







目录
1.首先Python 是一种高级编程语言
其语言特点为:
(1)简单易学:Python 的语法清晰简洁,采用缩进表示代码块,这使得代码易于阅读和理解
(2)可扩展性:可以使用 C、C++ 或其他语言编写的模块进行扩展,以提供更高的性能
(3)免费和开源:可以免费使用它,并且可以查看和修改其源代码
(4)跨平台:Python 可以在多种操作系统上运行,包括 Windows、Linux等
(5)丰富的类库:具有庞大的标准库和拓展库,可以处理各种工作、完成各种任务
(6)应用广泛:Python 被广泛应用于各种领域,包括网站开发、数据科学、人工智能、自动化脚本、科学计算等
(7)交互式解释器:Python 提供了交互式解释器,允许你边写代码边测试
(8)面向对象编程:Python 支持面向对象编程,包括类、对象、继承、封装和多态等概念。
print("Hello World!")2. Python基础语法
2.1 字面量
2.1.1六种数据类型
| 类型 | 描述 | 说明 |
| 数字(Number) | 整数(int)、浮点数(float)、复数(complex)、布尔(bool) | 整数:如:10、-10 浮点数即小数,例如:13.14 复数:如:4+3j,以j结尾表示复数 布尔:True表示真,False表示假。True本质上是一个数字记作1,False记作0 |
| 字符串(String) | 描述文本的一种数据类型 | 由任意数量的字符组成 |
| 列表(List) | 有序的可变序列 | Python中使用最频繁的数据类型,可有序记录一堆数据 |
| 元组(Tuple) | 有序的不可变序列 | 可有序记录一堆不可变的Python数据集合 |
| 集合(Set) | 无序 不重复集合 | 可无序记录一堆不重复的Python数据集合 |
| 字典(Dict) | 无序 Key-Value集合 | 可无序记录一堆Key-Value型的Python数据集合 |
常见的字面量类型:整数、浮点数、字符串等。
查看数据类型使用type()函数
2.1.2 类型转换
| 语句(函数) | 说明 |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象x转换为字符串 |
其中任何类型都可以转换成字符串
2.2 注释
注释是代码中的解释型语句,用来对代码内容进行注解注释不是代码,不会被程序执行。
2.2.1 单行注释:通过 #号定义,在#号右侧的所有内容均作为注释;建议在#号和注释内容之间,间隔一个空格;单行注释一般用于对一行或一小部分代码进行解释。
2.2.3 多行注释
通过一对三个引号来定义("""注释内容"""),引号内部均是注释,可以换行
多行注释一般对:Python文件、类或方法进行解释
2.3 标识符与关键字
2.3.1 标识符的命名规则
(1)只允许出现英文、中文、数字以及下划线(_)这四类元素,其余内容不允许
(2)标识符不能和Python中的保留字相同且大小写敏感
(3)第一个字符不能是数字!
2.3.2 关键字
保留字,又称关键字,指被程序语言内部定义并保留使用的标识符。
下表为python所有的保留字:

2.4 运算符

2.4.1算术运算符(如+, -, *, /, //, %, **)
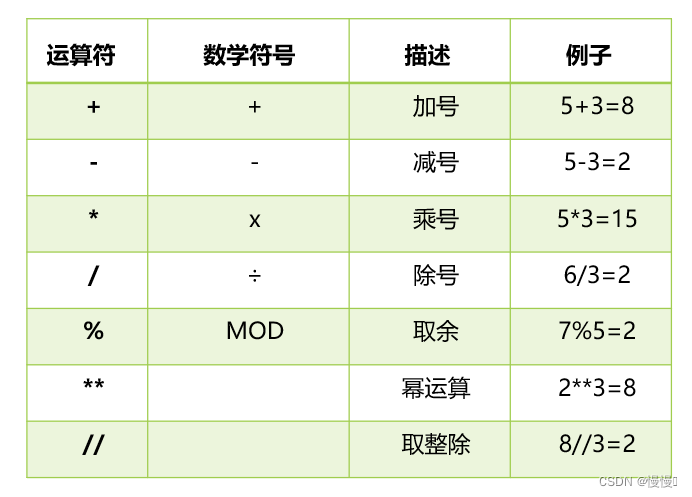
2.4.2比较运算符(如==, !=, >, <, >=, <=)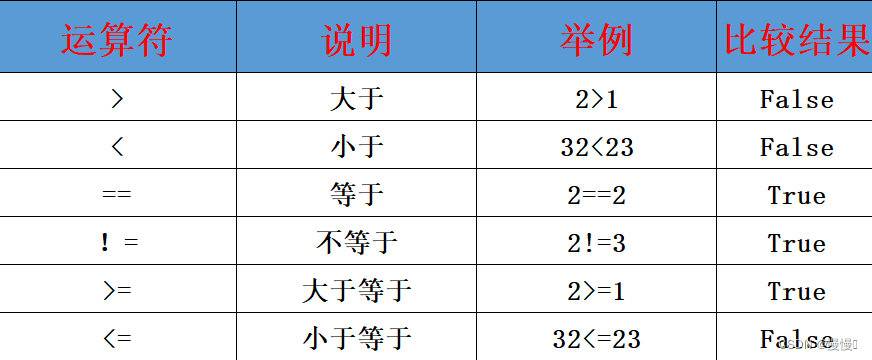
2.4.3 其他运算符
赋值运算符(如=)
复合运算符(如+=, -=, *=, /=等)
逻辑运算符(如and, or, not)
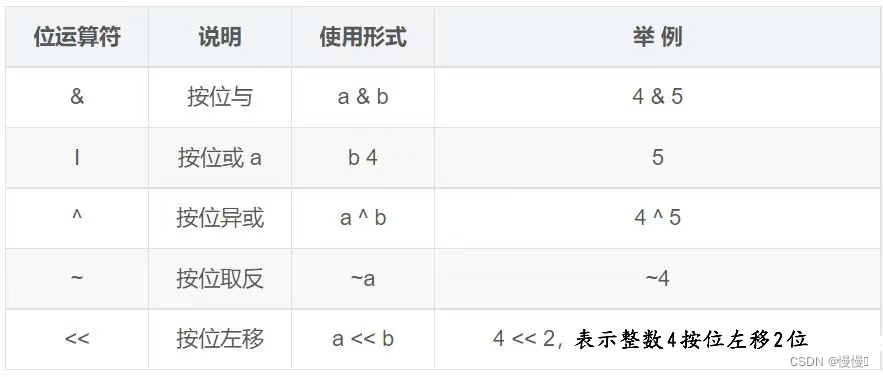
