







进入创业直播的第五章,我们即将面对项目中最硬核的挑战——对话记录与聊天界面。
在第三章中,我们曾提出一道思考题:考虑到对话须分为“本人-他人分身”、“他人-我方分身”、“我方分身-他人分身”,要如何设计出简洁明确且符合直觉的对话记录界面?
| 双主体下的对话记录界面
互联网时代的社交模式始终遵循单一维度,“真人-真人”的简单逻辑也让对话记录界面直观易懂、毫无上手难度。但在引入“分身”这个第二主体后,整个界面的设计思路也随之彻底转变。
我们当然不可能粗暴按“本人-他人分身”、“他人-我方分身”和“我方分身-他人分身”的形式进行分类,这不仅会大大增加对话条目的检索难度、还会产生来自“同一对象”的内容被刻意撕裂的感觉。
换言之,最终方案必然要呈现出嵌套结构,宏观上遵循一种分类关系,但细节条目又嵌套其他逻辑。出于依托主体(或者叫「起点」)的思路,我首先尝试了“本人”、“分身”和“陌生人”的三分设计。
(1)本人:涵盖用户本人亲自参与的全部对话,外加已添加为好友的他人与我方分身的聊天概况(以特殊颜色的字体显示以明确区分,点击可显示概况细节)。
(2)分身:列出分身在自由探索期间(类似〈旅行青蛙〉)与他人分身间的对话概况,帮助用户快速了解双方交流的话题统一度、观点契合度与性格匹配度。
(3)陌生人:非好友用户与我方分身间的对话概况,同样包含话题、观点与性格等几项总结性指标。
看起来还挺有道理……对吧?
| 错!关于界面布局的隐形陷阱
这样的分类方式是典型的“工程师中心”视角,对开发者来说简单易行,但却埋下了几个不易察觉的陷阱。
(1)对话内容拆分问题:我方分身在探索期间偶遇(我方分身-他人分身)的他人一旦也曾与我方分身主动聊天(他人-我方分身),则对话内容将被强制拆分在“分身”与“陌生人”两栏之下。于是,双边保持条目内容一致则有重复冗余之感;双边不一致则撕裂了与同一对象的对话结果。
(2)首页排布过于拥挤:这样的对话记录界面三分,意味着“随机探索”功能必须新开页面实现,会导致首页排布过于拥挤。
如果额外添加“随机探索”栏,会导致首页下方图标过于拥挤。
| 对话与探索融合:更精简的设计方式
综合考量之后,最新解决方案如下:
1. “本人”栏:由本人参与的对话细节,以及好友发来的消息概况。
2. “分身”栏:由分身参与的非好友消息概况。
3. “随机探索”栏:可查看行动日志,支持点击跳转至“分身”栏下的相应概况条目。探索栏内通过功能按钮提供随机探索喜好和设置,如愿意接受怎样的门票价格、偏好哪类环境/氛围/人群等。
新对话提醒“红点”🔴分两种颜色,蓝色代表他人真人参与,紫色代表他人分身参与(二者皆有显示为蓝色)。全部消息均按时间排序。

