






系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
- 问题背景:联邦学习面临的三大挑战
通信效率:联邦学习需要多次在客户端和服务器之间传输模型参数或梯度,通信成本很高,可能导致效率低下甚至不可行。
隐私保护:共享的模型参数中可能会泄露训练数据的敏感信息,威胁用户隐私。
模型实用性:为保护隐私而引入的技术(如差分隐私)可能会影响模型的收敛性和准确性。 - 现有方法的局限性
差分隐私(DP)已被广泛应用于联邦学习中,但:
DP 噪声对模型的准确性和收敛性有负面影响。
DP 噪声可能导致额外的通信开销。
联邦学习本身通信成本高,进一步加剧了这些问题。 - 解决方案:Adap-FedITK
核心目标:
低通信开销:减少传输数据量。
高模型准确性:减轻 DP 噪声对模型性能的影响。
隐私保护:实现客户端级别的差分隐私。
关键技术:
动态梯度裁剪:
根据客户端梯度的异质性,动态调整每轮中不同客户端的梯度裁剪阈值。
目的是降低 DP 噪声的负面影响,平衡隐私保护和模型实用性。
改进的 Top-k 算法:
利用梯度稀疏性和量化技术对模型进行压缩,减少传输的数据量。
集成编码技术进一步降低通信成本,消除冗余信息。
4. 实验结果
广泛的实验验证表明:
Adap-FedITK 实现了隐私与实用性的良好权衡。
在保证客户端隐私的同时,大幅提高了通信效率。
5. 总结
这段内容展示了作者提出的创新方案 Adap-FedITK,它从 动态梯度裁剪 和 通信压缩技术 两个方面入手,试图同时解决联邦学习中的隐私保护、通信效率和模型实用性三个核心问题,并通过实验验证其有效性。
提示:以下是本篇文章正文内容,下面案例可供参考
为什么要提出来top-k
随着配备传感器、计算能力和存储能力的物联网(IoT)设备的数量持续增长,大量数据每天在网络边缘生成。分析这些数据能够推动各类智能解决方案的发展,比如医疗、农业和交通等领域。然而,传统的机器学习方法需要将所有原始数据传输到中央服务器进行集中处理,这样的做法已经被证明存在显著的安全隐患,包括数据泄露和滥用,极大地威胁到端到端隐私保护。因此,数据隐私问题近年来受到了广泛用户群体的关注,分布式机器学习逐渐成为数据处理任务的首选方法,而联邦学习(FL)则代表了这一领域的最新进展。
联邦学习是一种机器学习方法,可以在不泄露原始数据的情况下,实现来自多个参与方的协作学习。其基本机制是让每个设备在本地训练模型,然后只共享模型参数的更新,最终实现协作式学习和模型的改进。然而,仅仅发布模型的训练参数仍然不足以确保隐私,因为敏感数据仍可能被攻击者(如恶意中央服务器)从一小部分共享参数中轻易推断出来。为了应对这一问题,传统的联邦学习框架中引入了差分隐私(DP),用于保护客户端数据的隐私。然而,差分隐私噪声会显著降低模型性能,影响模型收敛性,并导致额外的通信开销。由于联邦学习本身通信成本高,这些问题进一步加剧了联邦学习在实际应用中的复杂性。
在传统的联邦学习中,稀疏化技术常被用于简化本地模型,包括 Rand-k 稀疏化和 Top-k 稀疏化。这些技术从本地模型中随机选择或保留具有最高幅值的参数,形成稀疏模型。减少模型参数的数量可以降低客户端的通信成本。根据文献指出,Top-k 稀疏化更适合减少通信开销,因为它能保留模型中更重要的参数,从而确保模型性能。然而,大多数现有的联邦学习工作仍然以全精度权重的形式传输本地模型,其中包含大量冗余参数,这种冗余的参数传输会消耗过多的通信成本。
为了优化通信效率,梯度量化方法被提出,通过减少传输位宽(如将位宽降低到三值、二值或任意低位宽)来消除通信冗余。虽然量化和稀疏技术确实能够减少传输位宽,现有方法通常仅聚焦于压缩客户端到服务器的上行通信,而忽视了下行通信的优化。如何同时压缩上行与下行通信,减少联邦学习中的通信冗余并确保模型性能,仍是一个充满挑战的研究领域。
隐私保护同样是联邦学习中的一个突出研究方向,因为在共享模型参数或梯度的过程中,攻击者可能推断出敏感信息。为了解决这个问题,差分隐私(DP)被引入到联邦学习中,以保护客户端的数据(如实例级 DP 或客户端级 DP)。通常来说,客户端级别 DP 模型被认为更适合实际应用,因为其性能更优。然而,为了实现客户端级 DP,引入的随机噪声可能会显著降低模型的效用,带来实用性下降的问题。
有效综合考虑隐私和实用性之间的平衡仍然是一个紧迫的问题。模型准确性下降的主要原因有两个:
局部更新中剪裁操作导致重要信息丢失,特别是在小裁剪阈值的情况下。
引入的随机噪声严重影响了局部更新,特别是在较大的裁剪阈值下。过低或过高的裁剪阈值都会导致性能退化和效用下降。
