




前提准备工作
1、确保你已经安装了 Python
LangChain 需要 Python 3.8 或更高版本。你可以通过以下命令检查你的 Python 版本:
python --version2、使用 pip 安装 LangChain
通过以下命令安装 LangChain:
pip install langchain
pip install langchain-openai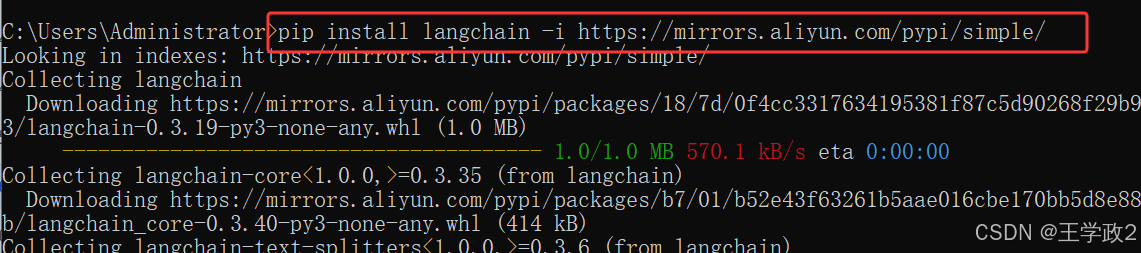

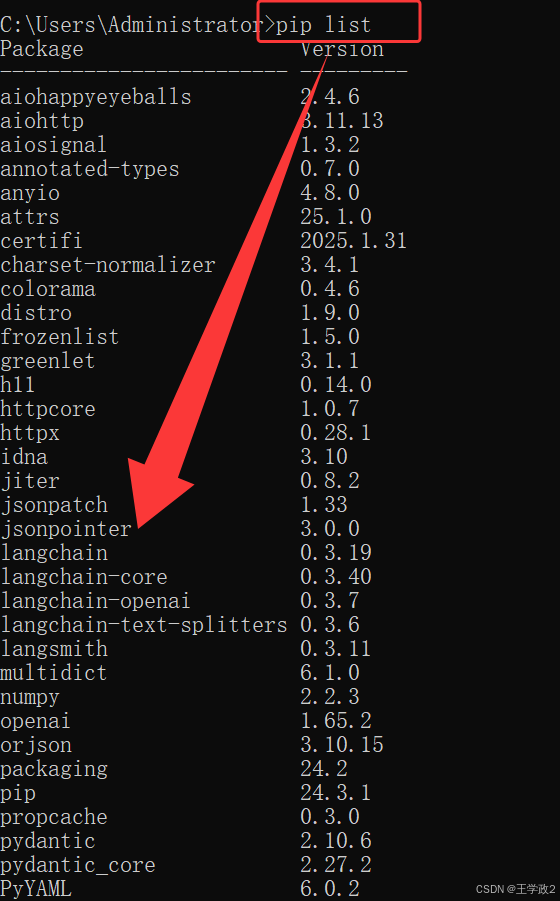