参考“EIDGO心我”logo,用蓝色与紫色区分消息来源。
通过这种方式,我们更自然地将三种对话情境纳入两种分类,也给“随机探索”保留了易于操作的摆放位置。
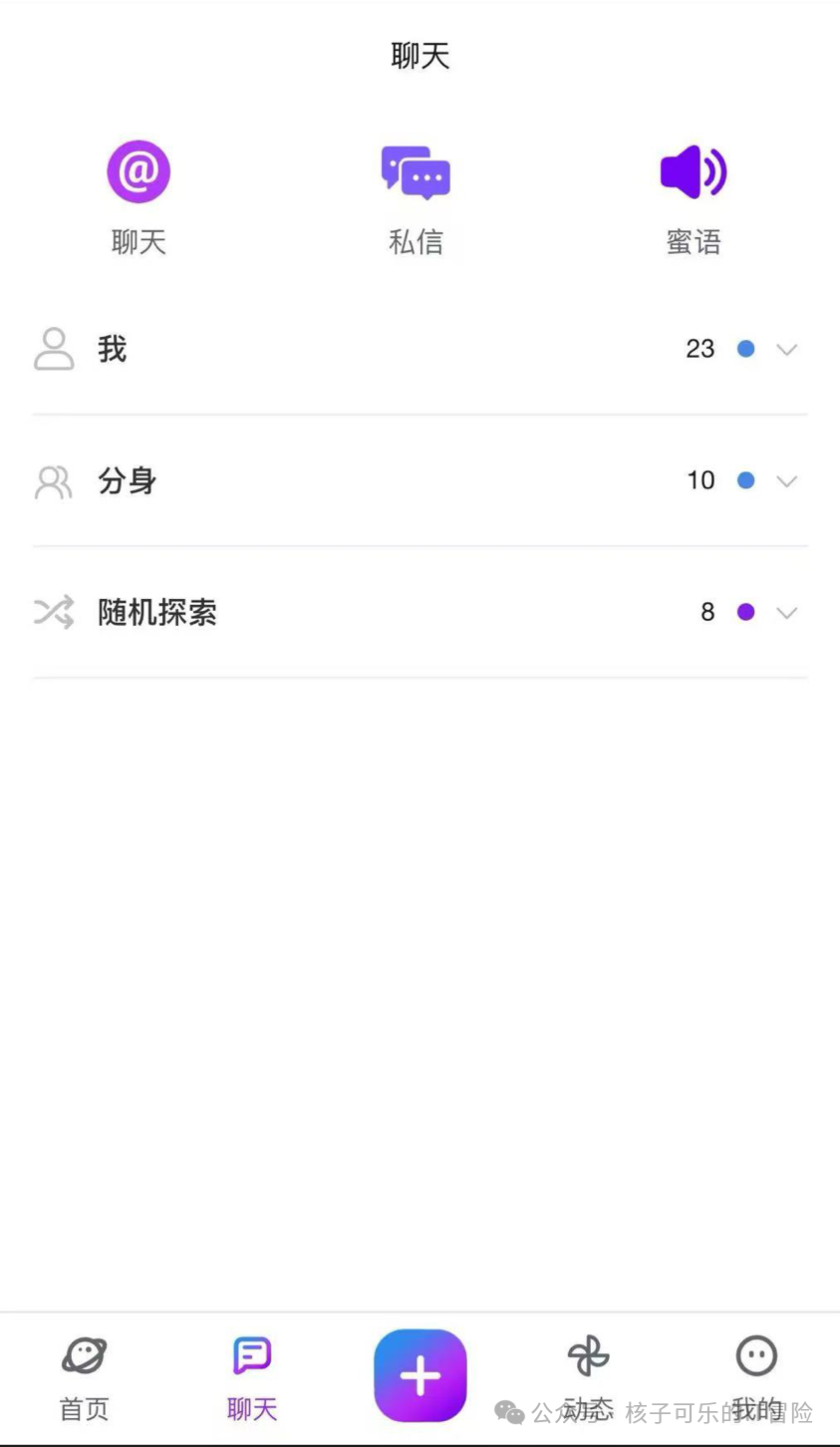
初版聊天页布局,设计老师没有理解“随机探索”需要拥有独立的界面,且下拉折叠式的排列方式会干扰上下滚动操作。
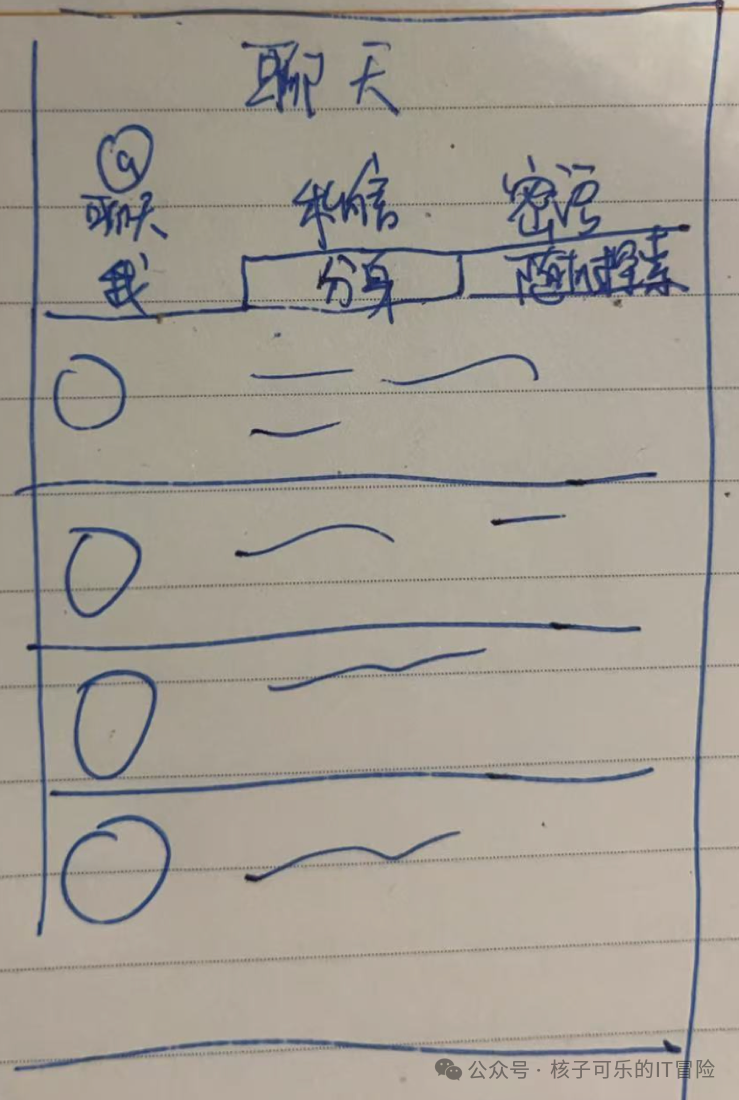
调整后以选项卡形式做区分,避免操作干扰的同时尽可能还原传统社交软件的使用感受。
| 私信与密语
在对话记录页面中,除了最常规的聊天一级目录外,还有私信和密语两个与之并列的分类。
私信 :由于“EIDGO心我”不允许用户真人间直接对话,因此除了好友申请之外,用户间就只能通过私信进行简单沟通。同样遵循B站的设计思路,在对方未回复的情况下,陌生人只能向他人发出最多3条私信,借此避免过度打扰。
密语 :即自由聊天模式,交流对象为好友和我们自己的分身。我们可以在这里随意交流,对话内容既不会生成概况,也不会被写入记忆库(因此不会对好友关系和自己的分身产生实际影响)。在未来的更新中,项目还考虑引入“时光机”功能,通过挂载不同时间点之前的记忆信息让用户与过去的自己或好友畅聊。
作为创业直播的第五章,我们终于完成了对话记录界面的初步设计,同时将“随机探索”功能也顺畅自然地融入其中。
欢迎大家与我一道见证这段经历,也期待评论区中的质疑拷打。在下周的更新中,我们聊聊怎样在成熟的社交对话框架内添加更多符合“EIDGO心我”特性的设计细节。第二段宣传片届时也将一同公布,敬请期待!

















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









