






深度确定性策略梯度(DDPG)算法详解
在深度强化学习(Deep Reinforcement Learning)中,深度确定性策略梯度(Deep Deterministic Policy Gradient), DDPG是一种非常有效的算法,适用于高维连续动作空间的问题。DDPG 是基于 Actor-Critic 架构 的深度强化学习算法,结合了策略梯度和价值函数逼近方法,广泛应用于自动驾驶、机器人控制和数据库调优等领域。本篇文章将详细介绍 DDPG 的训练过程。
DDPG 算法的训练流程
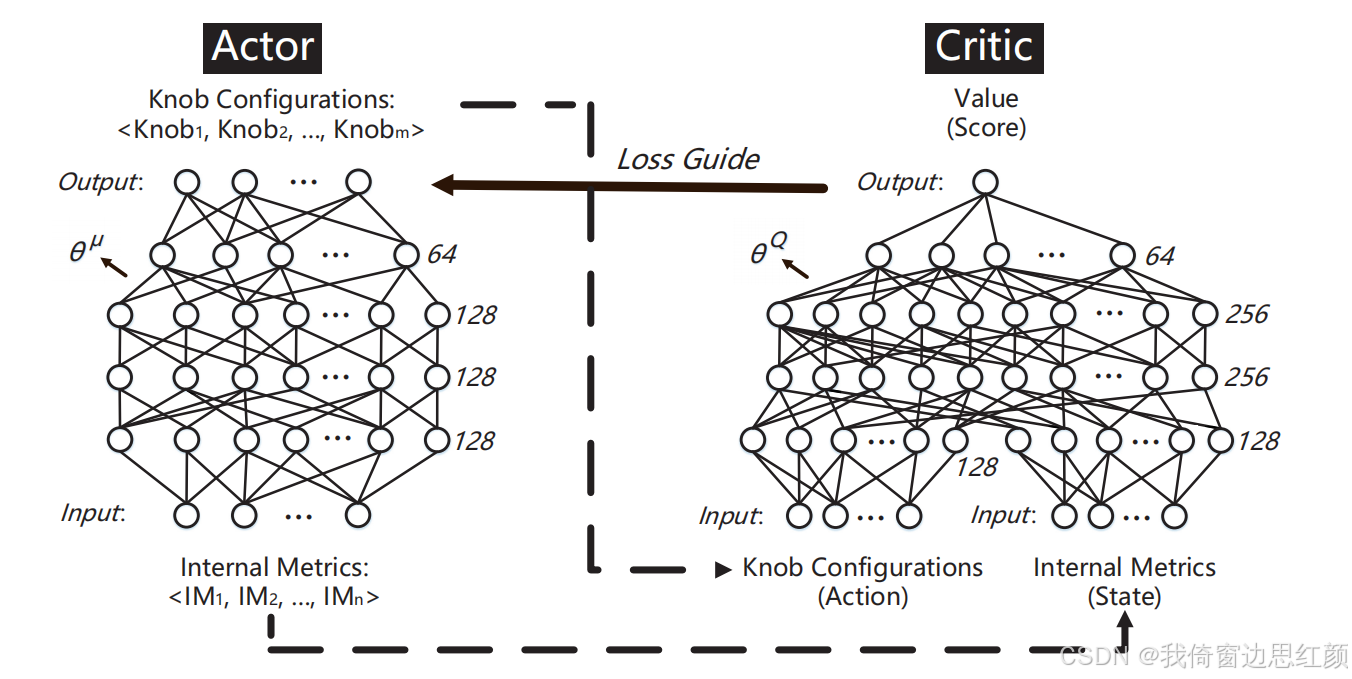
1. Actor 网络生成动作
a t = μ ( s t ∣ θ μ ) + N ( t ) a_t = \mu(s_t|\theta^\mu) + \mathcal{N}(t) at=μ(st∣θμ)+N(t)
-
解释:
- Actor 网络 接收当前的状态 s t s_t st 作为输入,输出一个确定性动作 a t a_t at。
- 噪声 N ( t ) \mathcal{N}(t) N(t)用于增加探索能力,确保智能体能够探索更多的状态空间。这是因为 DDPG 是一个确定性策略算法,如果没有探索,可能会陷入局部最优解。
-
目的:通过添加噪声来保证训练过程中的探索性,提高策略的泛化能力。
2. 执行动作,获取奖励和下一状态
- 在环境中执行 Actor 网络生成的动作
a
t
a_t
at,并得到:
- 奖励(Reward) r t r_t rt:反映当前动作对环境的影响。
奖励函数的定义
CDBTune 的奖励函数综合考虑了吞吐量和响应时间的变化,定义如下:
r t = C T ⋅ Δ T + C L ⋅ Δ L r_t = C_T \cdot \Delta T + C_L \cdot \Delta L rt=CT⋅ΔT+CL⋅ΔL
- r t r_t rt:当前动作 a t a_t at所获得的奖励。
- C T C_T CT和 C L C_L CL:调整吞吐量和响应时间的权重系数,用于平衡这两个指标的相对重要性。
- Δ T \Delta T ΔT:吞吐量的变化率,定义为调整配置前后吞吐量的差异。
Δ T = TPS new − TPS old TPS old \Delta T = \frac{\text{TPS}_{\text{new}} - \text{TPS}_{\text{old}}}{\text{TPS}_{\text{old}}} ΔT=TPSoldTPSnew−TPSold- Δ L \Delta L ΔL响应时间的变化率,定义为调整配置前后响应时间的差异。
Δ L = Latency old − Latency new Latency old \Delta L = \frac{\text{Latency}_{\text{old}} - \text{Latency}_{\text{new}}}{\text{Latency}_{\text{old}}} ΔL=LatencyoldLatencyold−Latencynew
