







【前置知识】
首先我们要了解什么是进程?知道什么是进程的PCB,可以查看我之前的文章什么是进程?
一、进程的优先级
(一)为什么要有优先级?
我们思考一下?为什么要有优先级?
本质:系统资源的不足,所有就必须要有优先级的出现解决这个问题。
就比如:我们去学校的食堂买饭,食堂肯定是有一个个的窗口,那么当我们学生的数量过多的时候,就需要到一个窗口去进行排队,出现这种现象的原因很简单,就是学校的食堂不够大,窗口不够多。
所以同样的道理,操作系统在调度进程的时候,由于CPU的资源有限,所以就决定了进程在被调度的时候,进程要进行排队,而排队就一定会有先后顺序,所以这个先后顺序就是进程的优先级。
(二)进程的优先级的范围
进程优先级范围:
- 在Linux中,进程的优先级可以通过nice值进行调整,范围为[-20, 19],而不是[-19, 20]。
- nice值越低,优先级越高,-20代表最高优先级,19代表最低优先级。
进程优先级是可以被修改的, PRI(new) = PRI(原)+ nice值,注意:这里的PRI(原)它都是默认按80为标准来进行计算的。
我们可以验证一下:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
while(1){
cout << "I am a process!" << endl;
sleep(1);
}
return 0;
}
我们在XShell下运行这段代码,然后通过ps -al来查看这个进程的信息
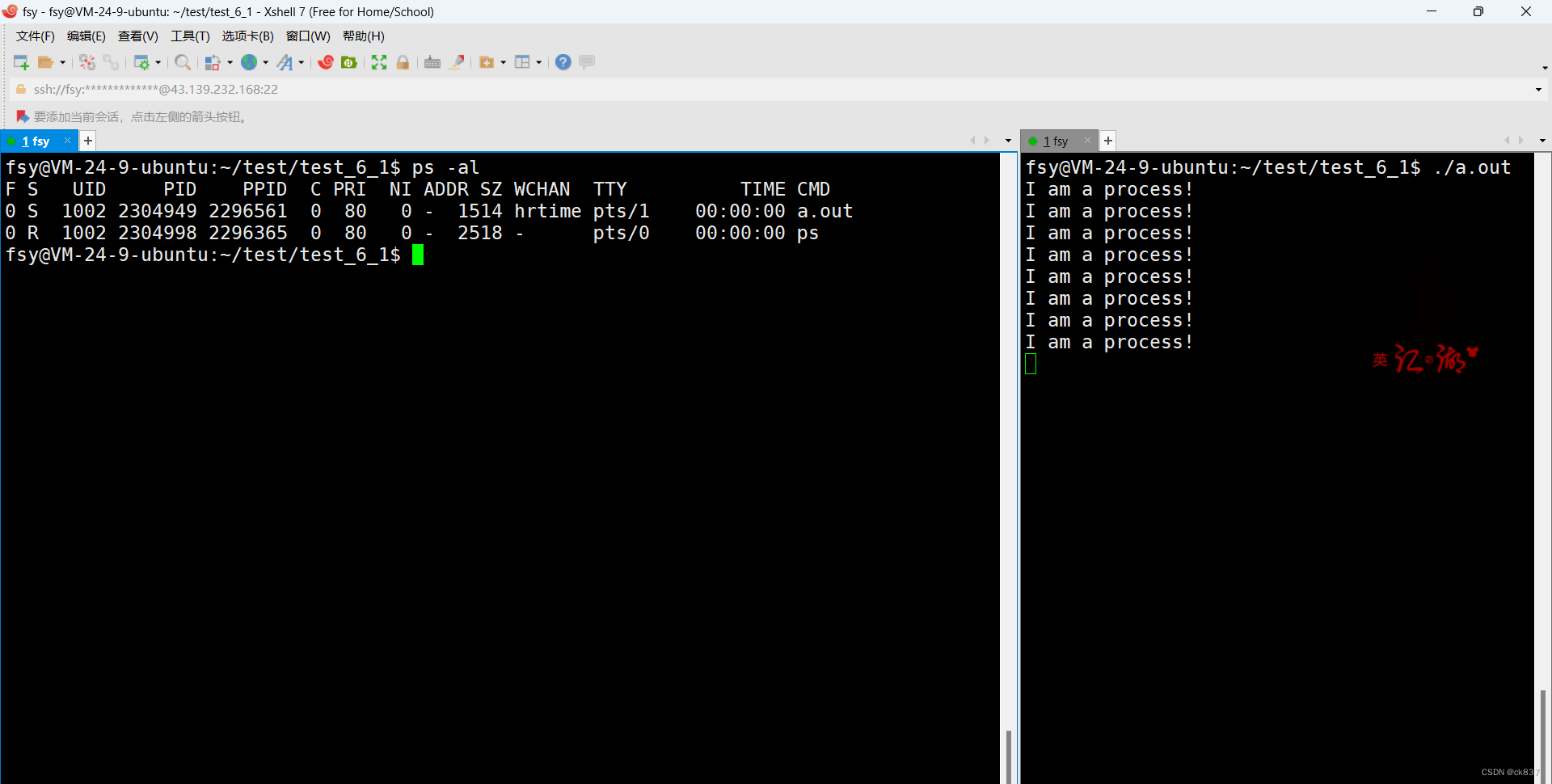
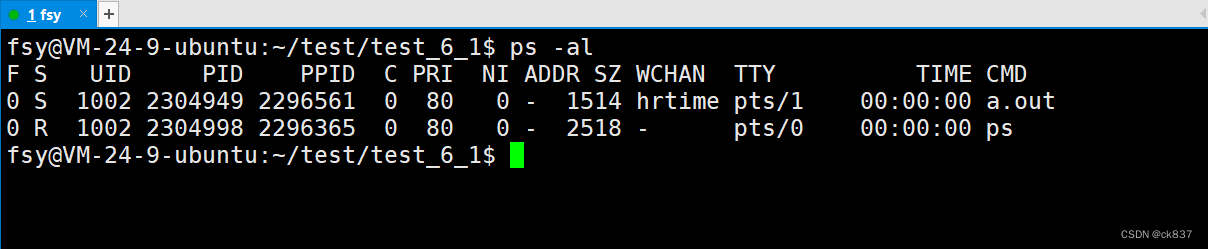
