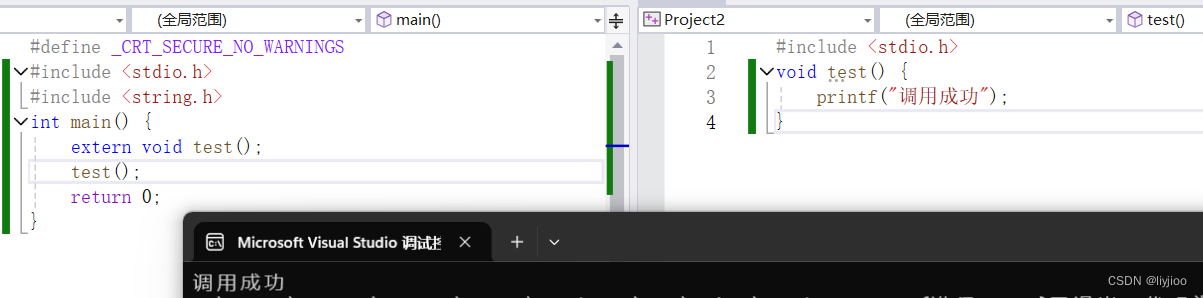
加上static后:
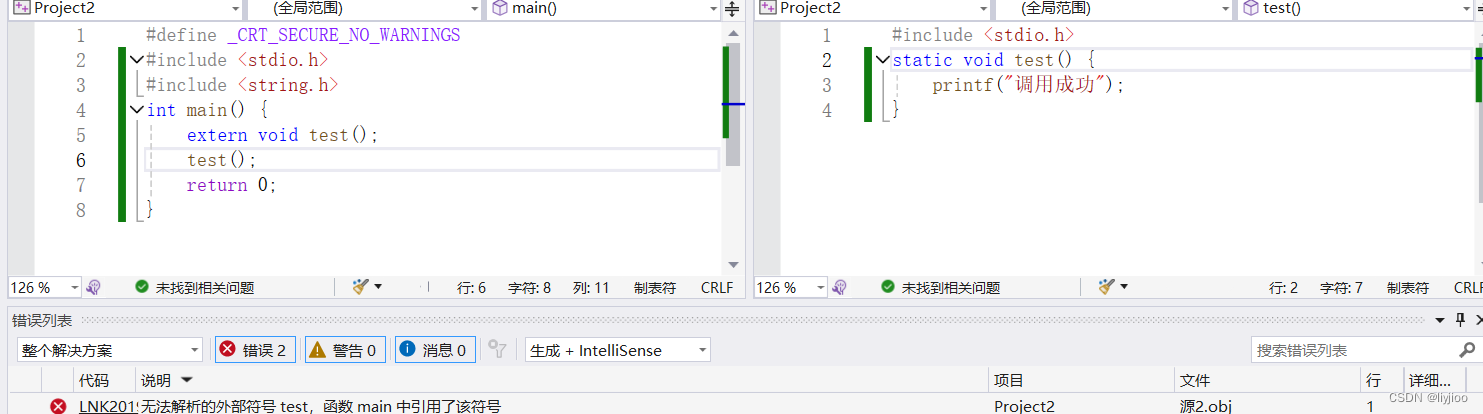
9.define定义宏和标识符常量
1)宏的概念:宏是一种在编译时期进行文本替换的机制。
宏也可以理解为带有参数(不需要写出类型)的文本替换。
举例如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define print(num) printf("%d\n",num)
int main() {
print(1);
}这样就能在控制面板中输出1。原因是在编译阶段,宏把print整个替换为printf("%d\n",1)所以就能打印出1。
10.C语言中的各类语句
1)语句的概念:在C语言中,分号隔开的一条是语句。
...
int a = 0;//有分号,算一条语句
;//有分号,也算一条语句,但是这条语句是空语句
...2)分支语句
i)if语句
1)if的判断语句不要写成连续的比较
例如计算年龄段的代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int age;
printf("请输入您的年龄,判断你的年龄段");
scanf("%d", &age);
if (0 <= age <= 17)
printf("未成年人");
else if (18 <= age <= 65)
printf("青年人");
else if (66 <= age <= 79)
printf("中年人");
else if (80 <= age <= 99)
printf("老年人");
else
printf("年龄输入有误");
return 0;
}这段代码一开始看可能没什么问题,但是运行起来如图:


会发现无论输入多少都是未成年人,这就是因为不能使用连续的比较,而是使用&&来连接多个判断。连续的判断是从左向右判断,对于0<=age先计算出正确所以为1,接下来就是1<=17这样无论如何都是正确的,所以会导致什么情况都是未成年人。所以可以写作0<=age&&age<=17;完善后的代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int age;
printf("请输入您的年龄,判断你的年龄段");
scanf("%d", &age);
if (0 <= age && age <= 17)
printf("未成年人");
else if (18 <= age && age <= 65)
printf("青年人");
else if (66 <= age && age <= 79)
printf("中年人");
else if (80 <= age && age <= 99)
printf("老年人");
else
printf("年龄输入有误");
return 0;
}
2)C语言中所有非零为真,0为假
3)if没写括号匹配if后面那个语句或代码块,else匹配最近的那个if
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
if (1)
if (2)
if (3)
printf("if语句没写括号匹配最近一行的代码块");
return 0;
}有输出就说明一层层if匹配下来,而不是只匹配一行,也有可能是块。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
if (1)
if (0){}
else
printf("匹配第二个if");
return 0;
}如果else与第一个if匹配,那么不输出,如果和第二个匹配就输出,结果是输出,所以else匹配最近的if。
4)return返回并终止函数
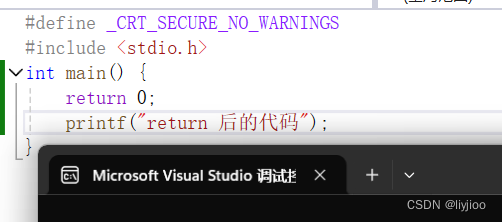 如图,return后的代码没有输出。
如图,return后的代码没有输出。
5)if中有赋值语句,返回值就是赋值的值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i;
if (i = 5)
printf("代码中i=5将5赋值给i,并返回5");
return 0;
}图示代码将5赋值给i,并返回5,if(5)为真,所以printf函数能够运行。
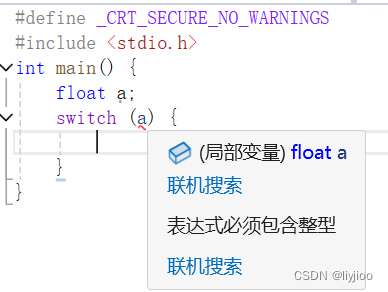
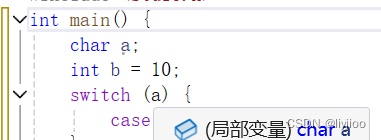
ii)switch语句
1)switch的括号中需要使用整形/字符表达式,case后需要使用整型常量表达式
如图,switch不能使用float等非整数元素
但是由于char类型实际上是ASCII码值即整数,所以char也能写在switch中。
在case中必须使用常量
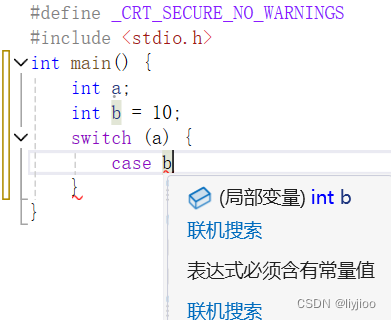
所以只要是常量,例如10+1也算是正确的语法格式

