







免责声明
本文技术内容仅供学习研究之用,转载请说明出处,如有侵权联系删除。作者不保证信息完全准确,不对因使用本文导致的任何损失负责。读者应自行承担使用风险,并遵守相关法律法规。
知识点概括
BeautifulSoup的使用
解析html
lxml
线程池
前期准备
文末进群
网站:https://haowallpaper.com
注意!!!爬虫请遵守法律法规。
如果没有安装lxml包的需要安装一下:
pip install lxml
实现过程
lxml
先讲一下lxml吧
lxml是一个高性能的XML和HTML解析库,它基于C语言的libxml2和libxslt库实现。虽然Python标准库中已经提供了xml.etree.ElementTree等用于解析XML的模块,但lxml在性能和功能上更为强大,因此它被设计为一个独立的第三方库。
使用 lxml 的原因
- 高性能:
lxml基于C语言实现,解析速度比Python自带的xml.etree.ElementTree更快。- 功能强大:
lxml支持XPath和CSS选择器,能够更灵活地提取HTML和XML中的数据。- 兼容性好:
lxml对HTML的解析非常宽容,即使HTML代码有错误,它也能正确解析。
寻找目标
在浏览器打开开发者工具,然后输入目标网址并回车,打开请求的文档数据包,看其响应。
- 搜索大法。
如图所示:第一个图片的标题中包含红色,那就直接在html数据中搜索,按ctrl+f搜索红色,可以看到其位置。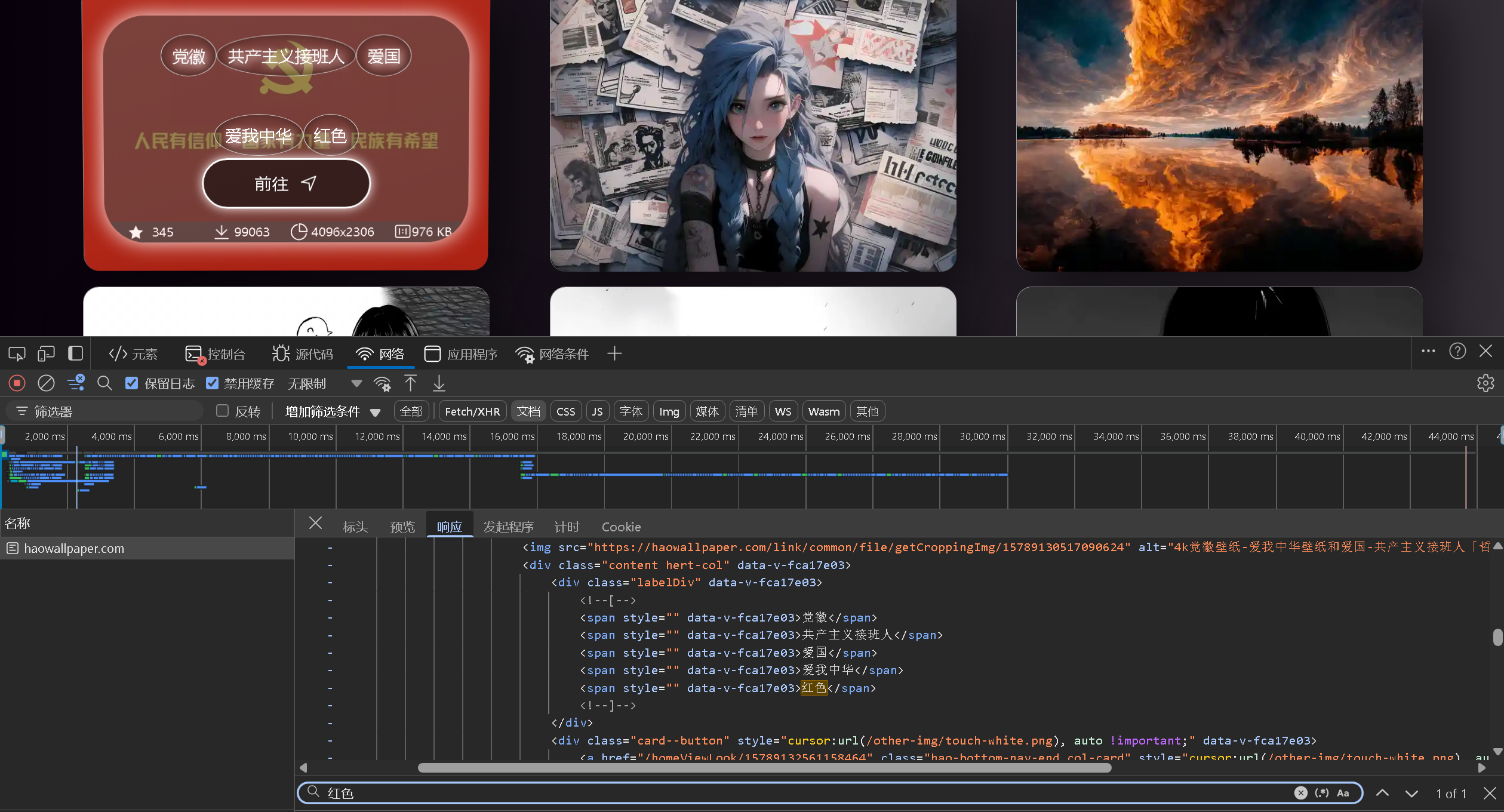
- 定位元素,拿到部分源码:
<div class="homeContainer" style="" data-v-fca17e03> <!--[--> <div class="card" style="animation-duration:0.125s;" data-v-fca17e03> <img src="https://haowallpaper.com/link/common/file/getCroppingImg/15789130517090624" alt="4k党徽壁纸-爱我中华壁纸和爱国-共产主义接班人「哲风壁纸」" title="4k党徽壁纸-爱我中华壁纸和爱国-共产主义接班人「哲风壁纸」" data-v-fca17e03> <div class="content hert-col" data-v-fca17e03> <div class="labelDiv" data-v-fca17e03> <!--[--> <span style="" data-v-fca17e03>党徽</span> <span style="" data-v-fca17e03>共产主义接班人</span> <span style="" data-v-fca17e03>爱国</span> <span style="" data-v-fca17e03>爱我中华</span> <span style="" data-v-fca17e03>红色</span> <!