在本文中,我们提出了一种改进的差分隐私联邦学习(DPFL)方案,结合自适应梯度裁剪和改进的 Top-k 稀疏化算法,命名为 Adap-FedITK。该方案可以在实现客户端级别差分隐私的同时,确保模型准确性和低通信成本。
自适应梯度裁剪:
考虑到客户端梯度幅值的异质性,设计了一种自适应裁剪方法,为每个客户端动态设置裁剪阈值,并对裁剪后的梯度添加适当的噪声。
该方法减轻了 DP 噪声对模型性能的负面影响。
通信优化方案:
引入更加高效的压缩机制,减少模型参数上传到服务器时的通信成本。
改进的 Top-k 稀疏算法结合分布式学习模型和量化编码技术,优化了通信中的数据冗余问题,并进一步提升通信效率。
相关工作
客户端的差分隐私学习
客户端级差分隐私联邦学习(DPFL)是指将差分隐私保护机制引入到联邦学习中,以确保学习模型不会暴露单个客户端是否参与了训练。这意味着客户端的整个数据集受到来自其他客户端的差分攻击的保护。Geyer 等人 首次在客户端层面探索了联邦学习优化中的 GDP 问题。此外,尽管可以通过增加隐私预算和提高噪声大小来实现更高的隐私,但过多的噪声也会降低模型性能。
Wu 等人 发现,目前对 DPFL 的研究中,在模型中添加均匀噪声会显著降低性能,特别是对于大型和复杂模型 。在该领域,隐私与效用之间的平衡仍然是一个瓶颈问题。为了应对这一限制,引入了 Adap-DPFL 的概念。例如,Sun 等人 、Ghazi 等人 和 Girgis 等人 通过引入混洗模型(shuffle model)来减少客户端添加的噪声。Andrew 等人 提出了一种基于更新中值的自适应裁剪方法。然而,他们的方法基于本地客户端将原始模型上传到服务器并向聚合模型添加噪声。这些解决方案依赖于受信任的服务器,但客户端敏感数据仍有可能泄露到服务器。
为了克服这一挑战,当前研究集中于向上传的本地模型添加噪声。Work 等人 提出了一个基于梯度感知裁剪的方案,该方案能够根据不同客户端的梯度情况自适应地裁剪梯度,从而减少理论指导的不足。
Yuan 等人 提出了一个噪声,其幅度随着几何级数递增,通过分析这种噪声的理论机制改进了模型性能。Pichapati 等人 提出了基于坐标的 DP-SGD 自适应裁剪方法,该方法通过减少每轮梯度中添加的噪声来改善模型性能。Xue 等人 设计了一种基于本地和全局历史信息的通用方法,用于敏感度估计,并使用自适应噪声来降低 DP 对联邦学习的影响。
然而,这些工作都没有考虑客户端本地模型参数在不同轮次中的梯度差异,这将导致噪声对模型影响的减弱。因此,我们考虑在客户端训练期间的梯度异质性,并设计自适应阈值梯度裁剪以处理每个客户端的模型参数,然后将适当的噪声添加到梯度中。
模型压缩
模型压缩是解决在传输复杂模型时,通信成本过高问题的一种常用方法。Mills 等人 改进了 FedAvg 算法,提出了 CE-FedAvg 算法,该算法结合了分布式 Adam 优化形式和一种新的压缩技术。Jiang 等人 提出了一种自适应模型裁剪方法,该方法在联邦学习过程中调整模型大小,从而减少通信和计算成本。
为了减少联邦学习中的上行通信成本,已有两种方法被提出:1)结构化更新,2)广义更新 。然而,大多数现有的压缩技术仅在理想条件下(如设备上的数据分布均衡时)运行良好,而对于非独立同分布(non-IID)数据的模型收敛性并未得到保证。为了解决模型压缩的高效通信和有限的收敛性问题,Ström 提出仅将振幅超过预定义阈值的梯度发送到服务器,以实现模型稀疏化。然而,选择适当的阈值在实际应用中仍然是一项具有挑战性的任务。
为应对上述挑战,Aji 和 Heafield 提出了 top-k 稀疏化方法,通过仅传输具有最大振幅的 k 个梯度条目来压缩模型。然而,传输 top-k 高精度模型参数可能导致大量冗余参数。已有研究 表明,这种更新方法仍会产生过高的通信成本。通过将稀疏性与非零元素的量化相结合,可以减少每个参数的传输位数,消除通信冗余,从而获得更高的通信增益。
Hu 等人 提出了一个新的客户端级差分隐私方案(Fed-SMP),同时兼顾了模型性能和通信成本。Fed-SMP 利用 top-k 稀疏化来压缩通信模型的大小。为了使客户端能够以相同参数坐标传输稀疏掩码梯度,该方法使用公共数据集来获取公共掩码。然而,这种方法假设服务器具有与所有客户端数据集相似的全局数据分布,这在实际中难以实现。
与现有联邦学习研究相比,本文结合了联邦学习的通信效率、隐私性和模型效用。具体来说,本文提出了自适应阈值梯度裁剪,改进了 top-k 稀疏算法,并从理论上分析了模型扰动稀疏化对 Adap-FedITK 收敛性的影响。本文还改进了 DPFL 的通信效率,同时兼顾隐私性和实用性之间的平衡,填补了当前研究的空白。
问题描述

