






随着《生成式人工智能服务管理暂行办法》正式实施,大模型上线备案成为企业合规运营的核心环节。其中,敏感词库建设与拦截关键词列表管理直接关系内容安全红线,今天我们就来详细解析一下大模型备案的这一部分,希望对想要做备案的朋友们能有所帮助。
一、备案制度背景及法律法规
法律框架
- 由《网络安全法》、《数据安全法》、《个人信息保护法》构成基础法律三角
- 网信办等七部门《生成式人工智能服务暂行办法》明确内容审核义务
- 《互联网信息服务深度合成管理规定》细化算法备案要求
备案核心目标
- 防范生成暴力、恐怖、歧视等违法内容
- 保护用户隐私与知识产权
- 维护意识形态安全与社会稳定
二、敏感词库的构建内容
大模型的敏感词库通常涉及以下内容:
- 暴力恐怖类:如 “*害”“爆*”“恐怖袭击” 等描述暴力行为或恐怖场景的词汇。
- 色情低俗类:包括 色情图片、链接、描述文字露骨的情色描写语句、“低俗” 等相关词汇。
- 毒品违法类:各种毒品名称及其变体形式,如 “海*因”“*麻”“摇头丸” 等。
- 网络欺凌类:辱骂攻击他人的侮辱性词汇,以及恶意传播谣言的行为特征表述相关词汇。
- 不良诱导类:过度消费引导词汇;早恋鼓吹言论;厌学辍学煽动言辞 等。
- 政治敏感类:反政府组织活动线索提示字眼,如 “颠覆政权”“分裂国家”“煽动叛乱” 等,以及涉及敏感政治事件、人物或话题的词汇。
- 宗教极端主义类:与宗教极端组织、极端思想传播相关的词汇,以及宣扬宗教极端主义的内容。
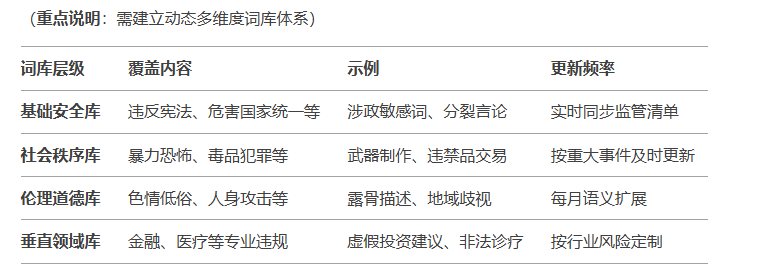
三、拦截关键词机制的技术要求
动态对抗策略
- 谐音/拼音识别:如"VX""薇❤"等变体拦截
- 上下文关联分析:"价格跳水"结合"股票推荐"触发预警
- 多模态内容筛查:图文组合规避检测的情况处理
分级拦截体系
- 一级拦截:直接屏蔽并记录日志(如涉恐内容)
- 二级拦截:内容替换+人工复核(如部分低俗用语)
- 三级拦截:风险提示+用户确认(如涉及反政活动)
合规性验证
- 每月压力测试:模拟10万+违规请求检验拦截率
- 误伤率控制:正常内容误拦率需低于0.1%
- 日志留存:完整记录处理记录备查,保存期≥6个月
四、企业备案实操要点
材料申报重点
- 取得ICP经营许可证
- 提交词库分类逻辑说明文档
- 提供近三个月拦截数据统计
- 附算法模型训练数据合规证明
持续合规管理
- 每季度更新词库并提交变更说明
- 重大节日/事件期间启动强化过滤模式
- 建立用户举报-复核-反馈闭环机制
大模型备案不是简单的技术适配,而是AI企业践行科技向善的必经之路。随着《人工智能示范法(专家建议稿)》等新规酝酿,建议企业提早做备案,早日抵达安全合规范围。

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