-
下一状态(Next State) s t + 1 s_{t+1} st+1:执行动作后环境返回的新状态。
-
目的:通过与环境交互收集经验,用于后续的策略学习。
3. 存储经验到经验回放池
( s t , a t , r t , s t + 1 ) → D (s_t, a_t, r_t, s_{t+1}) \rightarrow D (st,at,rt,st+1)→D
-
解释:
- 将当前的经验四元组 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 存入经验回放池(Replay Buffer) D D D。
-
目的:
- 经验回放池用于存储智能体与环境交互的历史数据。通过从回放池中随机采样数据,可以减少数据的时间相关性,提升训练的稳定性和效率。
4. 从经验回放池中随机采样
-
从回放池 ( D ) 中随机采样一批数据 ( s i , a i , r i , s i + 1 ) (s_i, a_i, r_i, s_{i+1}) (si,ai,ri,si+1)。
-
目的:打破时间相关性,提高样本的独立性,提升模型的泛化能力。
5. 计算目标 Q 值
y i = r i + γ Q ′ ( s i + 1 , μ ′ ( s i + 1 ∣ θ μ ′ ) ∣ θ Q ′ ) y_i = r_i + \gamma Q'(s_{i+1}, \mu'(s_{i+1}|\theta^{\mu'})|\theta^{Q'}) yi=ri+γQ′(si+1,μ′(si+1∣θμ′)∣θQ′)
- 解释:
- y i y_i yi 是目标 Q 值,用于更新 Critic 网络。
- γ \gamma γ是折扣因子(通常在 0 到 1 之间),用于平衡当前奖励和未来奖励的影响。
- 目标网络
Q
′
Q'
Q′和
μ
′
\mu'
μ′ 是 Critic 和 Actor 网络的慢速更新副本,用于计算更稳定的目标 Q
值。
目标网络的作用
- 减少训练过程中的震荡和不稳定性
- 避免策略和价值函数的相互干扰
- 提高训练的稳定性和收敛性
- 目的:目标 Q 值 y i y_i yi是 Critic 网络更新的参考标准。
6. 更新 Critic 网络的参数
L ( θ Q ) = 1 N ∑ i ( y i − Q ( s i , a i ∣ θ Q ) ) 2 L(\theta^Q) = \frac{1}{N} \sum_i (y_i - Q(s_i, a_i|\theta^Q))^2 L(θQ)=N1i∑(yi−Q(si,ai∣θQ))2
-
解释:
- Critic 网络的损失函数是均方误差(Mean Squared Error, MSE)。
- 通过最小化 y i y_i yi和 Q ( s i , a i ∣ θ Q ) Q(s_i, a_i|\theta^Q) Q(si,ai∣θQ) 之间的差距,更新 Critic 网络的参数 θ Q \theta^Q θQ。
-
目的:使 Critic 网络更准确地预测 Q 值,从而帮助 Actor 网络做出更好的决策。
