







要使用 lxml 和 requests 库解析腾讯视频的热搜榜数据,代码已经基本正确,但需要确保 xpath 表达式能够准确匹配目标元素。以下是代码的详细解释和可能的优化:
先导入我们需要的库:lxml中的extree和requests(这个是必须要有的)
我们先获取url,就是我们的这个网址
url = 'https://v.qq.com/biu/ranks/?t=hotsearch&channel=0'
接下来就是获取我们的:headers,
进入腾讯视频的榜单,右击热搜--->检查
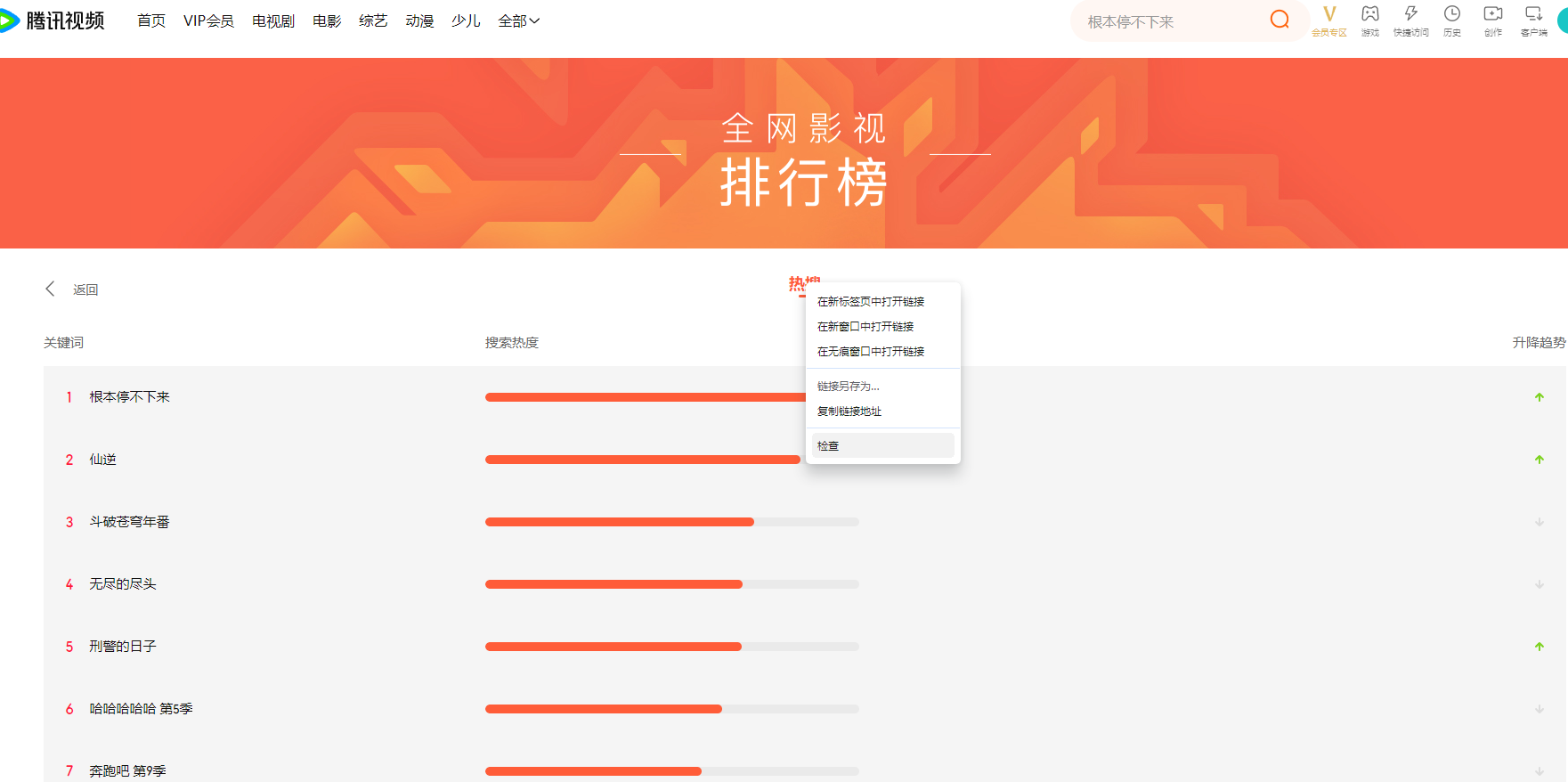
然后会出来这个界面,我们选择网络,然后刷新下网页,再点击rank.css
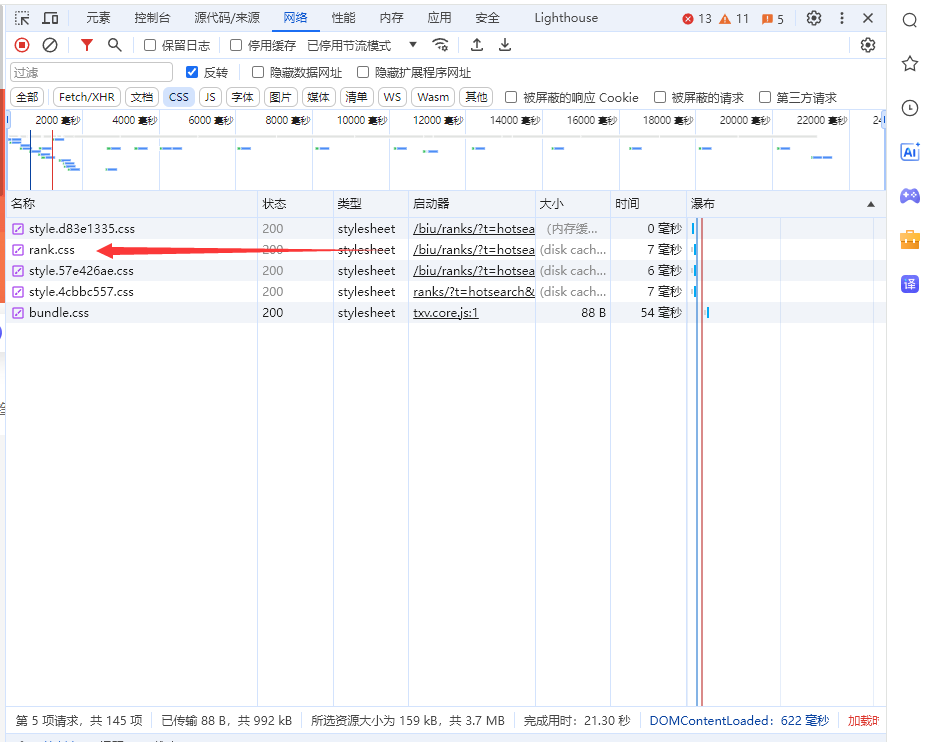
接下来获取我们的:User-Agent
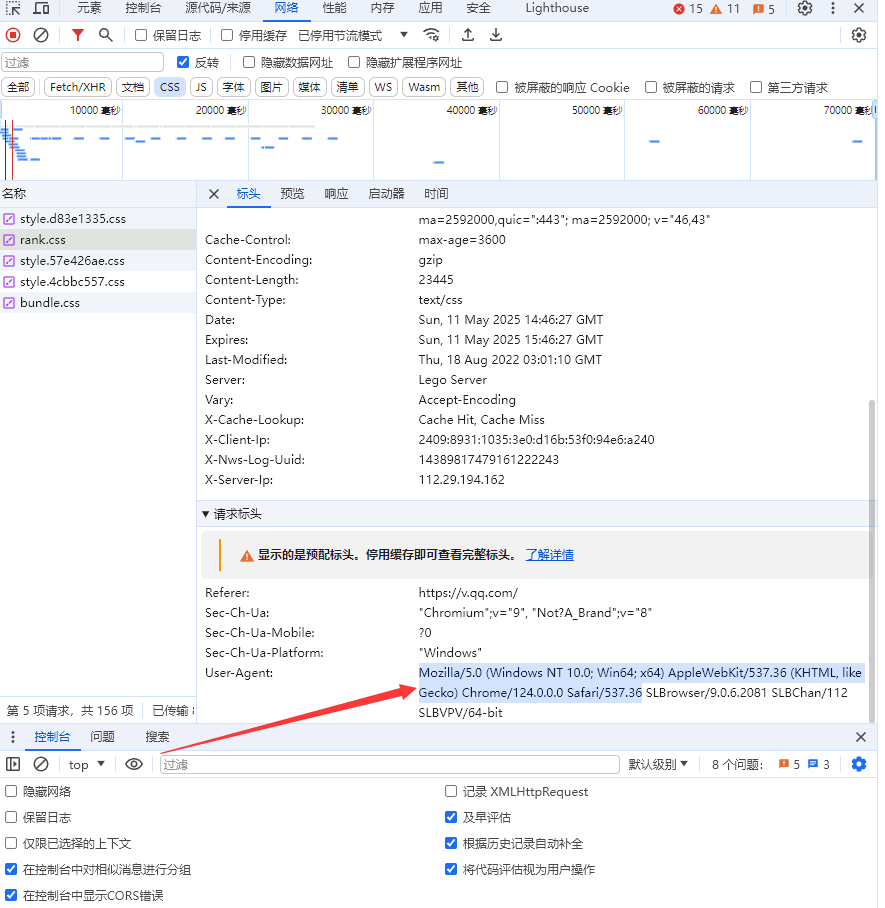
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}然后你可以根据自己的需要选择爬取前多少个榜单,这里我选择前十
titles = tree.xpath('//div[@class="item item_a"]/a/@title')[:n]基本上的重点就是上面的步骤!
import requests
from lxml import etree