我们可以看到a.out就是我们的代码的可执行程序,它的PRI为80,然后我们通过top命令对它进行修改,详细步骤为
top,然后按r,然后输入进程的PID,然后输入nice值,这里我输入5
PRI被修改成5了,然后我再次修改,这次我修改nice值为10,按理来说应该是85 +10 = 95,但结果是90
这里就说明了,修改PRI都是以80为基础来进行修改的。


二、操作系统是如何实现进程的优先级?(Linux内核2.6版本O(1)调度算法)
首先我们知道,根据冯诺依曼体系结构决定,CPU要拿数据,就要从内存中拿数据,所以一个进程要被CPU调度,就要将进程的代码数据和它的属性(PCB)加载进内存里,然后CPU再进行调度。
而一个CPU通常一次只能调度一个进程,而操作系统里是有很多的进程需要被调度的,所以这就意味着,这些等待被调度的进程就要进行排队,而排队就要有先后的顺序,也就是进程的优先级,那么想到这里?我们就要思考它是如何排队的?
我们在前面也看到了,进程的优先级范围的调整是[-20, 19], PRI的数值越小,优先级就越高,而进程间会有相同优先级的进程,在什么是进程?那一篇博客里,我也说过了,进程在组织的时候,是按照双链表的结构进行组织起来的,所以我们可以大致的想象
每个PRI会对应着数组的某个下标位置,有一种映射的关系,那么每个数组下标的位置存放的会是一个个双链表,这种结构不就是我们数据结构里的哈希桶吗?
然后操作系统就依次从下标小的位置去拿出一个运行的队列出来,然后依次运行,这样就实现了一个进程优先级的现象。
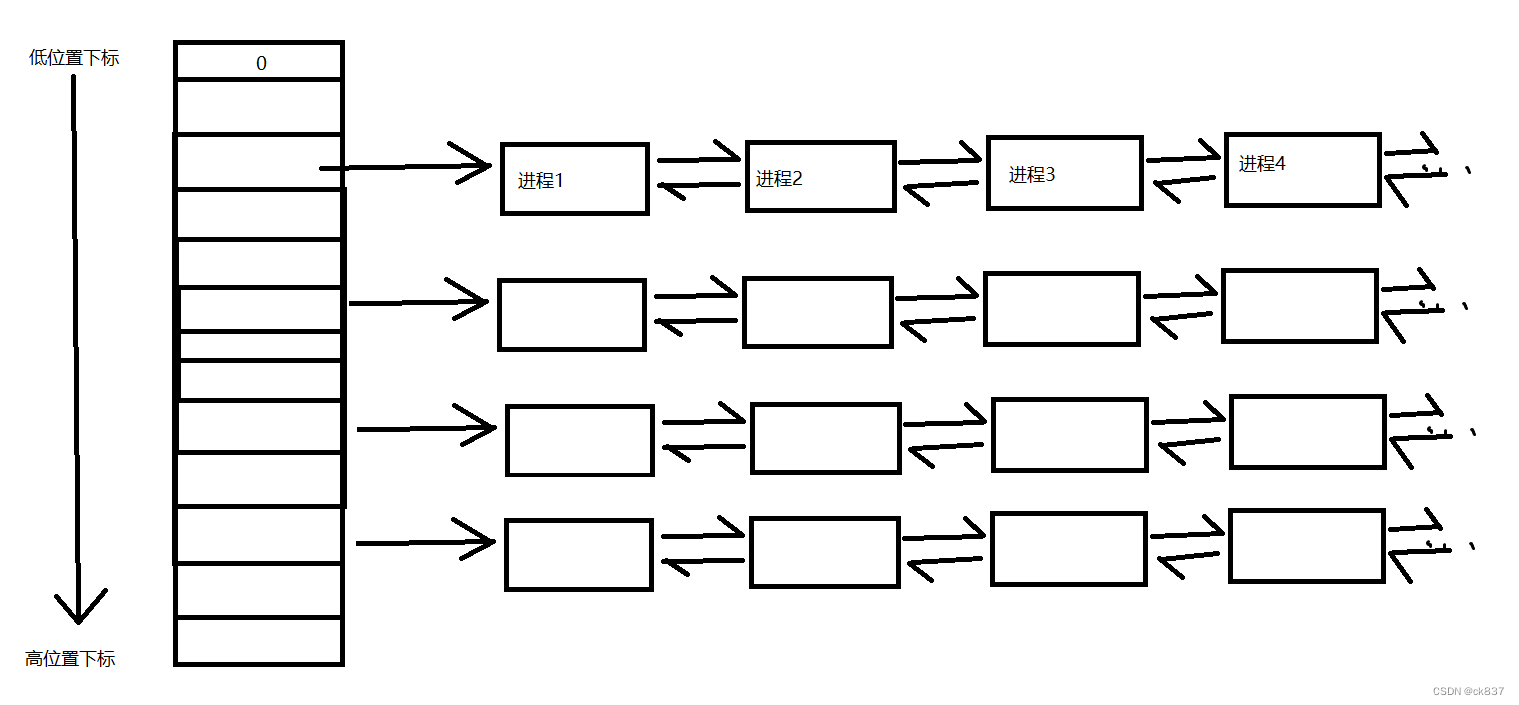
那么实际上,操作系统是怎么做的?
调度队列:
- Linux的调度器采用运行队列(runqueue)的概念。每个CPU有自己的runqueue,其中包含两个优先级数组:一个活动队列(active queue)和一个过期队列(expired queue)。