3、使用pip list 命令查询
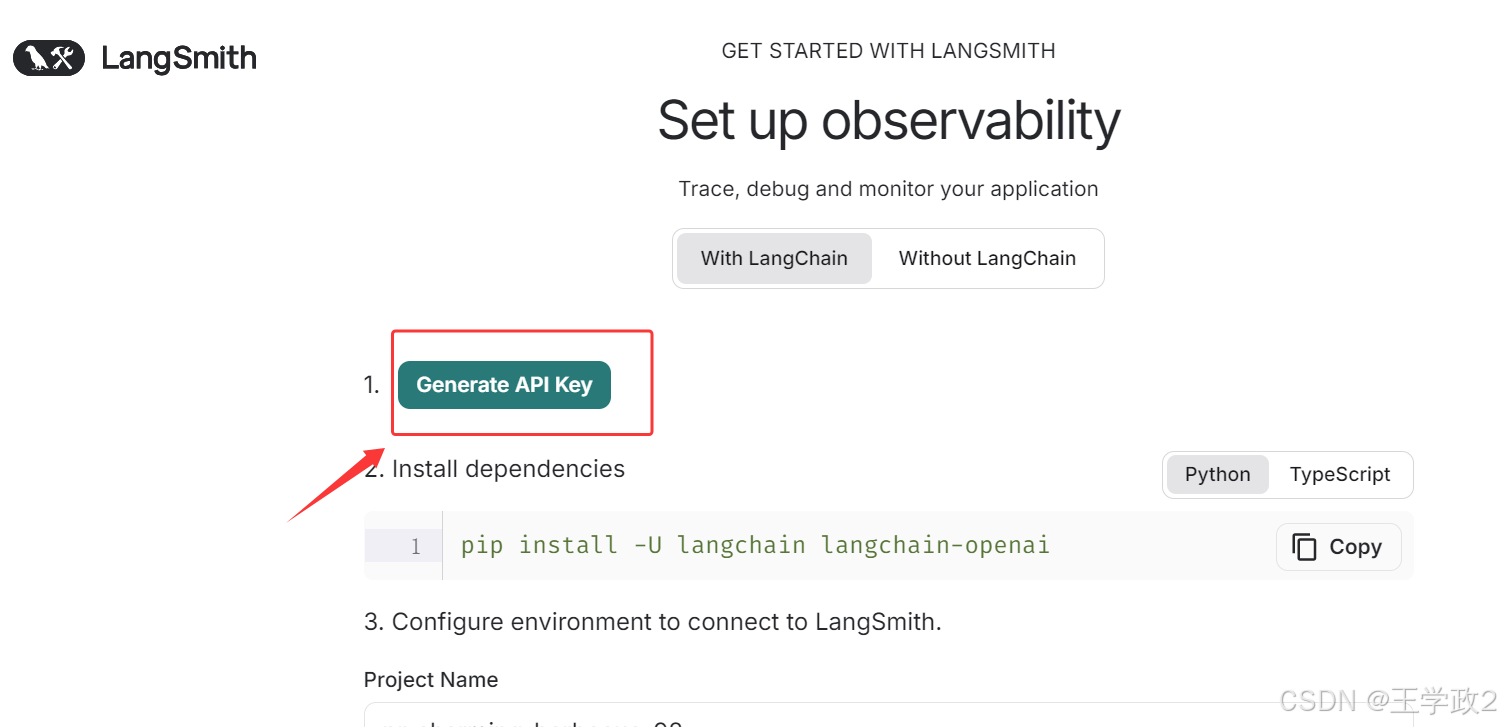
4、创建 LangSmith API Key
官网:
开始LangChain框架的使用
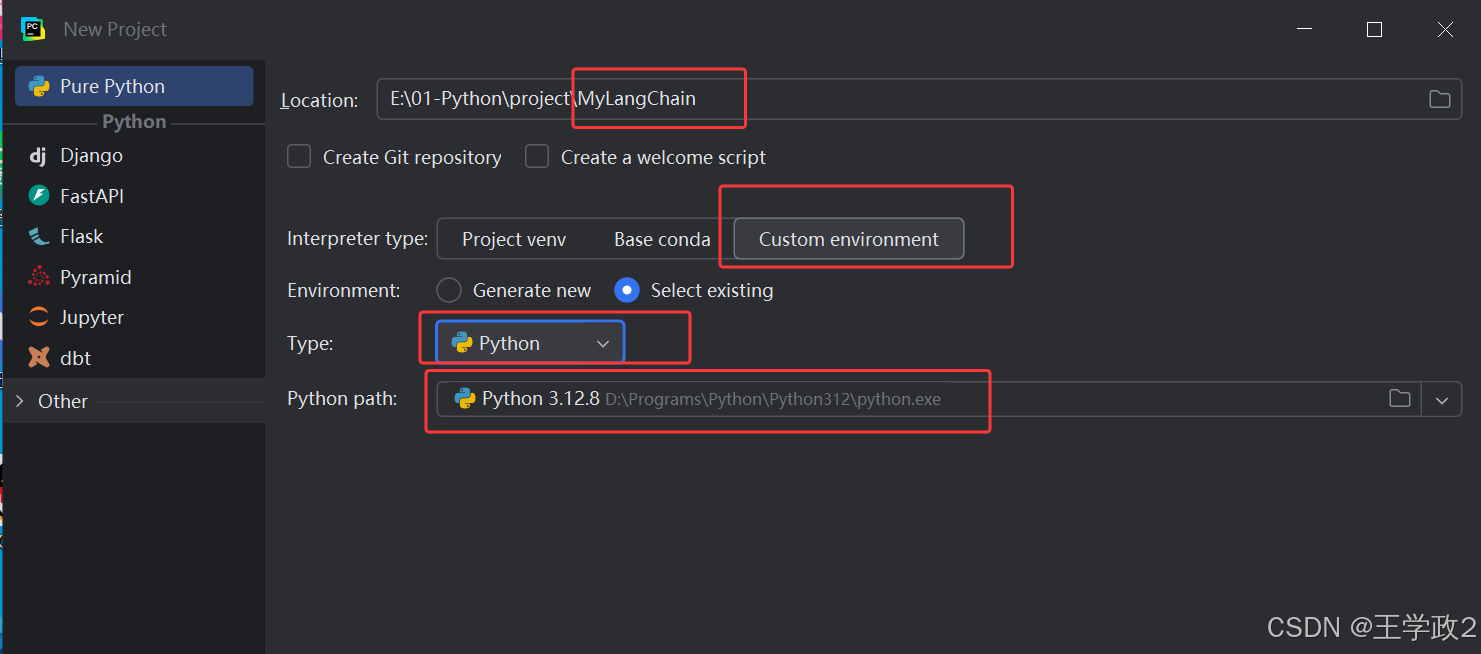
1、打开PyCharm创建MyLangChain项目
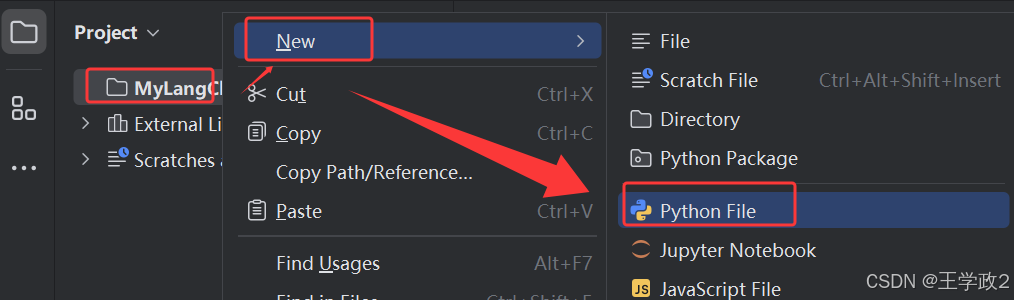
2、在项目上新建Demo1.py
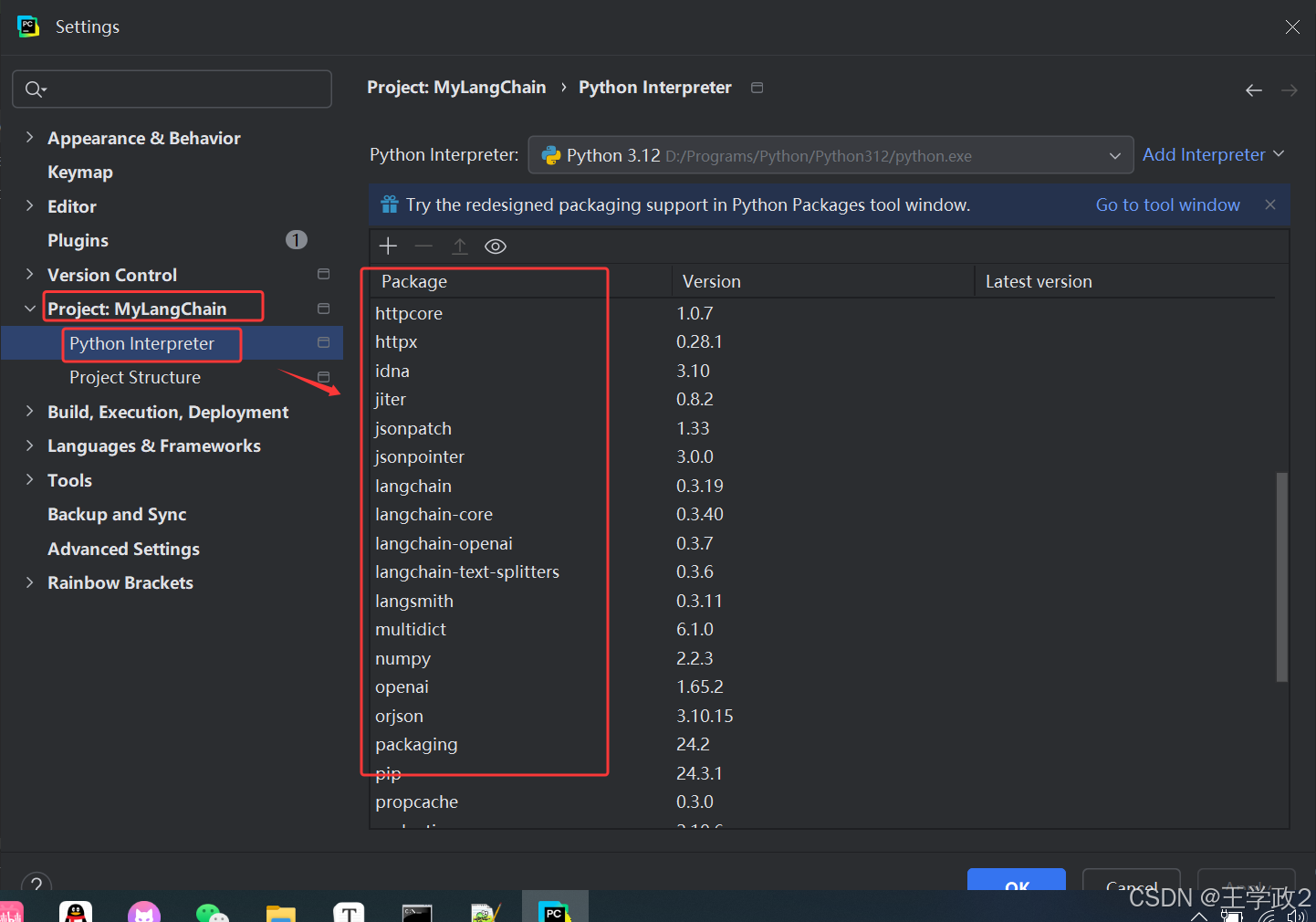
3、在PyCharm中查看依赖的第三方库
File --> settings--->
4、编写LangChain代码
创建一个简单的大模型应用示例
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
os.environ['http_proxy'] = '127.0.0.1:7897'
os.environ['https_proxy'] = '127.0.0.1:7897'
# 连接langchain
os.environ['LANGCHAIN_TRACING_V2'] = 'TRUE'
os.environ['LANGCHAIN_PROJECT'] = 'MyLangChain'
os.environ['LANGCHAIN_API_KEY'] = 'lsv2_xxxxx'
# 创建模型
model = ChatOpenAI(model = 'gpt-4-turbo')
# model = ChatOpenAI(model = 'gpt-3.5-turbo')
# 准备提示prompt
msg = [
SystemMessage(content="请将以下内容翻译成中文"),
HumanMessage(content="Hello World!")
