










前言
今天我们来复习K-means聚类模型,并用项目教大家快速了解K-means聚类模型,我会将大家编写代码中常见的错误点在代码注释中指出,希望不会浪费大家的时间,高效学习
一、项目背景与数据集
- 目标:根据鸢尾花的花萼和花瓣尺寸(4个特征),将样本分为3类(与真实类别对比)
- 数据集:Scikit-learn内置的 load_iris 数据集(150个样本,4个特征)
- 项目价值:掌握K-Means的核心原理、聚类过程及其可视化
二、完整代码实现
1.加载数据集与探索
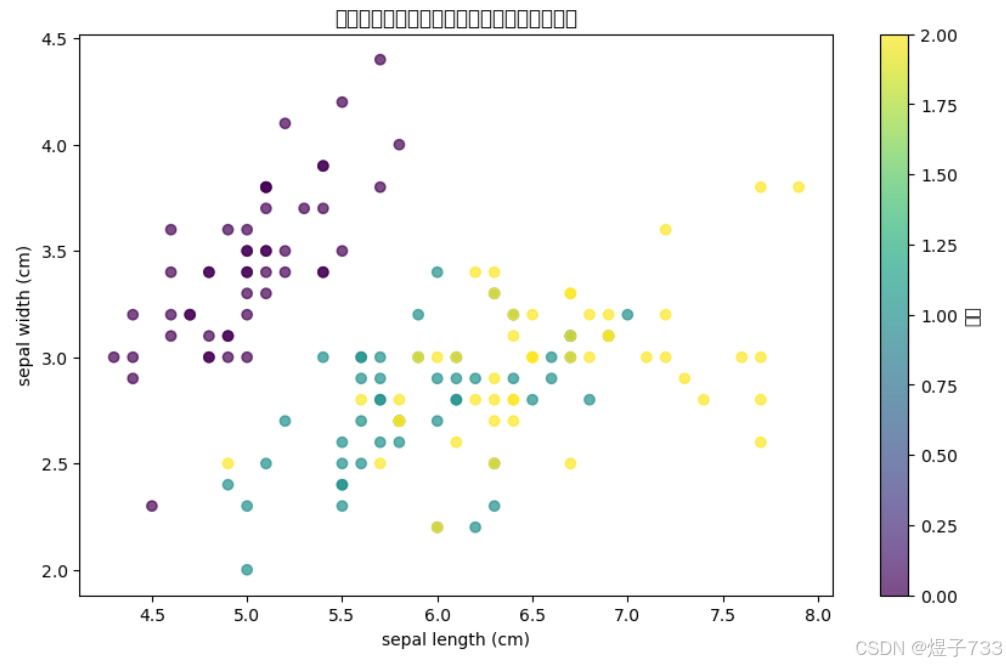
提取出数据特征,标签,以及名称等信息,并对前两个特征的样本进行可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 查看数据基本信息
print("特征名称:", data.feature_names)
print("样本数:", X.shape[0], "特征数:", X.shape[1])
print("真实标签分布:\n", pd.Series(y).value_counts())
# 可视化前两个特征分布
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', alpha=0.7)
plt.xlabel(data.feature_names[0])
plt.ylabel(data.feature_names[1])
plt.title("鸢尾花数据集前两个特征的分布(真实标签)")
plt.colorbar(label="类别")
plt.show()
输出效果

2.数据预处理
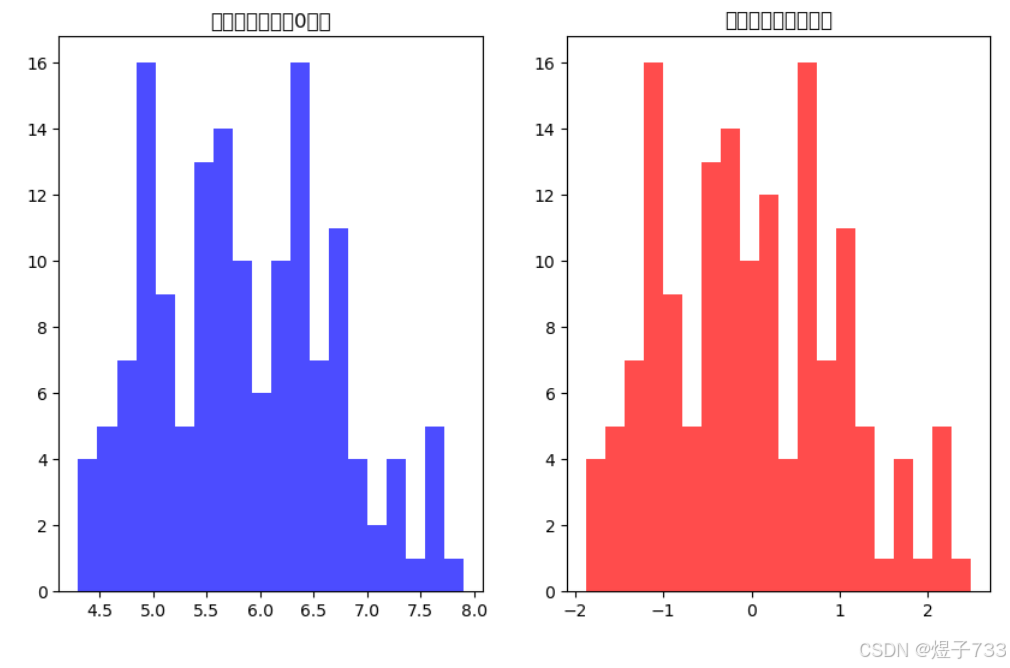
# 标准化特征(K-Means对特征尺度敏感!)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 对比标准化前后的特征分布
plt.figure(figsize=(10, 6))
plt.subplot(1,2,1)
plt.hist(X[:, 0], bins=20, color='blue', alpha=0.7)
plt.title("标准化前的特征0分布")
plt.subplot(1,2,2)
plt.hist(X_scaled[:, 0], bins=20, color='red', alpha=0.7)
plt.title("标准化后的特征分布")
plt.show()
输出效果
3.手动实现K-Means聚类
class KMeansManual:
def __init__(self, n_clusters=3, max_iters=100):
self.n_clusters = n_clusters # 聚类数
self.max_iters = max_iters
self.centroids = None # 聚类中心
self.labels = None
def _eculidean_distance(self, x1, x2):
"""计算欧氏距离"""
return np.sqrt(np.sum((x1 - x2) ** 2))
def _initialize_centroids(self, X):
"""随机初始化聚类中心"""
