







目录
8.2.2.@Data与@AllArgsConstructor与@NoArgsConstructor
9.3.@JosnFormat与@DataTimeFormat
9.6.@Bean与@ConditionalOnMissingBean的区别
9.9.@ReuqestParm与@ModelAttribute的区别
9.10.为什么java操作Redis方法里的参数类型不同于Redis
前言:
我用了12天学完了苍穹外卖(最后的前端部分没有学习),总共写了10天的笔记,对于苍穹外卖整体感受就是这个项目是非常适合新手入门的项目,代码层面并不复杂,其中细节很多,有助于开发人员形成一个代码规范(三层架构,封装数据),而这篇文章会将一些重要的知识点细节全部展示出来,让刚开始入手苍穹外卖的你们更容易了解这个项目,提高对应项目的认知。
1.项目介绍:
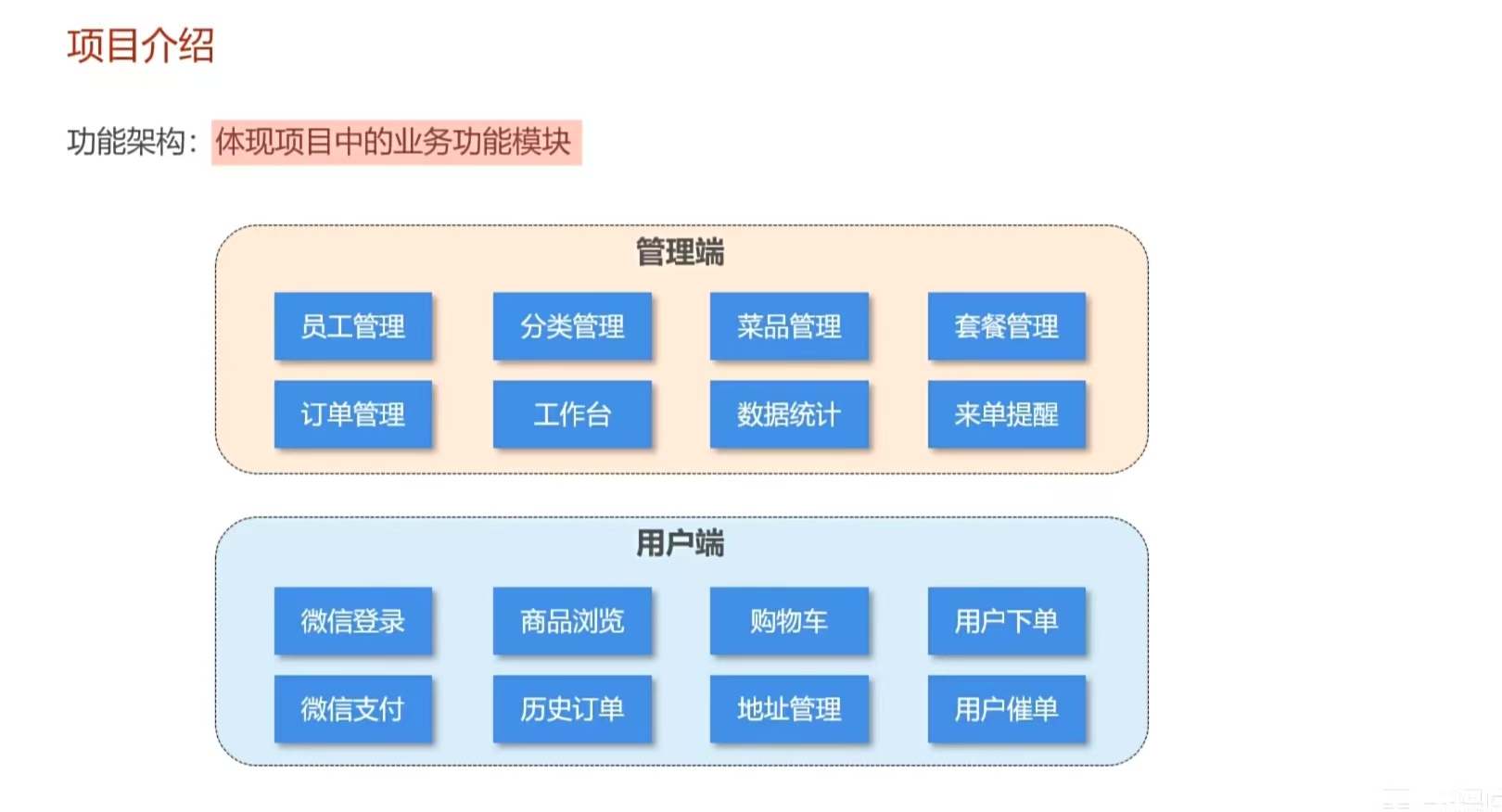
这个项目是一个关于外卖点餐的产品(已经封装好了,只需要将数据修改成自己的信息就可以直接使用),分为用户端和管理端。实现了用户点餐,商家接单的一系列业务
管理端
用户端(修改了一下)
2.业务板块介绍:
3.技术选型:

4.用户层:
4.1.微信小程序
4.1.1.服务端如何登录
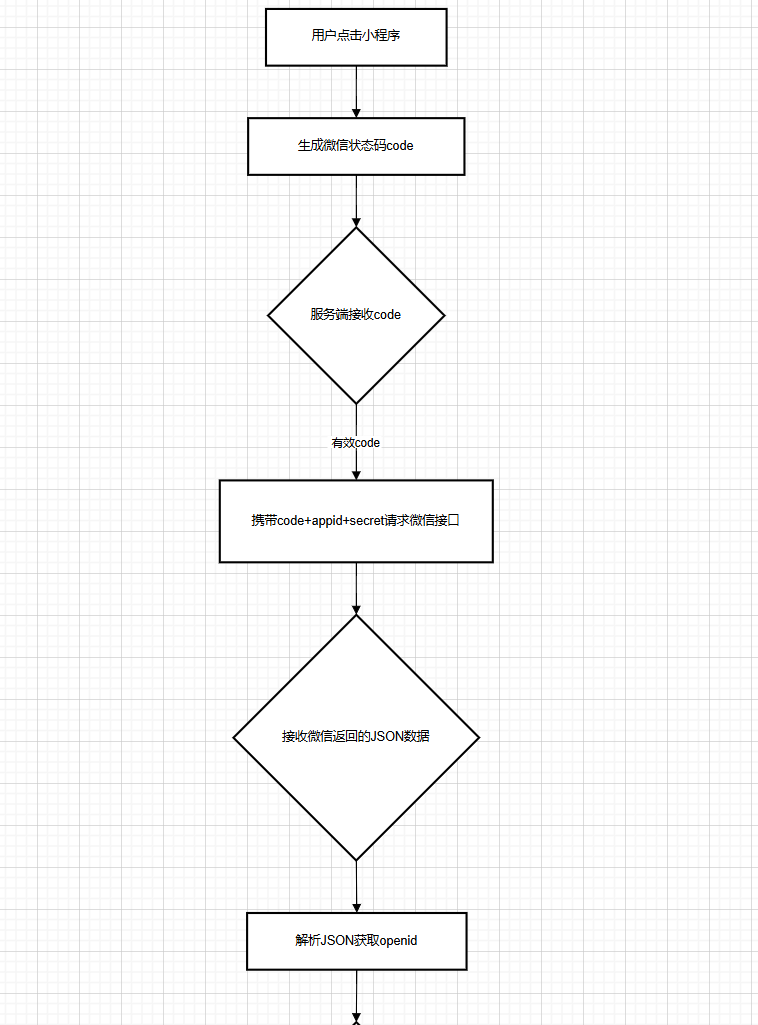
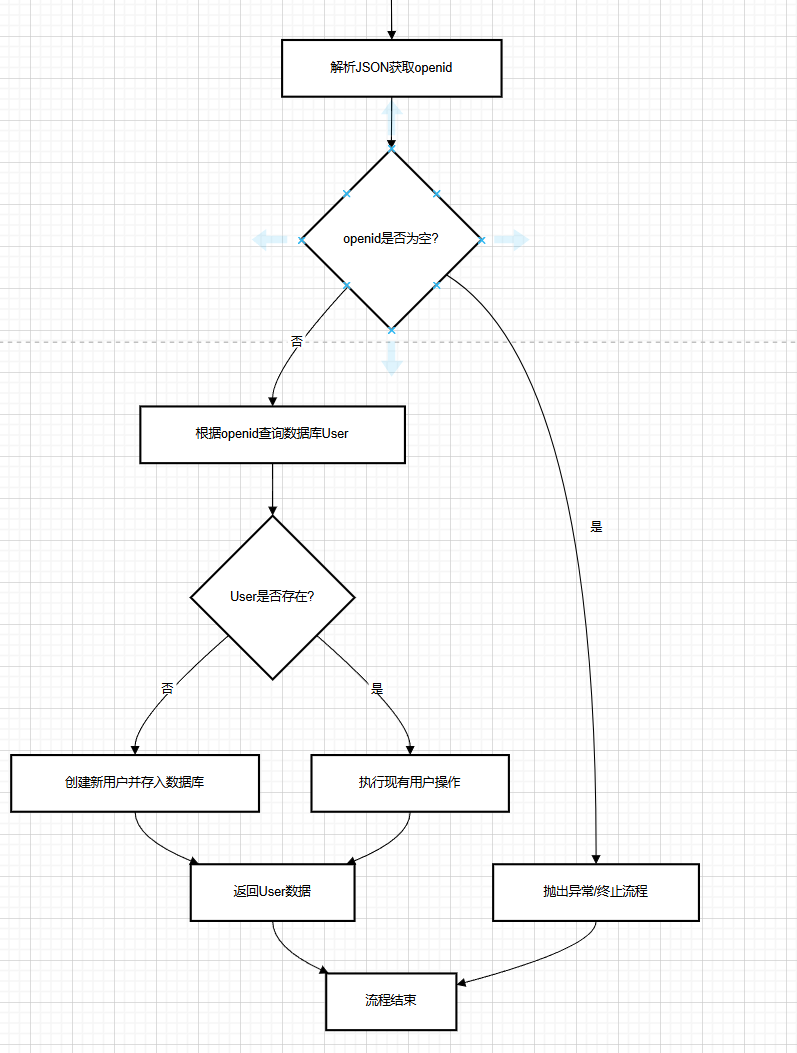
具体流程: 微信小程序开始编译(用户点击)生成微信状态码code
=》 服务端接收code(只能使用一次)
=》 服务端传出code与自己小程序的id与密钥参数访问微信接口服务
=》 接收微信接口服务传递过来的参数(JSON数据)
=》 进行JSON转换获取openid(用户微信的唯一标识)
=》 判断是否为空 =》 为空则抛出异常,不为空则在进行操作
=》 根据openid查询数据库
=》 判断数据库中User是否有值
=》 没有,则是新用户登录,将用户数据存入数据库 /有则是进行操作
=》 最终返回User数据
4.1.2.微信小程序注意事项
1.我们获取的code是微信的授权码,用这个授权码就可以获取关于用户登录时的信息(授权码只能使用一次)
2.获取的openid则是用户微信的唯一标识(每个用户的标识都不同),唯一想到什么,数据唯一,我们可以用这个来判断该用户是否注册(在数据库查询)
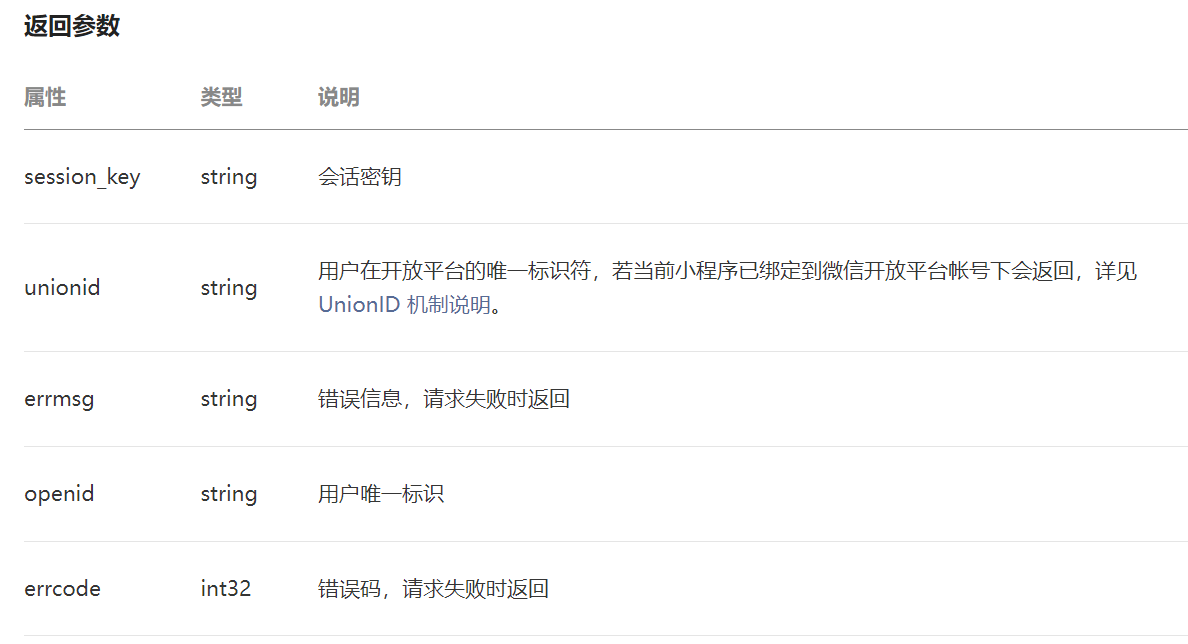
3.用授权码code来获取openid需要访问https://api.weixin.qq.com/sns/jscode2session(地址固定)
用地址栏传参(参数名固定,最后一个参数值也固定)(地址?参数名=值&参数名=值)

