










基于svm的python车牌识别代码 opencv车牌识别代码 有gui界面
机器学习车牌识别 数字图像处理,提供两个 GUI 界面
模型对汉字字符数据集预测准确率为98.08%,对字符数据集预测准确率为99.86%
核心代码均有注释 依赖库安装好后可直接运行
有讲解的PPT和 环境搭建教程,可以更好理解代码

以下文字及示例代码仅供参考!!
基于支持向量机(SVM)的车牌识别系统通常包含两个主要步骤:首先是车牌检测,其次是字符分割与识别。由于SVM特别适合分类任务,因此它常被用于车牌字符识别部分。下面是一个简化的实现示例,展示了如何使用Python结合OpenCV和SVM进行车牌识别。
步骤 1: 环境准备
首先确保安装了必要的库:
pip install opencv-python-headless numpy scikit-learn
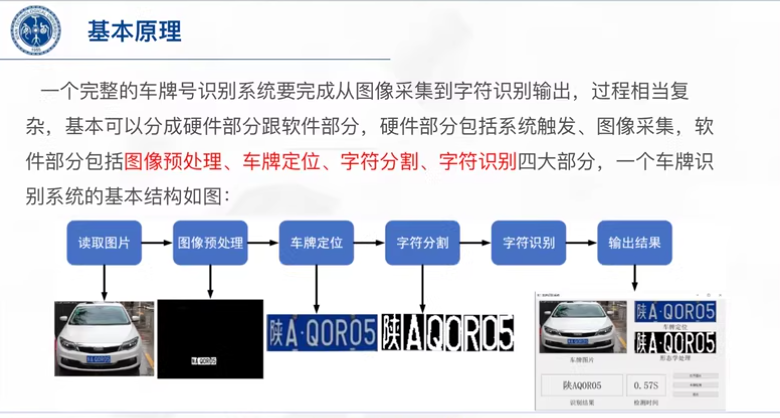
步骤 2: 车牌检测
这里我们采用一种简单的方法来检测车牌区域,实际应用中可能需要更复杂的算法或深度学习模型来提高准确性。
import cv2
import numpy as np
def detect_plate(img):
# 转为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用高斯模糊减少噪声
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edged = cv2.Canny(blur, 50, 150)
# 形态学操作,闭运算,连接组件
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 4))
closed = cv2.morphologyEx(edged, cv2.MORPH_CLOSE, kernel)
# 查找轮廓
contours, _ = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
aspect_ratio = w/h
if 3 < aspect_ratio < 6: # 假设车牌宽高比在3到6之间
return img[y:y+h, x:x+w]
return None
步骤 3: 字符分割与SVM训练
接下来是字符分割和训练一个SVM模型来识别这些字符。
训练SVM模型
首先,你需要一个数据集来训练你的SVM模型。这里假设你已经有了一个预处理过的字符图像数据集。
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import joblib
# 假设 X 是特征向量数组,y 是标签数组
# 这里只是一个示意,你需要根据实际情况准备数据
X, y = ...
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练SVM模型
clf = svm.SVC(gamma='scale')
clf.fit(X_train, y_train)
# 预测并评估模型
y_pred = clf.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred)}')
# 保存模型
joblib.dump(clf, 'svm_model.pkl')
字符分割与识别
然后,在检测到的车牌上进行字符分割,并使用训练好的SVM模型进行识别。
def segment_characters(plate_img):
# 将车牌图像转换为二值图像
_, binary = cv2.threshold(plate_img, 127, 255, cv2.THRESH_BINARY_INV)
# 查找轮廓
contours, _ = cv2.findContours(binary.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
sorted_contours = sorted(contours, key=lambda ctr: cv2.boundingRect(ctr)[0])
characters = []
for contour in sorted_contours:
x, y, w, h = cv2.boundingRect(contour)
if w/h > 0.3 and w/h < 3: # 简单筛选条件
character = plate_img[y:y+h, x:x+w]
characters.append(character)
return characters
# 加载模型
clf = joblib.load('svm_model.pkl')
# 示例车牌图像
img = cv2.imread('path_to_license_plate_image.jpg')
detected_plate = detect_plate(img)
characters = segment_characters(detected_plate)
# 对每个字符进行预测
for char in characters:
# 假设有一个函数 preprocess_char 来将字符图像转化为特征向量
feature_vector = preprocess_char(char)
prediction = clf.predict([feature_vector])
print(f'Predicted Character: {prediction[0]}')
上述代码片段提供了一个基本框架,具体实现细节如数据准备、字符预处理等需要根据实际情况进行调整和完善。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