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False) # 无放回抽取n_clusters个索引
return X[indices]
# 通过 X[indices] 获取这些索引对应的数据点作为初始聚类中心
def fit(self, X):
"""训练模型:迭代更新聚类中心和样本标签"""
n_samples, n_features = X.shape
self.centroids = self._initialize_centroids(X)
# 进入 for 循环,最多执行 max_iters 次迭代,直到收敛
for _ in range(self.max_iters):
# 1.分配样本到最近的聚类中心
distance = np.zeros((n_samples, self.n_clusters))
for i in range(self.n_clusters):
distance[:, i] = np.array([self._eculidean_distance(x, self.centroids[i]) for x in X]) # 二维数组,存储每个样本到每个聚类中心的距离
self.labels = np.argmin(distance, axis=1)
# 2.更新聚类中心
new_centroids = np.zeros((self.n_clusters, n_features))
for i in range(self.n_clusters):
new_centroids[i] = np.mean(X[self.labels == i], axis=0) # 以旧类样本各个特征的平均值作为新的中心
# 3.检查是否收敛
if np.allclose(self.centroids, new_centroids):
break
self.centroids = new_centroids
def predict(self, X):
"""预测样本的聚类标签"""
distances = np.zeros((X.shape[0], self.n_clusters))
for i in range(self.n_clusters):
distances[:, i] = np.array([self._eculidean_distance(x, self.centroids[i]) for x in X])
return np.argmin(distances, axis=1)
# 训练手动实现的模型
manual_kmeans = KMeansManual(n_clusters=3)
manual_kmeans.fit(X_scaled)
# 预测聚类标签
y_pred_manual = manual_kmeans.predict(X_scaled)
4.sklearn实现
from sklearn.cluster import KMeans
# 创建并训练模型
sklearn_kmeans = KMeans(n_clusters=3, random_state=42)
sklearn_kmeans.fit(X_scaled)
# 预测聚类标签
y_pred_sklearn = sklearn_kmeans.predict(X_scaled)