返回参数(我们这里只需要openid即可)
4.上面涉及到小程序的密钥,我们生成的时候记得保存下来,不然你后面来查询不到(只能重新生成)
5.返回参数的类型是JSON字符串的数据,我们需要将其转换成java能够识别的数据
4.2.Apache-Echarts
1.简介:它是进行图表设计的数据可视化技术
2.实现:其实就是根据官网要你后端返回的数据格式,你按照它的格式返回就行了
3.注意:查询数据库时,如果没有查到数据会返回个null,所以我们需要考虑返回null的情况
5.网关层:
5.1.Nginx
5.1.1介绍:
1.nginx一款开源的高性能 Web 服务器
2.核心特点:反向代理(保护服务端安全),负载均衡,内容缓存(提高访问效率)...
3.内容缓存:客户端访问服务端,先访问nginx的代理服务器,再将请求发送给服务端,nginx相当于有个缓冲区,如果你快速访问多个相同的请求那么nginx在第二个请求时将不会在访问服务器,而是在缓存区中取出数据返回给客户端
4.简单看一下
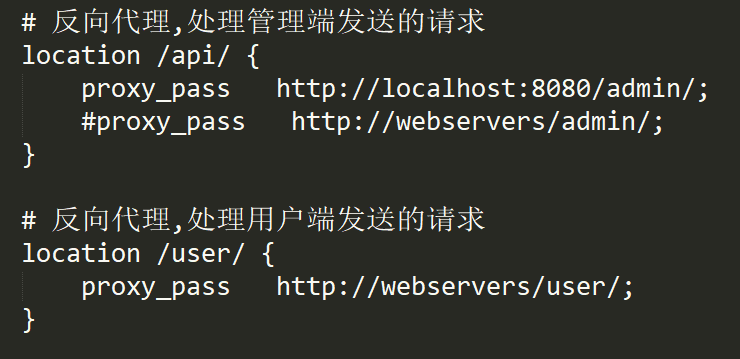
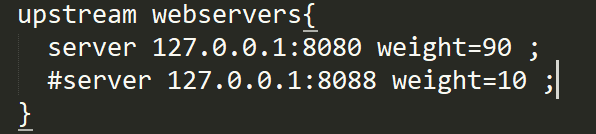
就是拦截api和user这个请求,替换proxy_pass:后面的请求,而webservers是你定义的请求路径,最终替换http://admin/127.0.0.1:8080http://admin/(用户端一样的,weight与负载均衡有关)
5.1.2.反向代理
1.隐藏服务端:很好理解,客户端是不是只能访问到我们的代理服务器,那我们暴露给客户端的地址是不是就是代理服务器的,而代理服务器可以将客户端访问的地址进行替换变成我们真实的服务端地址,从而保护了服务端,避免服务端的地址暴露出去(有危险)
2.实现负载均衡:在下面
3.缓存加速:参考上面的内容缓存
5.1.3.正向代理
1.隐藏客户端:和上面同理(上面是接收到真实客户端地址,假的服务端,这里就是反过来),就是由客户端来配置代理服务器,通过代理转发到服务端,服务端看到的是代理的地址
2.突破访问限制:(魔法)
3.缓存加速:参考上面的内容缓存
5.1.4.负载均衡
1.负载均衡就是把我们访问的请求按照指定的方式来均衡的分配给集群的每台服务器
2.可选方式:
6.应用层:
6.1.Swagger与knife4j与Yapi
1.老师使用了knife4j工具来简化Swagger
2.Swagger与knife4j:我目前了解的是通过相应注解可以实现接口规范,就是直接给你生成一个接口实现,前端可以依据它,减少沟通成本
3.Yapi好像是淘汰了,我建议使用最新工具Apifox(Swagger与knife4j与Yapi的功能都有)

1.引入knife4j依赖
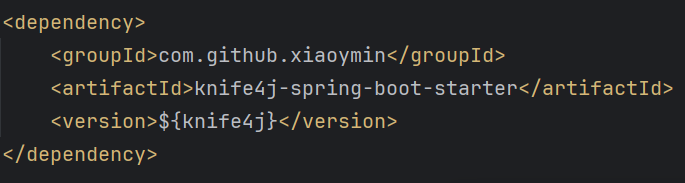
2. 配置
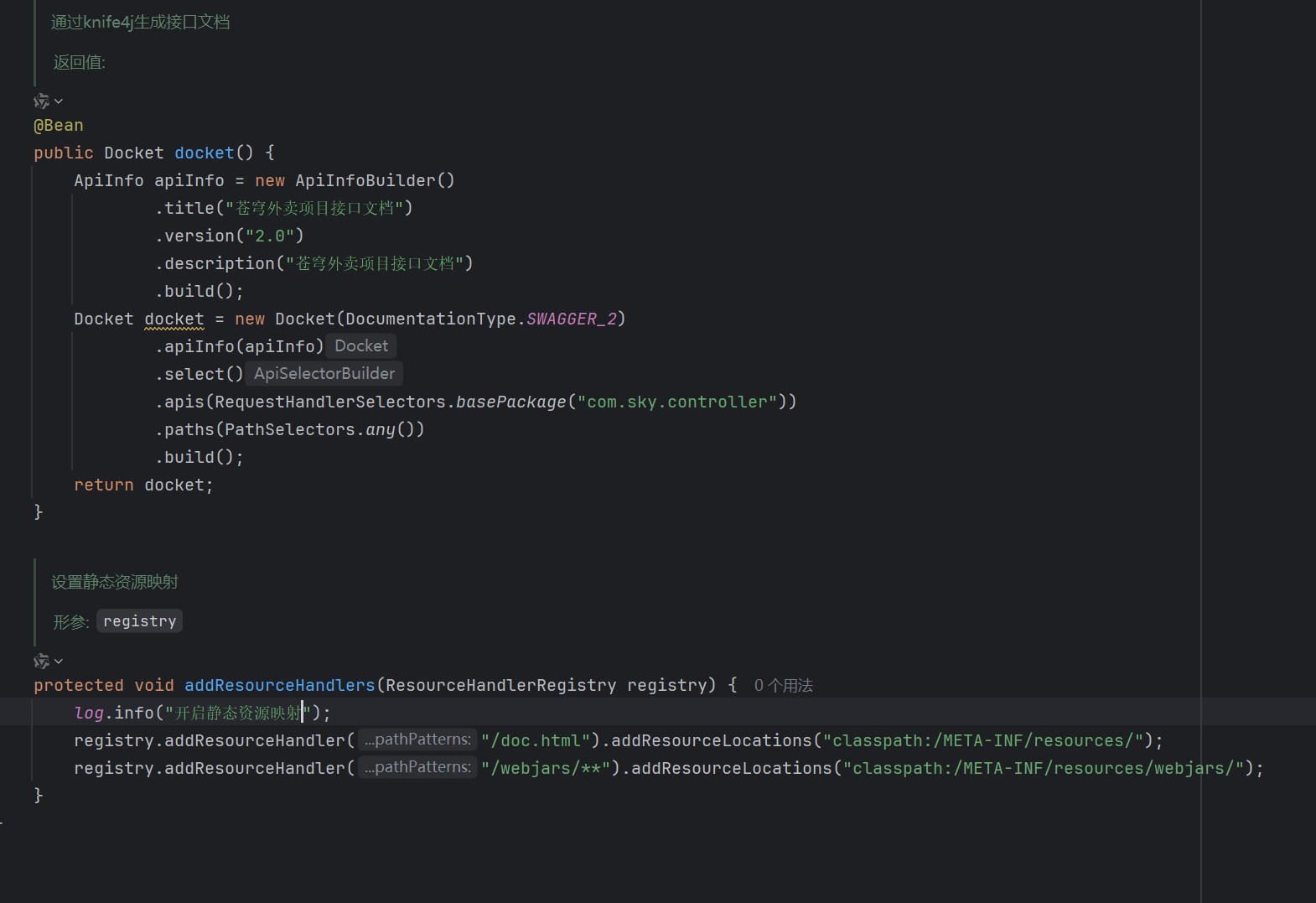
3.最核心的是它的注解的使用
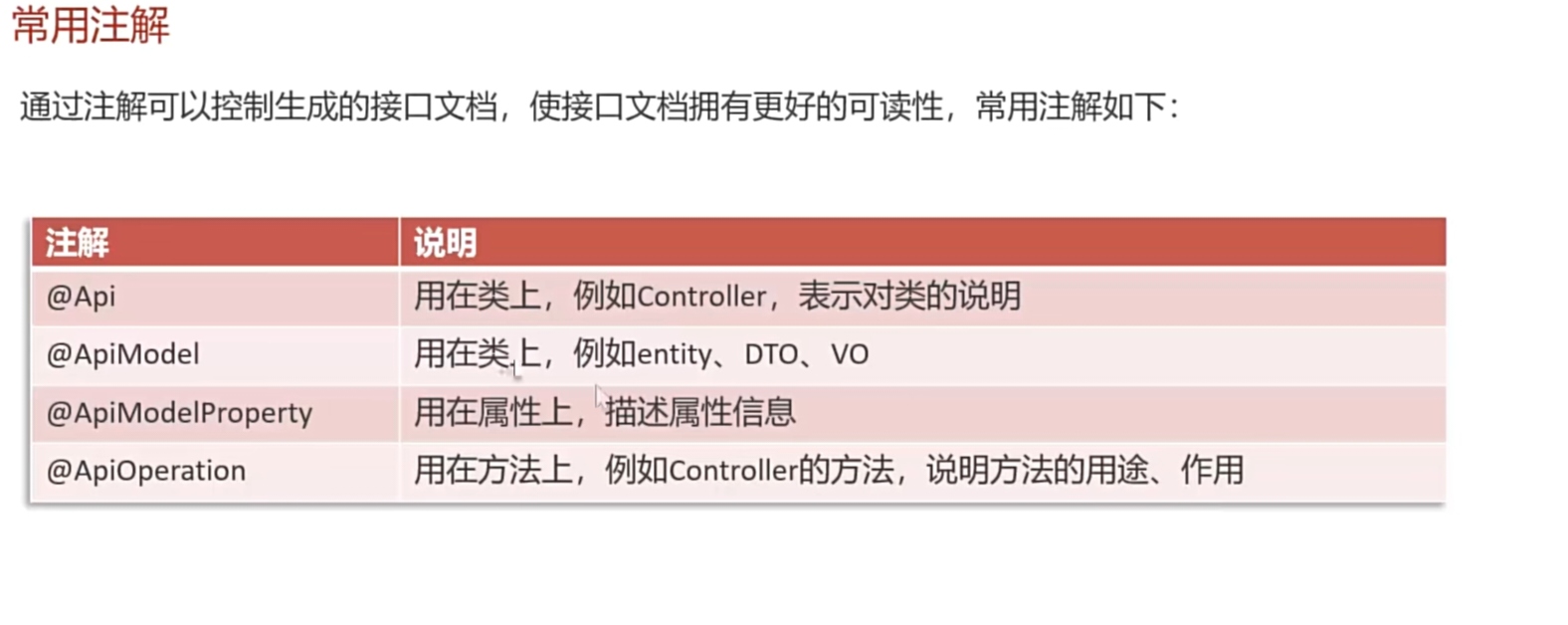
解释一下:
1. @Api就是作用于Controller上的(效果)
2.@ApiModel就是作用到封装类中的(类上注入)
3.@ApiModelProperty就是作用于实体类属性上的(属性注入)
4.@ApiOperation就是作用于Controller方法上的(方法注入)
6.2.JWT与ThreadLocal
1.为什么要使用到它:你想这是一个外卖系统涉及到登录操作,如果有人没有登录就直接通过路径来访问相应功能,那么是不是应该进行一个校验(这里使用的JWT令牌校验),通过才能访问,下面图片是JWT令牌的实现过程
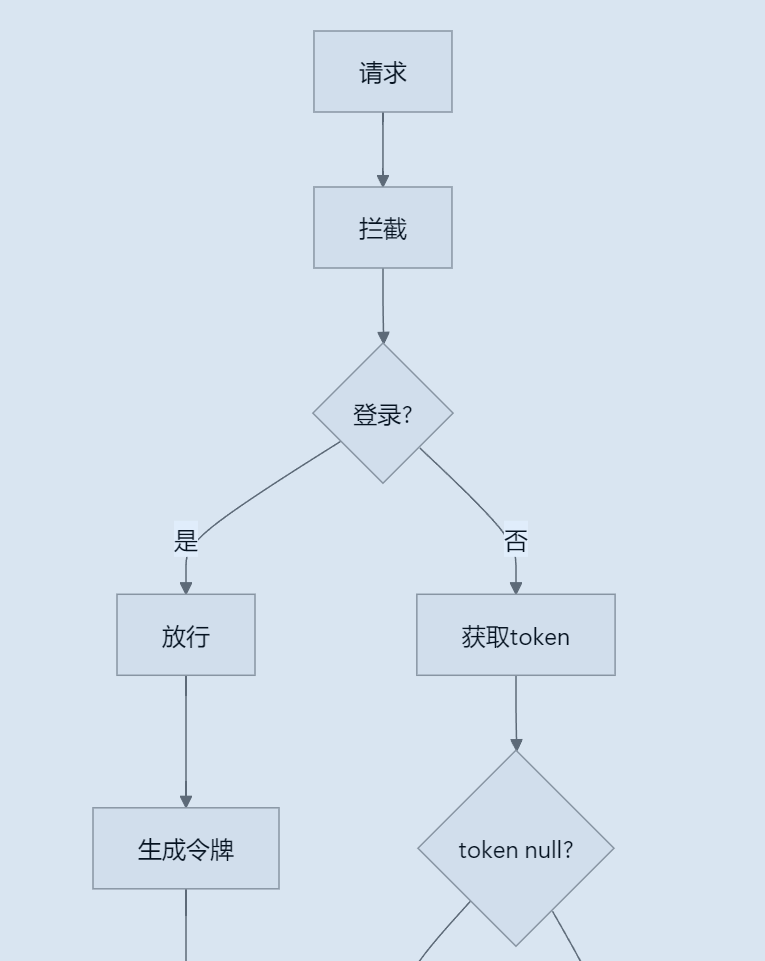
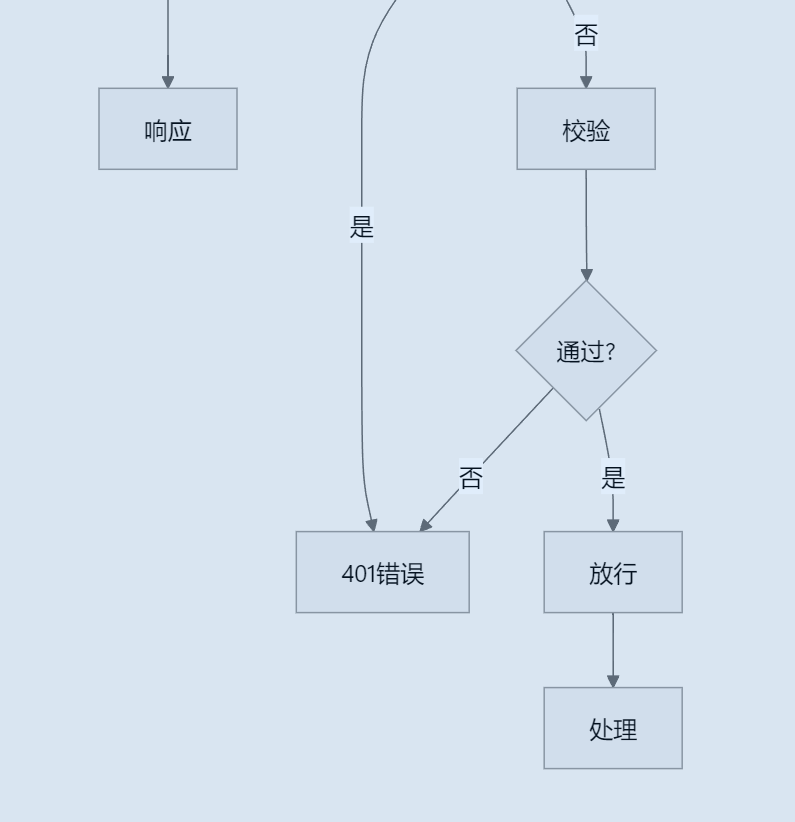
了解这个过程后,登录人是不是有唯一标识ID,如果你去操作某个功能,是不是要记录下你的操作记录,那么管理端是不是要根据ID,来确认是谁在操作,所以这个功能就是有它来实现的
2.先了解一下它:执行一个任务时是不是有多个线程来执行(抢票是不是多个人同时抢),而ThreadLocal就是每个线程自己特有的空间,别的线程不能访问(下面是它的方法)