位运算符(如&, |, ^, ~, <<, >>)
2.5 字符串格式化精度
使用辅助符号"m.n"来控制数据的宽度和精度
(1)m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
(2).n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:
%5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
%5.2f:表示将宽度控制为5,将小数点精度设置为2
小数点和小数部分也算入宽度计算。如,对11.345设置了%7.2f后,结果是:[空格][空格111.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为.35
(3)如果m比数字本身宽度还小,则m不生效
n会对小数部分做精度限制,同时会对小数部分做四舍五入
2.5.2 快速格式化
(1).可以通过
f"{变量}{变量}”的方式进行快速格式化
(2).这种方式适合对精度没有要求的时候快速使用
原因:不理会类型、不做精度控制
2.6 表达式的格式化
(1)表达式是一个具有明确结果的代码语句,在变量定义的时候,如 age=11+11,等号右侧的就是表达式,也就是有具体的结果,将结果赋值给了等号左侧的变量
(2)表达式的格式化语法
f"{表达式}”
"%s\%d\%f" %(表达式、表达式、表达式)
2.7数据输入之input()语句
(1)input()语句的功能是,获取键盘输入的数据
(2)可以使用:input(提示信息)用以在使用者输入内容之前显示提示信息。
要注意,无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型
3.python判断语句
3.1布尔类型和比较运算符
布尔类型的字面量:True表示真(是、肯定) False表示假(否、否定)
定义变量存储布尔类型数据: 变量名称 = 布尔类型字面量
除了可以定义布尔类型外,还可以通过<比较运算符>计算得到布尔类型的结果
• ==判断是否相等,!=判断是否不相等
• >判断是否大于,<判断是否小于
• >=判断是否大于等于,<=判断是否小于等于
3.2 if 语句
(1)if语句的基本格式
if 要判断的条件:
条件成立时,要做的事情
(2)if语句的注意事项:
•判断条件的结果一定要是布尔类型
•不要忘记判断条件后的:冒号
•归属于if语句的代码块,需在前方填充4个空格缩进
3.3 if else组合判断语句

(1)if else 语句,其中
if和其代码块,条件满足时执行
else搭配if的判断条件,当不满足的时候执行
(2)if else语句的注意事项:
else不需要判断条件,当if的条件不满足时,else执行
else的代码块,同样要4个空格作为缩进
3.4 if _elif_else组合使用语句
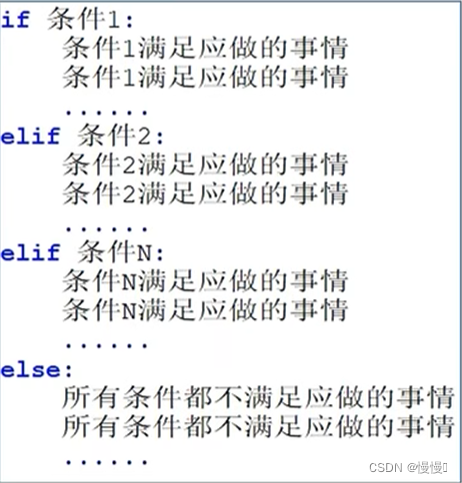
(1)该组合语句作用是可以完成多个条件的判断
(2)使用该语句注意:
•elif可以写多个
•判断是互斥且有序的,上一个满足后面的就不会判断了
•可以在条件判断中,直接写input语句,节省代码量
3.5 判断语句的嵌套

嵌套的关键点,在于:空格缩进
通过空格缩进,来决定语句之间的:层次关系
(2)注意:
•嵌套判断语句可以用于多条件、多层次的逻辑判断
•嵌套判断语句可以根据需求,自由组合if elif else来构建多层次判断
•嵌套判断语句,一定要注意空格缩进,Python通过空格缩进来决定层次关系
4.python循环语句
4.1 while循环

(1)while循环的注意事项
•条件需提供布尔类型结果,True继续,False停止
•空格缩进不能忘
•请规划好循环终止条件,否则将无限循环