# 查看聚类中心
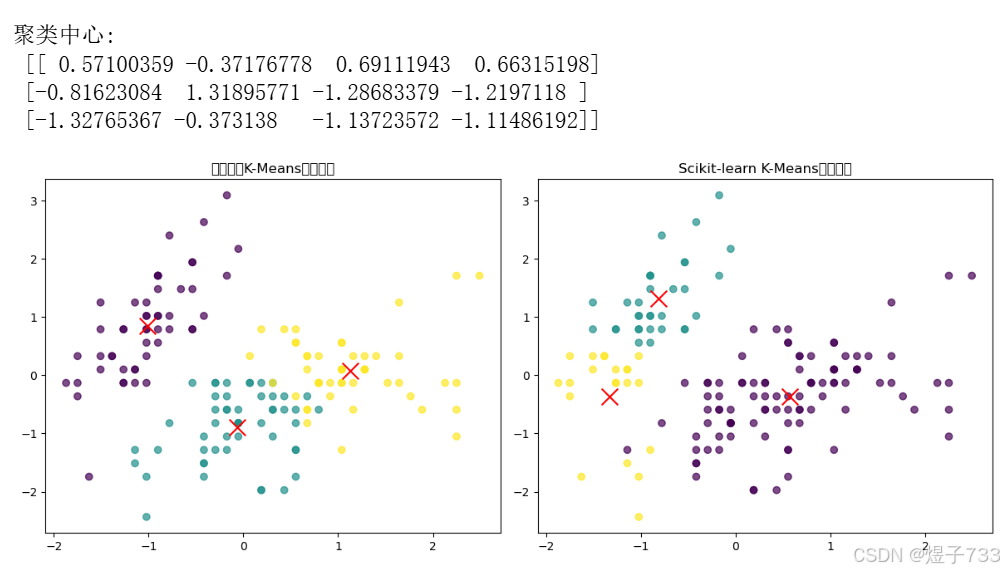
print("\n聚类中心:\n", sklearn_kmeans.cluster_centers_)
# 可视化聚类结果
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=y_pred_manual, cmap='viridis', alpha=0.7) # c表示颜色决定,不同类别颜色不同,cmap控制颜色变化
plt.scatter(manual_kmeans.centroids[:, 0], manual_kmeans.centroids[:, 1], c='red', marker='x', s=200)
plt.title("手动实现K-Means聚类结果")
plt.subplot(1, 2, 2)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=y_pred_sklearn, cmap='viridis', alpha=0.7)
plt.scatter(sklearn_kmeans.cluster_centers_[:, 0], sklearn_kmeans.cluster_centers_[:, 1], c='red', marker='x', s=200)
plt.title("Scikit-learn K-Means聚类结果")
plt.tight_layout()
plt.show()
输出效果
三、模型评估与对比
from sklearn.metrics import silhouette_score
# 计算轮廓系数(评估聚类效果)
silhouette_manual = silhouette_score(X_scaled, y_pred_manual)
silhouette_sklearn = silhouette_score(X_scaled, y_pred_sklearn)
print("\n手动实现K-Means的轮廓系数:", silhouette_manual)
print("Scikit-learn K-Means的轮廓系数:", silhouette_sklearn)
# 对比聚类结果与真实标签
print("\n手动实现K-Means vs 真实标签:")
print(pd.crosstab(y, y_pred_manual, rownames=['真实标签'], colnames=['预测标签']))
print("\nScikit-learn K-Means vs 真实标签:")
print(pd.crosstab(y, y_pred_sklearn, rownames=['真实标签'], colnames=['预测标签']))
输出效果

总结
以上就是今天要讲的内容,本文仅仅简单介绍了K-means聚类模型的推导与实现,还有一些其他的优化K-means聚类模型的方法但本文主旨是便于大家复习模型,就不再赘述
以上所有代码在Github仓库
结尾致敬
我是一位新手博客小白,将以复习机器学习与深度学习和强化学习模型为系列进行创作,希望能和大家一起共勉学习,如果有问题或者错误请在评论区@鼠鼠,觉得有帮助大家的可别忘了点赞加关注哦!

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