- 运行队列中的每个优先级数组是一个链表数组,每个链表对应一个特定的优先级。调度器使用这些链表来管理具有相同优先级的进程。
实际上就是在CPU中,它管理着一个结构体runqueue,该结构体里有两个成员。
- 一个活动队列,也就是当前CPU正在运行调度的队列。
- 一个是过期队列,这个队列是把要新加入的进程就先放在这个队列里
> 而这两个其实都是数组,数组大小是140个空间,其中前100个空间是操作系统要用的,有特殊用途,我们只能使用后40个数据空间,这就是为什么优先级只有40个范围
为什么要有这个过期队列呢?直接加入进活动队列里不就行了吗?
- 首先,一个CPU它如果既要运行我们对应的进程,如果没有过期队列,它是不是就还需要花费一些资源,去维护新加入进来的进程,这样不仅加大了管理的成本,也浪费CPU的资源,CPU资源是非常宝贵的。
- 其次,我们试想一下,在这种调度结构里,总是先把优先级高的执行了之后,再依次向下执行,那么如果有一些进程,它的优先级很低,但是对于操作系统而言,可能随时都会有新的进程到来,如果这些进程的优先级都比较高,那么低优先级的进程将会迟迟得不到被调度,造成饥饿问题。
- 如果我的CPU当前已经把该数组位置的进程链表都执行完了,执行到下一个优先级了,但是此时,又突然来一个刚才执行完的进程,需要我去执行,那么这时候我是又返回去执行,然后再去执行下一个进程的位置吗?那么这样子设计的成本是非常高的。
我们的操作系统是非常优雅的,它不会去浪费这些资源和精力去做这种事情。实际上CPU的runqueue,它里面有两个二级指针,分别指向活动队列数组和过期队列数组。