4.1.2 while 循环的嵌套使用(循环内套循环)

(1)嵌套循环需要注意的地方:
•注意条件的控制,避免无限循环
•多层嵌套,主要空格缩进来确定层次关系
(2) 嵌套循环的使用难点:循环条件的控制,层次越多越复杂,需要细心+耐心
4.2 for 循环

(1)for循环的注意点:
无法定义循环条件,只能被动取出数据处理要注意,循环内的语句,需要有空格缩进
4.2.2 range语句(获得一个数字序列)
for 循环语句,本质上是:序列类型。
range(num1,num2,step)获取一个从num1开始,到num2结束的数字序列(不含num2本身)数字之间的步长以step为准(step默认为1)
例如,range(5,10,2)取得的数据是:[5,7,9]
4.2.3 for循环中的临时变量,
其作用域限定为:循环内
这种限定①是编程规范的限定,而非强制限定②不遵守也能正常运行,但是不建议这样做如需访问临时变量,可以预先在循环外定义它。
4.2.4 for循环的嵌套使用

与while循环嵌套使用相同,需注意缩进确定层次关系
4.3 break 和 continue
4.3.1 continue

continue关键字用于:中断本次循环,直接进入下一次循环(临时中断)
continue可以用于:for循环和while循环,效果一致
在上述代码中:在循环内,遇到continue就结束当次循环,进行下一次。所以,语句2是不会执行的。
continue应用场景:
在循环中,因某些原因,临时结束本次循环
4.3.2 break

break关键字用于:直接结束循环(永久终端)
break可以用于:for循环和while循环,效果一致
在上述代码中:在循环内,遇到break就结束循环了。所以,执行了语句1后,直接执行语句3了
4.3.3 注意事项
•continue和break,在for和while循环中作用一致
•在嵌套循环中,只能作用在所在的循环上,无法对上层循环起作用
5.数据容器
5.1 数据容器的定义
数据容器是一种可以容纳多份数据的数据类型,这些容纳的每一份数据称之为一个元素。Python中常见的数据容器包括:
- list(列表)
- tuple(元组)
- str(字符串)
- set(集合)
- dict(字典)
元素位置关系(有序/无序) 元素是否可以修改分类(可变/不可变) 字符串(str) 序列类型 有序 不可变类型 列表(list) 序列类型 有序 可变类型 元组(tuple) 序列类型 有序 不可变类型 集合(set) 集合类型 无序 可变类型 字典(dict) 映射类型 无序 可变类型
5.2 数据容器的分类和特点
5.2.1 列表(list)
(1)定义:使用方括号[]表示,元素之间用逗号,分隔。
(2)特点:可容纳多个元素
可容纳不同类型的元素
数据是有序存储的
允许重复数据存在
可进行增删查改
示例:my_list = [1, 2, 'a', 3.14, True]
5.2.2元组(tuple)
(1)定义:与列表类似,但使用圆括号()表示,且元组是不可变的(即不能修改其内容)。
(2)特点:可容纳多个元素、可容纳不同类型的元素、数据是有序存储、允许重复数据存在、不可变
示例:my_tuple = (1, 2, 'a', 3.14)
5.2.3字符串(str)
(1)定义:由一系列字符组成的不可变序列。
(2)特点:可容纳多个字符、数据是有序存储的、不可变
示例:my_string = 'Hello, World!'
5.2.4集合(set)
(1)定义:使用大括号{}或set()函数表示,集合中的元素是不重复的。
(2)特点:不含重复元素、无序存储、可进行集合运算(如并集、交集、差集等)
示例:my_set = {1, 2, 3, 4}
5.2.5字典(dict)