威胁模型
在上述协议中,客户端的训练数据从未离开本地,但中间参数需要参与服务器共享。本文假设服务器是“诚实但好奇”的,它可能通过模型推断攻击来揭示关于客户端的私密信息。例如,Fredrikson 等人 提出了一个用于图像检索的逆向攻击模型,使用面部识别系统。Shokri 等人 [提出了对模型的推断攻击,旨在暴露与模型泄露相关的隐私风险,并针对这些攻击提出对策。
此外,在从服务器下载全局模型参数后,客户端也可以通过上述攻击推断其他客户端的私密信息。
差分隐私


方法论
提示:这里对文章进行总结:
自适应梯度裁剪


改进的 Top-k 稀疏化
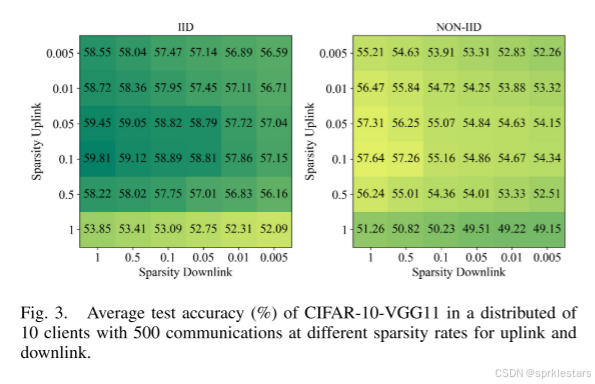



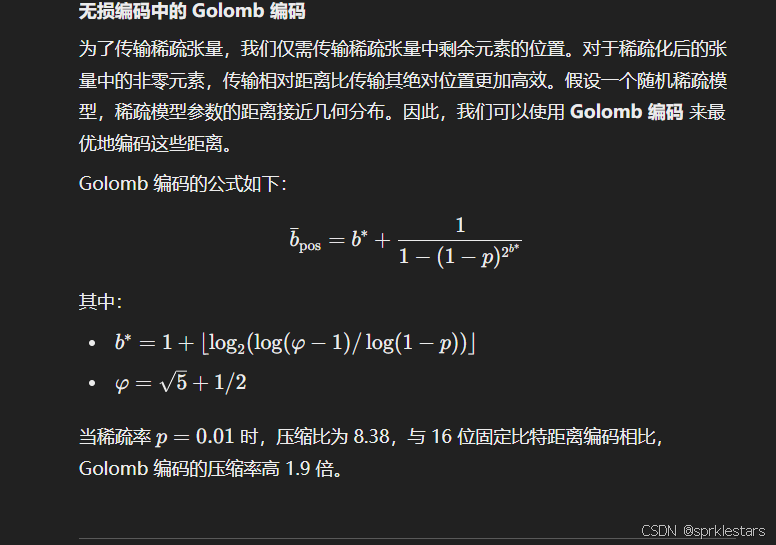
结合量化和无损编码
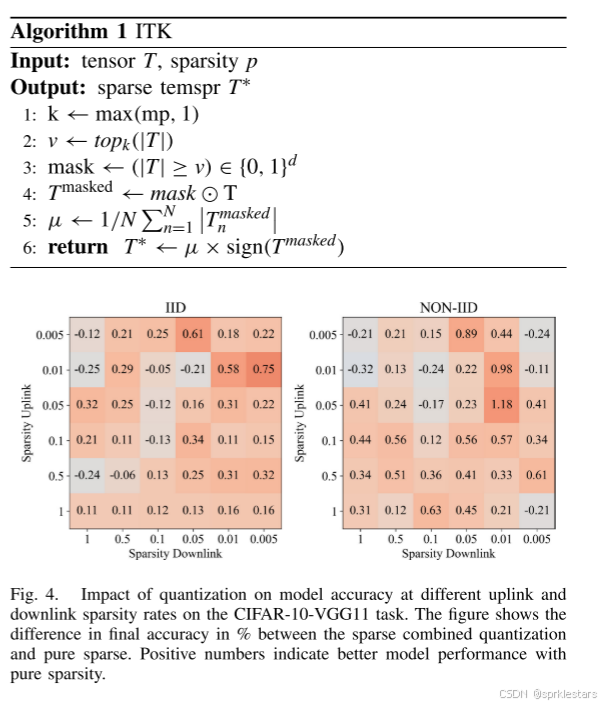



Adap-FedITK






算法的优势
隐私保护:
随机采样和高斯噪声提供强大的隐私保护,满足差分隐私要求。
自适应裁剪减少了隐私机制对模型性能的负面影响。
通信效率:
稀疏化与 Golomb 编码的结合显著降低了上行和下行通信量。
在非 IID 数据分布下也能维持高效通信。
模型性能:
考虑到客户端间的梯度异质性,动态裁剪和稀疏化提高了模型的收敛性。
在降低通信量的同时,保持或提高了模型的最终精度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









