






系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
概括
提示:这里可以添加本文要记录的大概内容:
目前大多数旨在保护隐私的联邦学习方案都存在合谋攻击的脆弱性,并且缺乏参与者的验证机制来巩固参数服务器的聚合结果,从而导致用户的隐私泄露和不准确的模型训练结果。为了解决这些问题,我们提出了一个可验证的隐私保护联邦学习框架对抗共谋攻击。首先,利用ElGamal加密算法重新配置联合学习方案,该算法有效地保护了某些参与者和服务器之间勾结的情况下参与者的数据隐私。此外,辅助服务器的引入可以实现非合谋的参数服务器和辅助服务器对梯度密文的联合解密,可以有效抵御数据上传过程中单一参数服务器模型的内部攻击。第三,该方案设计了一种验证机制,使参与者能够有效地验证参数服务器聚合结果的准确性和完整性,防止参数服务器向参与者返回不正确的聚合结果。实验结果和性能分析表明,我们提出的方案不仅加强了安全措施,而且还保持了模型训练的精度,超过了许多现有的方法的安全性和正确性。
提示:以下是本篇文章正文内容,下面案例可供参考
一、背景介绍
随着算法的显著进步和数据的广泛可用,深度学习在图像识别 [1]、语言翻译 [2]、医学诊断 [3] 和金融投资 [4] 等领域取得了重要里程碑,接近甚至超越了人类水平。大量的数据在促进深度学习训练和预测过程中发挥了关键作用;然而,这也带来了隐私方面的担忧。首先,将参与者的私密数据纳入数据集可能无意中暴露相关个人的敏感信息。此外,当数据上传至服务器时,数据拥有者对其私密数据的使用缺乏意识和控制。某些领域,如医疗机构,受限于法规,禁止共享敏感数据,如患者记录。因此,如果医疗机构希望构建一个高精度的医学诊断模型,而法律限制仅能访问非敏感数据,那么机构内可用的数据的有限性可能导致训练出不准确的深度学习模型。
为了保护参与者的隐私,研究人员提出了联邦学习的概念。该方法允许彼此不信任的参与者在不泄露各自私人数据集的情况下进行协作学习。与仅依赖本地数据集不同,通过共享深度学习模型,所有参与者共同训练出更精准的模型。首先,每个参与者使用各自的本地数据集独立训练模型,生成梯度向量。随后,这些梯度向量被上传至参数服务器进行聚合。聚合完成后,每个参与者从参数服务器获取聚合后的梯度向量,并利用它们更新本地深度学习模型。这个迭代过程将持续进行,直到得到更精确的模型。尽管联邦学习能够防止攻击者直接访问私人数据,Phong 等人 [5] 表明,即使仅共享梯度,敌对者仍然可以访问参与者的私密数据。同时,Ma 等人 [6] 提出了利用 ElGamal 同态加密算法的多方深度学习方案 [7]。虽然该方案有效地保护了参与者私密信息的机密性,但它仍存在一定的安全局限性。首先,同态加密密钥的生成需要参数服务器和参与者的协作。因此,如果参数服务器与参与者串通,密钥的完整性将受到破坏,导致参与者的数据易受攻击。其次,参与者在密钥生成和联合解密中的参与会对其带来显著的负担。
为了应对上述问题,本研究提出了一种创新的联邦学习方案,优先考虑隐私保护。该方案保护参与者免受串通攻击,保持聚合结果的准确性和完整性,保护同态加密密钥,并最大限度地减少参与者的通信成本。本文的主要贡献包括:
提出了一个新的可验证隐私保护联邦学习框架(VPFLCA),利用 ElGamal 同态加密算法确保参与者敏感信息的机密性,并有效防止服务器与某些参与者之间的串通攻击;
引入了一个辅助服务器,作为防范服务器和参与者之间串通攻击的对策。参数服务器和辅助服务器可以共同解密使用 ElGamal 加密算法加密的梯度密文,有效防止在数据上传过程中单一参数服务器模型的内部攻击。此外,该辅助服务器的引入不仅减少了参与者的参与度,还降低了与参与者相关的通信成本;
提出了一个验证机制,使参与者能够有效验证聚合结果的准确性和完整性,利用双线性聚合签名,防止参数服务器向参与者返回错误的聚合结果,从而确保聚合结果的准确性;
通过实验评估了该方案,结果表明,所提出的方案在安全性、效率和准确性方面表现优异。
本文结构如下:第二部分概述了现有的隐私保护深度学习研究;第三部分介绍了深度学习及相关技术的基础;第四部分详细介绍了 VPFLCA 的系统模型和安全需求;第五部分阐述了我们提出的方案的架构和具体细节;第六部分分析了 VPFLCA 的安全性和可验证性;第七部分提供了理论分析和实验模拟;最后,第八部分做出总结。
二、前瞻知识