--]--> </div> <div class="card--button" style="cursor:url(/other-img/touch-white.png), auto !important;" data-v-fca17e03> <a href="/homeViewLook/15789132561158464" class="hao-bottom-nav-end col-card" style="cursor:url(/other-img/touch-white.png), auto !important;" data-v-fca17e03 data-v-ea2948d5> <span data-v-ea2948d5>前往</span> <span data-v-ea2948d5></span> </a> </div> <div class="card--center" data-v-fca17e03> <div data-v-fca17e03> <span data-v-fca17e03></span> 345 </div> <div data-v-fca17e03> <span data-v-fca17e03></span> 99063 </div> <div data-v-fca17e03> <span data-v-fca17e03></span> 4096x2306 </div> <div data-v-fca17e03> <span data-v-fca17e03></span> 976 KB </div> </div> </div> </div> <div>... </div> <!--更多--> </div> - 我们想要的是
img标签中的图片链接。观察源码,直接写出定位代码:
解释:img_list=BeautifulSoup(response.text,'lxml').find('div',class_="homeContainer").find_all('img')-
BeautifulSoup(response.text, 'lxml')
•response.text:response是一个 HTTP 响应对象,通常是通过requests库从某个网页获取的。response.text表示网页的 HTML 源代码(以字符串形式)。
•BeautifulSoup:这是 Python 中用于解析 HTML 和 XML 文档的库。它会将 HTML 文本解析成一个可操作的树形结构,方便后续提取数据。
•'lxml':这是 BeautifulSoup 的解析器,lxml是一个高效的解析器,它解析速度快且功能强大。
这部分代码的作用是将网页的 HTML 内容解析成一个 BeautifulSoup 对象,方便后续提取数据。 -
.find('div', class_="homeContainer")
•.find:这是 BeautifulSoup 对象的一个方法,用于查找第一个匹配的 HTML 元素。
•'div':表示要查找的 HTML 元素是<div>标签。
•class_="homeContainer":表示要查找的<div>标签的class属性值为"homeContainer"。
这部分代码的作用是找到页面中第一个class为"homeContainer"的<div>元素。
• 注意class是python保留关键字,为避免冲突,用class_代替。 -
.find_all('img')
•.find_all:这是 BeautifulSoup 对象的一个方法,用于查找所有匹配的 HTML 元素。
•'img':表示要查找的 HTML 元素是<img>标签。
这部分代码的作用是在上一步找到的<div>元素内部,查找所有的<img>标签。 -
[img['src'] for img in ...]