3.进行思考:那么怎么实现这个取出登录人ID的操作呢?登录是不是也要一个接口来实现,那么服务端就必须有对应代码来实现(是不是就是查询数据库,有数据就登录成功,没有则失败),登录成功时,我们会接收到登录人的信息(包含ID),那么我们是不是可以先实现准备一个线程的ThreadLocal (登录操作肯定是一个线程在完成) (如图)
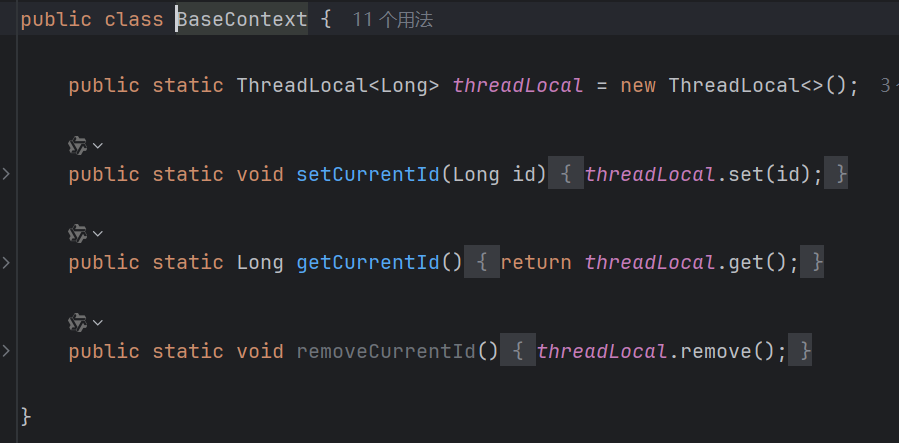
我们将登录人ID赋值给ThreadLocal ,那么现在这个ThreadLocal是不是确定下来了,以后你要操作人ID,你从ThreadLocal中取出来就行了
4.进行ThreadLocal的移除
6.3.Aop(面向切面的思想 )
1.Oop(面对对象)是不是通过封装对象来实现相应功能,而不是用单一属性,而Aop思想就是把冗余的代码抽离出来(假如有部分方法里都要实现这段代码,我们就可以抽离出来,进行封装)(动态代理)
2.环绕通知是最重要的(拦截器///过滤器是不是要先拦截校验(之前说过,是不是可以进行ThreadLocal存值),通过则放行(执行方法会取出值),执行完返回(移除TreadLocal))
3.利用Aop可以解决代码冗余,提高代码复用性(抽离处重复代码),那么是不是也增强了代码的可维护性和扩展性(只需要该这一处就行)
6.4.文件上传功能(阿里OSS)
1.为什么要实现这个功能:你前端页面是不是要展示你的文件数据(图片),怎么展示呢?
2.具体实现:通过用户上传文件 --> 前端将文件传到服务端 --> 服务端接收到文件 --> 调用阿里云OSS将文件存入OSS --> OSS再返回这个存入文件的访问路径(访问这个路径可以直接下载该文件)--> 服务端接收路径存入数据库 --> 再返回这个路径给前端 --> 前端访问这个路径直接下载这个文件将其展示在页面上
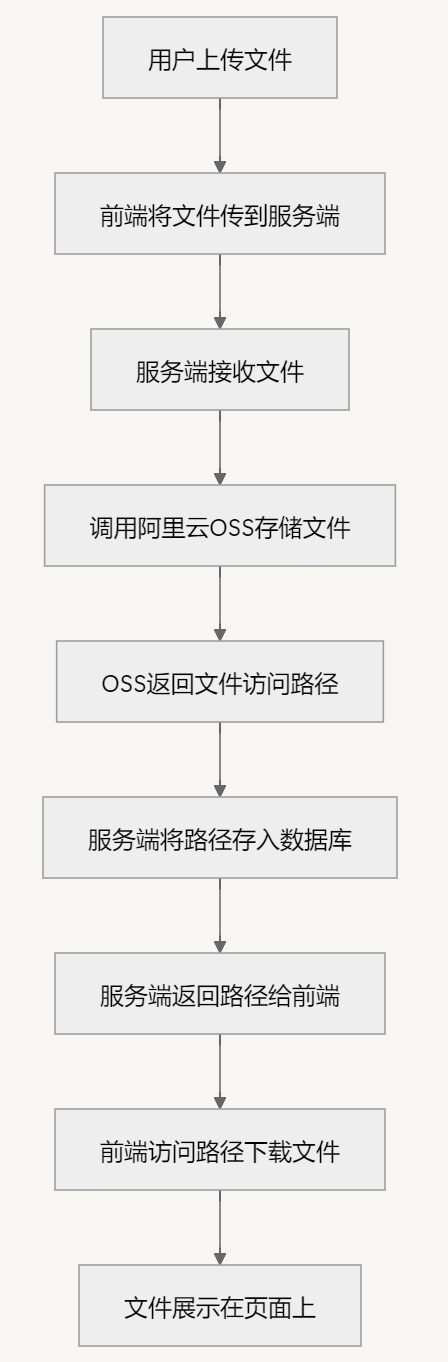
3.建议自己会去定义关于操作阿里云OSS的工具类
4.注意:接收前端传过来的文件参数时,接收参数(类型:MultipartFile)要保持与文件参数名一致