]
result = model.invoke(msg)
print(result)注意:
将 os.environ['LANGCHAIN_API_KEY'] = 'lsv2_xxxxx' 这行代码中的Key换成自己的。
5、运行代码
如果不出所料的化代码的运行结果会报错
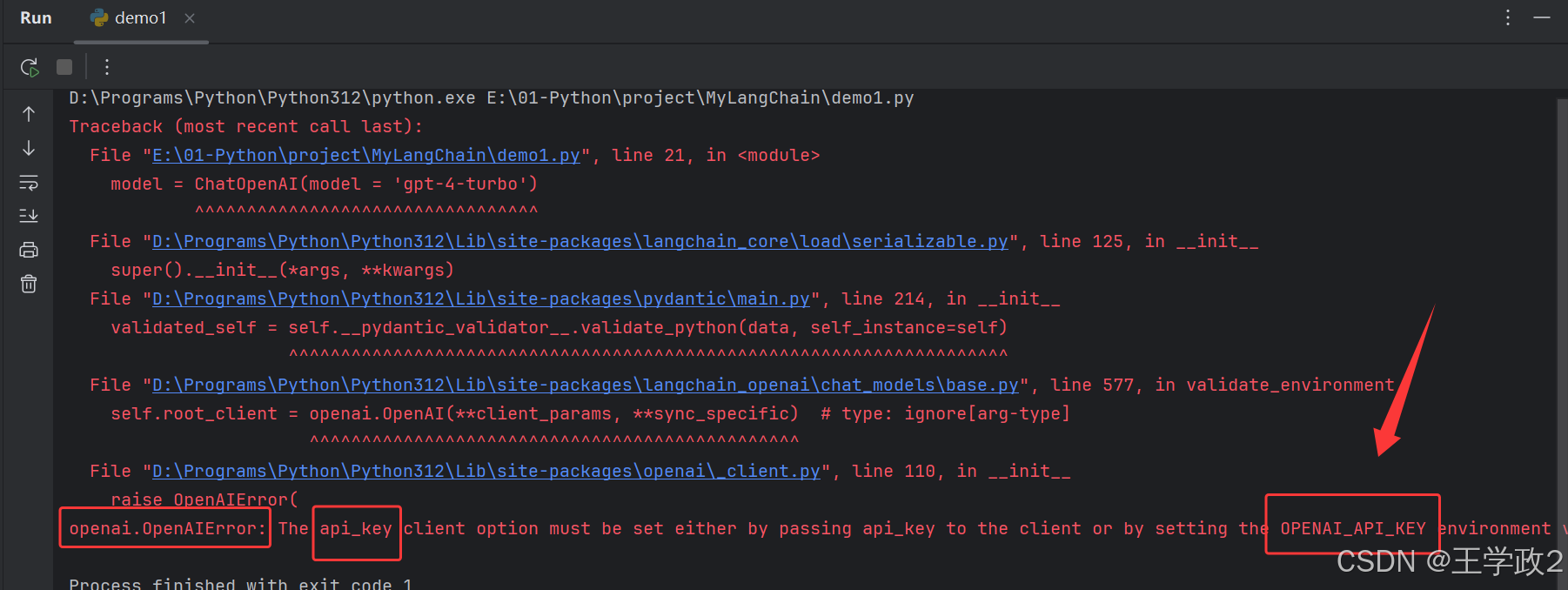
根据错误提示信息来看,是缺少了OpenAI的Key。
6、此时某宝上购买一个key先用着
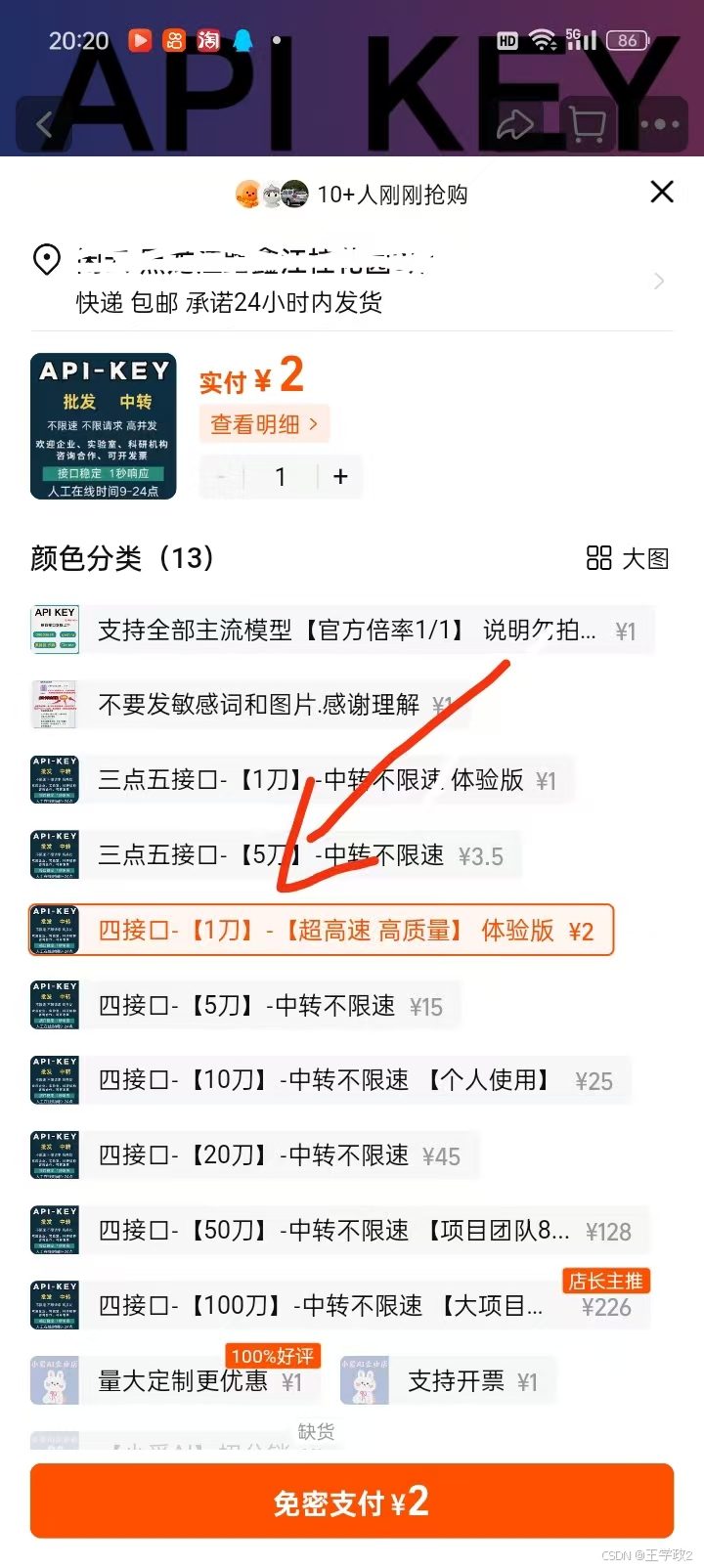
注意:选择 四接口(GPT-4)