在隐私保护深度学习领域,近年来许多研究者做出了重要贡献。这些贡献可以分为两大类:基于数据扰动的机制,如差分隐私,和基于密码学的机制,包括同态加密和安全多方计算(SMPC)。此外,我们还调查了与可验证性和串通攻击相关的研究工作。
差分隐私被广泛应用于隐私保护深度学习,作为一种主流的数据扰动机制。Shokri等人提出了一种深度学习系统,参与者向梯度中添加噪声,并选择性地共享梯度(例如1%至100%),以并行训练模型。然而,Phong等人发现,在多方深度学习中,参与者向参数服务器传输梯度可能会通过差分隐私无意间泄露其私有数据。Zhang等人提出了两种为分布式学习算法提供差分隐私的方法。Phan等人引入了一种专门针对深度学习训练的差分隐私机制,在该机制中,噪声的注入不是依赖于训练步骤的数量,而是根据神经网络中特征的贡献动态调整。Miran等人成功地将同态加密与差分隐私相结合,应用于逻辑回归算法,形成了一个高效且安全的适用于机器学习的方案。Gong等人提出了一个隐私增强的多方深度学习框架,在其中他们在训练的不同阶段动态分配隐私预算,以进一步提高安全性,而不影响模型训练精度。
SMPC因其在交互过程中保护参与者隐私的能力而被广泛认可,并且被认为在深度学习训练中能够有效维护隐私安全。然而,采用SMPC往往会导致较高的通信和计算复杂度,从而影响实际应用中的效率。2017年,Mohassel等人提出了安全的二方计算协议,用于线性回归、逻辑回归和神经网络训练。这些协议促进了对共享小数和非线性函数(如Sigmoid和Softmax)的安全算术操作。为了保护深度学习中的用户隐私,Bansal等人构建了一种基于秘密共享和安全标量的二方协议。然而,随着参与者数量的增加,该方案的效果会下降。Bonawitz等人提出了一种利用秘密共享技术的安全数据聚合方法,允许任何参与者撤销参与。然而,采用秘密共享技术会导致参与者的通信开销过大。
同态加密为在深度学习中保护私有数据提供了有前景的解决方案,因为它允许对加密数据进行算术操作。Phong等人基于Paillier和LWE加密系统构建了两种隐私保护的深度学习方案。然而,所有参与者共享一个公共加密密钥,这使得该方案容易受到恶意参与者的未授权访问。Tang等人解决了分布式深度学习方案中共享单一密钥加密的问题,从而防止了云服务器与任何学习参与者之间的串通。然而,这种方法会增加参与者的开销。Zhang等人提出了两种隐私保护的深度学习方案(DeepPAR和DeepDPA),其中DeepPAR保护了每个参与者的输入隐私,同时保持动态更新的机密性,但该方案对串通攻击没有防护。
在可验证性方面,Ma等人首次引入了隐私保护深度学习中的可验证性概念。然而,仍然存在参数服务器和参与者之间串通的潜在风险。Xu等人提出了一种隐私保护和可验证的联邦学习框架。该框架通过使用同态哈希函数和双重掩蔽协议来确保结果的正确性,同时通过变体的秘密共享技术和密钥协议保护用户本地梯度的隐私。然而,需要注意的是,该方案的通信成本较高。Guo等人提出了一种可验证的聚合协议,在联邦学习中,该协议在通信和计算方面都高效,同时通过使用线性同态哈希和承诺方案确保聚合过程的完整性。该协议有效解决了与聚合相关的安全挑战,并提供了显著的具体效率。Zhou等人提出了一种隐私保护和可验证的联邦学习方法,称为PVFL,该方法最小化了验证所需的通信和计算开销。该方法通过引入差分隐私噪声来保护客户端的隐私,同时采用非追溯的验证机制,实现了独立于掉线和维度的验证通信开销。
针对串通攻击,Byrd等人提出了一种基于盲分布式差分隐私的安全联邦学习协议,有效防止了客户端串通和Sybil攻击。Du等人提出了一个针对跨孤岛联邦学习的可验证且抗串通攻击的隐私保护框架,采用Paillier加密系统和batchcrypt。然而,Paillier加密系统相比于ElGamal或EC-ElGamal等加密系统,带来了更高的通信和计算成本。Gao等人提出了一种动态联邦学习方法,既可验证又能抗串通攻击,采用了拉格朗日插值和承诺技术。Xiao等人提出了一个针对工业物联网的基于Sybil的串通攻击(SCA)的联邦学习系统。该技术的主要目的是提高聚合中毒串通模型的可能性,从而有效隐藏其攻击行为。然而,该方案没有考虑可验证性。
在隐私保护联邦学习领域,现有的若干方案未能同时解决抵抗串通攻击和可验证性的问题。虽然有些方案考虑了这两个方面,但它们会导致较高的通信和计算开销。为了解决上述问题,本研究在确保隐私保护、可验证性和抗串通性时,改进了相关技术和验证方法,同时保证参与者的通信和计算开销较低。
三、加密手段