6.5.Spring Cache
6.5.1.简介:
Spring Cache基于代理(代理其方法,执行相应存缓存清理缓存的操作)
6.5.2.@CachePut
1.介绍:实现缓存存储
2.实现:
必写属性:cacheNames="名称" ==》指定缓存名称
key="Spring表达式语言" ==》下面
key的写法:
1.#方法形参名(如#user)
2.#result(方法返回值)
3.#p0(方法的第一位形参,依次类推#p1第二位形参)
4#a0(与3相同,就名称变了)
5.#root.args[](数组里填0,就代表方法第一位形参)
6.点 . 代表对象导航(就是取出对象里面的具体属性,如#user.name)
7.其实上面的最终作用就是生成一个key(只不过你可以利用不同的数据)
3.疑问:有什么用啊
1.因为用注解修饰,它是自动帮你存入缓存数据库中(Redis),那么你是不是需要指定一个key给它,值给你存
2.而且key是不是要不重复,而且key要定义的有意义,规律
3.而上面的两个属性就是来实现key的名称的
4.cacheNames代表的是这个类型数据的前缀名称(保持相同即可)
5. key则是你需要特意设置的不同值
6.最终组成效果:如cacheNames="userCache" ,key="#user.id"
=》userCache::id(具体值)
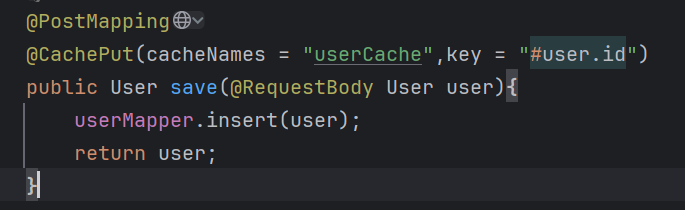
注意:该注解是先执行完方法后才会执行注解的缓存功能(因此才能使用返回值数据)(一般#参数名称,使用的最多,其他的你可以自己翻看源码里面全部都有解释)
6.5.3.@Cacheable
1.介绍:执行方法之前会拿cacheNames+key属性组成的key去Redis中查询,能查到数据直接返回该数据,不执行方法,不能查到数据,则是执行方法,再将方法的返回值存入Redis中
2.该注解的属性与@CachePut属性基本一致(名称一样,唯一不同就是key没有#result这个写法了,从介绍知)
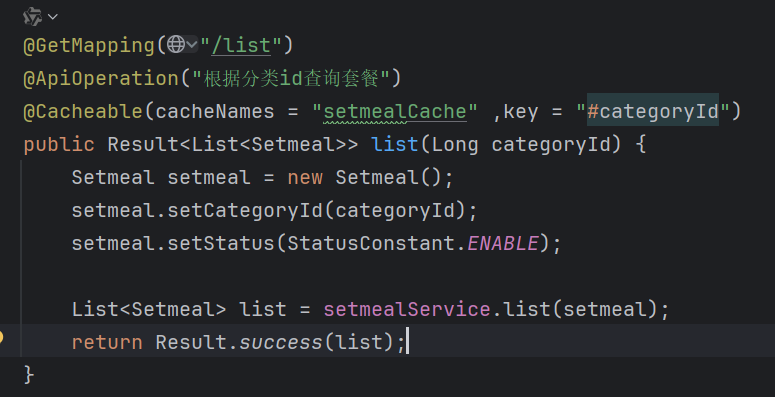
3.注意:该注解优先方法执行(先查Redis,没有执行方法,将方法返回值存入Redis)
6.5.4.@CacheEvict
1.介绍:方法执行完成后,会根据cacheNames+key属性组成的key去Redis中删除单一数据,如果你想要删除所有数据,那么将key换成allEntries(设置该属性为true,则是删除所有数据,false则不删数据)
2.该注解的属性用法与@Cacheable基本一致
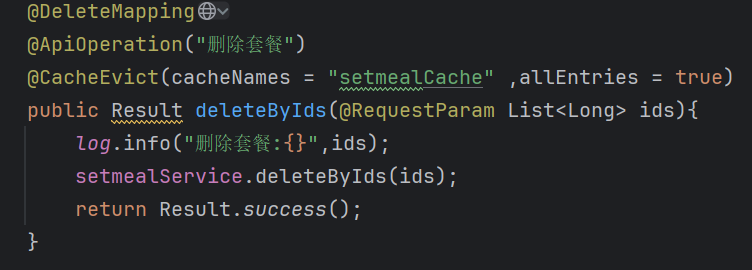
3.注意:该注解功能是方法执行完成之后才进行删除操作
6.6.Spring Task
1.介绍:Spring Task是由Spring提供的,可以用来定时去执行某些代码的逻辑
2.应用场景:信用卡还款,售票系统处理未支付订单
3.使用步骤:
1.导入坐标(由于是Spring提供,它已经在Spring依赖中)
2.启动类添加注解@EnableScheduling开启任务调度
3.自定义定时任务类中添加注解@Component(注入Spring容器中)
4.类中的方法来具体实现代码逻辑
5.类中的方法返回值必须为void ,方法名任意,并且在方法上加入注解@Scheduled,实现注解里面的属性
4.@Scheduled
具有写法 : @Scheduled(cron="填入cron表达式")
5.cron表达式:
1.简单来说就是你指定什么时候来执行这个代码的逻辑(每分钟执行一次这个代码)
2.它有6/7个域(秒,分,时,日,月,周,年),为什么是6或7?==》因为年是可以选的,可以选择不写
3.注意:日和周只能定义一个(一个存在,一个就必须不存在,用?表示),表达式中不同的符号表示不同的含义,而我们不需要掌握如何书写该表达式(问Ai),我们只需要会指定我们的需求就行
6.明确两个点:指定什么时候执行,具体执行的代码
6.7.WebSocket
1.介绍:它是基于TCP的一种网络协议
2.WebSocket与HTTP协议的区别:
1.web Socket只需要一次握手就可以建立持久性的连接,并且支持双向传输数据
2.HTTP需要三次握手,四次挥手来建立短连接,它是请求响应模式(前端请求后端响应)(单向的)
3.它们都是基于TCP的一种网络协议
3.实现:
1.导入坐标
2.导入组件用于通信
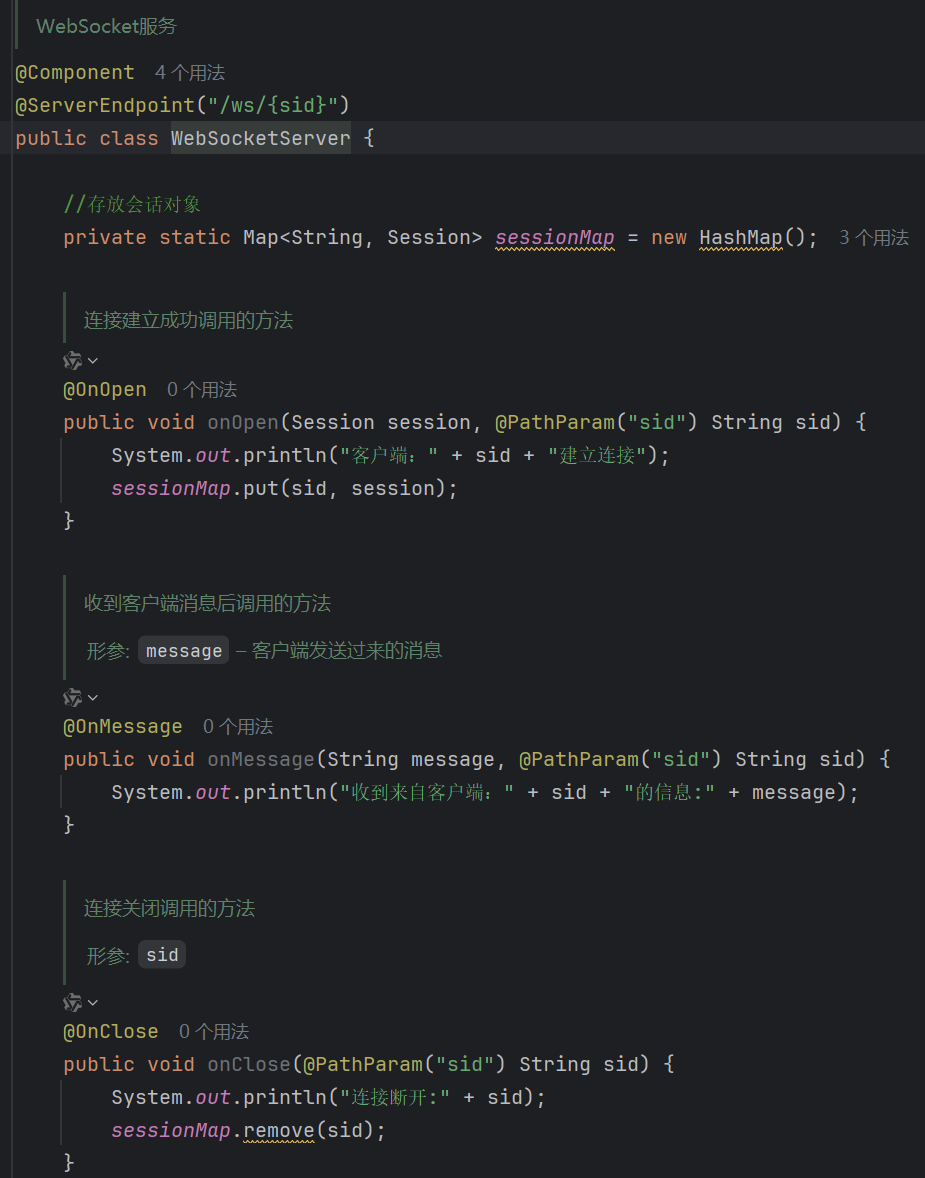
3.在配置类中注册组件
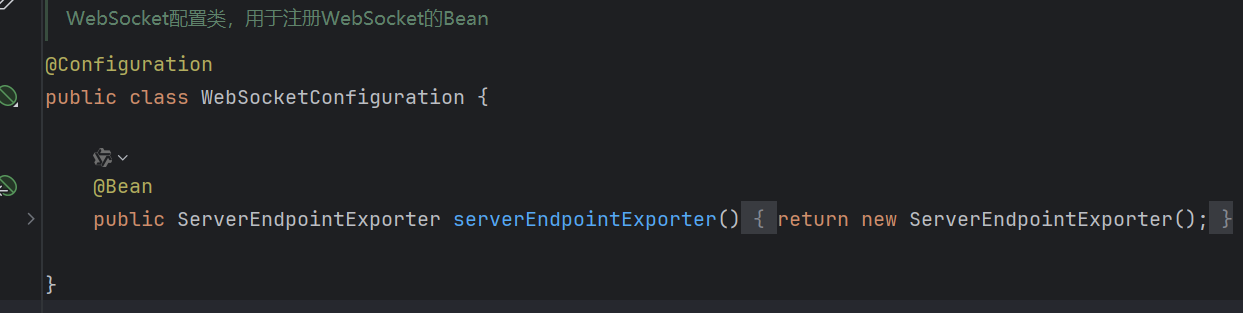
4.实现自己的需求(向客户端发送消息)
4.怎么写组件:
1.定义一个类,添加注解@Component,@ServerEndpoint(和@RequestMapping一样写前端请求地址)
2.定义多个方法,添加注解@OnOpen,@OnMessage,@OnClose
5.注解的解释:
1.@OnOpen:添加了这个注解的方法会在客户端和服务端建立连接后调用
2.@OnMessage:添加了这个注解的方法是在服务端收到客户端消息后调用该方法(类似于Controller中的方法)
3.@OnClose:添加了这个注解的方法是在连接关闭后调用的方法
6.群发功能:
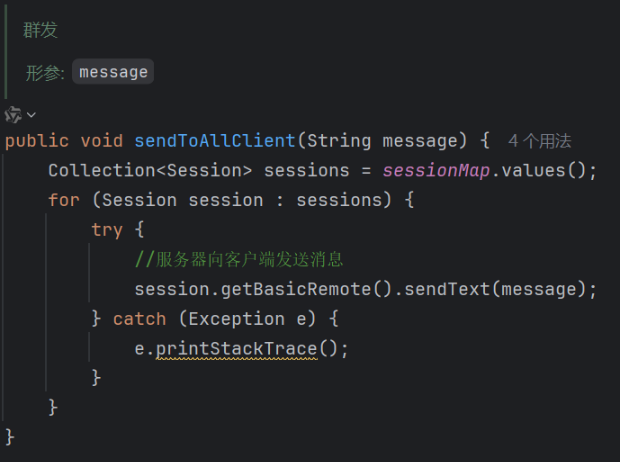
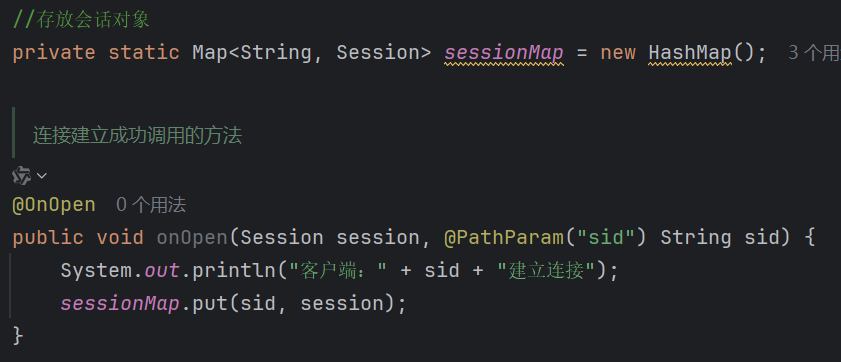
原理:在连接成功后调用一个方法存入客户端传来的标识
那么等我们需要群发时可以直接调用sendToAllClient实现群发
6.8.Apache-POL
1.简介:处理Microsoft office各种文件(可以在java程序中操作文件进行读写,一般操作Excel)
2.应用场景:银行系统导出交易明细,各种业务导出Excel报表
实现:导入坐标,如何使用就行了