•for img in ...:这是一个列表推导式,用于遍历上一步找到的所有<img>标签。
•img['src']:对于每一个<img>标签,提取其src属性的值。src属性通常存储图片的 URL 链接。
这部分代码的作用是将所有<img>标签的src属性值提取出来,存储到一个列表中。 -
完整代码的作用
• 这行代码的目的是从网页的 HTML 内容中提取出位于class="homeContainer"的<div>元素内部的所有图片的 URL 链接,并将这些链接存储到一个名为img_list的列表中。
-
构建请求
快速构建爬虫代码工具:点击访问
用法: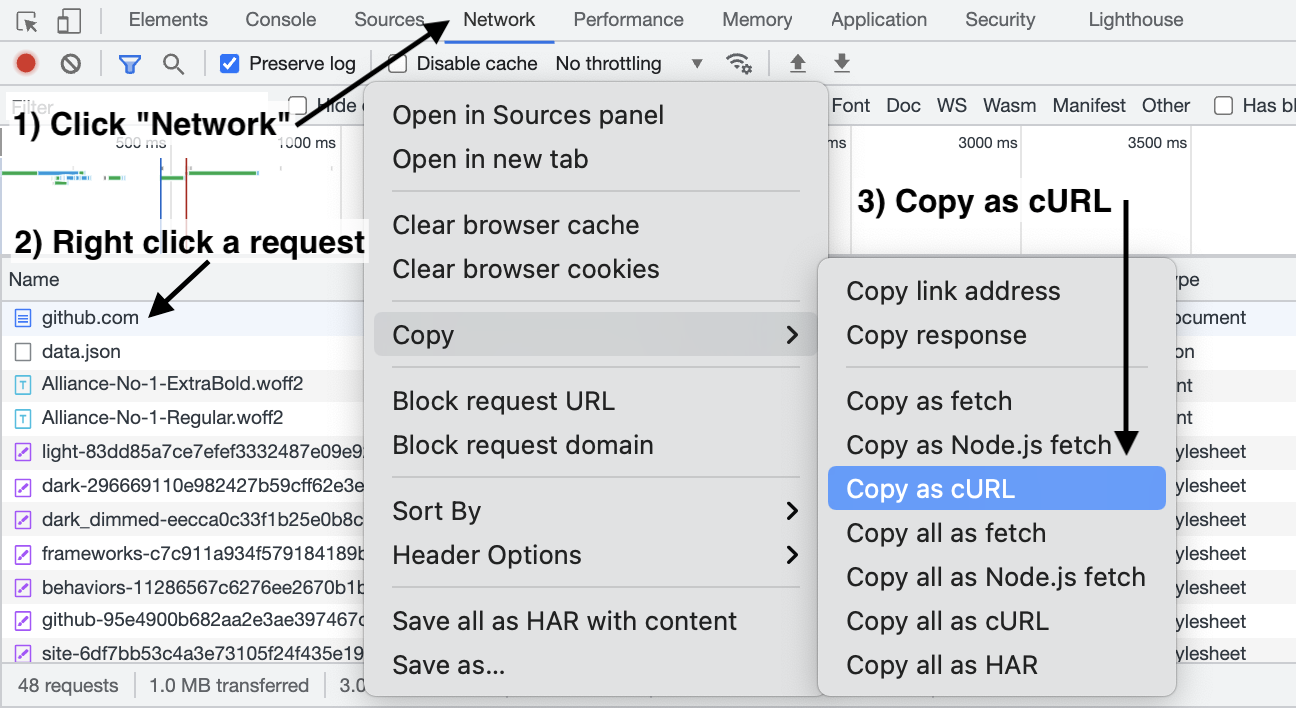
将请求的数据包复制为curl,然后构建请求。同时找到html的编码方式。
编码方式:

代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'DNT': '1',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
'sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-gpc': '1',
}
response = requests.get('https://haowallpaper.com/', headers=headers)
response.encoding = 'utf-8'
img_list = [img['src'] for img in BeautifulSoup(response.text, 'lxml').find('div', class_="homeContainer").find_all('img')]
print(img_list)
运行结果:

点击第一个图片链接,发现就是网站中的图片。
保存图片
图片是需要以二进制的方式读取和写入的。
现在我们的目的是:给一个图片链接,需要保存为图片。
写代码:
def down_one_pic(pic_link: str):
response1 = requests.get(pic_link, headers=headers)
with open(f'{pic_link.split("/")[-1]}.jpg', 'wb') as f:
f.write(response1.content)
解释:
def down_one_pic(pic_link: str):
•def:定义一个函数。
•down_one_pic:函数的名称,表示该函数的功能是下载一张图片。
•pic_link: str:函数的参数,表示图片的链接,类型为字符串(str)。response1 = requests.get(pic_link, headers=headers)
•requests.get(pic_link, headers=headers):
•requests:这是一个 Python 的第三方库,用于发送 HTTP 请求。
•get:requests库中的一个方法,用于发送 GET 请求,获取指定 URL 的内容。
•pic_link:函数的参数,表示要下载的图片的 URL。
•headers=headers:在发送请求时,附带自定义的 HTTP 请求头。headers是一个字典,通常用于伪装请求来源,避免被服务器拒绝。
• 这行代码的作用是向pic_link发送一个 GET 请求,获取图片的内容,并将响应对象存储在变量response1中。with open(f'{pic_link.split("/")[-1]}.jpg', 'wb') as f:
•with open(...):使用with语句打开文件,这样可以确保文件在操作完成后自动关闭。
•f'{pic_link.split("/")[-1]}.jpg':
•pic_link.split("/"):将图片链接按照/分割成一个列表。例如,如果pic_link是"https://example.com/path/to/image.jpg",那么分割后的列表是['https:','','example.com','path','to','image.jpg']。
•[-1]:取列表的最后一个元素,即图片的文件名(image.jpg)。
•.jpg:将文件名扩展名设置为.jpg,确保保存的文件是一个 JPG 格式的图片。
•'wb':表示以二进制写入模式打开文件。图片内容是二进制数据,因此需要使用二进制模式写入。
•as f:将打开的文件对象赋值给变量f。
• 这行代码的作用是根据图片链接的文件名,创建一个本地文件,准备写入图片内容。f.write(response1.content)
•response1.content:response1是requests.get返回的响应对象,content属性包含服务器返回的二进制内容,即图片的二进制数据。
•f.write(...):将图片的二进制数据写入到之前打开的文件中。
• 这行代码的作用是将从服务器获取的图片内容写入到本地文件中。- 完整代码的作用
- 从指定的图片链接(
pic_link)下载图片。- 根据图片链接的文件名,将图片保存到本地,文件扩展名统一为
.jpg。
先保存一个试试:
down_one_pic(img_list[0])
运行后发现同目录下有一张图片,并且可以打开,说明成功保存。