url = 'https://v.qq.com/biu/ranks/?t=hotsearch&channel=0'
n = 10 # 你可以修改这个值来改变爬取的数量
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}
try:
# 获取网页内容
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
tree = etree.HTML(r.text)
# 提取前 n 个视频标题
titles = tree.xpath('//div[@class="item item_a"]/a/@title')[:n]
# 动态生成文件名和标题
output_filename = f'video_top{n}.txt' # 例如 video_top20.txt
# 保存到文本文件
with open(output_filename, 'w', encoding='utf-8') as f:
f.write(f"腾讯视频热搜榜Top{n}\n")
f.write("=" * 20 + "\n")
for i, title in enumerate(titles, 1):
f.write(f"{i}. {title}\n")
print(f"视频名字已成功保存到 {output_filename}") # 动态输出文件名
except Exception as e:
print(f"发生错误: {e}")代码说明
requests.get(url, headers=headers):发送HTTP GET请求,获取网页内容。response.encoding = 'utf-8':确保响应内容以UTF-8编码解析,避免乱码。etree.HTMLParser(encoding='utf-8'):使用lxml的HTML解析器,并指定编码为UTF-8。tree.xpath('//div[@class="item item_a"]/a/@title'):使用XPath表达式提取所有符合条件的标题。//div[@class="item item_a"]/a/@title表示查找所有class为item item_a的div元素下的a标签的title属性值。[:10]:只取前10个结果,可以根据自己的需要自己设定。
注意事项
- XPath表达式:确保XPath表达式与网页结构匹配。如果网页结构发生变化,可能需要调整XPath表达式。
- 反爬虫机制:某些网站可能会检测并阻止爬虫请求,可以通过设置更复杂的请求头或使用代理来规避。
运行结果
运行代码后,将输出腾讯视频热搜榜的前10个标题。如果网页结构或XPath表达式正确,结果将类似于以下内容:
lxml解析结果: ['标题1', '标题2', '标题3', '标题4', '标题5', '标题6', '标题7', '标题8', '标题9', '标题10']
如果结果为空或不符合预期,建议检查网页结构或调整XPath表达式。

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









