










基于YOLOv8深度学习的火焰烟雾检测系统
基于深度学习YOLOv8+Pyqt5的火焰烟雾检测识别系统(完整源码源文件+已标注的数据集+训练好的模型)
Python + PyQt5可视化界面
可对图片,视频,摄像头进行识别
下面将提供一个如何使用YOLO模型进行火焰和烟雾检测的指南,并附上示例代码。
项目概述
本项目旨在开发一个基于深度学习的火焰和烟雾检测系统,能够实时识别图像或视频流中的火焰和烟雾位置。
步骤
1. 环境配置
首先安装必要的依赖项。这里以YOLOv5为例。
pip install torch torchvision torchaudio opencv-python
git clone https://github.com/ultralytics/yolov5 # 克隆YOLOv5仓库
cd yolov5
pip install -r requirements.txt # 安装依赖
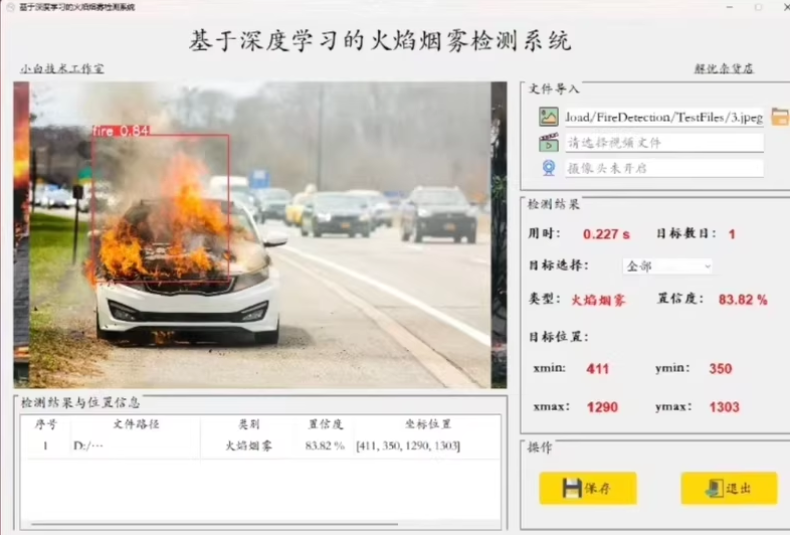
2. 数据准备
你需要收集并标注包含火焰和烟雾的图像数据集。每个图像应标记出火焰或烟雾的位置和类别标签。可以考虑使用公开的数据集或自行收集并标注。
创建一个YAML文件描述你的数据集路径和类别信息。例如data/fire_smoke.yaml:
train: ./data/images/train/
val: ./data/images/val/
nc: 2 # 类别数量:火焰、烟雾
names: ['fire', 'smoke']
3. 模型训练
根据你的数据集对YOLOv5模型进行训练。
# 使用YOLOv5s作为基础模型
python train.py --img 640 --batch 16 --epochs 100 --data fire_smoke.yaml --weights yolov5s.pt --cache
这行命令将启动训练流程,其中--img指定了输入图片尺寸,--batch是批量大小,--epochs是训练轮数,--data指向你的数据配置文件,--weights指定预训练权重。
4. 模型评估
训练完成后,可以使用以下命令对模型进行评估:
python val.py --weights runs/train/exp/weights/best.pt --data fire_smoke.yaml --img 640
5. 推理与部署
使用训练好的模型进行推理。以下是一个简单的Python脚本示例,用于加载模型并对单张图片进行预测:
import torch
from pathlib import Path
import cv2
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt') # 根据实际路径调整
def detect_fire_smoke(image_path):
img = cv2.imread(image_path)
results = model(img)
rendered_img = results.render() # 返回渲染后的图像列表
output_path = Path(image_path).parent / 'output.jpg'
cv2.imwrite(str(output_path), rendered_img[0])
print(f"结果已保存到 {output_path}")
if __name__ == "__main__":
image_path = 'path/to/your/test/image.jpg' # 替换为你的测试图像路径
detect_fire_smoke(image_path)

注意事项
- 上述代码片段是为了说明目的而简化了的示例。实际应用中可能需要根据具体情况调整。
- 虽然我们基于YOLOv5进行了示例,但当你真正使用YOLOv8时,请参考其官方文档进行相应的调整。
- 对于特定的应用场景,可能还需要对模型进行微调,以提高识别精度。
- 训练过程可能需要较大的计算资源,建议在具备GPU支持的环境中运行上述代码。
通过以上步骤,你可以构建一个基本的基于YOLO的火焰和烟雾检测系统


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