2)default可以写在switch任何地方,并且没有写break可能会产生贯穿(fall through)
#include <stdio.h>
int main() {
int number = 3;
switch (number) {
case 1:
printf("One\n");
break;
case 2:
printf("Two\n");
break;
default:
printf("Not one or two\n");
break;
case 3: // 尽管这里语法上正确,但逻辑上可能不是最佳实践
printf("Three\n");
break;
}
return 0;
}这段代码最后的结果是Three,这说明default可以写在任何地方,但是必须等case比较完才行。
case比较的顺序是 从前往后,而且没有break就会发生贯穿。
#include <stdio.h>
int main() {
int number = 3;
switch (number) {
case 3:
printf("Three\n");
case 1:
printf("One\n");
case 2:
printf("Two\n");
}
return 0;
}这段代码的结果是 ,可见代码因为没有break发生贯穿,后面的case也运行了
,可见代码因为没有break发生贯穿,后面的case也运行了
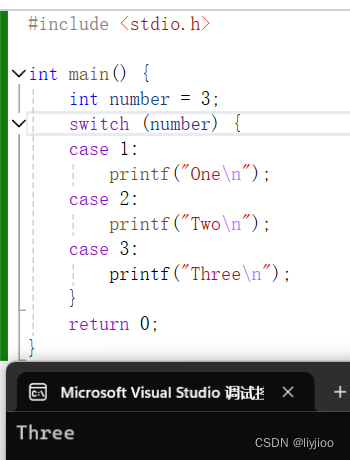 而我们一旦把3放后面,就算贯穿也只读取一个
而我们一旦把3放后面,就算贯穿也只读取一个
这说明case是从上往下判断的。
3)循环语句
i)while语句
1)while循环和continue共同使用时,需要判断while循环是否会陷入死循环。
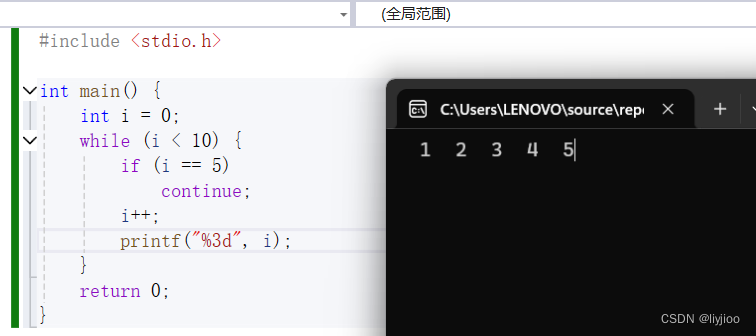
如图,i++在i等于5之后就不变了,陷入死循环。
ii)for循环
1)for循环要特别注意初始化的省略
给出如下代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i = 0;
int j = 0;
for (; i < 10; i++) {
for (; j < 10; j++) {
printf("输出%d\n",j);
}
}
return 0;
} 输出如图,总共只有10次输出,但是实际上两次10和10的循环应当是100次,这里却只有10次,
输出如图,总共只有10次输出,但是实际上两次10和10的循环应当是100次,这里却只有10次,
其实这是因为j自从第一次循环变为10,后面几次循环都不变了,就一直没法进入内循环,只有第一次i=0时打印了10次。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i = 0;
for (; i < 10; i++) {
for (int j = 0; j < 10; j++) {
printf("输出%d\n",i*10+j+1);
}
}
return 0;
}但只要我将j的每次初始化写到代码中,那么就会输出100次,如图:
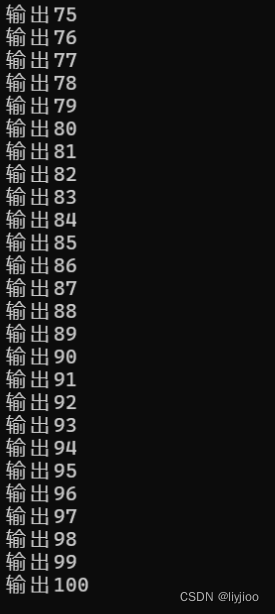 实际上for循环的每一个部分,如初始化部分,条件判断部分(如果判断省略就恒为真),迭代部分都是可以省略的,但是在省略时一定要看清楚是否会产生影响,如上面的去除初始化的例子。
实际上for循环的每一个部分,如初始化部分,条件判断部分(如果判断省略就恒为真),迭代部分都是可以省略的,但是在省略时一定要看清楚是否会产生影响,如上面的去除初始化的例子。
11.函数
1)分类
函数分为库函数和自定义函数,库函数有IO函数, 字符串操作函数,字符操作函数,内存操作函数,时间/日期函数,数学函数,其他库函数。
对于自定义函数,有以下注意点:
i)形参是实参的一份临时拷贝,对形参的修改不会改变实参
ii)数组传递时是指针,所以使用函数时也要传递数组大小
iii)对某个指针指定的元素自增不能写成*p++,因为++后置自增优先级高,会先将指针后移。
2)函数的定义/声明/调用方法:
定义:
返回类型 函数名(参数类型1 参数名1, 参数类型2 参数名2, ...) {
// 函数体
// ...
return 返回值; // 根据函数返回类型返回相应的值
}
声明:返回类型 函数名(参数类型1, 参数类型2, ...);
调用:函数名(参数1, 参数2, ...);
3)嵌套调用和链式调用
嵌套调用是指在一个函数中调用了另一个函数,链式访问是指把一个函数的返回值作为另一个函数的参数。
接下来是对较难理解的链式访问的举例:
...
printf("%d",printf("%d",printf("%d",43)));
...这段代码的最后输出是4321,因为printf函数实际上是有返回值的,返回值就是打印的字符个数,43打印出来是2个字符,所以下一个打印的是2,然后2是1个字符,所以最后一个打印的是1。
嵌套调用函数但不能嵌套定义函数
 如图可以在a中调用b
如图可以在a中调用b 但是不能在a中定义b
但是不能在a中定义b
4)函数多返回值的情况
假设我们需要将创建一个二维数组,且二维数组的值都是0,然后随机在二维数组中取一个点变为1,此时如果想要获得这个点的信息,需要返回横坐标和纵坐标,举例代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int find_1(int arr[5][5],int size) {
for (int j = 0; j < size; j++) {
for (int k = 0; k < size; k++) {
if (arr[j][k] == 1) {
return j;
return k;
}
}
}
}
int main() {
srand((unsigned int)time(NULL));
int arr[5][5] = { 0 };
arr[rand() % 5][rand() % 5] = 1;
printf("%d %d",find_1(arr, 5));
return 0;
}显而易见,这样的代码是错误的,首先返回值不能使用"%d %d"直接打印,其次使用两次return是不符合语法的的,在第一次的return后函数就退出了,根本没法进行下一个return操作。
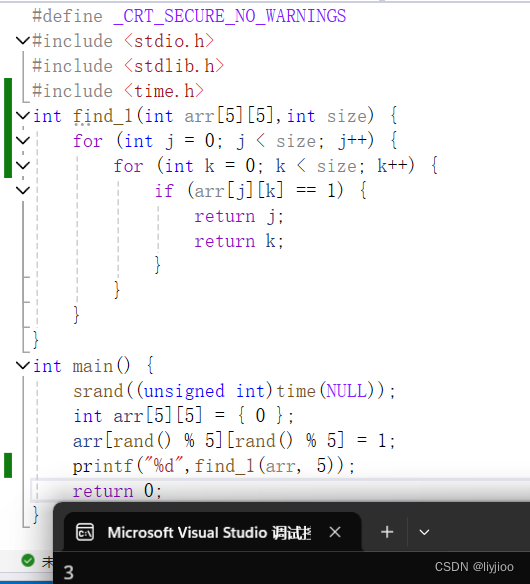 所以假设只使用一个%d还能打印出这个随机生成的1在第四行,但是这与我们所想的返回其横纵坐标就不一样了,所以当希望返回多个值时,可以使用指针传参来返回值。
所以假设只使用一个%d还能打印出这个随机生成的1在第四行,但是这与我们所想的返回其横纵坐标就不一样了,所以当希望返回多个值时,可以使用指针传参来返回值。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void find_1(int arr[5][5],int size,int*y,int*x) {
for (int j = 0; j < size; j++) {
for (int k = 0; k < size; k++) {
if (arr[j][k] == 1) {
*y = j + 1;
*x = k + 1;
}
}
}
}
int main() {
int i, j;
srand((unsigned int)time(NULL));
int arr[5][5] = { 0 };
arr[rand() % 5][rand() % 5] = 1;
find_1(arr, 5, &i, &j);
printf("第%d行,第%d列", i, j);
return 0;
}这样就能正确打印了。
5)函数与逗号表达式的结合使用
 如图,逗号表达式(1,2),(3,4),5实际上只有3个参数,分别是2,4,5(逗号表达式的值是最后的逗号后面的值)
如图,逗号表达式(1,2),(3,4),5实际上只有3个参数,分别是2,4,5(逗号表达式的值是最后的逗号后面的值)
6)函数与递归
i)递归的必要条件:
1)存在限制条件
2)不断接近这个限制条件
若是没有这两个限制条件,程序很容易陷入栈溢出,如图:
由于内存分为栈区,堆区,静态区,其中栈区存放局部变量和形参以及函数调用,堆区是动态开辟的内存,静态区含有全局变量和使用static修饰的变量。 所以每次进行函数调用,都会在栈区开辟空间,但是要是没有限制条件,这样一直开辟不收回,就会造成栈溢出。
ii)递归的运行流程
如图是拆分将一个高位数的数值拆分为一个个个位数并输出的代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
void print(int num) {
if (num > 9)
print(num / 10);
printf("%3d",num % 10);
}
int main() {
int num;
printf("请输入需要拆分的数值");
scanf("%d", &num);
print(num);
return 0;
}  如下是运行流程,箭头表示顺序
如下是运行流程,箭头表示顺序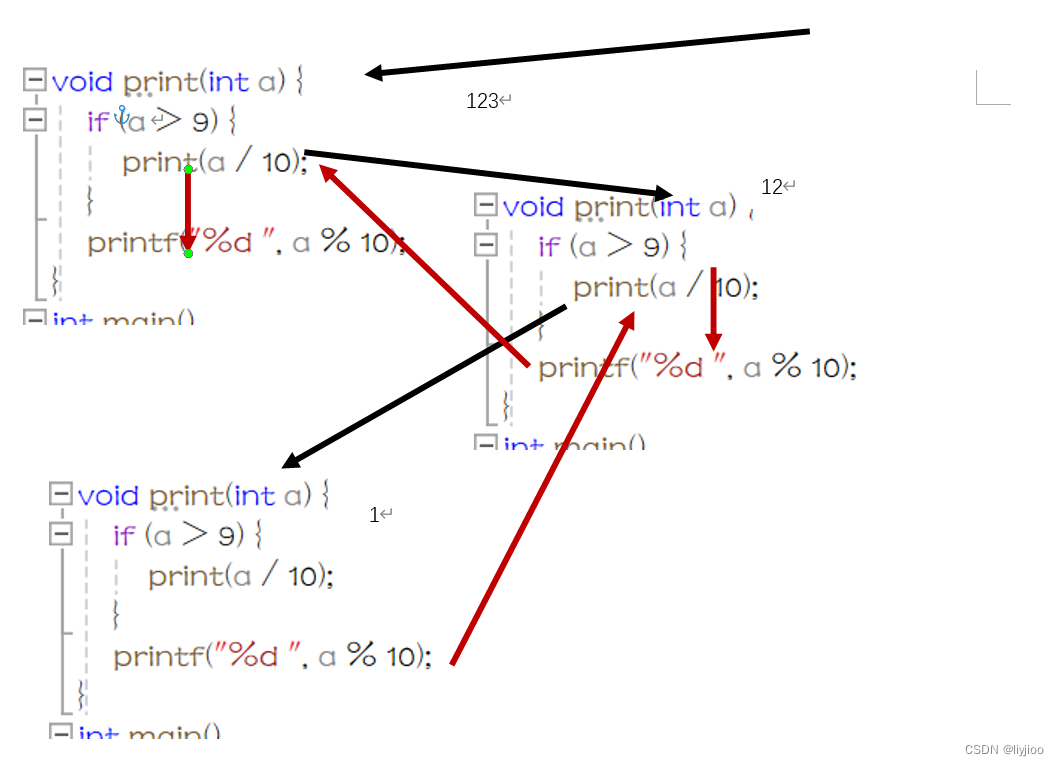
iii)递归易错点
易错代码如图:

这段代码中,想使用count来记录字符串的长度并使用递归在每次遇到非零字符就增加count,但是这段代码的count根本就不能通过递归回到调用他的上一个函数,只能返回他自己的count=1,所以要是把代码改成如下:
#include<stdio.h>
int str_len(char* ar) {
if (*ar != 0)
return 1 + str_len(++ar);
else
return 0;
}
int main() {
char* ar = "abc";
printf("%d",str_len(ar));
return 0;
}注意:++ar不要写成ar++,后置是先使用后++,这样就会报错栈溢出
这样就能输出3即字符串的长度,所以对于一般的需要进行累加的递归,我们需要明白代码大致是两个组成部分,一个是接近性质条件,还有一个就是结构相似的return,并且后一个return会影响前一个return。
更多例题将呈现在最后的C语言各类应用中。
12.数组
1)定义:一组相同数据类型的元素集合
2)初始化分类:分为不完全初始化和完全初始化。
一维数组初始化的方法如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdlib.h>
int main() {
int arr1[10];//只有指定大小
int arr2[10] = { 1,2,3,4,5,6,7,8,9,0 };//既有指定大小又有赋值,并且赋值的个数大于指定大小,只取前n个,并且指定大小必须是常量
int arr3[] = { 1,2,3,4,5,6,7,8,9,0 };//只有赋值,注意不能视作int arr3[]再arr3={...}
int* arr4 = (int*)malloc(sizeof(int) * 10);
return 0;
}二维数组的初始化方法如下:
#define _CRT_SECURE_NO_WARNINGS
int main() {
int arr1[3][3];//静态
int arr2[3][3] = { 1,2,3,4,5,6,7,8,9 };//与下一条类似,不过没写更详细的括号
int arr3[3][3] = { {1,2,3},{4,5,6},{7,8,9} };
int arr4[][3] = { 1,2,3,4,5,6,7,8,9 };//不写行,但不能不写列
int* arr5 = (int*)malloc(sizeof(int) * 3*3);
return 0;
}下面解释不完全初始化:

i)一维非字符数组
如图,对于一个有10个大小的数组,然而只存入了3个,在自动窗口中我们可以看到前3个数据被赋值了,后面的数据都是0,这样的初始化称为不完全初始化。
ii)一维字符数组
由于字符串的结束字符是‘\0’,所以当字符串大小为n个且初始化的字符为n-1个时,使用strlen依旧能检测出来大小为n-1,但是这里的0不是真正意义上的结束符,而是不完全初始化默认的0。
如图: 
iii)二维数组
对于二维数组,如果已经指定{},那么不完全初始化就会按照{}的顺序来,如果没有就按照元素出现顺序赋值,如图:

arr1的{}中还有两个{},那么数组赋值时,第一个{}就是二维数组中第一个一维数组,{1,2,3}实际上就等同于一维数组{1,2,3,0},第二个{}就是第二个一维数组,{4,5}等同于{4,5,0,0},后面没有初始化就都是{0,0,0,0}
arr2中{1,2,3,4,5}放到二维arr[3][4]就是{1,2,3,4}{5,0,0,0}{0,0,0,0}
但是一/二维数组的不完全初始化不能写入空括号:


3)数组在内存中的存放顺序
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
int main() {
int arr[] = {1,2,3,4};
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%p\n", &arr[i]);
}
return 0;
} 由这样的输出可知,arr[0]的地址小于arr[1],并且随着下标的增加,地址越来越高,所以可知数组在内存中连续存放,并且由低到高存放。
由这样的输出可知,arr[0]的地址小于arr[1],并且随着下标的增加,地址越来越高,所以可知数组在内存中连续存放,并且由低到高存放。
二维数组也一样,每个一维数组都是连续存放,从第一个一维数组开始,从左到右由低到高存放,第n个一维数组就顺序放到第n-1个一维数组的尾部。
4)数组名的作用
i)数组直接写下名称,大部分呢情况是指首元素地址
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4 };
printf("%d", *arr);
return 0;
}这段代码的输出是1,说明直接使用数组名就代表首元素地址。
ii)但是在使用sizeof(数组)或者&数组时,数组就是代表整个数组。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4 };
printf("%d\n", sizeof(arr)/sizeof(arr[0]));
printf("%p\n", &arr);//数组的地址,也就是数组首元素地址
printf("%p\n",arr+1);//跳过首元素的地址
printf("%p\n", &arr + 1);//跳过一个数组的地址
return 0;
}
如图,4的计算是因为sizeof里面是4个类型为int的元素,此时再除以第一个元素int的大小,就算出4
第二个是数组取地址得到的是数组的地址,对其+1就跳过一个数组了,但如果只写数组名+1,那么就只跳过一个元素
注意:这里的+1不能写成++,因为数组名虽然是首元素地址,但是这个指针实际上是指针常量,下面是常量指针和指针常量的区别:
const 类 *名 = 地址; 称为常量指针,其值不可改,地址可改
类 * const名 = 地址; 称为指针常量,其地址不可改,值可改
所以,++实际上是一种赋值操作,即arr=arr+1,由于指针常量地址不可改的特性,所以这样的赋值操作是错误的。
13.指针
1)指针概念
指针是一个变量,变量里存放着地址。
2)指针类型的运用
由于指针的大小都是4/8字节,看似每种类型的指针都是一样大小的,但不同类型在进行解引用操作时能访问空间大小是不同的。
如图,使用int*类指针指向int,修改int*就能一次性修改4个字节