1.系统模型
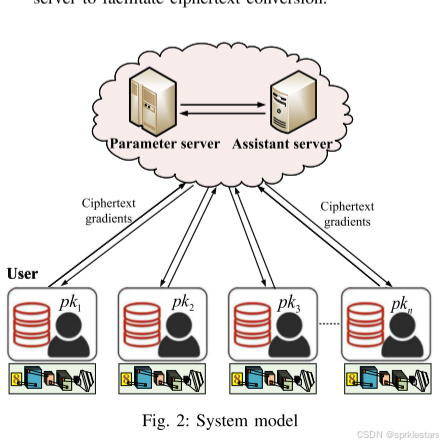
参与者:
每个参与者拥有一个独立的数据集,用于协同训练更精确的学习模型。为此,每个参与者从自己的数据集中选择一个小批量数据来训练新的梯度向量。然后,他们加密这些梯度向量并将其上传到参数服务器。
参数服务器:
参数服务器具备强大的存储和计算能力,以提供云服务。它聚合所有参与者上传的加密梯度向量,同时与辅助服务器合作,确保训练参与者数据的隐私。
辅助服务器:
辅助服务器协助参数服务器执行联邦学习以保护隐私。它持有部分私钥,主要与参数服务器合作,促进密文转换的过程。
威胁模型
在系统模型中,参数服务器可能是恶意服务器,即参数服务器可能会主动偏离协议,试图破坏参与者的隐私并用虚假的结果进行欺骗。辅助服务器是半诚实模型,它严格遵循协议并返回正确的计算结果,但对计算出的敏感数据感到好奇。此外,我们假设参数服务器和辅助服务器之间没有串通。同时,每个实体可能会部分地与其他实体串通,以获取其他参与者的私人信息。此外,我们提出的方案中的所有数据都通过不安全的公共通道传输,使其容易受到窃听。在本文中,我们引入了一个主动攻击者A,攻击者A的目标是获取参与者的私人数据。具体来说,攻击者A在该场景中具有以下能力:
A可以窃听所有实体之间的通信,以通过公共通道获取加密数据。
A可能通过执行交互协议来破坏参数服务器或辅助服务器,目的是获取关于参与者的敏感信息。
A可能与部分参与者串通,目的是获取关于其他参与者的敏感信息。然而,A不能同时与参数服务器和辅助服务器串通,否则这将违反假设,即参数服务器和辅助服务器之间没有串通。
C. 设计目标
在阐述复杂的框架之前,必须明确隐私保护联邦学习方案的目标,即确保深度学习方案的有效性、保护机密信息、优化训练模型的效率,并确保该方案的可验证性。
功能性: 在隐私保护的联邦学习方案中,我们的目标是确保参与者能够成功训练出符合其要求的模型,使他们能够完成所需的任务,如图像分类。
隐私性: 保护参与者的本地数据集至关重要。此外,在数据传输过程中,必须防止通过传输信息泄露参与者的私人信息。
有效性: 在保持理论可行性的同时,必须确保该方案的实际适用性。这需要对真实数据集进行测试,并根据实验结果解释方案的可行性。
可验证性: 参数服务器在该方案中执行梯度聚合,因此参与者需要有效验证参数服务器返回的聚合结果的正确性。
方案内容