7、阅读第三方中转服务的文档 
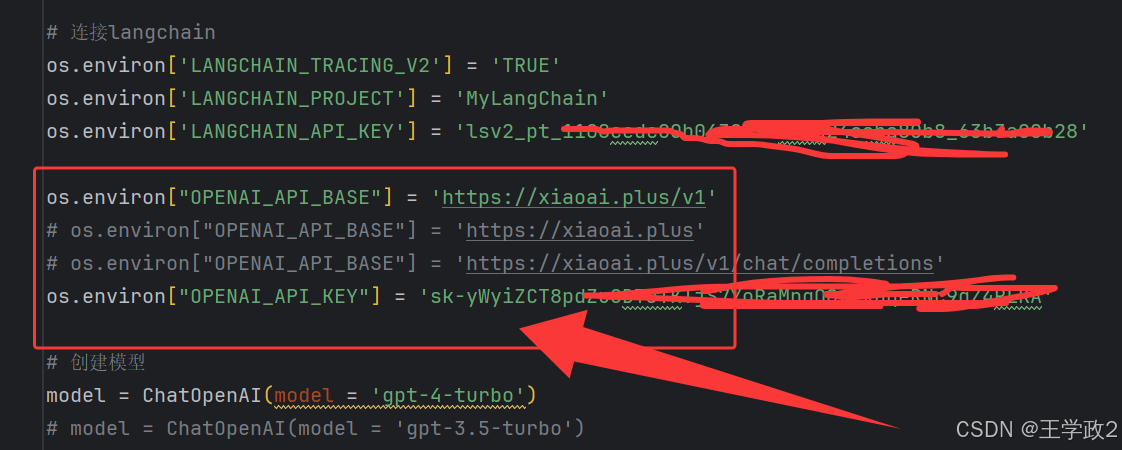
os.environ["OPENAI_API_BASE"] = 'https://xiaoai.plus/v1'
os.environ["OPENAI_API_KEY"] = 'sk-xxxx'
以上是LangChain的配置
API请求接口:
https://xiaoai.plus/
https://xiaoai.plus/v1
https://xiaoai.plus/v1/chat/completions
这三个接口地址都可以,调不通的话挨个试!