但假设我们使用char*来指向,最后只修改一个字节


将最低位的一个字节改为了0
3)指针的运算
指针+-整数=指针
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4,5,6,7,8,9 };
printf("%p\n", arr);
printf("%p\n", arr + 1);
return 0;
}如上代码访问了数组第一个元素的地址,并且使用了+1访问到了第二个元素的地址
指针-指针=整数
->实际上可以看作上一条的变式,表示了两个指针之间相差了多少。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4,5,6,7,8,9 };
printf("%d\n", &arr[3]-&arr[9]);
return 0;
}答案是-6,因为9和3之间差了6,并且小的减大的了,所以是负数。
指针的比较
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4 };
int* ptr = arr;
int i = 0;
while (1) {
if (ptr + i >= &arr + 1)
break;
else
{
printf("%5d", *(ptr + i));
}
i++;
}
return 0;
}这段代码将当前的指针与数组后一个内存位置比较,如果当前指针小于后一个内存位置,即在该内存位置之前,那么就打印出该地址解引用后的数值,但如果比这个大或相等,就退出循环,结果就是输出数组的所有值。如图:
![]()
但是数组的比较只能与数组后面的比较,不能与数组前面的比较
4)野指针
由于局部变量不初始化存放的就是随机值,所以当一个指针变量所指向的内存地址是未知的、随机的或不可用的,这样的指针就是野指针。
1.野指针产生的情况
i)指针变量未初始化
- 当一个指针变量被定义后,如果没有显式地对其进行初始化,它的值将是随机的,可能指向内存中的任意位置。此时,如果尝试通过该指针访问或修改内存,将会导致不可预知的结果,因为该指针所指向的地址可能是无效的或已被其他程序使用的。
- 这种情况在局部变量指针中尤为常见,因为局部变量在定义时不会自动初始化为NULL或其他有效地址。
ii)指针越界访问
- 当指针访问数组或其他内存块时,如果超出了其合法范围,就会形成越界访问。此时,指针可能指向一个不属于原内存块的地址,从而变成一个野指针。
- 例如,在访问数组时,如果循环的索引超出了数组的长度,就可能导致指针越界。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,2,3,4 };
int* ptr = arr;
for (int i = 0; i < 5; i++) {
printf("%3d", ptr[i]);
}
return 0;
}![]() 结果如图,这样的野指针是很危险的,因为访问的这个超出索引的内存可能被分配给其他程序
结果如图,这样的野指针是很危险的,因为访问的这个超出索引的内存可能被分配给其他程序
iii)指针所指空间已释放
- 如果一个指针之前指向的内存空间已经被释放(例如,通过free函数或delete操作符),但指针的值没有被更新为NULL,那么该指针就变成了野指针。此时,再次通过该指针访问内存将是危险的,因为该内存空间可能已经被重新分配给其他程序使用。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int* test() {
int a = 10;
return &a;
}
int main() {
int* ptr = test();
printf("%d", *ptr);
return 0;
}上述代码中由于a是一个局部变量,所以test函数使用完a就被释放,但是返回了a的地址,这个时候ptr接受了a的地址,但是现在a的内存中可能被其他程序使用,所以ptr成了野指针。
但是即使指向空间释放的指针还是能访问一次该内存(现代操作系统和编译器通常不会立即释放或重新分配已经“离开作用域”的局部变量所占用的内存。相反,它们可能会将这块内存标记为可重新使用,并在后续的内存分配请求中将其分配给其他对象。然而,这个过程并不是即时的,也不是由编译器直接控制的,而是由操作系统的内存管理策略决定的)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int* test() {
int a = 10;
return &a;
}
int main() {
int* ptr = test();
printf("%d", *ptr);
printf("%d", *ptr);
printf("%d", *ptr);
return 0;
} 这段代码输出:![]()
5)数组传参会变为指针
数组传参分为一维数组传参,二维数组传参等,这里介绍一/二维数组传参
i) 一维数组传参
假设为一维数组int arr[10] = {0},那么可以写成int arr[]/int arr[10]或是写成int* ptr。假设一维数组为int* arr[10] = {…},那么可以写成int arr[]/int* arr[10]或是int** ptr(传参指针数组,变为了指向整形指针的指针,即二级指针)
综上,对于一维数组传参,可以使用数组和指针,数组可以写个数也可以不写,指针对于整形数组使用一级指针,对于指针数组可以使用二级指针。
ii)二维数组传参
假设为int arr[3][5]={0},可以使用int arr[3][5]作为形参,也可以省略行,但不能省略列,如int arr[][5],但不能使用一维或二维指针,因为二维数组的数组名实际上是首元素地址即一维数组地址,注意是一个数组的地址而不是第一个数组的首元素地址,所以假设用int*来作为形参,解引用后为int但二维数组解引用应该是一个数组,同理也不是int*,所以也不能使用二级指针。
综上,对于二维数组传参,可以使用数组和指针,数组必须有大小,但是可以省略行,使用指针就必须使用数组指针。
所以,无论是一维还是二维,都是可以使用数组,但是如果想用指针,一级二级等指针只能用在一维数组,如果先用在二维数组就必须使用数组指针。
6)void* ptr表示无类型指针
接下来使用qsort函数来解释:
qsort(base(数组首元素地址),num(数组长度),width(每个元素字节宽度),int (*cmp)(const void *e1(比较的两个元素的地址),const void * e2))
其中,有一个新的指针,即void*类型的指针,这种指针可以接受任意类型的指针,也就能对任意类型排序。
 如图,这样的代码能无错误直接通过的。
如图,这样的代码能无错误直接通过的。
但是void*不能用来修改和运算,因为不知道有多少字节。但是进行强制类型转换后就可以操作了。


接下来是对qsort的运用,让一个倒序的数组排序为正序:
注意:升序e1在前,倒序e1在后
#include <stdio.h>
#include <stdlib.h>
int cmp(const void* e1, const void* e2) {
return *((int*)e1) - *((int*)e2);
}
int main() {
int arr[] = { 9,8,7,6,5,4,3,2,1 };
qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]), cmp);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%3d", arr[i]);
}
return 0;
}由于这一位的参数类型必须是int,所以如果是对其他数据类型进行操作,需要用到强制类型转换
#include <stdio.h>
#include <stdlib.h>
int cmp(const void* e1, const void* e2) {
return (int)(*((float*)e1) - *((float*)e2));
}
int main() {
float arr[] = { 9,8,7,6,5,4,3,2,1 };
qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]), cmp);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%9f", arr[i]);
}
return 0;
}![]()
如果是结构体类型或其他组合的数据,那就是需要取一个关键词来进行比较,例如下列代码对学生排序,关键词是学生的名称的ASCII码。
#include <stdio.h>
#include <stdlib.h>
typedef struct stu {
char* name;
int age;
}Stu;
int cmp(const void* e1, const void* e2) {
return strcmp(((Stu*)e1)->name, ((Stu*)e2)->name);
}
int main() {
Stu arr[] = { {"Liming",12},{"Zhangsan",13},{"Wangwei",11}};
qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]), cmp);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%s", arr[i].name);
}
return 0;
}如图,字符串的比较可以使用strcmp。
根据这个原理。我们就能写出qsort内部的代码逻辑,如下:
#include <stdio.h>
#include <stdlib.h>
int cmp(const void* ptr1, const void* ptr2) {
return *((int*)ptr1) - *((int*)ptr2);
}
void swap(char* ptr1, char* ptr2, int width) {
for (int t = 0; t < width; t++) {
char temp = ptr1[t];
ptr1[t] = ptr2[t];
ptr2[t] = temp;
}
}
void m_sort(void* arr, int size, int width, int(*ptr)(const void*, const void*)) {
for (int i = 0; i < size - 1; i++) {
for (int j = 0; j < size - i - 1; j++) {
if (ptr((char*)arr + width * j, (char*)arr + width * (j + 1)) > 0)
swap((char*)arr + width * j, (char*)arr + width * (j + 1),width);
}
}
}
int main() {
int arr[10] = { 0,9,8,7,6,5,4,3,2,1 };
m_sort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(arr[0]), cmp);
for (int i = 0; i < 10; i++) {
printf("%3d", arr[i]);
}
return 0;
}和qsort一样先传入四个参数,第一个参数是整个排序对象的起始位置,第二个为总大小即用于后面的冒泡排序,第三个为单个元素的长度,用于后面的冒泡排序以及交换,第四个是函数指针,这里就用到了void*传入任何的参数,到后面强制类型转换就行了,转为char*就是因为char*一次就只能走一个字节,刚好传入的参数有字节数,所以就能完成比较和排序。
7)%s会解引用再输出,即使用printf且占位符为%s时,第二个参数是指针
#include <stdio.h>
int main() {
char arr[] = "123";
printf("%s\n", arr);
printf("%s\n", &arr);
return 0;
}如图,arr和&arr作为指针传入。
但是,第一个指针是指向数组第一个元素的指针,第二个指针是指向数组的指针,但是printf 的 %s 格式期望一个指向字符的指针,而不是一个指向数组的指针,所以实际上会发生指针类型的隐式转换。在这个上下文中,&arr 会被自动转换成 arr 的值,即数组首元素的地址。
8)字符串由于是常量,所以创建完就不会再被修改,所以只会被存储一份,使用指针指向相同的字符串,实际上指针指向的地址也是一样的
#include <stdio.h>
int main() {
char arr1[] = "123";
char arr2[] = "123";
char* ptr1 = "123";
char* ptr2 = "123";
if (arr1 == arr2)
printf("数组一样\n");
else
printf("数组不同\n");
if (ptr1 == ptr2)
printf("指针一样\n");
else
printf("指针不同\n");
return 0;
}如图代码,输出的是数组不同,指针相同,数组是可变的,所以实际上arr1和arr2首元素指针指向的是不同的地址,但是由于”123”字符串创建后不会再次创建一个相同的”123”的字符串,所以指针ptr1和ptr2指向同一个”123”,所以指针相同。
9)指针,数组,函数的组合
i)指针数组
1.定义:由于数组二字在后,所以指针数组就是一个数组,这个数组中的每一个元素都是一个指针
2.应用:
#include <stdio.h>
int main() {
int ptr1[] = { 1,2,3 };
int ptr2[] = { 4,5,6 };
int ptr3[] = { 7,8,9 };
int* arr[] = { ptr1,ptr2,ptr3 };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
printf("%3d", arr[i][j]);
}
printf("\n");
}
return 0;
}此处代码先创建了三个int类的数组,然后创建一个int*类数组,将三个int*的指针放入该int*类的数组(即指针数组),最后输出。
ii)数组指针
顾名思义,数组指针就是一个指针,指向一个数组,由于[]的优先级比*高,所以对于我们一开始看到的int* arr[10],[]先与arr结合,所以是一个数组,但是假设我们把*先与arr结合,即int (*ptr)[10],这样就说明ptr是一个指针,其指向的类型就是去除掉* ptr即int [10]类型的数据,即大小为10的包含整形数据元素的数组,数组指针可以这样使用:int (*ptr)[10] = &arr;所以数组指针解引用后就是一个数组名,即首元素地址。
然而,数组指针更多用于二维数组:
#include <stdio.h>
int test1(int arr[2][2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", arr[i][j]);
}
}
}
int test2(int(*ptr)[2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", ptr[i][j]);
}
}
}
int main() {
int arr[2][2] = {1,2,3,4};
test1(arr);
printf("\n");
test2(arr);
return 0;
}这样两种打印方式都能打印二维数组的值,即1234.
数组和指针辨析:

iii)函数指针
#include <stdio.h>
int test1(int arr[2][2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", arr[i][j]);
}
}
}
int main() {
printf("%p\n", test1);
printf("%p\n", &test1);
return 0;
}如上函数使用printf函数打印出函数名和函数的地址,最后发现输出如下:

可知,函数名和函数取地址都是能获得该函数的地址的。
由刚刚的结论可以知道,如果想用函数的地址,*和ptr必须写在一起,即(*ptr),除此之外,还需要加上函数的返回值类型一级传入值类型(形参),例如上述的代码的test1函数可以用int(*ptr)(int [2][2])来存储该函数的地址,注意,函数指针的参数就是参数的类而不是参数,它不需要写上名称,使用类就是直接去掉参数的名即可,例如一个二维数组,int arr[2][2]去掉名就为int [2][2]这就是二维数组的类,又如int *ptr是一个指针,去掉名称ptr剩下的就是int*,说明该指针指向int类型的数据。如果要理解这个数组/指针包含/指向的元素是什么,那就还要删掉其附带的结构如[]和*等。
但是,函数指针的参数也可加上参数名,例如下面的代码可以写作:
#include <stdio.h>
int test1(int arr[2][2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", arr[i][j]);
}
}
}
int main() {
int arr[2][2] = { 1,2,3,4 };
int (*ptr)(int arr[2][2]) = test1;
ptr(arr);
return 0;
}
#include <stdio.h>
int test1(int arr[2][2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", arr[i][j]);
}
}
}
int main() {
int arr[2][2] = { 1,2,3,4 };
int (*ptr)(int[2][2]) = test1;
ptr(arr);
return 0;
}函数指针的辨析:
 函数指针的调用不需要解引用,但是解引用也没问题,而且解多少次都是不会有影响。
函数指针的调用不需要解引用,但是解引用也没问题,而且解多少次都是不会有影响。
#include <stdio.h>
int test1(int arr[2][2]) {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
printf("%4d", arr[i][j]);
}
}
}
int main() {
int arr[2][2] = { 1,2,3,4 };
int (*ptr)(int[2][2]) = test1;
ptr(arr);
(*ptr)(arr);
(**ptr)(arr);
(***ptr)(arr);
return 0;
}![]() 结果如图,但是需要注意*优先级低于(),所以不要写成*ptr(arr)之类的。
结果如图,但是需要注意*优先级低于(),所以不要写成*ptr(arr)之类的。
iiii)函数指针数组
函数指针数组可以用于多个函数需要调用,把它们包括在一个数组中便于调用,其中arr也被称为转移表,通过数组下标转移到某和函数。
如下是一个加减乘除计算机的代码实现:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int add(int num1,int num2) {
return num1 + num2;
}
int sub(int num1, int num2) {
return num1 - num2;
}
int div(int num1, int num2) {
return num1 / num2;
}
int mul(int num1, int num2) {
return num1 * num2;
}
int main() {
int choice = 0, num1 = 0, num2 = 0;
int(*arr[4])(int, int) = { add,sub,div,mul };
printf("1.加法2.减法3.除法4.乘法");
printf("请输入操作符和操作数>>");
scanf("%d %d %d", &choice, &num1, &num2);
printf("%d\n",arr[choice-1](num1, num2));
return 0;
}这样,假设我们输入1加法,然后算127+980

定义辨析:
回调函数: 将某个函数指针或地址作为参数传递给另一个函数,在这个函数中使用该指针调用其指向的函数,这个作为参数的函数就是回调函数。回调函数不是由该函数实现方调用,而是由特定事件或条件发生时由另一方调用,例如test(print)假设这是在main函数中的代码,可见main作为实现方没有调用print函数,而是在另一方test中调用。
应用如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void menu() {
printf("------------------\n");
printf("-------1.add------\n");
printf("-------2.sub------\n");
printf("-------3.mul------\n");
printf("-------4.div------\n");
printf("-------0exit------\n");
printf("------------------\n");
}
int ADD(int a, int b) {
return a + b;
}
int SUB(int a, int b) {
return a - b;
}
int MUL(int a, int b) {
return a * b;
}
int DIV(int a, int b) {
return a / b;
}
int main() {
int choice = 0;
int x = 0, y = 0;
do {
menu();
printf("请输入选择");
scanf(" %d", &choice);
switch (choice) {
case 1:
{
printf("请输入操作数");
scanf("%d,%d", &x, &y);
printf("%d\n",ADD(x, y));
}; break;
case 2:
{
printf("请输入操作数");
scanf("%d,%d", &x, &y);
printf("%d\n",SUB(x, y));
}; break;
case 3:
{
printf("请输入操作数");
scanf("%d,%d", &x, &y);
printf("%d\n",MUL(x, y));
}; break;
case 4:
{
printf("请输入操作数");
scanf("%d,%d", &x, &y);
printf("%d\n",DIV(x, y));
}; break;
case 0:
printf("退出");
break;
default:
printf("输入有误");
break;
}
} while (choice >= 1 && choice <= 4);
return 0;
}如图为某加减乘除的计算机,但是这样每次都要获取两个操作数,如果输入0又不需要输入,代码过于冗余,所以可以再写一个函数,然后把函数指针传参给这个函数,如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void menu() {
printf("------------------\n");
printf("-------1.add------\n");
printf("-------2.sub------\n");
printf("-------3.mul------\n");
printf("-------4.div------\n");
printf("-------0exit------\n");
printf("------------------\n");
}
int ADD(int a, int b) {
return a + b;
}
int SUB(int a, int b) {
return a - b;
}
int MUL(int a, int b) {
return a * b;
}
int DIV(int a, int b) {
return a / b;
}
int cal(int(*ptr)(int,int)) {
int x, y;
printf("请输入操作数");
scanf("%d,%d", &x, &y);
return ptr(x, y);
}
int main() {
int choice = 0;
int x = 0, y = 0;
int (*arr[5])(int, int) = { 0,ADD,SUB,MUL,DIV };
do {
menu();
printf("请输入选择");
scanf(" %d", &choice);
switch (choice) {
case 1:
{
printf("%d\n", cal(ADD));
}; break;
case 2:
{
printf("%d\n", cal(SUB));
}; break;
case 3:
{
printf("%d\n", cal(MUL));
}; break;
case 4:
{
printf("%d\n", cal(DIV));
}; break;
case 0:
printf("退出");
break;
default:
printf("输入有误");
break;
}
} while (choice >= 1 && choice <= 4);
return 0;
}这样就使用cal调用回调函数ADD/SUB/DIV/MUL
iiiii)函数指针数组指针
函数指针数组指针就是指向函数指针数组的指针,即*应使用()获得更高的优先级,函数指针数组是 返回类型(*名称[大小])(参1,…),所以函数指针数组指针就是返回类型(*(*名称)[大小])(参1,…)
例如int ( * ( * pArr ) [ 10 ] ) ( int int )
10)指针进阶例题
1.指针的加法
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
struct test {
int Num;
//...
}*p;//假设test的大小为20字节
int main() {
p = (struct test*)0x100000;
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}答案是0x100000+20=0x100014,0x100000+1=0x100001,0x100000+4=0x100004
加法就看类型,后面的0x1就是1不用多虑。
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int arr[4] = { 1,2,3,4 };
int* ptr1 = (int*)(&arr + 1);
int* ptr2 = (int*)((int)arr + 1);
printf("%x %x", ptr1[-1], *ptr2);
return 0;
}答案是4 2000000,第一个好理解,第二个把地址转换为int类型1,将地址加1此时就是单纯地加上1,由于每个地址块占一个字节,所以转为地址后实际上是往后走了一个字节,演示如图:

2.大小不一数组强行转换
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int a[5][5];
int(*p)[4] = a;
printf("%d %p", &a[4][2] - &p[4][2],&p[4][2] - &a[4][2]);
return 0;
}![]() 答案如左。
答案如左。
此处创建了一个5*5大小的二维数组,如图:
 接下来是用数组指针,指向一个4个元素大小的数组,使用a取出这个5*5大小数组的首行地址即首地址,并将指针指向这个地址。绿框表示数组指针。
接下来是用数组指针,指向一个4个元素大小的数组,使用a取出这个5*5大小数组的首行地址即首地址,并将指针指向这个地址。绿框表示数组指针。

所以绿框每次少一个,所以第4行共少了4个,第二个输出希望以地址形式,那么-4的二进制为10000000 00000000 00000000 00000100
反码为 11111111 11111111 11111111 11111011
补码为 11111111 11111111 11111111 11111100
所以32位下为fffffffc,64位下前面由于为1所以补1导致前面多了8个f。
3.自增会对后面的计算造成影响

14.数据的存储
1)计算机内存中采用小端存储

 如图可见该数据的存储方式为小端存储,即高位在高地址(右)侧,低位在低地址(左)侧。
如图可见该数据的存储方式为小端存储,即高位在高地址(右)侧,低位在低地址(左)侧。
由图,我们也可以发现,大小端是对于字节而言的,并非对于二进制而言的,假设对于二进制而言,那整个十六进制就和内存中的不同了,例如aa是10101010,反过来就是01010101,那十六进制就成了55,就不是原来的aa了,但是看图上,发现实际上就是每个字节倒转了位置,原来的aa还是aa,字节内部是不发生变化的。
如果想要检测大小端存储方式也很简单,只需要带个1,然后取出最低位,因为1(int)的十六进制为00 00 00 01,假设小端,01在第一个字节,所以取出第一个字节就是1,如果大端,00在第一个字节,所以第一个字节取出0就是大端。
代码如下:
#include <stdio.h>
int check_sys() {
int a = 1;
char* ptr = (char*)&a;
return *ptr;
}
int main() {
if (check_sys)
printf("小端存储");
else
printf("大端存储");
return 0;
}小端存储的逆运用:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
union A {
short a;
char b[2];
}a,*p;
int main() {
p = &a;
p->b[0] = 0x11;
p->b[1] = 0x22;
printf("%x\n", p->a);
return 0;
}此处的数组是从低地址向高地址存储,输出却是高地址先输出。例如十六进制0x11223344,这里的11是高地址,44是低地址。
2)字符char类型
char类型在内存中是以ASCII码存储, 二进制从00000000到11111111,
00000000代表0,01111111代表127(2^7-1),10000000代表-128(由于10000000无法减一,所以遇见默认就是-128),11111111代表-1
所以随着char从00000000增长到11111111,char的值从0到127到-128到-1,再加一截断回到0。假设是无符号,那就从0到255再到0。
 所以在00000000到11111111的范围内,每次加一都是从0到正到负。对于char和使用int的打印时的整形提升看符号,负数提升全为1取反为0不影响,正数提升全为0所以也不影响。
所以在00000000到11111111的范围内,每次加一都是从0到正到负。对于char和使用int的打印时的整形提升看符号,负数提升全为1取反为0不影响,正数提升全为0所以也不影响。
例如:
#include <stdio.h>
#include<string.h>
int main() {
char a = 128;
printf("%d\n", a);
return 0;
}这段代码的结果是-128,这是因为128在char中实际上是127+1,通过上述结论,我们可知127+1=-128,所以假设将a=-128后,结果也是-128
应用:
#include <stdio.h>
#include<string.h>
int main() {
char a = -1;
char arr[1000];
for (int i = 0; i < 1000; i++) {
arr[i] = a--;
}
printf("%d\n", strlen(arr));
return 0;
}从-1开始,每次减一会一直到-128,再到127,最后到0结束,总共经历了128-1+1+127-0=255个字节。
3)整数int类型
 如图,与char类似,int类型的递增也是如同环状的。
如图,与char类似,int类型的递增也是如同环状的。
4)浮点数float类型
i)引入
#include <stdio.h>
#include<string.h>
int main() {
int a = 9;
float* p = (float*) & a;
printf("%d\n", a);
printf("%f\n", *p);
*p = 9.0;
printf("%d\n", a);
printf("%f\n", *p);
return 0;
} 可见,浮点数float和整数int虽然都是4个字节,但内部由于解析方式不同,导致同一个数会打印出不同的结果。
可见,浮点数float和整数int虽然都是4个字节,但内部由于解析方式不同,导致同一个数会打印出不同的结果。
ii)存储方式:(-1)^S*M*2^E
每个浮点数都可以写成这样的格式
S标识符号位,占1bit,由于符号是(-1)^S次方,所以正数S=0,负数S=1
M由于是2进制,所以使用二进制的科学计数法,后面的数是2的E次方,所以M是小于2大于等于1的数,float中占23bit,double中占52bit,但由于M用在二进制的科学计数法,小数点前的数肯定为1不能为0,所以1可以省区来提高精度。
E标识2的次方数,float中占8bit,double中占11bit,但由于E可能是负数(例如0.5,,变为2进制为0.1(2^(-1)),所以S=0,M=1,E=-1),所以为了E为正数,对于float类型,E要加上127,double要加上1023。
存放时,使用的是SEM。
以i的9.0(float)为例,9的二进制数为1001,可以看作(-1)^0*1.001*2^3
所以S=0,M=001,E=3+127=130
故SEM为0 10000010 00100000000000000000000
换为十六进制就是41 10 00 00,验证如图:
 由于计算机的字节的小端存储,所以低位的00放在低地址处,高位的41放在高地址处,结果就是返过来的00 00 10 41。
由于计算机的字节的小端存储,所以低位的00放在低地址处,高位的41放在高地址处,结果就是返过来的00 00 10 41。
但如果使用十进制的解析方式,输出的是
又如5.5的存储:
5.5的二进制为101.1,所以S=0,M=011,E=2+127=129=128+1
所以SEM为0 10000001 01100000000000000000000
转为十六进制就是40 B0 00 00由于小端存储,所以内存中可以看见00 00 B0 40
iii)浮点数的快速判断