(1)定义:使用大括号{}表示,字典由键值对组成,键是唯一的,值可以是任意类型。
(2)特点:键是唯一的、数据无序存储、可进行增删查改
示例:my_dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
5.3数据容器的常用操作
5.3.1 列表(list)
(1)访问元素:
使用索引访问列表中的元素,索引从0开始。
示例:my_list[0] 访问列表的第一个元素。
(2)更新元素:
通过索引直接给元素赋值,即可更新元素。
示例:my_list[1] = 'b' 将列表的第二个元素更新为'b'。
(3)添加元素:
使用 append() 方法在列表末尾添加元素。
使用 insert() 方法在指定位置插入元素。
示例:my_list.append(4) 在列表末尾添加元素4;my_list.insert(2, 'c') 在索引为2的位置插入元素'c'。
(4)删除元素:
使用 del 语句删除指定位置的元素。
使用 pop() 方法删除并返回指定位置的元素(默认为最后一个)。
使用 remove() 方法根据值删除元素。
示例:del my_list[2] 删除索引为2的元素;my_list.pop() 删除并返回最后一个元素;my_list.remove('a') 删除值为'a'的元素。
(5)列表截取与拼接:
使用切片操作截取列表的一部分。
使用 + 操作符拼接两个列表。
示例:new_list = my_list[1:3] 截取索引1到2(不包括3)的元素;combined_list = my_list + another_list 将两个列表拼接起来。
(6)列表排序与反转:
使用 sort() 方法对列表进行排序(默认升序)。
使用 reverse() 方法反转列表。
示例:my_list.sort() 对列表进行排序;my_list.reverse() 反转列表。
5.3.2 元组(Tuple)
元组是不可变的,因此不能像列表那样进行添加、删除或修改元素的操作。
但可以执行索引、切片和遍历等操作。
5.3.3 字符串(String)
(1)字符串操作:
使用索引和切片访问字符串中的字符。
使用 replace() 方法替换字符串中的字符或子串。
使用 split() 方法将字符串拆分为列表。
使用 join() 方法将列表中的元素连接成字符串。
示例:new_string = my_string.replace('old', 'new') 替换字符串中的'old'为'new';word_list = my_string.split(' ') 将字符串按空格拆分为列表。
(2)字符串检查:
使用 startswith() 和 endswith() 方法检查字符串是否以指定前缀或后缀开始或结束。
使用 isalpha()、isdigit()、isspace() 等方法检查字符串是否全由字母、数字或空格组成。
5.3.4 集合(Set)
(1)创建集合:使用花括号 {} 或 set() 函数创建集合。
(2)集合操作:
使用 add() 方法添加元素。
使用 remove() 或 discard() 方法删除元素(如果元素不存在,discard() 不会引发异常)。
使用集合运算符(如 &、|、-)进行交集、并集、差集运算。
5.3.5 字典(Dictionary)
(1)创建字典:使用大括号 {} 或 dict() 函数创建字典。
(2)访问元素:使用键(key)访问字典中的值(value)。
(3)更新元素:通过键直接给值赋值,即可更新元素。
(4)删除元素:
使用 del 语句删除指定键的值。
使用 pop() 方法删除并返回指定键的值。
使用 clear() 方法删除字典中的所有键值对。
(5)遍历字典:
使用 items() 方法遍历字典中的所有键值对。