然后就是批量保存
for img_link in img_list:
down_one_pic(img_link)
ok
多页请求
先说一下,想实现多页请求,有两种方法:
- get直接请求页码,然后解析响应
方法最简单- xhr请求,需要加密和解密
有一定难度,不在本次学习范围内,以后有机会讲
所以我们只讲最简单的方法
翻页
点击第二页进行翻页,观察url变成:https://haowallpaper.com/?isSel=true&page=2,但是却找不到文档请求,也找不到图片链接(实际上是用了xhr请求,携带了一个加密的参数,返回了加密的数据,图片链接的部分信息就在解密后的数据中)。但是我们换个思路,既然url变了,我们直接重新开一个浏览器(最好是inprivate浏览),请求刚才的链接:然后我们找到了文档请求,且也能找到图片链接,这时候我们依然可以用刚才的方法下载图片。
多页
那么如何多页呢?观察url:https://haowallpaper.com/?isSel=true&page=2,只需要把page=2改成page=3就能拿到第三页的数据,以此类推,就可以拿到多页数据,我们只下前10页。
代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'DNT': '1',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
'sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-gpc': '1',
}
def down_one_pic(pic_link: str):
"""
下载一个图片
"""
response1 = requests.get(pic_link, headers=headers)
with open(f'{pic_link.split("/")[-1]}.jpg', 'wb') as f:
f.write(response1.content)
print(f'{pic_link.split("/")[-1]}.jpg 下载完成')
def get_one_page_pic(page_num: int) -> list:
"""
返回每一页的图片链接列表
"""
response = requests.get(f'https://haowallpaper.com/?isSel=true&page={page_num}', headers=headers)
response.encoding = 'utf-8'
img_list = [img['src'] for img in BeautifulSoup(response.text, 'lxml').find('div', class_="homeContainer").find_all('img')]
return img_list
if __name__ == "__main__":
for i in range(1, 11):
print(f'正在下载第{i}页图片')
img_list_n = get_one_page_pic(i)
for img_link in img_list_n:
down_one_pic(img_link)
线程池
如果你执行上面代码,你会发现下载的好慢,程序只能等上一张图片下完才能下载下一张,而且只能等待上一页下完,才能下载下一页。
有没有可能让多个图片同时下载呢,有:线程池。
我先把代码贴出来,然后解释:
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'DNT': '1',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
'sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-gpc': '1',
}
def down_one_pic(pic_link: str):
response1 = requests.get(pic_link, headers=headers)
with open(f'{pic_link.split("/")[-1]}.jpg', 'wb') as f:
f.write(response1.content)
print(f'{pic_link.split("/")[-1]}.jpg 下载完成')
def get_one_page_pic(page_num: int):
response = requests.get(f'https://haowallpaper.com/?isSel=true&page={page_num}', headers=headers)
response.encoding = 'utf-8'
img_list = [img['src'] for img in BeautifulSoup(response.text, 'lxml').find('div', class_="homeContainer").find_all('img')]
with ThreadPoolExecutor(max_workers=6) as executor:
executor.map(down_one_pic, img_list)