修改之后的代码
8、再次运行代码
还是报异常:openai.APIConnectionError: Connection error
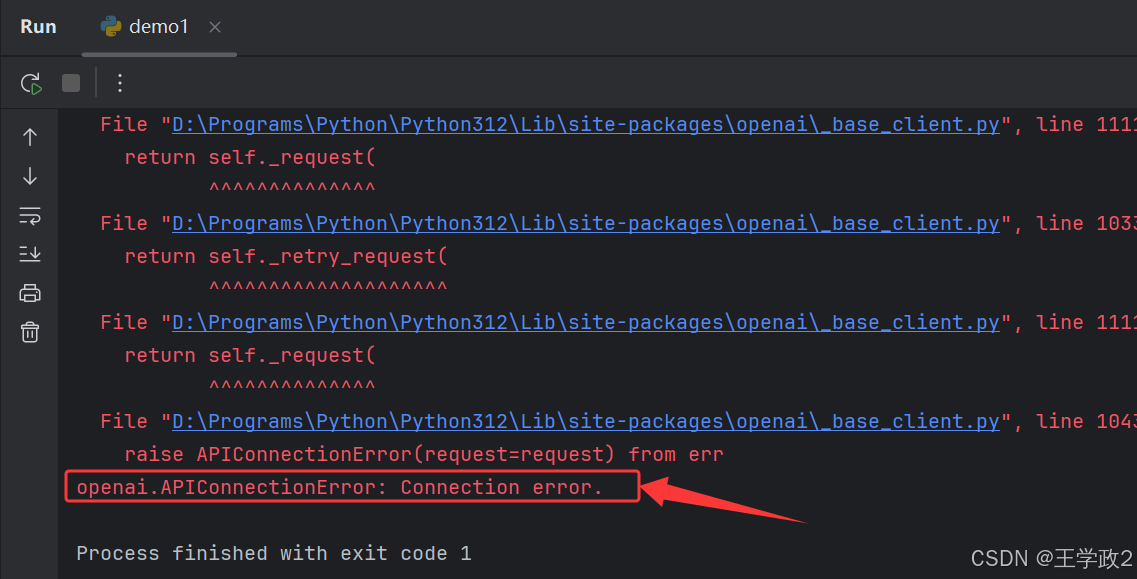
通过异常信息我们分析出是OpenAI连接失败了!
这里需要访问境外网站,OpenAI国内访问不了,所以需要安装V P N
9、安装V PN
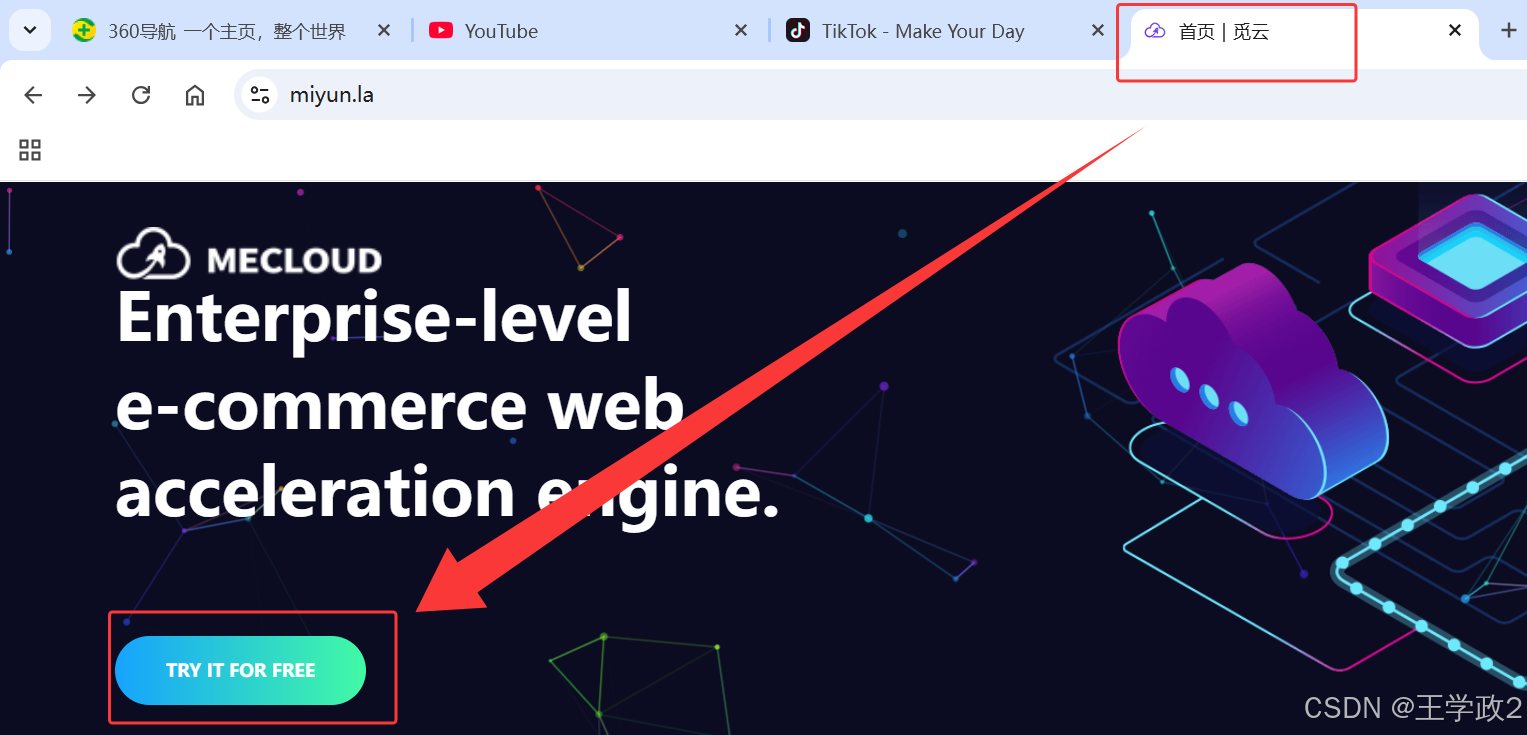
访问 MECLOUD 网站并注册账号!