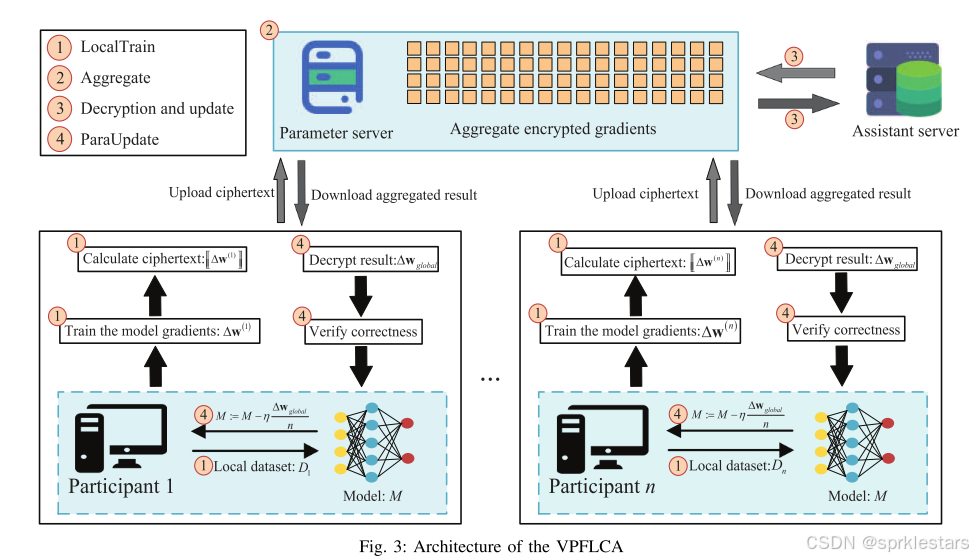


本地训练阶段


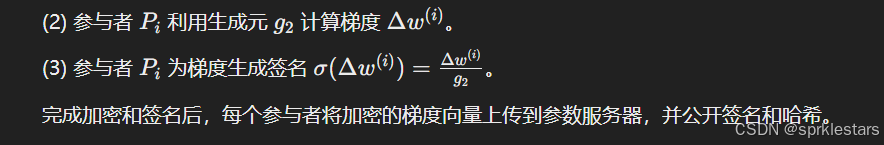

全局聚合
提示:这里对文章进行总结:

密文转换



总结:参数服务器+辅助服务器+可验证+双线映射保证安全性


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