然后CPU运行活动队列,不需要管新加入的进程,统一将新加入的进程放到过期队列中,过期队列其实就相当于是活动队列的一个镜像,新加入的进程就根据优先级映射到对应的数组下标,然后添加进对应位置的哈希桶里面,当CPU把运行队列里的内容都执行完了。
> 这时候运行队列就是空的,然后只需要把那个二级指针,将它们交换一下所指向的内容,这样CPU立马就又得到了一个有数据的活动队列,然后此时又有了一个空的过期队列
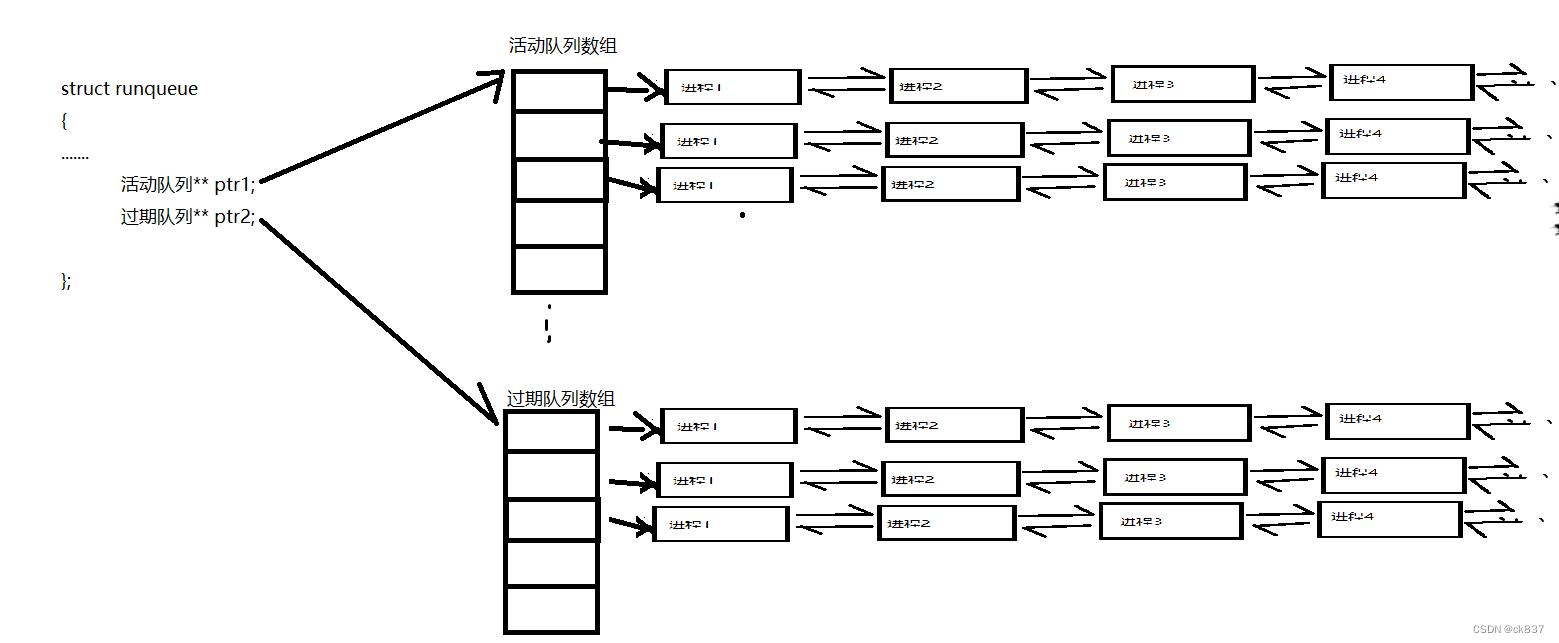
这种处理方式是不是非常的优雅!
那么操作系统该怎么知道活动队列的内容为空呢?
有人说,判空还不简单吗?直接遍历一遍,看看哪里有数据不就好了吗?
但是这样线性遍历的时间复杂度是一个O(N)级别的,我们操作系统响应是非常快的,这显然不合适。
- 操作系统使用了位图的数据结构,来记录活动队列的每个下标的位置,低比特位就代表高优先级,也对应着低下标位置。
- 然后对应的比特位映射的数组下标位置如果有内容,就将它置为1,没有内容了就置为0,然后操作系统只需要通过位运算,就可以很快速的定位到哪些位置有内容。
- 从低比特位开始拿,拿最近的一个比特位为1的位置,这样也有了优先级的出现。
- 最后只需要判断这个位图的值是不是0,就能够知道活动队列是不是为空了。
综上所述,这种进程优先级的调度算法是Linux内核2.6版本引入的O(1)调度算法。Linux 2.4 及之前版本: 使用的是 O(n) 调度算法,调度器的时间复杂度与系统中进程的数量成线性关系。在进程数量较多时,调度效率较低。这种算法极大的提高了调度效率和系统的扩展性。















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