3.具体操作Excel
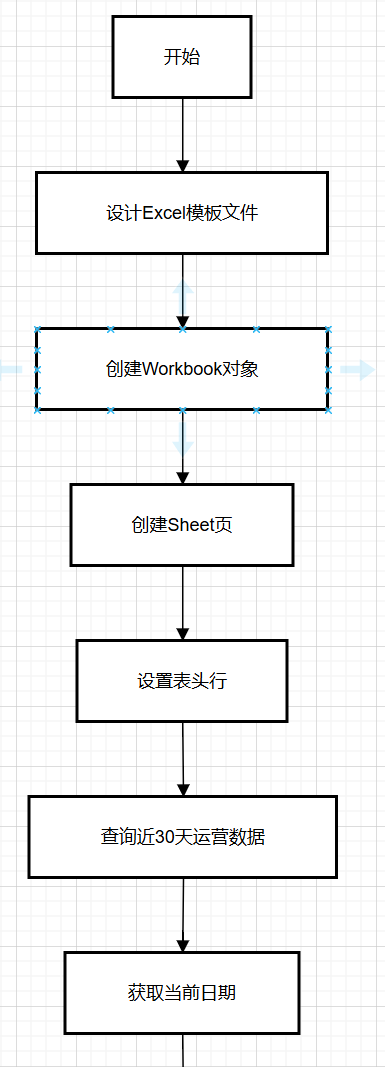
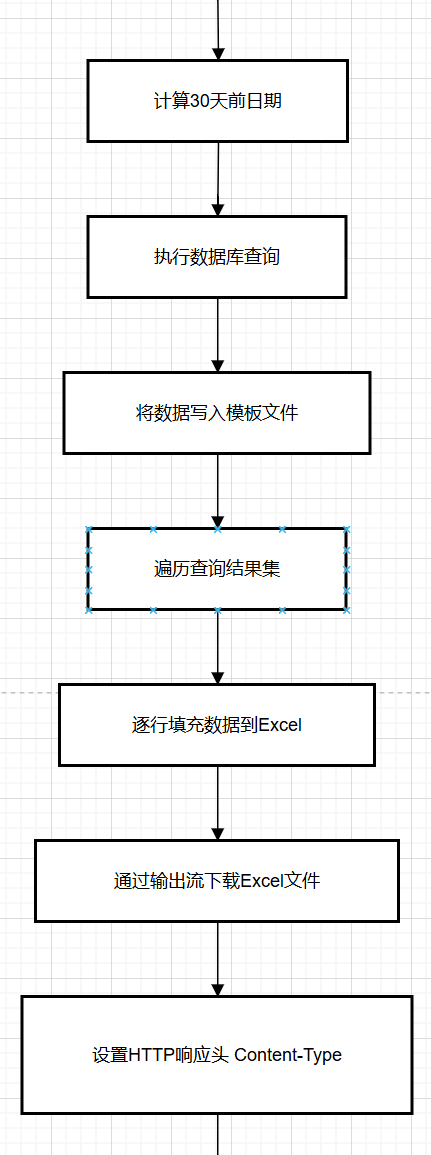
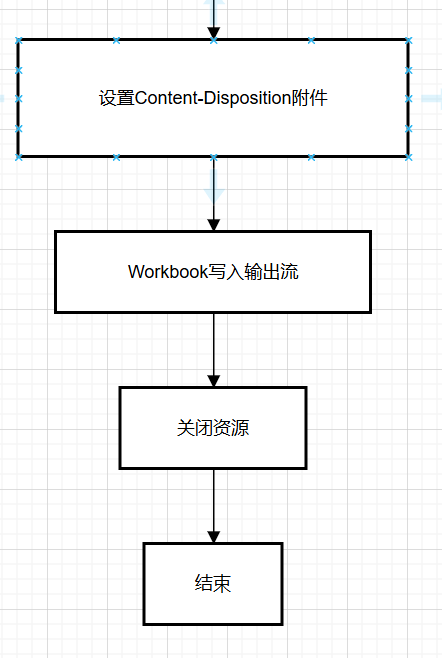
1.步骤:
1.设计Excel模板文件
2.查询近30天的运营数据
3.将数据写入模板文件中
4.通过输出流将Excel文件下载到客户端浏览器中
2.操作数据写入
3.具体操作:
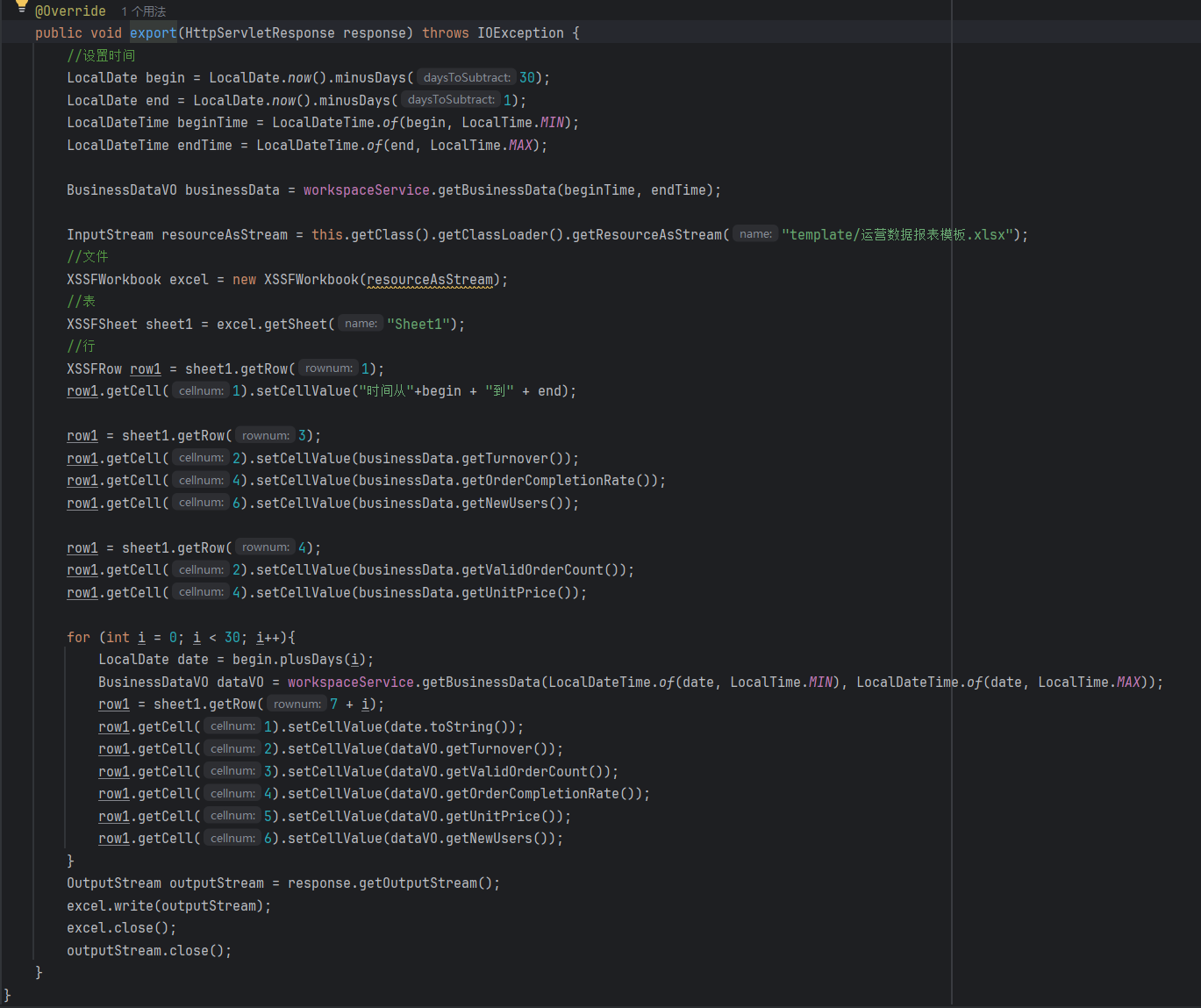
1.获取Excel文件:创建对象XSSFWorkbook(如果你初始化时指定了一个Path路径,然后文件不存在它会默认帮你创建这个Excel文件),当然这种方式只可以写入Excel文件,如果你需要读出数据,那么你创建对象时需要指定一个InputStream,来实现读出
2.获取Excel中的表(Sheet),使用Excel对象调用getSheet("这里面只能指定表格名称")即可(看方法名称就行)
3.获取表中的行,使用Sheet表对象调用getRow(),这个方法你就必须指定索引(索引从0开始)
4.获取行中的单元格,使用Row行对象调用getCell(),这个方法你就必须指定索引(索引从0开始),你获取到了单元格你就可以赋值使用setCellValue()
4.小技巧:你可以根据实现类所需形参的类型来创建对应对象(特别是IO流这里)
7.数据层:
7.1.PageHelper
1.介绍:PageHelper是Mybatis提供的一个插件
2.怎么使用:(先导入依赖)

先看一下
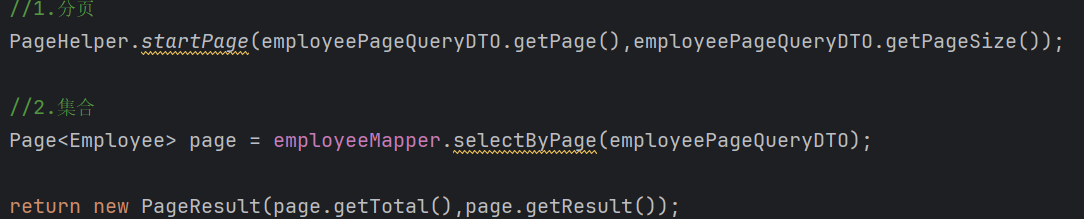
就是你给它一个页码值和页数值,它会动态的进行分页查询,我们不需要再写Limit
3.原理:它是基于TreadLocal来实现的,上面说了TreadLocal是不是可以存值,而PageHelper就是基于它来进行的存(页码值,页数值),等我们的SQL语句实现的时候就会拿出来动态的进行分页查询(类似于动态SQL)
4.上面为什么调用selectByPage时(明明返回的应该是一个集合,怎么用Page来接收),其实Page是继承于ArrayList集合的(增加了一些功能,它可以获取总页码(getTotal(),下面的第一条语句就是来获取总数),我们真实的数据(那个集合)通过getResult()来获取数据库返回的数据),

5.注意:PageHelper只能对它下面的第一个Mapper的SQL语句进行动态查询
7.2.Redis的基本使用
1.Redis的Windows版本似乎好久没有更新了,在Redis中没有用户名的概念,只有密码(在Windows版本中是在配置类中更改密码)
![]()
在该配置类中找到
![]()
将注释解除,requirepass 后面接的就是你的密码
2.Mysql与Redis命令的区别:Mysql的命名是不区分类型的,而Redis则是区分类型
3.Redis的基本类型:

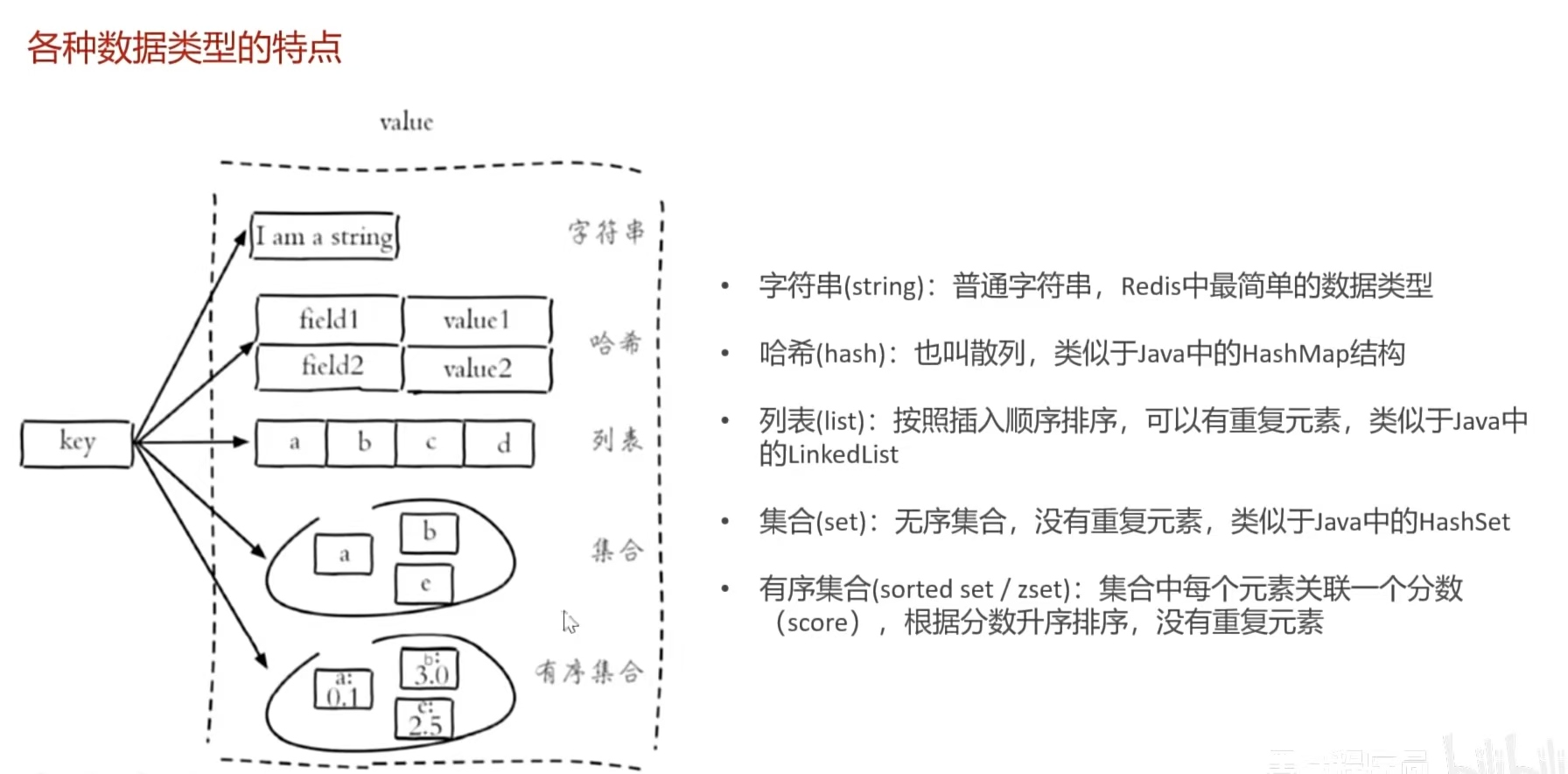
4.Redis字符串类型命令:

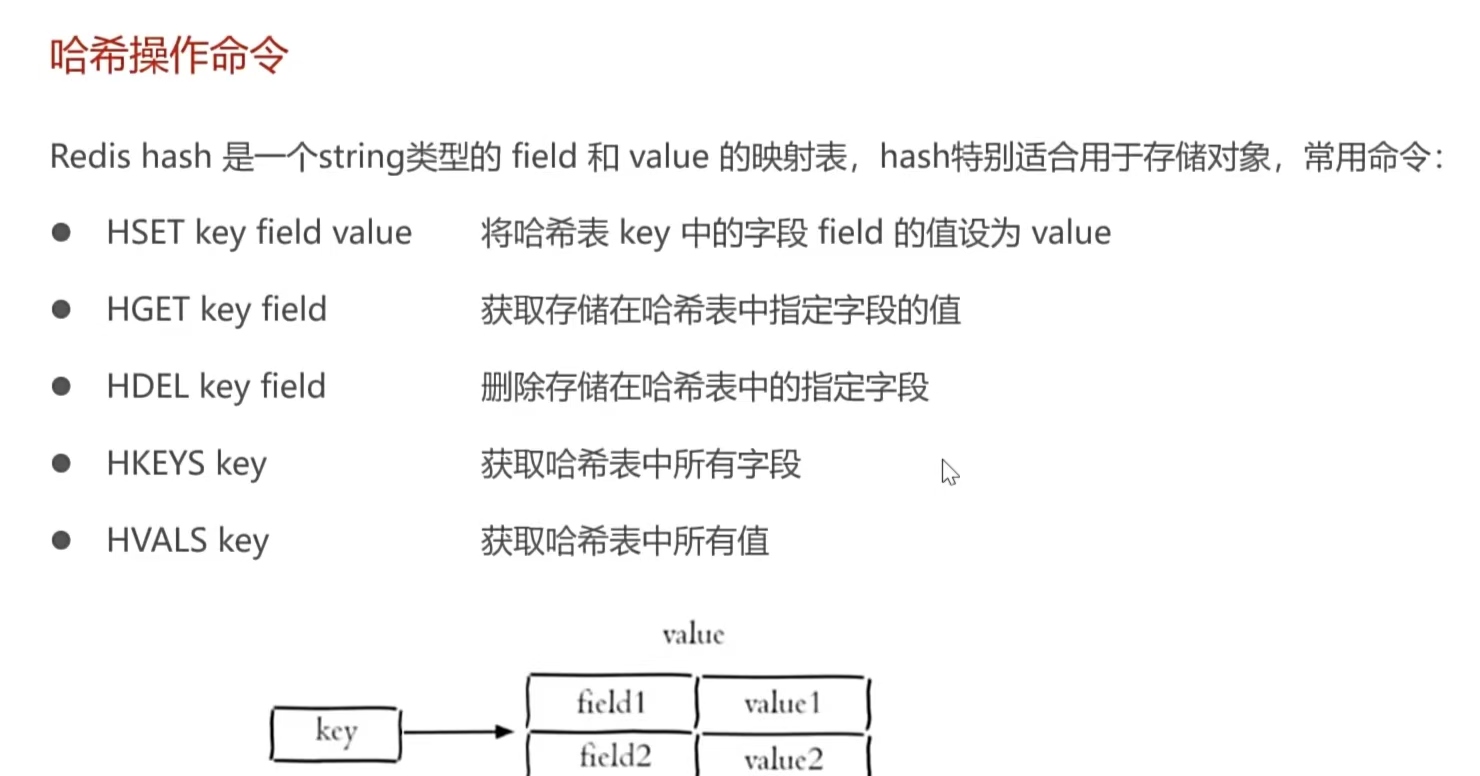
5.Redis哈希类型命令:
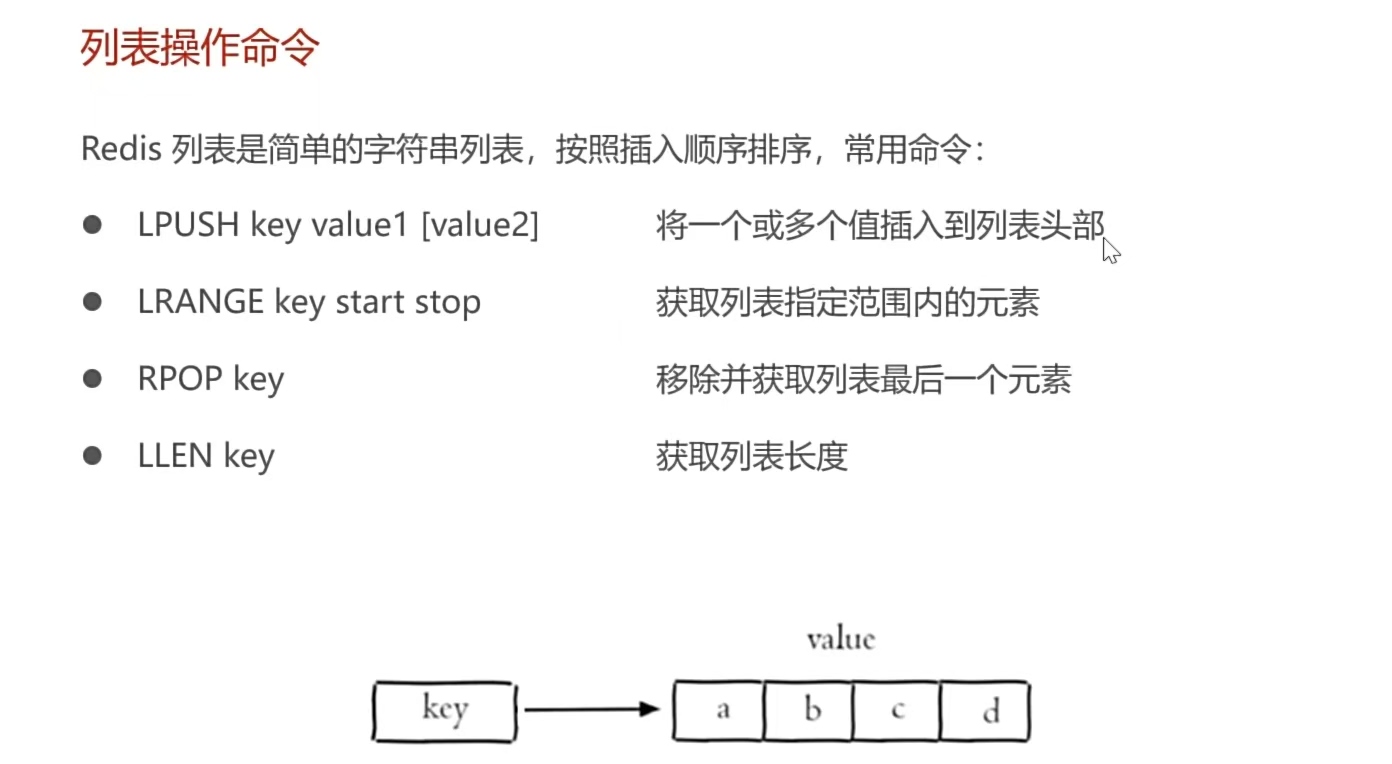
6.Redis列表类型命令:
7.Redis集合类型命令:
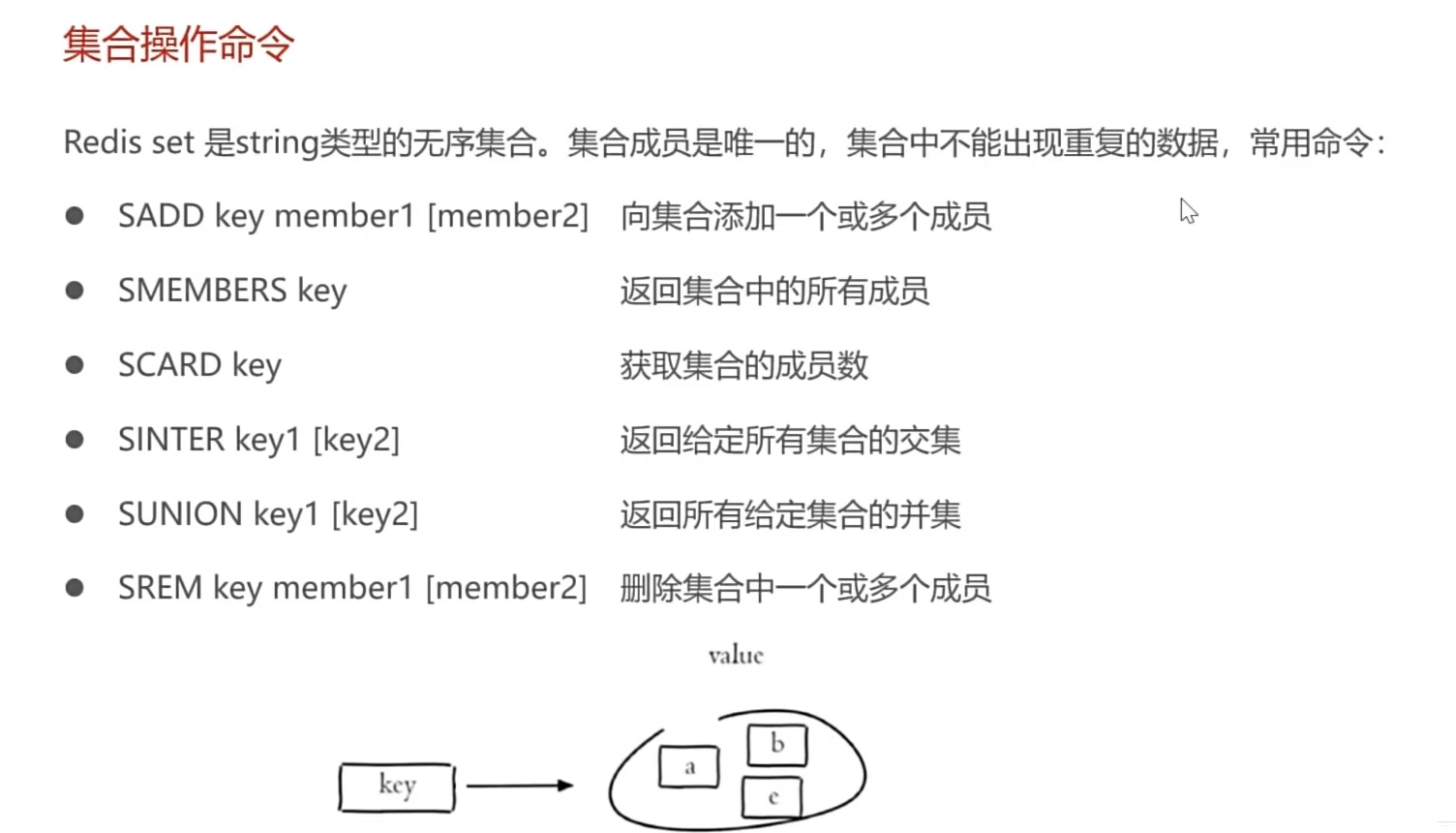
8.Redis有序集合类型命令:

9.Redis通用命令:

10总结:
1.在Redis命令使用时返回的是1就代表执行成功,0就是失败
2.在字符串类型命令中set与setnx的区别:set是如果key存在,那么会覆盖之前value(没有就创建,有就不覆盖),而setnx则是key存在,不会覆盖(没有就创建,有就不操作)
3.在字符串类型命令中setex可以设置过期时间(指定30秒,30秒后结束那么Redis就会自动删除该key),所以我们可以想到什么场景 =》验证码(它是会过期的)
4.在哈希类型命令中没有什么注意的,不过哈希的key与field不好记忆,一个简单理解的方法
=》你将key看作Mysql中的table(表),而field就是表中的ID,value就是具体的数据
5.在列表类型命令中要注意一下添加命令lpush:它每次添加数据都是从最左侧添加(先添加a后添加b,那么它们的顺序是:b a)(看作队列)
6.在列表类型命令中怎么使用查询命令lrange:就是指定索引,开始索引和结束索引(结束索引有点不同与java),开始索引(一般写0,索引从0开始的),而结束索引(写-1代表列表的最后一个元素,-2代表倒数第二个元素,依次推)
7.在有序集合类型(不允许重复,分数为double类型)命令中查询命令zrange中可以加一个参数:withscores,加了这个参数会将分数也查询出来,没有就只会查询所有元素
8.在有序集合类型(不允许重复)命令中添加分数命令zincrby:是在原先分数的基础上添加分数(现在=原先+要添加值)
9.在通用命令中keys命令:可以写(keys *)查询所有key ,这样写(keys set*)查询前缀为set的key
7.3.Spring data redis
1.在pom中导入Redis坐标

2.配置数据源
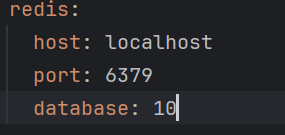
先在开发环境中配置Redis的具体参数,在主配置文件中引用开发环境的参数(有多种环境,之前说过)
3.编写配置类,创建RedisTemplate对象
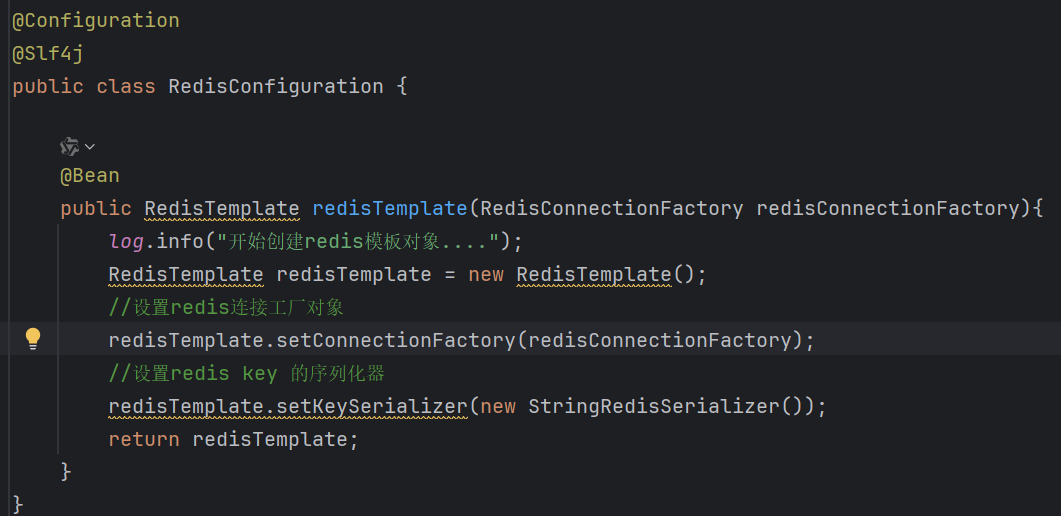
4.通过RedisTemplate对象来操作Redis
8.工具:
8.1.Git使用与简化
8.1.1.Git简介:
Git是一个版本控制工具,可以进行管理项目代码,是团队合作必须使用的工具,我们必须学会使用它
8.1.2.使用方式:
1.命令行使用:具体命令就不细说了,我感觉就那一套模板,比Linux简单
2.使用图形化界面TortoiseGit:它俗称小乌龟,可以简化操作,用图形化界面的方式来操作(作者学鹏哥C语言时,鹏哥推荐使用它进行提交代码上传仓库打卡)
3.使用IDEA:既然我们是开发人员,可以直接使用IDEA中的图形化界面来提交
8.1.3.仓库的选择:
1.国内的仓库平台Gitee码云:国内的访问速度快,便于提交
2.国外的仓库平台Github:国外的,也是世界上最大的开源平台,你有可能访问不了,访问速度慢(可以使用魔法来),如果不想要花钱,我推荐使用Steam++(改名为Watt Toolkit)
8.1.4.总结:
1.我认为应该尽量多使用命令行来实现,多使用你会发现Linux,Docker,Git这些工具命令使用大差不差,你以后学习到某个工具时会发现其实和那些命令差不多,你都能想到该写什么
2.如果你要使用TortoiseGit,推荐下载镜像版本,当初作者就傻傻的在下官网的版本,下的实在是太慢了
3.我也推荐使用Github这个仓库,不是说国内的不好,其实都差不多(它们两个仓库还支持双向传递),但是嘛,我一开始也是使用码云,等我想要使用Github时(怎么访问这么慢啊),作者嘛,就四处找,哦,原来要工具加速,这样就锻炼了我的查询资料的能力(学开发基本自学),最主要的是会用工具了
8.2.扩展Lombok注解
8.2.1.@Builder注解
1.我们先初步了解一下它的核心功能
1.自动生成Builder静态内部类,并且提供链式编程的调用方法,可以逐步设置对象属性值,最后通过 .build()方法(前面有个点)生成目标对象
2.简化对象的创建,你想啊如果你定义的实体类属性很多,你难道要通过set方法一个个赋值啊
3.写法:
@Builder
public class User{}
User user = User.builder().属性名(给值).**.build(构建完成)
这里的标签是定义在类上
2.特性:
1.默认值支持:就是先给属性个值,再在属性上写@Builder.Default,你给的值就是默认值了
@Builder.Default
private String name = "zhanghada";
(zhanghada就是默认值,定义在属性上)
2.自定义构建:就是上面User user = User.builder().属性名(给值).**.build(构建完成) ,你可以将builder()方法改个名,怎么写:类上加上@Builder(builderMethodName="指定方法名")
3.好处:简化代码,不用一个个set方法写
4.注意事项:这是Lombok中的注解,要引入Lombok依赖
8.2.2.@Data与@AllArgsConstructor与@NoArgsConstructor
1.@Data:我就简单说一下,@Data就是除了有参无参构造的方法,其他的方法全集成到这个注解了(set,get,toString...)
2.@AllArgsConstructor:也只有有参无参构造的方法没有说了,所以它就是全部参数的构造
3.@NoArgsConstructor:无参构造
8.3.TODO工具
1.这是IDEA内置的工具
2.怎么使用:在注释里写个TODO即可(// TODO:(接你要写的内容将会展示出来))
3.有什么用呢:你在注释里添加了这个TODO,那么在TODO的工具窗口中你可以双击条目,直接跳转到对应代码处(当你有些代码还未完善时添加它,提醒你要完成)
4.你进行提交代码时,如Git使用commit时可以勾选Check TODO(确保未有遗漏)
5.团队统一使用(确保可读性和可维护性)
8.4.MD5加密
1.这是一个哈希函数
2.看到哈希,想到什么,HashSet集合,在集合中是不是通过一定算法将值给计算成哈希值,并且是不是无法将哈希值反推回来,注意是不是有一个现象叫哈希碰撞(就是有较小几率不同的值(多个)但是计算出来的哈希值相同,这就是哈希碰撞)
3.根据上面推出MD5加密特性:
1.不可逆性(无法反推)
2.确定性(相同的值计算出的哈希值一定相同)
3.抗碰撞性弱(哈希碰撞)
4.思考:苍穹外卖中使用了对用户密码进行加密存入数据库 ,但是它的安全性似乎不足,会出现哈希碰撞,所以这里可以进行改进
9.知识点扩展:
9.1.Serializable接口
1.看一下

2.实现了该接口的类,该类的对象可以被序列化(转换成字节流)
3.所以为什么要实现这个接口呢?
1.返回给客户端时要JSON数据,实现该接口可以转换,但是在项目中有对应注解转换JSON
2.可以缓存/持久化:存储到Redis,数据库,文件时要使用序列化
4.什么是序列化:将内存中的对象转换字节流(为什么要用可以参考上面接口(它就实现了序列化转换))
5..什么是反序列化:反过来
9.2.传参的方式
1.路径传参:如:Localhost:8080/emp/1 ,就是写在了访问路径上而且用/分割的(1就可以看作一个参数,这个1的参数名为status),那么我们服务端想要接收这个参数,必须使用注解@PathVariable("这里面写传过来的参数名(status呗)"),如果你接收参数的类型名称与参数名相同,那么可以直接写注解@PathVariable,不写参数名了,但是你对应的Mapping注解的路径必须这样写(假如你参数名为id , @*Mapping("/访问路径/{参数名id}"))
2.地址栏传参:如:Localhost:8080/emp?name="给值", 就是写在了访问路径上而且用?来分割的,那么我们服务端想要接收这个参数,必须使用注解@RequestParam("这里面写传过来的参数名(name呗)"),如果你接收参数的类型名称与参数名相同,那么可以直接写注解@RequestParam,不写参数名了,因为这是简单参数传值Mapping注解的访问路径不需要写参数名
3.请求体传参:一般传JOSN的数据,如图
我们要接收这个请求头,那么必须写这个注解@RequestBody(这个绝对不能省略)
而且你都用请求体传参了,里面的属性至少不是一个吧,所以建议使用封装类来接收(注意:请求体内的属性名与封装类中的属性名要一一对应,才能自动封装到类中,才能接收到值)
总结:所以我们就保持访问参数名与服务端中的属性名一致(出错的几率小,但是你必须知道这个原理是怎么回事)
9.3.@JosnFormat与@DataTimeFormat
1.是我们遇到的一些问题,才了解了这个,问题是我们数据库中的时间类型的数据返回给前端展示是变成了数组展示(要解决它)
2.@JosnFormat就是可以将我们后端的数据转换成JSON形式的数据(这样就不是展示数组了),其实这里应该想到什么(序列化,对,就是通过序列化来实现的这个转换功能),它其实还可以进行反序列化操作,就是上面反转过来就是
3.@DataTimeFormat就是将前端传过来的时间(假如你用LocalDateTime来接收,格式是不是有要求)而它就是将传过来的时间格式进行一个转换,变成我们想要的格式
9.4.全局统一日期格式
1.在配置类中继承WebMvcConfigurationSupport,实现其中的方法