7. 使用 Critic 网络的梯度更新 Actor 网络
J
(
θ
μ
)
=
E
s
∼
D
[
Q
(
s
,
μ
(
s
∣
θ
μ
)
∣
θ
Q
)
]
J(\theta^\mu) = \mathbb{E}_{s \sim D} \left[ Q(s, \mu(s|\theta^\mu) | \theta^Q) \right]
J(θμ)=Es∼D[Q(s,μ(s∣θμ)∣θQ)]
∇
θ
μ
J
≈
1
N
∑
i
∇
a
Q
(
s
i
,
a
∣
θ
Q
)
∣
a
=
μ
(
s
i
)
∇
θ
μ
μ
(
s
i
∣
θ
μ
)
\nabla_{\theta^\mu} J \approx \frac{1}{N} \sum_i \nabla_a Q(s_i, a|\theta^Q) |_{a=\mu(s_i)} \nabla_{\theta^\mu} \mu(s_i|\theta^\mu)
∇θμJ≈N1i∑∇aQ(si,a∣θQ)∣a=μ(si)∇θμμ(si∣θμ)
-
解释:
- Actor 网络的目标是最大化 Critic 网络评估的 Q 值。
- 首先计算 Critic 网络对动作 a a a 的偏导数 ∇ a Q ( s i , a ∣ θ Q ) \nabla_a Q(s_i, a|\theta^Q) ∇aQ(si,a∣θQ),然后通过链式法则更新 Actor 网络的参数 θ μ \theta^\mu θμ。
-
目的:通过 Critic 网络提供的反馈,调整 Actor 网络,使其能够输出更优的动作。
8. 软更新目标网络
θ ′ = τ θ + ( 1 − τ ) θ ′ \theta' = \tau \theta + (1 - \tau) \theta' θ′=τθ+(1−τ)θ′
-
解释:
- 目标网络的参数更新采用软更新(Soft Update),其中 τ \tau τ是一个很小的常数(如 0.001)。
- 软更新使目标网络参数平滑地向当前网络参数靠拢,而不是直接替换。这有助于提高训练的稳定性,防止策略的剧烈波动。
-
目的:目标网络的稳定更新有助于减小训练过程中的波动,提高模型收敛性。
总结
- DDPG 算法是基于 Actor-Critic 架构的深度强化学习算法,通过结合经验回放池和目标网络的软更新,解决了高维连续动作空间中的策略优化问题。
- 核心步骤包括:
- Actor 网络生成确定性动作。
- Critic 网络评估 Actor 网络生成的动作,并为 Actor 网络提供优化方向。
- 通过经验回放池和目标网络的软更新,提高训练的稳定性和样本效率。
应用场景
- 自动驾驶:用于控制车辆的转向、加速和刹车。
- 机器人控制:用于调整机器人手臂的运动轨迹。
- 数据库调优(CDBTune):通过调整数据库配置参数,如缓存大小和线程数,提高数据库性能。
以上就是 DDPG 算法的训练过程。希望这篇文章能帮助您深入理解 DDPG 的工作原理!

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