5)空类型
i)用于函数返回
ii)用于函数参数,表示该函数就是没有参数,一旦传入就报错
没写参数但传入参数是不会报错的

一旦写上void类型的参数,就会报错。

iii)用于指针类型
6)自定义类型

15.VS环境C语言技巧
1)debug和release
debug是调试版本,包含调试信息,文件大,但release是发布版本,不能进行调试,但是文件小。
也就是说,release中不能使用F5来跳到断点,按下F5直接执行完程序。
2)release对代码有优化

如图代码,打印完13个1就崩溃了。
 如果i<17等更大的判断范围,可能会出现无限循环,原因是:
如果i<17等更大的判断范围,可能会出现无限循环,原因是:
 数组的下标增长地址由低到高,栈区使用由高到低,所以可能会覆盖导致循环条件被破环。
数组的下标增长地址由低到高,栈区使用由高到低,所以可能会覆盖导致循环条件被破环。
但是使用release就没报错,这是因为release把i在地址上放到了arr的后面。
 3)调试
3)调试

4)代码优化技巧
下列是字符串赋值的自定义函数
#include <stdio.h>
void m_strcpy(char* arr1,char* arr2) {
while (*arr2 != 0) {
*arr1 = *arr2;
arr1++;
arr2++;
}
*arr1 = '\0';
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}由于自增都是使用在解引用赋值之后,所以可以把自增和解引用赋值写在一起。
#include <stdio.h>
void m_strcpy(char* arr1,char* arr2) {
while (*arr2 != 0) {
*arr1++ = *arr2++;
}
*arr1 = '\0';
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}由于while的结束条件是0,字符串赋值的结束条件是0,所以可以把赋值fangdaowhile的判断内,赋值完0后返回0刚好退出循环。这样连后面的*arr1='\0'赋值都不需要了。
#include <stdio.h>
void m_strcpy(char* arr1,char* arr2) {
while (*arr1++ = *arr2++) {
}
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}但是此时的代码健壮性不足,如果输入 NULL等空指针虽然能正常进入m_strcpy函数,但是会报错,如图:

所以可以加上if语句来判断,代码如下:
#include <stdio.h>
void m_strcpy(char* arr1,char* arr2) {
if(arr1!=NULL&&arr2!=NULL)
while (*arr1++ = *arr2++) {
}
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, NULL);
printf("%s\n", arr1);
return 0;
}
if语句没有任何报错,直接就输出了,这样不利于维护,所以可以引入assert断言,同时加入assert.h头文件,assert(False)就会报错。
#include <stdio.h>
#include<assert.h>
void m_strcpy(char* arr1,char* arr2) {
assert(arr1 != NULL);
assert(arr2 != NULL);
while (*arr1++ = *arr2++) {
}
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, NULL);
printf("%s\n", arr1);
return 0;
}
还可以加上const来避免模板字符串指向的值修改,然后返回初始值,如下:
#include <stdio.h>
#include<assert.h>
char* m_strcpy(char* arr1,const char* arr2) {
char* a = arr1;
assert(arr1 != NULL);
assert(arr2 != NULL);
while (*arr1++ = *arr2++) {
}
return a;
}
int main() {
char arr1[] = "helloworld";
char arr2[] = "world";
m_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}综上,该代码的注意点为:1.while和自增的简化 2.返回值和const 3.assert断言
所以一个好的代码应该多注意assert断言和const的使用。
16.动态内存分配
1)内存区划分

2)堆区的使用
i)malloc和free
-
malloc没有足够空间就返回NULL
-
free后要注意还需要将指针指向NULL
-
free只能释放动态开辟的内存,所以free不能释放数组等,这样的行为是未定义的
ii)calloc初始化0
malloc申请的空间是不会初始化的,如下:

但如果使用calloc,可以将动态开辟的空间初始化为全0
 1.calloc和malloc的区别
1.calloc和malloc的区别
-
语法不同,calloc后面包含两个参数,一个参数是个数一个参数是大小
-
Calloc有初始化,所以效率更低,需要初始化后才返回
iii)realloc可以在原来动态开辟的内存上继续开辟一段内存空间,返回值为void*,但是能自动处理类型转换
void* realloc(void* memblock, size_t size)
第一个参数是需要修改的内存块指针,第二个参数是新开辟内存空间的字节数
1.如果指向的空间之后有足够的空间可以追加,则直接追加,返回的是原来的起始地址,如果空间不足,则realloc函数会重新找一个新的内存区域,重新开辟一块指定大小的动态内存空间,并且把原来内存空间的数据拷贝过去,释放旧的内存空间还给操作系统,最后返回新开辟的内存空间的起始地址。
![]()
2.realloc开辟的空间超过内存,就会返回NULL,所以不要直接使用原指针的名称,如果超了就返回NULL就找不到原来的内存了,所以用p2之后再判断是否为空再赋值给p
3.realloc使用NULL等价于上面的malloc

3)堆区使用易错点
1.
由于malloc创建可能会遇到创建失败,返回NULL的情况,如果对NULL解引用就是错误的
2.
程序越界访问导致错误
3.
对非动态开辟内存free
4.
p指针开辟空间又在使用中改变导致free无法释放最后程序崩溃
free时p已经在末尾了
5.
对同一块内存重复释放,解决方法就是释放完就置空NULL,这样free(NULL)就没操作一样
6. 第二行的代码调用其实是值传递,创建了堆区,但是行数调用完p就销毁了,最后堆区数据还在可是再也找不到了,str依旧是NULL,最后赋值非法访问报错
第二行的代码调用其实是值传递,创建了堆区,但是行数调用完p就销毁了,最后堆区数据还在可是再也找不到了,str依旧是NULL,最后赋值非法访问报错
4)柔性数组
柔性数组就是在结构体末尾加上一个大小不确定的数组,写作类 名[]或类 名[0],要注意在这个数组之前必须有一个及以上的成员,即不能让一个结构体中只放一个柔性数组,如下:
#include <stdio.h>
struct S {
char b;
int arr[];//int arr[0]
};
int main() {
printf("%d\n", sizeof(struct S));
return 0;
}这个这个结构体的柔性数组不算入整个结构体的大小。
所以上面的代码结果为1
对于柔性数组的内存开辟,可以使用malloc的加法,一个是sizeof结构体,由上面的结论可知,此时的sizeof是不包括柔性数组的大小,所以加上sizeof(类)*个数即可。
struct S* s = (struct S*)malloc(sizeof(struct S) * 4);//此处arr大小为4也可以使用指针来写。
#include <stdio.h>
struct S {
char b;
int* arr;
};
int main() {
struct S* s = (struct S*)malloc(sizeof(struct S));
s->arr = (int*)malloc(sizeof(int) * 4);
return 0;
}指针和数组的区别

17.文件操作
1.文件概念:
磁盘上的文件是文件,比如C盘打开后里面全是文件
2.在程序设计上的文件分类
按照用途

接下来的内容都是对数据文件的操作:
3.文件标识/文件名
文件路径+文件名主干+文件后缀
4.文件缓冲区
 输出和输入数据都是先放在缓冲区,直到充满缓冲区才输入输出
输出和输入数据都是先放在缓冲区,直到充满缓冲区才输入输出
缓冲区的大小主要看编译系统
5.文件的打开与关闭
1)文件指针
文件被保存在结构体变量中,该结构体变量的类型是FILE,这个FILE存放文件相关信息(文件名字,文件状态,文件当前位置),每当打开一个文件系统会自动创建并填充FILE,所以可以创建一个File*指针指向这个File结构体
2)文件打开与关闭
i)语法:
打开:FILE *fopen(const char* filename,const char* mode)
filename可以使用相对路径或是绝对路径,相对路径直接名.后缀即可,绝对路径磁盘目录后加:,目录包含关系使用//

使用+变读写的细节:
1. r+(读写模式)
- 功能:允许文件同时被读取和写入。
- 打开行为:
- 如果文件存在,打开文件,文件指针置于文件开头。
- 如果文件不存在,打开失败(通常返回一个NULL指针,表示文件未成功打开)。
- 写入行为:写入操作会从当前文件指针的位置开始,覆盖该位置及其之后的内容(如果有的话)。如果写入的内容比原内容短,则后面的内容会保留;如果写入的内容比原内容长,则后面的内容会被覆盖或删除。
- 读取行为:读取操作从当前文件指针的位置开始。
- 应用场景:适用于需要读取和修改文件中间部分内容的场景。
2. a+(追加读写模式)
- 功能:允许文件在末尾追加内容,并可以读取文件。
- 打开行为:
- 如果文件存在,打开文件,文件指针置于文件末尾。
- 如果文件不存在,创建新文件。
- 写入行为:写入操作总是在文件末尾追加内容。
- 读取行为:读取操作从当前文件指针的位置开始,通常需要先使用
fseek等函数将文件指针移动到文件的开始或其他期望的位置。 - 应用场景:适用于需要在文件末尾追加新内容,并且可能需要读取文件全部或部分内容的场景。
3. w+(写读模式)
- 功能:允许文件被写入和读取,但会先清空文件内容。
- 打开行为:
- 如果文件存在,打开文件,并清空文件内容,文件指针置于文件开头。
- 如果文件不存在,创建新文件。
- 写入行为:写入操作从头开始,覆盖(实际上是先清空)原有内容。
- 读取行为:读取操作从当前文件指针的位置开始,通常是文件的开头(因为文件内容已被清空)。
- 应用场景:适用于需要完全重写文件内容,并且可能需要读取新写入内容的场景。
关闭: int fclose(FILE *stream)
ii)特性:
如果返回失败就返回NULL
iii)易错示例:
 fclose必须有文件才能关闭,即不能fclose(NULL)
fclose必须有文件才能关闭,即不能fclose(NULL)
这里与堆区不一样,freee(NULL)是合法的,只不过没有操作
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<string.h>
#include <errno.h>
int main() {
FILE* f = fopen("text.txt", "r");
if (f == NULL)
printf("%s\n", strerror(errno));
else
{
printf("%c\n", fgetc(f));
fclose(f);
}
f = NULL;
return 0;
} 这样就正确了![]()
3)思考:
对于文件我们需要fopen和fclose来打开或关闭文件
但是键盘和屏幕貌似没有打开和输入的说法
因为程序在一开始就自动打开这两个流设备,分别是键盘-标准输入设备-stdin,屏幕-标准输出设备-stdout,stderr,这三个流设备都是FILE*类型变量
例如我们能直接使用fputc和fgetc输出和输入数据。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char a = fgetc(stdin);
fputc(a, stdout);
return 0;
}输出如图:
6.文件输入输出
1)写文件 (文件输出流)
i)fputc(内容,文件)

注意:不换行
ii)fputs("字符串",文件指针)
 同样的,也没有换行,使用\n换行
同样的,也没有换行,使用\n换行
2)写文件 (文件输入流)
i) fgetc(文件指针)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
FILE* pf = fopen("text.txt", "r");
if (pf == NULL)
printf("文件打开失败");
else {
char c = fgetc(pf);
fputc(c, stdout);
fclose(pf);
pf = NULL;
}
return 0;
}这样就能把刚才的HelloWorld的H输入了
ii)fgets(char[],最大个数,文件指针)-读取一行
最大个数这个参数是包括0的
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
FILE* pf = fopen("text.txt", "r");
char buf[1024];
if (pf == NULL)
printf("文件打开失败");
else {
fgets(buf,1024,pf);
printf("%s", buf);
fclose(pf);
pf = NULL;
}
return 0;
}使用缓冲区buf读数据
3)格式化输入输出
i)输出给文件就是fprintf,多了第一个参数是文件指针

ii) 输入就是fscanf,比起scanf就多了第一个参数文件指针

由上图也可知,格式化输入输出也可用于标准输入输出流
4)二进制输入输出
i)fwrite(输入的数据的地址,大小,个数,文件指针)

ii)fread(输出的数据的地址,大小,个数,文件指针)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
struct a {
float f;
int i;
};
int main() {
FILE* pf1 = fopen("text.txt", "wb");
struct a A1 = {1.2,1};
for (int i = 0; i < 3; i++) {
fwrite(&A1, sizeof(struct a), 1, pf1);
}
fclose(pf1);
pf1 = NULL;
FILE* pf = fopen("text.txt", "rb");
struct a A = {0};
while (fread(&A, sizeof(struct a), 1, pf)) {
printf("%f %d\n", A.f, A.i);
};
fclose(pf);
pf = NULL;
return 0;
}上面是fread和fwrite的结合使用,fread是有返回值的,返回值就是读取的数据个数,当到最后没有数据读取的时候,fread返回0退出while循环
5)文件操作函数
i) fseek随机读取
int fseek( FILE *stream, long offset, int origin );
第一个参数stream为文件指针
第二个参数offset为偏移量,如果为正就是向右偏移,如果为负就是向左偏移
第三个参数origin设定从文件的哪里开始偏移,可能取值为:SEEK_CUR、 SEEK_END 或 SEEK_SET
SEEK_SET: 文件开头
SEEK_CUR: 当前位置
SEEK_END: 文件结尾
其中SEEK_SET,SEEK_CUR和SEEK_END和依次为0,1和2.
例如:

这样就读取成功了,但唯一需要注意的是文件要ASCII编码
ii)ftell返回当前位置与文件起始位置的偏移量

iii)rewind让文件读取返回到起始位置

6)文件结束判定
i)EOF作为文件结束标志,转到定义后实际上是-1


ii) feof用于判断文件读取结束时,是因为读取失败而结束还是遇到文件尾结束,所以feof不能用来判断文件是否结束
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
FILE* pf = fopen("text.txt", "r");
int c = 0;
if (pf == NULL) {
printf("文件打开失败");
}
else {
while ((c = fgetc(pf)) != EOF) {
putchar(c);
}
if (ferror(pf)) {
printf("error when reading");
}
else if (feof(pf)) {
printf("end of file reached successfully");
}
}
fclose(pf);
pf = NULL;
return 0;
}所以可以使用ferror和feof一起使用判断
ferror判断是否读取(流错误)时出错(正常读取为0)
feof判断是否遇到EOF出错(非0正常结束)
iii)相较于strerror(errno),perror更加的便捷,操作如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
FILE* pf = fopen("text.txt", "r");
char c = 0;
if (pf == NULL) {
perror("文件读取错误");
return 0;
}
fclose(pf);
pf = NULL;
return 0;
}
这样还能自定义报错方式,先输出一段自定义报错语段,再加上冒号,再报出错误信息。
7)对比scanf/fscanf/sscanf和printf/fprintf/sprintf

第一个是针对标准输入流/标准输出流的格式化输入输出
第二个是针对所有输入流/输出流的格式化输入输出
第三个中sscanf是从字符串中读取格式化数据,sprintf是读取格式化的数据到字符串
18.C语言的程序环境和预处理
程序由两个环境,一个是翻译环境(源代码转换为可执行的二进制机器指令),一个是执行环境(可执行程序运行起来产生结果的环境)
1).c文件向.exe文件的转换
每个源文件都由编译器经过单独的编译,生成其对应的目标文件(.obj),所有的目标文件加上链接库经过链接器就会产生可执行程序。
链接器同时会引入标准C函数库中任何被该程序所用到的函数,并将个人程序库中的引用也链接入程序中。在我们平时写的代码中,引入的都是我们所需要使用的代码的头文件,但头文件与代码的实现是不同的,它主要负责声明,实现则存在于库函数中,区别如下:
- 头文件和库文件的主要区别在于:头文件提供函数、变量、类型等的声明,让编译器知道它们的存在和如何使用它们;而库文件提供这些声明的实际实现,即编译后的代码。
- 我们通常使用头文件来引入我们需要的函数,因为头文件包含了使用这些函数所需的所有声明。然而,仅仅包含头文件是不够的,我们还需要在链接时提供包含这些函数实现的库文件,否则链接器会报错,因为它找不到这些函数的实现。
2)编译阶段分为预编译,编译,汇编三个阶段
i)预处理阶段-->生成.i文件
1.#include头文件的包含,把头文件的内容全放在了.c文件中
2.删除注释(使用空格替换注释)
3.#define替换
可见预处理阶段就是进行文本操作,include即将文本进行一次拷贝,删除注释使用空格替换和define即文本替换操作。
ii)编译阶段->生成.s文件
编译阶段形成汇编代码,包括语法分析,词法分析(把C语言代码拆解,例如把代码拆分出操作符,等。),语义分析(读懂代码),符号汇总(将程序的函数和全局变量汇总,用于下一步的汇编)
iii)汇编阶段->生成.o/.obj文件
把汇编代码转换成了二进制指令,并形成符号表
即符号名和符号地址一一对应。
3)链接阶段
链接阶段包括合并段表,符号表的合并和重定位
每个目标文件都会把自己分成几段,多个目标文件段与段之间的合并就称为合并段表
符号表中可能有些符号表的内容是函数声明,所以会与函数的定义重名,这个时候就重定义,合并为一个表

4)运行环境
程序要运行,必须得载入内存,在有操作系统的环境中,由操作系统完成,在独立的环境中,需要手动安排也可以由可执行代码载入只读内存完成
接下来就是调用main函数,运用栈堆和静态区等存储变量
最后退出main函数,这个退出可能是正常也可能异常
5)预定义符号
i) __FILE__读取文件路径,返回字符串

ii)__LINE__读取当前行,返回整形

iii)__DATE__和__TIME__返回当前日期和时间,返回字符串
可用于写入文件当前操作的时间
iiii)__FUNCTION__返回当前内容所在的函数,返回字符串
iiiii)__STDC__如果返回1就严格遵守C语言标准,返回整形
6)#开头的预处理指令
i)#define
define是不需要加=或者;,因为define是替换而不是赋值
1.#define name stuff定义标识符
1)#define MAX 100
2)#define reg register
reg int a;---->register int a;
3)#define do_forever for(;;)
do_forever;
return 0;这样就会无限循环
但是
do_forever
return 0;这样就会直接退出
4)#define CASE break;case
写Case自动补break
5)\来分行写代码
#define DEBUG_PRINT printf("file ...\
...\
...")使用\来分行写代码,最后一行不需要
2.#define定义宏
1)定义:允许把参数替换到文本中,这种实现称为宏或定义宏
#define name(parament-list) stuff,parament-list是逗号隔开的符号表,他们可能出现在stuff中,注意(必须紧紧靠着name,不然会被解释为stuff的一部分
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define ADD(x,y) x+y
int main() {
printf("%d\n", ADD(1,2));
return 0;
}例如上述代码算两数求和,实际上是ADD(x,y)被替换为x+y
2)宏的文本输出
当我们想对创建的两个变量进行提示输出时,可能会有如下的写法:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
void print(int num) {
printf("a/b=%d\n", num);
}
int main() {
int a = 10;
int b = 20;
print(a);
print(b);
return 0;
} 这样的结果可能根本看不出来到底a是10还是b是10
这样的结果可能根本看不出来到底a是10还是b是10
实际上,printf可以有另一种写法,即两个字符串拼接,如printf("Hello""World");
![]() 结果如图。
结果如图。
当我们使用#来修饰宏定义参数时,能发现宏定义参数变成了文本
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define print(x) printf(#x)
int main() {
int a = 10;
print(a);
return 0;
}![]()
所以使用这两部分的性质,我们可以将a,b分别当作参数输出,如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define print(x) printf(#x"=%d",x)
int main() {
int a = 10;
int b = 20;
print(a);
print(b);
return 0;
}![]()
3)宏的拼接
宏除了能文本化输出,还可以使用来文本拼接,演示如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define print(x,y) printf("%d\n",x##y)
int main() {
int HisAge = 18;
print(His, Age);
return 0;
}这样就能将His和Age拼接,产生的HisAge作为参数并输出
4)注意点:
1. 宏的直接替换
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define SQUARE(x) x*x
int main() {
printf("%d\n", SQUARE(3+1));
return 0;
}上方的代码中我不再是写入一个参数,而是写入一个表达式,由于3+1=4,所以一开始可能会理所应当以为是算完才放入计算,但实际上宏定义是替换,结果是3+1*3+1=7
为了获得我们所期待的结果,可以使用小括号的优先级来完善代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define SQUARE(x) (x)*(x)
int main() {
printf("%d\n", SQUARE(3+1));
return 0;
}但是假设这是一个相加的运算,如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define DOUBLE(x) (x)+(x)
int main() {
printf("%d\n", 10*DOUBLE(3+1));
return 0;
}这样10*(3+1)会比后面的+(3+1)的优先级更高,所以还需要再写入括号:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define DOUBLE(x) ((x)+(x))
int main() {
printf("%d\n", 10*DOUBLE(3+1));
return 0;
}宏参数也有可能带有副作用:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define MAX(x,y) (x)>(y)?x:y
int main() {
int a = 10;
int b = 11;
int max = MAX(a++, b++);
printf("a=%d,b=%d,c=%d", a, b, max);
return 0;
} ![]()
2. 调用宏的参数中如果有define定义,先替换为define定义的文本,再使用宏
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define NUM 10
#define ADD(x) ((NUM)+(x))
int main() {
printf("%d\n", 10*ADD(3+1));
return 0;
}如上代码,NUM先替换,再使用ADD
3. 宏不能出现递归
// 尝试定义一个递归宏来计算阶乘,但这是错误的
#define FACTORIAL(n) ((n == 0) ? 1 : (n * FACTORIAL(n - 1)))
int main() {
// 这里会导致预处理器无限递归,因为宏调用会不断展开
// 最终会导致编译错误,因为预处理器有替换次数的限制
printf("%d\n", FACTORIAL(5)); // 这行代码不会正常工作
return 0; 如上所示代码,由于宏只是文本替换而不是代码执行,所以n==0这个判断根本不会执行,那么这段代码就会FACTORIAL(5), FACTORIAL(4), FACTORIAL(3)一直执行下去而忽略0这个结束条件
5) 宏的优势和劣势
i)优势1:宏更加灵活,是类型无关的
ii)优势2:宏没有函数调用和返回开销,宏比函数在程序的规模和速度方面更胜一筹
例如MAX最大值的反汇编:

图示为宏

图示为函数
这是因为宏在预编译阶段就已经文本替换了
iii)优势3:宏参数可以出现类型,但函数做不到
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define SIZE(X) printf("%d\n",sizeof(X))
int main() {
SIZE(int);
return 0;
}这样就能输出4了。
i)劣势1:不适用于多次调用
 如图示代码如果写个函数进行比较反而更方便,所以宏适用于少调用的情况。
如图示代码如果写个函数进行比较反而更方便,所以宏适用于少调用的情况。
ii)劣势2:不能使用调试时define已经替换,所以难以改正错误
iii)劣势3:宏没有类型定义,所以不够严谨
iiii)宏可能会带来运算符优先级的问题,但是函数如果传参是算式的时候会先算完再传参
6)#undef取消宏定义
 如图就无法识别了。
如图就无法识别了。
3.命令行定义
在预编译阶段从命令行传入数值
4.条件编译
i)#ifdef判断是否定义 ,#endif结束
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define MAX 60
int main() {
#ifdef MAX
printf("Hello World");
#endif
return 0;
}这段代码中定义了MAX,然后就输出了Hello World
这种代码用于有些时候有些代码在某些情境下没必要,但是删掉又可惜,就可以使用条件编译
ii)#if判断后面是否为真,#endif结束,如果为真就运行