if __name__ == "__main__":
page_list = list(range(1, 11))
with ThreadPoolExecutor(max_workers=2) as executor1:
executor1.map(get_one_page_pic, page_list)
代码解释:
-
down_one_pic函数:
• 从给定的图片链接(pic_link)下载图片并保存到本地。
• 使用requests.get发起请求,获取图片内容。
• 将图片保存为本地文件,文件名从链接中提取。 -
get_one_page_pic函数:
• 获取指定页面(page_num)的图片链接列表。
• 使用requests.get获取页面内容。
• 使用 BeautifulSoup 解析页面,提取图片链接。
• 使用线程池并发下载页面中的所有图片。 -
主程序:
• 遍历所有页面(从第 1 页到第 10 页)。
• 使用线程池并发处理每个页面的图片下载任务。
线程池的用法:
线程池是并发编程中的一种机制,用于管理和复用线程资源。它可以帮助我们高效地执行大量并发任务,而无需手动创建和管理线程。
ThreadPoolExecutor
ThreadPoolExecutor是concurrent.futures模块中的一个类,用于创建线程池。它提供了简单易用的接口来并发执行任务。
代码中的线程池使用:
-
主线程池(
executor1)if __name__ == "__main__": page_list = list(range(1, 1157)) with ThreadPoolExecutor(max_workers=2) as executor1: executor1.map(get_one_page_pic, page_list)•
page_list:包含所有页面编号的列表(从 1 到 10)。
•ThreadPoolExecutor(max_workers=2):
• 创建一个线程池,最多允许同时运行 2 个线程。
•executor1.map(get_one_page_pic, page_list):
• 将get_one_page_pic函数和page_list中的每个页面编号一一对应。
• 线程池会自动分配任务到线程中并发执行。
• 每个线程负责调用get_one_page_pic函数处理一个页面。 -
子线程池(
executor)def get_one_page_pic(page_num: int): response = requests.get(f'https://haowallpaper.com/?isSel=true&page={page_num}', headers=headers) response.encoding = 'utf-8' img_list = [img['src'] for img in BeautifulSoup(response.text, 'lxml').find('div', class_="homeContainer").find_all('img')] with ThreadPoolExecutor(max_workers=6) as executor: executor.map(down_one_pic, img_list)•
img_list:从页面中提取的图片链接列表。
•ThreadPoolExecutor(max_workers=6):
• 创建一个线程池,最多允许同时运行 6 个线程。
•executor.map(down_one_pic, img_list):
• 将down_one_pic函数和img_list中的每个图片链接一一对应。
• 线程池会自动分配任务到线程中并发执行。
• 每个线程负责调用down_one_pic函数下载一张图片。
线程池的优势:
- 提高效率:
• 并发执行任务,充分利用多核 CPU 的性能,减少总执行时间。- 资源管理:
• 限制最大线程数(max_workers),避免过多线程占用系统资源。- 简化代码:
• 使用executor.map可以轻松实现并发任务的分配,无需手动管理线程的创建和销毁。
线程池的使用注意事项
-
线程池大小:
•max_workers的值需要根据任务类型和系统资源合理设置。
• 对于 I/O 密集型任务(如网络请求、文件读写),可以设置较大的线程池大小。
• 对于 CPU 密集型任务,线程池大小通常不应超过 CPU 核心数。 -
异常处理:
• 如果某个任务抛出异常,线程池会继续执行其他任务,但异常不会自动传播到主线程。
• 可以通过捕获异常并记录日志来处理任务中的错误。 -
线程池的生命周期:
• 使用with语句可以确保线程池在任务完成后正确关闭。
• 如果不使用with语句,需要手动调用shutdown()方法关闭线程池。
程池结构,代码实现了高效的并发下载,大大提高了程序的性能。
总结
注意!!!
- 请勿将线程加太多,会对服务器造成影响。
- 本文只是用于讲解知识。
有不懂的老铁欢迎评论区留言。
本文仅用于学习交流,勿他用。
祝大家学习愉快 ☺️
python&爬虫逆向交流群:dzEzMDg3MDk4NTU5

















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