站点有详细的帮助文档 选择 windows 的帮助文档

 购买完成之后安装 Clash
购买完成之后安装 Clash
软件安装完成之后依次按照官网的帮助文档中的操作步骤来就行!
10、再次运行代码
打印输出结果:
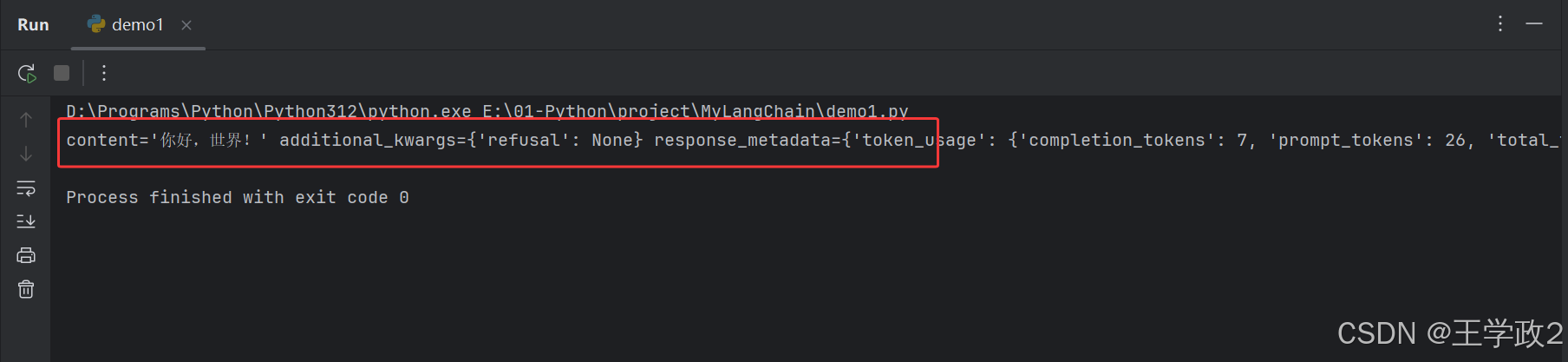
大功告成了,至此我的第一个使用LangChain框架调用大模型接口成功了!

















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