使用 keys() 方法遍历字典中的所有键。
使用 values() 方法遍历字典中的所有值。
6.函数
6.1 函数的定义
在Python中,你可以使用def关键字来定义一个函数。函数的定义包括函数名、参数列表和函数体。
def function_name(parameter1, parameter2, ...):
"""函数文档字符串(可选)"""
# 函数体
# 这里是函数执行的代码
return result # 返回结果(可选)6.2 函数的参数
- 位置参数:按照函数定义时的顺序传递参数。
- 默认参数:在函数定义时给参数指定默认值,调用函数时可以省略该参数。
- 关键字参数:在调用函数时,通过参数名来指定参数值,而不是按照位置。
- 可变位置参数(也称为非关键字参数):使用
*args来接收任意数量的位置参数,这些参数被组织成一个元组。 - 可变关键字参数:使用
**kwargs来接收任意数量的关键字参数,这些参数被组织成一个字典。
6.3 函数的返回值
- 函数可以使用
return语句来返回一个值或多个值(作为元组)。 - 如果函数没有
return语句或return后面没有跟任何值,那么函数将返回None。
6.4 函数的调用
调用函数就是执行函数体中的代码。你可以通过函数名加上括号(可能包含参数)来调用函数。
6.5 函数的文档字符串
在函数定义的第一行,你可以使用三引号(""")来定义函数的文档字符串(也称为docstring)。这个字符串用于解释函数的功能、参数和返回值等。
6.6 匿名函数(Lambda函数)
Python中的lambda关键字允许你定义简单的匿名函数。这些函数主要用于需要函数作为参数的场合。
lambda_func = lambda x, y: x + y
result = lambda_func(3, 4) # result 现在是 76.7 递归函数
递归函数是在函数体内部调用自身的函数。递归函数通常用于解决可以分解为更小、相似子问题的问题。
6.8 局部和全局变量
- 局部变量:在函数内部定义的变量是局部变量,它们只在函数内部可见。
- 全局变量:在函数外部定义的变量是全局变量,它们在整个程序中都是可见的。在函数内部,你可以使用
global关键字来声明一个变量是全局的。
6.9 函数的属性
函数也是对象,因此它们有属性。例如,你可以使用__name__和__doc__属性来获取函数的名称和文档字符串。
6.10 嵌套函数
你可以在一个函数内部定义另一个函数,这样的函数称为嵌套函数。嵌套函数可以访问其外部函数的局部变量(除了那些被标记为nonlocal的)。
7.文件操作
7.1打开文件
使用内置的open()函数来打开文件。该函数接受两个主要参数:文件名和模式。
file = open('filename.txt', 'r') # 打开文件以读取('r')
# 其他常用模式包括:'w'(写入,覆盖已有内容)、'a'(追加)、'x'(创建,如果文件已存在则报错)、'b'(二进制模式)
# 还可以组合模式,如 'rb'(二进制读取)7.2 文件模式
'r':读取(默认)'w':写入(会覆盖文件)'a':追加(在文件末尾添加内容)'x':创建(如果文件已存在则报错)'b':二进制模式(可以与其他模式组合,如'rb'或'wb')'+':更新(读取和写入,如'r+'、'w+'、'a+')
7.3 读取文件
一旦文件被打开,就可以使用各种方法来读取文件内容。
# 读取整个文件
contents = file.read()
# 读取指定数量的字节
contents = file.read(10)
# 逐行读取文件
for line in file:
print(line, end='') # 注意:默认每行末尾会有换行符,end='' 用于避免额外的换行