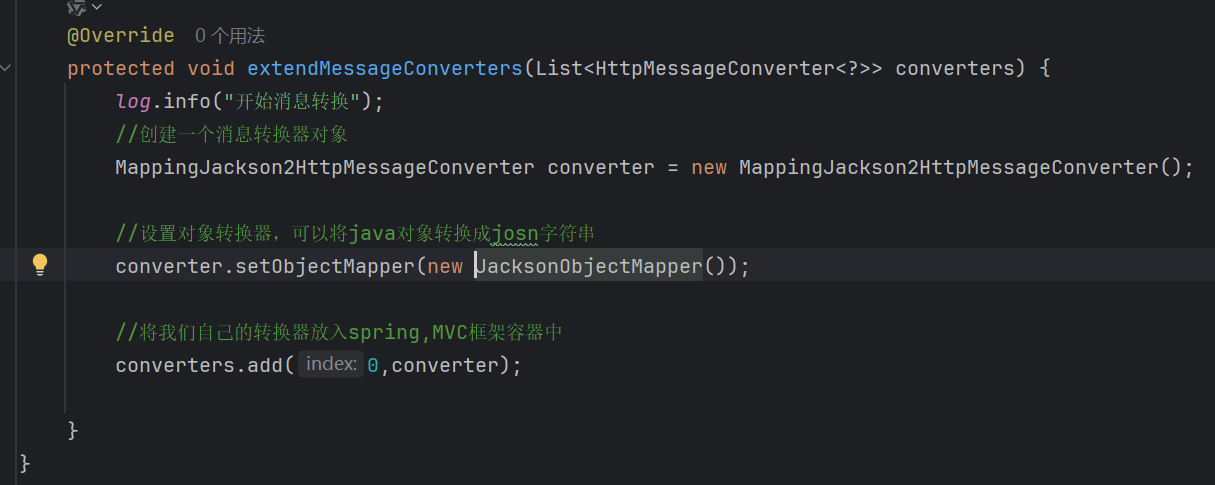
2.设置一个对象转换器
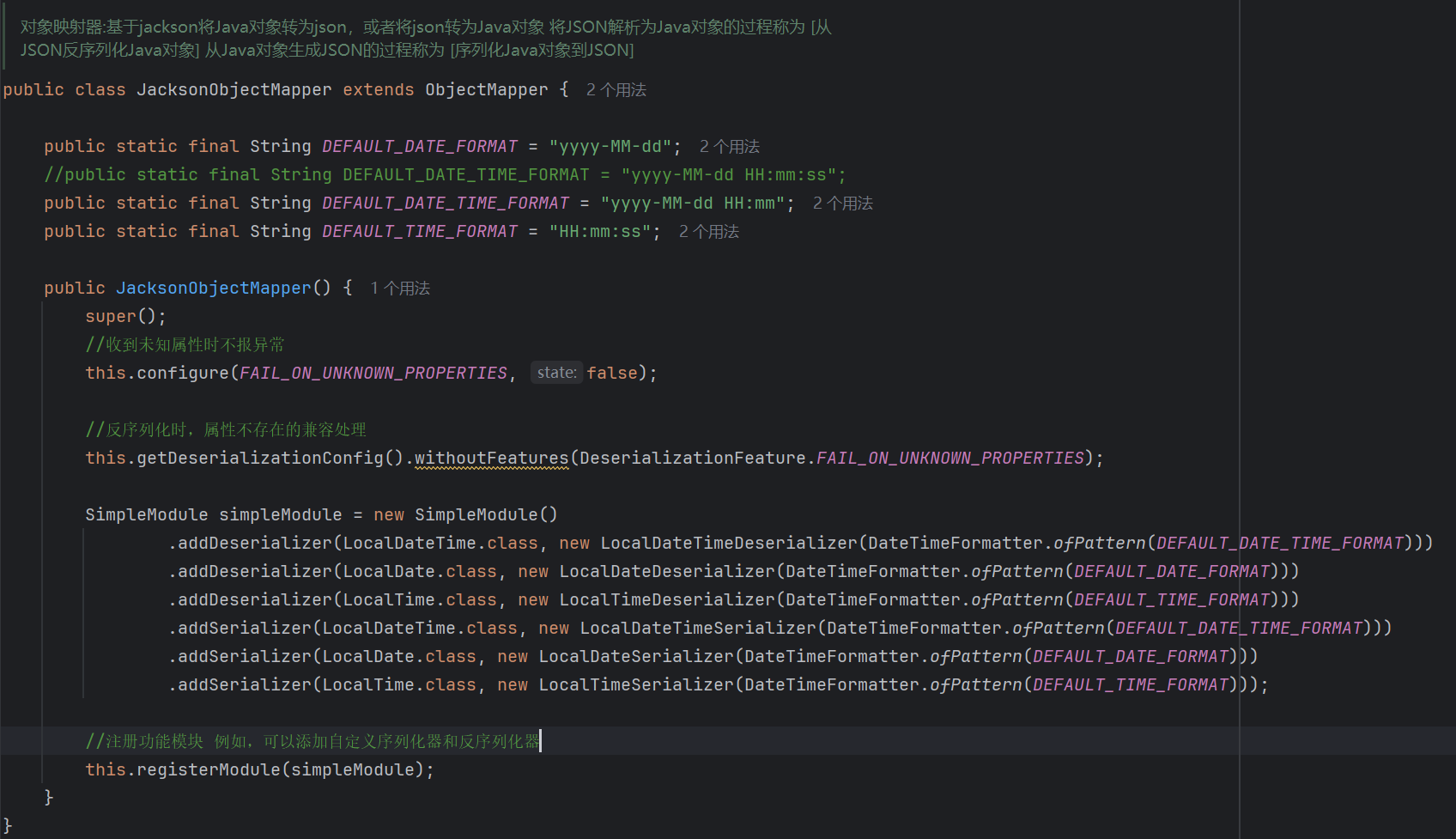 、
、
9.5.元注解
1.@Target(指定注解可用位置,有很多类型可以选,具体代表功能网上搜,教你怎么看),你直接Ctrl+左键就可以进入相应源码中,选中这个ElementType(就可以看到有什么类型了)
![]()
2.@Retention(指定注解在什么地方有效,配合反射使用),同理Ctrl+左键进入RetentionPolicy
![]()
3.注解类中必须要定义一个参数成员 ,怎么定义?
一般定义:参数类型 自定义名称(一般取名value)+();
定义默认值:参数类型 自定义名称() default +默认值;(当然value可以定义别的名字)
9.6.@Bean与@ConditionalOnMissingBean的区别
1.Spring的@Bean,你加上了这个注解,默认就是单例的,只会创建一个Bean,无论这个配置类被加载了多少次,或者是有多少个配置类,就是只能存在一个相同类型的对象(多个通类型会报错,使用@Primary(优先注入),或者@Qualifier(指定名称))
2.@ConditionalOnMissingBean的功能是不存在这个指定类型的Bean时才会创建这个被标记的Bean(避免重复覆盖),并不能保证唯一
9.7.为什么@ReuqestParm可以省略
1.之前我说过,@ReuqestParm这个注解是用来接收前端地址栏传参时所使用的注解,当前端与后端参数名称相同时可以省略
2.为什么呢?
1.首先后端如果用基本类型,数组,集合来接收前端的数据,Spring会默认使用@ReuqestParm这个注解
2.而前后端参数名称相同,省略@ReuqestParm,那么Spring就会自动按@ReuqestParm来实现(类似自动装配,它会帮你自动一一对应上)
3.如果前后端多个参数名称也对应相同,也可以省略@ReuqestParm,Spring会自动根据名称来接收
4.参数名称不同,那么你就需要指定对应名称,让Sping能够来对应接收数据
5.前端传过来是一个数组,你选择String类型接收,@ReuqestParm可以忽略,选择集合,数组来接收,那么你需要声名@ReuqestParm,Spring先知道前端传过来数组,然后你加上了@ReuqestParm,那么Spring会自动拿出前端数组里面的元素,装入后端的集合或者数组中(当然参数不同,你还需要指定参数)
6.接上面,如果我不写这个注解@ReuqestParm呢,那么Spring会默认前端传过来的是一个整体参数,不会进行拆分,那么你数组或者集合的第一个元素装的就是它
3.总结:明确后端接收数据的参数类型(基本类型,字符串,数组,集合),Spring就会默认@ReuqestParm,前后端参数名称不同,就在注解中指定名称
9.8.为什么@ModelAttribute可以省略
1.我一开始都不知道这个注解,这是我写代码时报错时询问Ai时才知道它
2.如果前端传过来很多参数,后端是不是可以用一个自定义实体类来接收,老师说可以省略注解,我之前一直以为就是@ReuqestParm,好吧,其实是@ModelAttribute
3.@ModelAttribute的作用:
1.如果你后端用来接收前端的参数是一个对象,自定义实体类(这种封装类),那么Spring识别到这个参数类型,就会自动默认@ModelAttribute来实现功能
2.而@ModelAttribute的功能就是将前端传过来的参数一一对应进后端封装的实体类中(就说实体类的属性名称与前端参数名称相同,就可以一一对应赋值)
4.为什么可以省略:
1.其实原理和@ReuqestParm差不多,因为Spring会识别,当你后端接收参数是自定义类型(这样的类型都可以),Spring就会默认@ModelAttribute来实现,所以你可以省略
2.类似功能可以根据上面@ReuqestParm说明来推出
9.9.@ReuqestParm与@ModelAttribute的区别
1.@ReuqestParm要参数名称对应才能省略,而@ModelAttribute实际上是进行实体类封装,不需要参数名称对应也能省略(实体类中的属性名称要与前端参数名称对应)
2.Spring默认识别不同:当基本类型,字符串,数组,集合时(@ReuqestParm),自定义实体类时(@ModelAttribute)
3.@ModelAttribute一般都不用特意写出来,而@ReuqestParm就需要自己判断
9.10.为什么java操作Redis方法里的参数类型不同于Redis
Redis的value类型是String类型,而java中的value类型却是Object类型
Redis ![]()
java ![]()
为什么呢? =>因为java会自动将Object转换成String类型再存入Redis,而java使用Object来接收值(实现不同类型都可以接收,最终会转换为String)
9.11.JSON字符串数据的转换
1.我们调用的是JSON.parseObject(),这个方法,它可以将JSON格式的字符串反序列化转化成java对象
2.怎么使用
1.将JSON字符串转换成特定Java对象
String json = "{"name": "zhanghada" , "age": 18}";
User user = JSON.parseObject(json,User.class) ; =》 如果有一个与json参数内的属性一一对应的实体类对象User,那么我们可以直接这样写,转换成User该类的对象
2. 将JSON字符串转换成通用Java对象
String json = "{"name": "zhanghada" , "age": 18}";
JSONObject jsonObj= JSON.parseObject(json); =>没有对应实体类,那么我们可以封装成一个通用的Json对象(java能使用的对象)
3.总结:第一种方式用于获取大量参数时,我们可以封装一个实体类来接收,而第二种方法则是获取单一参数时来使用

















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