#if后还可以调用#define的

5.#include包含
可以使用<>引入库函数,也可以使用""引入自己的文件
双引号""的查找方式:现在源文件目录下查找,如果没有找到就在标准位置查找,如果再找不到就返回编译错误
<>的查找策略是直接到标准位置查找
可见文件查找范围来说""要大于<>,所以库函数也可以是""来引入,但是这样会很麻烦要先去源文件查找,这样效率太低
头文件写法:
在头文件中使用#pragma once或者
#ifndef...
#define...
...
#endif来放置重复包含
6.宏的应用
i)使用宏来重写offsetof
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define OFFSETOF(struct_name,member_name) (int)&(((struct_name*)0)->member_name)
typedef struct {
char c1;
int a;
char c2;
}s;
int main() {
printf("%d\n", OFFSETOF(s, c1));
printf("%d\n", OFFSETOF(s, a));
printf("%d\n", OFFSETOF(s, c2));
return 0;
}使用结构体指针指向0的位置,然后取成员输出地址,再将地址强制转为int类型即可
19.C语言的各类应用
1)获取指定值之内的所有随机位数水仙花数
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<math.h>
int main() {
int number_max;
printf("请输入输出水仙花数的最大值");
scanf("%d", &number_max);
for (int i = 0; i <= number_max; i++) {
int sum = 0;
int n = 1;
int temp = i;
while (temp/=10) {
n++;
}//计算位数
temp = i;
do {
sum += pow(temp % 10, n);
} while (temp /= 10);
if (sum == i) {
printf("%d是水仙花数\n", i);
}
}
}该代码先是输入一个水仙花数最大值,然后每次循环计算位数,最后使用pow计算n次方和是否为原来的数,如果是就是水仙花数。
这段代码里很容易将不写temp,这样对i修改计算会导致for循环的i也被修改,这样代码就无限循环了。
以及temp/=10写为temp/10,这就导致while循环不终止。
还有sum,n这些需要在计算下一次重置为初始值,所以可以将初始化直接搬到for循环里,这样就不需要重复写代码了。
2)打印菱形
题目要求:输入一个数,然后以这个数为上三角行数打印出对应菱形。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<math.h>
int main() {
int line;
printf("请输入需要打印的菱形的上三角形的行数");
scanf("%d", &line);
for (int i = 0; i < line; i++) {
for (int j = line - 1 - i; j > 0; j--) {
printf(" ");
}
for (int j = 0; j <= i*2; j++) {
printf("*");
}
printf("\n");
}
for (int i = 0; i < line - 1; i++) {
for (int j = 0; j <= i; j++) {
printf(" ");
}
for (int j = 0; j < 2 * line - 3 - 2 * i;j++) {
printf("*");
}
printf("\n");
}
return 0;
}菱形问题就看作打印空格,星形和换行的结合。
 如图,最中间一行(line行)的空格数为0,由于是等腰三角形,所以第一行有line-1个空行,又由于行数从0开始,所以第一行的空格为line-1-i(行数),同理解出后面的空格数和星数。
如图,最中间一行(line行)的空格数为0,由于是等腰三角形,所以第一行有line-1个空行,又由于行数从0开始,所以第一行的空格为line-1-i(行数),同理解出后面的空格数和星数。
3)汽水兑换求总数问题
题目情景:1元可以兑换1瓶汽水,喝完剩下的两个空瓶可以兑换一瓶汽水,求最后的能喝多少。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<math.h>
int main() {
int money,total,empty;
printf("请输入目前的钱");
scanf("%d", &money);
total = money;
empty = total;
while (empty != 1) {
total += empty / 2;
empty = empty / 2 + empty % 2;
}
printf("当前的钱可以买:%d瓶汽水", total);
return 0;
}一开始我们先将钱的数量赋值给汽水总数,因为一开始有多少钱就能喝多少汽水,然后将汽水数赋值给空瓶数,这样就说明喝完汽水剩下的都是空瓶。然后循环当空瓶数不为一时不断兑换汽水和喝汽水,判断条件是不为一是因为空瓶数到最后肯定为1,然后此时就换不了也喝不了了,原因是由于两瓶换一瓶,所以最后的瓶数必定能被2整除,那么有可能为1瓶也可能为0瓶,由于2瓶喝完能换一瓶,一瓶喝完就不能换只能剩下一瓶了,所以结束条件就可以看作是只剩一瓶了而不是只剩瓶数小于2,当然也可以写作小于2,代码效果相同。如果题目认为可以借一瓶,那么还能再喝一瓶,最后一个空瓶还回去,那就要另当别论了,此时空瓶可以为0个。

 多次输入可见实际上可以买的瓶数就是钱数乘2减1,但实际上就是如此。
多次输入可见实际上可以买的瓶数就是钱数乘2减1,但实际上就是如此。
这里我使用二叉树进行解释:
如图,假设我有4块钱,那么可以喝4瓶(第3层),剩下4瓶可以环2瓶(第2层),2瓶又可以换1瓶(第一层),可见无论多少瓶,都可以画作这样一幅二叉树,除了最后一层,剩下层数的结点个数为n-1,最后一层为n,所以总共2n-1个。但是这个算式必须考虑在n=0时的情况,因为这个二叉树是没有n=0的画法,并不适用于该情况。
上述满二叉树适用于偶数元的情况,在钱数为奇数时,先画前n-1块钱能获得的汽水,然后得到n-1块钱能获得2n-3瓶汽水,加上第n瓶的1瓶,以及还能再换一瓶(无论如何都会多出一个空瓶,这个n-1的满二叉树的空瓶与第n个空瓶再换一瓶),总共还是2n-1瓶。
4)互换数组的奇偶数,使奇数放在左侧,偶数放在右侧。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
void show_arr(int n,int* arr) {
for (int i = 0; i < n; i++) {
printf("%3d", arr[i]);
}
printf("\n");
}
int main() {
int size;
printf("请输入需要输入的数组的大小");
scanf(" %d", &size);
int* arr = (int*)malloc(sizeof(int) * size);
for (int i = 0; i < size; i++) {
printf("请输入第%d个数组元素的值",i+1 );
scanf(" %d", &(arr[i]));
}
printf("原数组为:");
show_arr(size, arr);
int left = 0;
int right = size - 1;
while (left < right) {
while (left < right && arr[left] % 2 == 1) {
left++;
}
while (left < right && arr[right] % 2 == 0) {
right--;
}
if (left < right) {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
printf("交换后的数组是:");
show_arr(size, arr);
return 0;
}这段代码先是按照用户的要求创建了一个数组,然后通过while循环使用左右指针分别从最左侧和最右侧往另外一段移动,直到left找到偶数以及right找到奇数,然后互换,期间需要注意是否left和right会越界,所以每个while和if都要判断left<right。
5)杨辉三角
按照行的需求生成一个杨辉三角,要求格式为金字塔形。如图:
 代码如下:
代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main() {
int width;
printf("请输入需要生成的杨辉三角行数");
scanf(" %d", &width);
int* arr = (int*)malloc(sizeof(int) * width * width);
for (int i = 0; i < width; i++) {
for (int j = 0; j <= i; j++) {
if (j == 0){
arr[i * width + j] = 1;
continue;
}
else if (i == j){
arr[i * width + j] = 1;
continue;
}
else {
arr[i * width + j] = arr[(i - 1) * width + j - 1] + arr[(i - 1) * width + j];
}
}
}
for (int i = 0; i < width; i++) {
for (int k = 0; k < width - 1 - i; k++) {
printf(" ");
}
for (int j = 0; j <= i; j++) {
printf("%4d", arr[i * width + j]);
}
printf("\n");
}
return 0;
}杨辉三角可以视作一个数组,然后这个数组的第一列和对角线相等的坐标数值都是1,其他都是其上面的和左上角数据数值之和,重点是在打印,打印就与菱形问题类似,但是为了空出足够的距离,可以一次打印两个空格,为了整齐,使用%4d,不用其他数字是因为每一行与前一行差两个空格,所以可以加上4个空格刚好与上一行的元素成轴对称。
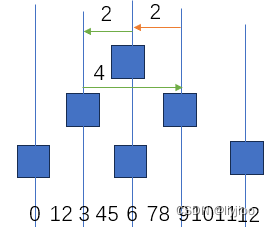 作简图如左,为了方便观察,将轴对称线从每个结点的中心穿过
作简图如左,为了方便观察,将轴对称线从每个结点的中心穿过
6)多个if判断类型题目
i)判断凶手
四个凶手供词为
A:不是我
B:是C
C:是D
D:C在胡说
三人为真话,一人为假话,那么凶手是谁。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main() {
for (int killer = 1; killer <= 4; killer++) {
if ((killer != 1) + (killer == 3) + (killer == 4) + (killer != 4) == 3) {
printf("%c", killer + 64);
}
}
return 0;
}if语句若为真就返回1,若为假返回0,三个人真就说明加起来是3,打印出来就是C。
ii)判断名次
A:b第二,我第三
B:我第二,e第四
C:我第一,d第二
D:c最后,我第三
E:我第四,a第一
每位选手都只说对了一半,请用编程确定比赛的名次
如果使用上一题的方法,会得到许多值,这是因为可能同个名次出现好多人
所以可以加上判断a*b*c*d*e=120,即一到五名都有一个人。
iii)将a,b,c逆序输出
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a, b, c;
printf("请输入abc的三个值,使用空格隔开");
scanf("%d %d %d", &a, &b, &c);
if (a < b) {
int temp = a;
a = b;
b = temp;
}
if (a < c) {
int temp = a;
a = c;
c = temp;
}
if (b < c) {
int temp = b;
b = c;
c = temp;
}
printf("abc的值为%d,%d,%d", a, b, c);
}
这段代码就是看a是不是比b,c小,把最大的放在a上,然后b是不是比c小,把最小的放c上。
iiii)闰年判断
闰年:能被4整除但不能被100整除,或是能被400整除
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int year;
printf("请输入年份");
scanf("%d", &year);
if ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0))
printf("%d年是闰年", year);
else
printf("%d年不是闰年", year);
return 0;
}7)求最大公因数
求公因数可以使用短除法和辗转相除法。
短除法就是一遍遍除以同一个数,将除完的商再除,这样直到最后不能再同整除一个值了为止,将从开始到最后的除的数乘起来,最后获得最大公因数。
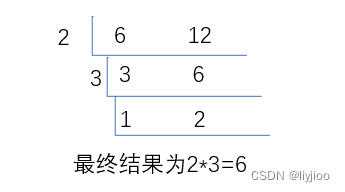 左图就是以6和12为例的短除法。
左图就是以6和12为例的短除法。
辗转相除法就是将被除数除以除数得到商和余数,然后将除数作为被除数,余数作为除数,继续计算,直到余数为0,此时的除数就是最大公因数。
具体验证方法可以是使用矩形验证,假设还是求是求15和12的最大公因数,那就把15和12作为两边,如图:

获得公因数就是说12能被这个数整除,15也能被这个数整除,那也可以看作画多个相同的正方形,能刚好将这个矩形框填满,而且既然是求最大公因数,那么就要让这个正方形最大。
那么此时还剩下一个长为12,宽为3的矩形,继续对这个矩形分割,能刚好将这个矩形分成四份,如图:
此时12为边的正方形的边长是边为3正方形的边长的4倍,那就说明12里面能被边长为3的正方形填满,实际上为什么12能被3填满,就是因为无论画多少,最后一个将最大矩形填满的正方形都是沿着上一级的正方形的某条边填满的,即存在倍数关系,然后上上一级的大小就是上一级和最后一集的大小的组合,上图可能不是很直观,下面画一个比较直观的图,例如作16578和30021的最大公因数,那么作如下简图:
所以画到最后,反着推都是有倍数关系的,即刚好填满的正方形是最大且是两者的因数。
所以代码就是使用while循环,进行除法,然后除数变被除数,余数变除数,不断循环直至余数为0,最终的答案就是上一次的余数即最后一次能整除的除数。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int a, b, r;//两个操作数,a最大,b最小,r余数
printf("请输入需要进行求解最大公因数的两个操作数,中间使用空格隔开");
scanf("%d %d", &a, &b);
if (a < b) {//如果b大,互换两数
int temp = a;
a = b;
b = temp;
}
while (r = a % b) {
a = b;
b = r;
}
printf("两数的最大公因数是%d", b);
return 0;
}先是把最大值给了a,最小值给了b,然后辗转相除,最后的除数就是最大公因数。
8)算前n项阶乘的和
算阶乘可以使用先算后加或者边算边加。
先算后加的代码可以使用数组存储n个阶乘的值,然后for循环加起来
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
int main() {
int n;
int total = 0;
printf("请输入你需要计算几项阶乘的和");
scanf("%d", &n);
int* arr = (int*)malloc(sizeof(int) * n);
for (int i = 1; i <= n; i++) {
int sum = 1;
for (int j = 1; j <= i; j++) {
sum *= j;
}
arr[i - 1] = sum;
}
for (int i = 0; i < n; i++) {
total += arr[i];
}
printf("前n项阶乘的和为%d", total);
return 0;
}但是这样计算每个阶乘都要计算i遍,如果阶乘的n为很大的值是,程序就会需要使用很多很多的时间,如图:


所以我们可以选择一种算法能够边算边加,这样就能算1次1阶乘,算1次2阶乘,都是计算一次就直接加上去,这样就能省去很多时间。
边算边加的代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i;
int sum = 1;
int total = 0;
printf("请输入你需要计算几项阶乘的和");
scanf("%d", &i);
for (int j = 1; j <= i; j++) {
sum *= j;
total += sum;
}
printf("前%d项阶乘的和为%d", i, total);
return 0;
} 如图,可见省去了大量的时间。
如图,可见省去了大量的时间。
9)求素数
首先,我们需要先了解什么是素数
素数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的数。
所以我们可以使用试除法从2除到n-1,假设能被整除就退出。
同时2由于只有1和2能整除,所以也是素数,这段代码中刚好i=2,j=2相等为素数。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int i;
int j;
printf("请输入需要进行判断的数");
scanf("%d", &i);
for (j = 2; j < i; j++) {
if (i % j == 0)
break;
}
if (j == i)
printf("是素数");
else
printf("不是素数");
return 0;
}