# 使用文件对象作为迭代器(等同于上面的逐行读取)
lines = file.readlines()7.4 写入文件
使用write()方法将数据写入文件。
# 将字符串写入文件
file.write('Hello, world!\n')
# 将数据转换为字符串并写入文件(如果数据不是字符串)
data = [1, 2, 3]
file.write(str(data) + '\n')7.5 关闭文件
使用close()方法关闭文件是一个好习惯,因为它会释放系统资源。
file.close()或者使用with语句,它可以自动关闭文件,即使在处理文件时发生异常。
with open('filename.txt', 'r') as file:
contents = file.read()
# 文件在这里会自动关闭7.6 文件位置
tell():返回文件当前位置(字节偏移量)seek(offset, whence=0):移动文件位置。offset是字节数,whence可以是0(文件开头)、1(当前位置)或2(文件末尾)
7.7 文件属性
name:返回文件的名称mode:返回文件被打开时的模式closed:如果文件被关闭,返回True
7.8 文件的编码
在读取或写入文本文件时,你可能需要指定文件的编码方式(如UTF-8、ASCII等)。这可以通过open()函数的encoding参数来完成。
file = open('filename.txt', 'r', encoding='utf-8')7.9 二进制文件操作
当以二进制模式(如'rb'或'wb')打开文件时,可以使用与文本模式相同的read()、write()等方法,但数据是以字节形式处理的。
7.10 错误处理
当处理文件时,可能会发生各种错误,如文件不存在、没有读取权限等。你可以使用try-except块来处理这些错误。
try:
file = open('filename.txt', 'r')
# ... 文件操作 ...
except FileNotFoundError:
print("文件不存在")
except PermissionError:
print("没有权限读取文件")
finally:
if 'file' in locals() and not file.closed:
file.close()8.异常处理、模块与包
8.1异常处理
异常处理是Python中用于处理运行时错误的一种机制。当Python代码在运行时遇到错误,它会抛出一个异常。如果没有适当的异常处理,程序通常会终止并显示一个错误信息。异常处理允许程序在发生错误时优雅地处理并继续执行,或者采取适当的补救措施。
关键点:
(1)try/except语句:用于捕获并处理异常。try块包含可能引发异常的代码,而except块则包含处理异常的代码。
try:
# 尝试执行的代码
x = 1 / 0
except ZeroDivisionError:
# 处理ZeroDivisionError异常的代码
print("除数不能为0")(2)多个except块:可以指定多个except块来处理不同类型的异常。
try:
# ...
except ZeroDivisionError:
# 处理除以零的代码
pass
except FileNotFoundError:
# 处理文件未找到的代码
pass(3)except语句不指定异常类型:如果except语句后面没有指定异常类型,它将捕获所有类型的异常。
try:
# ...
except:
# 处理所有类型异常的代码
pass但是,通常不推荐这样做,因为它会捕获所有异常,可能会隐藏一些难以调试的问题。
(4) else和finally块:else块在try块成功执行(即没有引发异常)后执行,而finally块无论是否发生异常都会执行。通常用于执行清理操作,如关闭文件或释放资源。
try:
# ...
except:
# ...
else:
# 仅在try块成功执行后执行
pass
finally:
# 无论是否发生异常都会执行
pass(5)引发异常:使用raise语句可以手动引发异常。这通常用于在检测到无法处理的错误时通知调用者。
if some_condition:
raise ValueError("无法处理的条件")(6)自定义异常:通过创建继承自Exception或其子类的类,可以定义自定义异常。
class MyCustomError(Exception):
pass
raise MyCustomError("发生了自定义异常")8.2 模块
模块是包含Python定义和语句的文件。模块可以定义函数、类和变量。模块也可以包含可执行的代码。Python使用模块来组织代码,使代码更易于理解和维护。
关键点:
(1)导入模块:使用import语句可以导入模块并使用其中的定义。
import math
print(math.sqrt(16)) # 输出:4.0(2)从模块中导入特定项:使用from ... import ...语句可以从模块中导入特定的函数、类或变量。
from math import sqrt
print(sqrt(16)) # 输出:4.0(3)模块搜索路径:Python解释器在导入模块时会搜索特定的路径。这些路径包括当前目录、PYTHONPATH环境变量中指定的目录以及标准库的安装目录。
(4)模块作用域:模块中定义的函数、类和变量默认具有模块作用域,即它们只能在模块内部访问。但是,可以使用global关键字在函数内部修改全局变量。
(5)模块的执行:当模块被导入时,Python会执行模块中的代码(如果有的话)。这通常用于初始化模块或定义全局变量和函数。但是,如果模块只包含函数、类和变量定义而没有可执行代码,则导入模块时不会执行任何操作。
(6)模块重用:模块允许程序员重用代码,而无需在每个新程序中重新编写相同的函数或类。这有助于提高代码的可维护性和可重用性。
8.3 包
包是包含多个模块的目录。包提供了一个命名空间来组织相关的模块。在Python中,包是通过在目录中包含一个特殊的__init__.py文件来识别的。
关键点:
目录结构:包通常具有层次结构,其中每个目录都包含一个__init__.py文件以及一个或多个模块文件(.py文件)。
导入包中的模块:使用点号(.)分隔的模块名可以导入包中的模块。例如,如果有一个名为mypackage的包,其中包含一个名为mymodule的模块,则可以使用以下语句导入该模块:`import mypackage.
9. python面向对象程序设计
9.1 类和对象
- 类(Class):类是对象的蓝图或模板,它定义了对象应有的属性和方法。
- 对象(Object):对象是类的实例,它根据类创建并具有类的所有属性和方法。
9.2 构造方法
构造方法(或称为初始化方法)在创建对象时自动调用,用于初始化对象的属性。在Python中,构造方法名为__init__。
class MyClass:
def __init__(self, value):
self.value = value
# 创建对象
obj = MyClass(10)
print(obj.value) # 输出: 109.3 封装
封装(Encapsulation)是隐藏对象的属性和实现细节,仅对外提供公共访问方式的过程。在Python中,可以通过定义私有属性和方法来实现封装。虽然Python中没有像Java或C++那样的显式私有访问修饰符(如private),但通常约定将属性名和方法名前加上一个下划线(_)来表示它们是“私有的”,并通过公共方法来访问和修改这些“私有”属性。
class MyClass:
def __init__(self, value):
self._value = value # 约定俗成的“私有”属性
def get_value(self):
return self._value
def set_value(self, new_value):
self._value = new_value
# 创建对象并访问属性
obj = MyClass(10)
print(obj.get_value()) # 输出: 10
obj.set_value(20)
print(obj.get_value()) # 输出: 209.4 继承
继承(Inheritance)是一种代码重用机制,它允许一个类(子类或派生类)继承另一个类(父类或基类)的属性和方法。在Python中,通过冒号(:)和基类的名称来实现继承。
class ParentClass:
def __init__(self):
self.parent_attr = "I'm from ParentClass"
def parent_method(self):
print("This is a method from ParentClass")
class ChildClass(ParentClass):
def __init__(self):
super().__init__() # 调用父类的构造方法
self.child_attr = "I'm from ChildClass"
def child_method(self):
print("This is a method from ChildClass")
# 创建子类对象并访问属性和方法
child_obj = ChildClass()
print(child_obj.parent_attr) # 输出: I'm from ParentClass
print(child_obj.child_attr) # 输出: I'm from ChildClass
child_obj.parent_method() # 输出: This is a method from ParentClass
child_obj.child_method() # 输出: This is a method from ChildClass在上面的例子中,ChildClass继承了ParentClass,因此它可以使用ParentClass的所有属性和方法。注意,在ChildClass的__init__方法中,我们调用了super().__init__()来确保父类的构造方法也被执行。这是因为在继承中,如果子类定义了__init__方法,而父类也定义了__init__方法,并且子类没有显式地调用父类的__init__方法,那么父类的__init__方法将不会被执行。

















 3609
3609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