但是由于只要直到这个数能被其平方根内的数整除即可说明该数不是素数。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <math.h>
int main() {
int i;
int j;
printf("请输入需要进行判断的数");
scanf("%d", &i);
for (j = 2; j <= sqrt(i); j++) {
if (i % j == 0)
break;
}
if (j > sqrt(i))
printf("是素数");
else
printf("不是素数");
return 0;
}
由于偶数不是素数,所以可以两个两个加,但前面要分类讨论,2和偶数。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<math.h>
int main() {
int i;
int j;
printf("请输入需要进行判断的数");
scanf("%d", &i);
if (i == 2)
printf("是素数");
else if (i % 2 == 0)
printf("不是素数");
else {
for (j = 3; j <= sqrt(i); j += 2) {
if (i % j == 0)
break;
}
if (j > sqrt(i))
printf("是素数");
else
printf("不是素数");
}
return 0;
}
10)递归例题
i)求n项阶乘
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int count_n(int num){
if (num != 1)
return num * count_n(num - 1);
else
return 1;
}
int main() {
int num;
printf("输入n,求n!");
scanf("%d", &num);
printf("阶乘为%d", count_n(num));
return 0;
} 
ii)求第n个斐波那契数之和
定义:1 1 2 3 5 8 13 ...前两个数之和等于下一个数
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int Fib(int n){
if (n != 1 && n != 2)
return Fib(n - 1) + Fib(n - 2);
else
return 1;
}
int main() {
printf("%d",Fib(8));
return 0;
}这样就能求得第八个斐波那契数,即21
但是使用斐波那契数每调用一次,就需要再调用两次(分别是n-1和n-2),所以对于处理较大的数会消耗大量的时间,所以使用迭代会大大减少计算量,迭代的写法如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int Fib(int n){
int a = 1;
int b = 1;
int c = 1;//分别是前一个,中间,后一个的三个数字
while (n > 2) {
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main() {
printf("%d",Fib(8));
return 0;
}iii)汉诺塔问题
汉诺塔问题是一个经典的递归问题,它源于印度的一个古老传说,涉及到三根柱子和一些大小不同的圆盘。游戏的目标是将一个柱子上的所有圆盘移动到另一个柱子上,同时遵循小圆盘不能放大圆盘下面的原则。
具体流程如图,先将前面的n-1个圆环通过结束杆放到中转杆,再将最后一个圆环放到结束杆,最后将中转杆上的n-1个圆环通过起始杆放到结束杆,所以代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void print(char s,char d) {
printf("%c -> %c\n", s, d);
}
void Hanno(int n,char start,char temp,char end) {
if (n == 1)
print(start, end);
else {
Hanno(n - 1, start, end, temp);
print(start, end);
Hanno(n - 1, temp, start, end);
}
}
int main() {
Hanno(3, 'A', 'B', 'C');
return 0;
}汉诺塔的代码实现实际上就是使用if语句看是否该圆环为最底部圆环,如果是直接将其从起始杆放到终止杆,如果不是就先把前n-1个使用递归从起始杆通过中转放到终止杆,再将最后一个放到终止杆,最后将n-1个在中转杆上起始通过起始杆放到终止杆上。
或者换句话来说,一开始要将n-1个圆环通过终止杆放到中转杆上,实际上就是要将n-2个圆环通过中转杆放到终止杆上,那也就是n-3个圆环通过终止杆放到中转杆上,以此类推,只有终止杆和中转杆的身份一直在改变,所以代码从start, temp, end变为了start, end, temp,最后的temp,start, end中转和起始互换是因为剩下的n-1个圆环在中转杆上,把中转杆和起始杆的身份互换就能回到将n-1个圆环从起始(实际上是在原中转杆上)到终止杆的汉诺塔问题。
结果如图:

iiii)青蛙跳台阶
青蛙跳台阶是指青蛙可以一次跳1个或2个台阶,跳上n个台阶可以有多少种方法。
这样的题目我们可以简化为在跳上第n个台阶,我们就需要跳上第n-1个台阶或是跳上第n-2个台阶,再通过向上条1格或2格就能到达,所以跳上第n个台阶的方法就是跳上第n-1个台阶的方法+跳上第n-2个台阶的方法,所以代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int count(int n) {
if (n == 1)return 1;
if (n == 2)return 2;
return count(n - 1) + count(n - 2);
}
int main() {
printf("%d",count(3));
return 0;
}这里是求3个台阶的方法。
![]() 答案3是因为1+1+1和2+1和1+2这三种。
答案3是因为1+1+1和2+1和1+2这三种。
11)字符左旋
字符左旋就是指字符左旋是指将字符串中的前n个字符移动到字符串的末尾,其余字符保持不变。即字符串左边的一部分转移到右边,如abcdef可左旋为cdefab
代码上就可以一个个移动,每次移动后都要将其余字符左移。
这样便可以直接求出左旋字符,代码如下:
#include <stdio.h>
#include <string.h>
void left_move(char* ptr,int num) {
int len = strlen(ptr);
for (int i = 0; i < num; i++) {
char temp = ptr[0];
for (int j = 0; j < len - 1; j++) {
ptr[j] = ptr[j + 1];
}
ptr[len - 1] = temp;
}
}
int main() {
char arr[] = "abcdef";
left_move(arr,2);
printf("%s\n", arr);
return 0;
}但实际上,左旋可以直接看成把指定位置之内的元素和其余字符互换位置,但内部字符没有反转,即abcdef,如果要反转2个字符,就可以直接看成ab和cdef互换位置,得到cdefab,里面位置不反转。
但是这样反转需要将前面指定的这些字符都转到后面,如果一个个转就和上一段代码一样了,但假设我们将一段字符串翻转两次,这个字符串中每个字符就不变,那假设两个字符串,先内部转一次,外部再转一次,这样这样也能完成左旋。
#include <stdio.h>
#include <string.h>
void reverse(char* left, char* right) {
while (left < right) {
*left = *right ^ *left;
*right = *right ^ *left;
*left = *right ^ *left;;
left++;
right--;
}
}
void left_move(char* ptr,int num) {
int len = strlen(ptr);
reverse(ptr, ptr + num - 1);
reverse(ptr + num, ptr + len - 1);
reverse(ptr, ptr + len - 1);
}
int main() {
char arr[] = "abcdef";
left_move(arr,2);
printf("%s\n", arr);
return 0;
}当要判断字符是否左旋而来就可以一个个代入,左旋1次,2次,直到最后,如果没有匹配就不是左旋而来,
#include <stdio.h>
#include <string.h>
void reverse(char* left, char* right) {
while (left < right) {
*left = *right ^ *left;
*right = *right ^ *left;
*left = *right ^ *left;;
left++;
right--;
}
}
void left_move(char* ptr,char * ptr2) {
int len = strlen(ptr);
int num;
for (num = 0; num < len; num++) {
char temp = ptr[0];
for (int i = 0; i < len - 1; i++) {
ptr[i] = ptr[i + 1];
}
ptr[len - 1] = temp;
if (strcmp(ptr, ptr2) == 0)
{
printf("第二个字符串是由第一个字符串左旋而来,左旋的次数是%d", num+1);
return;
}
}
printf("不是左旋而来");
}
int main() {
char arr[] = "abcdef";
char arr2[] = "cdefab";
left_move(arr,arr2);
return 0;
}除此之外,还可以把一个字符串复制一份放到该字符串后面,然后进行模式匹配看待匹配字符串是否为拼接后的字符串即可,例如abcdef找cdefab,把第一个字符串使用strncat拼接一份(不能使用strcat因为strcat的结束标志是拷贝直到’\0’,自己拷贝自己会导致strcat一直无法读取到\0,导致死循环,但是strncat是 strncat(str1,str2,len),指定大小后就不会受到0的影响,直接手动输入即可),拼接完之后,字符串是abcdefabcdef,由于该字符串中含有cdefab字串,所以是左旋而来,模式匹配可以使用strstr(str1,str2)匹配,strstr找字串,在str1中找str2,如果能找到字符地址char*,否则返回NULL空指针。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
void judge_left_move(char* ptr,char * ptr2) {
strncat(ptr, ptr, strlen(ptr));
printf("%s\n%s\n", ptr,ptr2);
if (strstr(ptr, ptr2)!=NULL)
printf("左旋而来");
else
printf("不是左旋而来");
}
int main() {
char arr[] = "abcdef";
char arr2[] = "asdcde";
judge_left_move(arr,arr2);
return 0;
}假设代码这样写,随便的字串都是左旋了,所以还需要使用strlen判断长度是否正确
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
void judge_left_move(char* ptr,char * ptr2) {
strncat(ptr, ptr, strlen(ptr));
printf("%s\n%s\n", ptr,ptr2);
if (strstr(ptr, ptr2)!=NULL&&strlen(ptr2)==strlen(ptr))
printf("左旋而来");
else
printf("不是左旋而来");
}
int main() {
char arr[] = "abcdef";
char arr2[] = "cde";
judge_left_move(arr,arr2);
return 0;
}这样即可。
12)杨氏矩阵
杨氏矩阵就是个数字矩阵,每行从左到右递增,从上到下递增
假设希望找到一个值,我们可以使用内外for循环一个个比较,但是希望时间复杂度小于O(n),那就可以使用画线法。
由于每行从左到右递增,所以右侧的值为每行最大,由于从上到下递增,所以每列最下方最大,所以假设取右上角,如果待查找的数比这个数大,那这个数肯定在下几行,如果小,那肯定在该行左侧,假设取左下角,大就该行右侧,小就前几行,所以取这两个点就能明确待查找点的发现,那如果取左上角,比这个点大可能向右可能向下,右下角也同理。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <string.h>
void find(int ptr[3][3], int k, int row, int col) {
int i = 0;//行
int j = col-1;//列
while (i < row && j >= 0) {
if (ptr[i][j] > k)
j--;
else if (ptr[i][j] < k)
i++;
else {
printf("查找成功");
return;
}
}
printf("查找失败");
}
int main() {
int arr[3][3] = {1,2,3,4,5,6,7,8,9};
int k = 7;
find(arr, k, 3, 3);
return 0;
} 代码实现的效果就如图,这个待查找的值如果比这个右上角的值小,那么就左移直到相等或者找不到,如果大就下移,这个下移依旧不会改变其为一行的最大值的特性,一旦发现待查找的值小,就左移直到相等或找不到。
代码实现的效果就如图,这个待查找的值如果比这个右上角的值小,那么就左移直到相等或者找不到,如果大就下移,这个下移依旧不会改变其为一行的最大值的特性,一旦发现待查找的值小,就左移直到相等或找不到。
 左下角也同理,上移也不会影响其最小值的特性。
左下角也同理,上移也不会影响其最小值的特性。
13)找单独出现的数字问题
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,1,2,2,3,3,4,4,5,5,6,6,7 };
int s_n = 0;
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
s_n ^= arr[i];
printf("%d\n", s_n);
return 0;
}使用异或就能获得单独出现的数字
但当想找到两个单独出现的数字时,就需要进行分组异或,这个分组需要让相同的数组在同一组,让不同的数字在不同组,然后进行分别的异或,就能找到单独的两个值
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
int arr[] = { 1,1,2,2,3,3,4,4,5,5,6,6,7,8 };
int num = 0, pos = 0, s_n1 = 0, s_n2 = 0;
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
num ^= arr[i];
for(int i =0;i<sizeof(num);i++){
if (num >> i&1==1) {
pos = i;
break;
}
}
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
if (arr[i] >> pos & 1 == 1)
s_n1 ^= arr[i];
else
s_n2 ^= arr[i];
}
printf("第一个是%d,第二个是%d", s_n1, s_n2);
return 0;
}由于与1与只有两种可能,一种是1,一种是0,一开始使用异或,相同的为0,实际上就是不同的两个数异或,然后位移找不同(为1)的那一位,这一位就作为区分这两个不同数的分组依据
14)思维题:
1)赛马问题:
36匹马,6个跑道要至少比几次才能确定前三名。
36只比六把,得到6个第一,然后6只比一次,比出真正的第一,那么第一的那只马的那把的第二和第三有可能是真正的第二和第三,第二的那只马的那把的第二有可能是真正的第三,第三的那只马可能是真正的第三,所以3+2+1再比一趟,共比8次。
改编:假设变为25匹马
答:5跑道先跑5次,第六次出来第一,因为第六次的第一名就是第一名没必要参加比赛,第七次刚好就2+2+1只马比赛刚好5只,共比7次。
2)烧香问题:
一根香不均匀,烧完要1小时
有两根香,确定15分钟
第一根首尾点燃,烧完刚好半小时,然后第二根在第一根点燃时烧了半小时,还剩下半小时,第一根烧完后第二根首尾点燃就剩下30/2分钟即15分钟。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









