






【独家破解】AI黑科技横扫Nature封面!人类飞行员竟被无人机吊打?(附9套前沿源码)
最近科研圈炸出一颗王炸!Nature最新封面惊现逆天操作——无人机赛道竟被AI血洗!瑞士团队开发的Swift系统直接碾压人类世界冠军,创下历史最快圈速!
这波操作背后藏着两大"外挂":卡尔曼滤波+强化学习的究极缝合术!前者像开了天眼般精准预测环境,后者通过疯狂试错练就绝杀策略。当状态预判遇到决策优化,直接催生自动驾驶、机械臂控制等领域的核爆级突破!
想要提前解锁:
✅ 卡尔曼滤波的"上帝视角"调参秘笈
✅ 强化学习的百万级试错训练框架
✅ 两大神技的22种融合姿势
✅ 可直接魔改的Python/Matlab源码
立即扫码上车!错过这波可能要等Nature下个百年特刊了!有需要的同学 工棕号【AI因斯坦】回复 “9强化卡尔曼” 即可领取。
Champion-level drone racing using deep reinforcement learning
文章解析
文章介绍了一个名为Swift的自主无人机系统,它结合了深度强化学习和物理世界中收集的数据,能够在第一人称视角无人机比赛中达到甚至超越人类世界冠军的水平。Swift由感知系统和控制策略组成,通过模拟训练并在现实世界中微调,成功地在与三位人类冠军的直接比赛中多次获胜,并记录了最快的比赛时间。
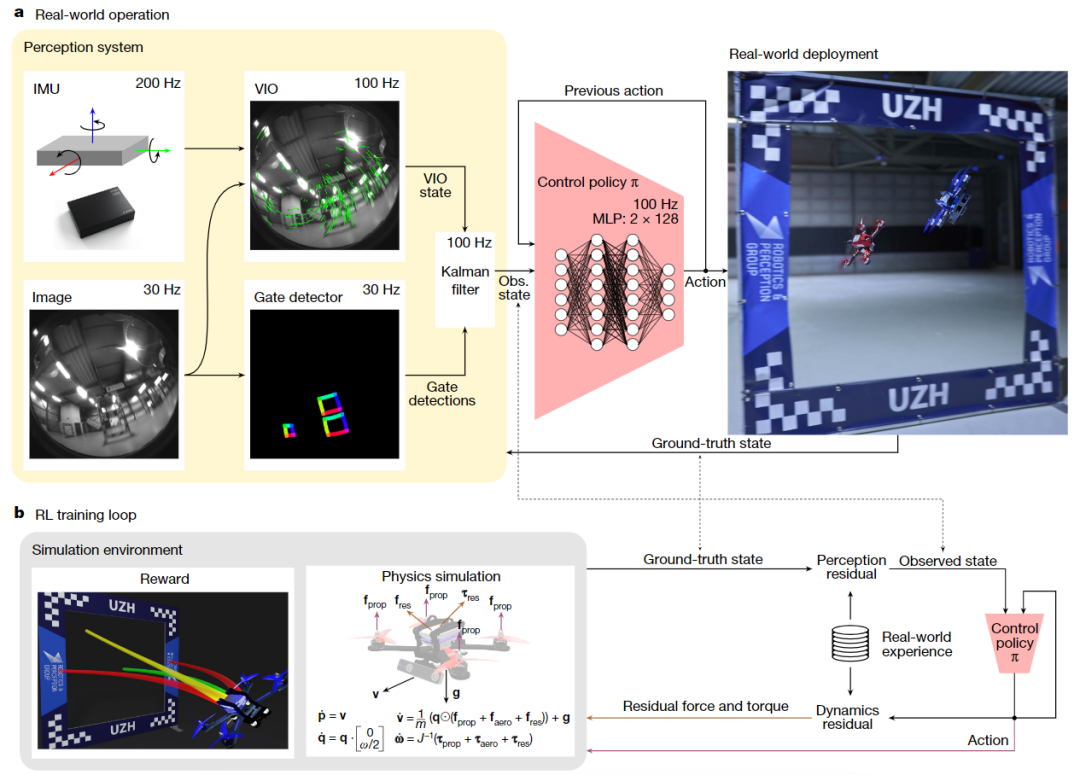
创新点:
1. 仿真到现实的高效迁移:通过深度强化学习在仿真环境中预训练,并利用真实物理数据微调,解决了自主无人机从虚拟到现实场景的迁移难题。
2. 模块化系统设计:提出分层的感知系统(状态估计)与控制策略(动作生成)协同架构,增强复杂动态环境下的实时决策能力。
3.超越人类冠军的性能:首次实现自主无人机在竞速任务中击败人类世界冠军,验证了算法在高速、高精度控制任务中的实用性。
Multi-AGV Path Planning Method via Reinforcement Learning and Particle Filters
文章解析
文章提出了一种名为粒子滤波-双深度Q网络(PF-DDQN)的多自动引导车(AGV)路径规划方法,该方法结合了粒子滤波(PF)和强化学习(RL)算法,通过利用PF处理网络权重的不精确性,并优化DDQN模型以获得最优的真实权重值,提高了算法的优化效率和收敛速度。
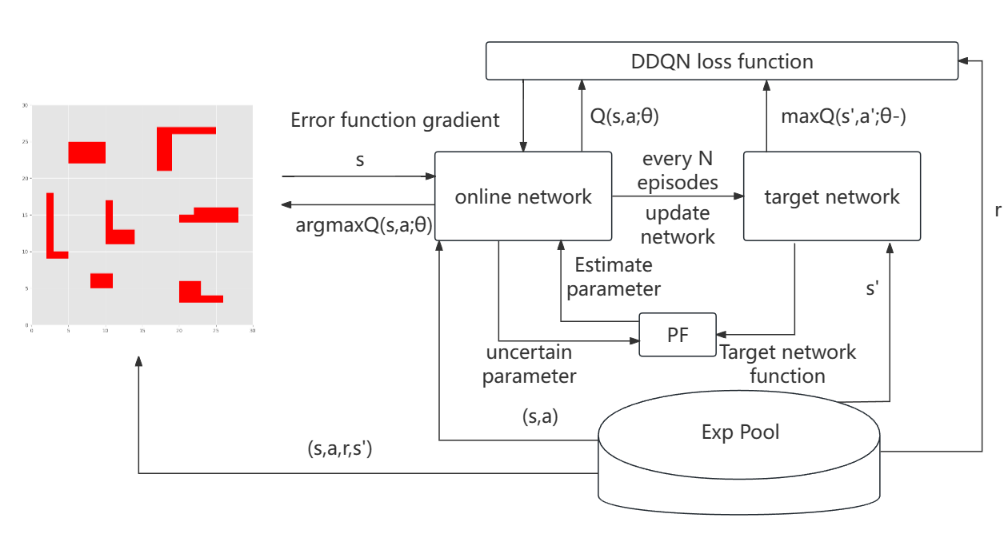
创新点:
1. 粒子滤波与强化学习的融合:引入粒子滤波(PF)处理深度Q网络(DDQN)权重的不确定性,提升多AGV路径规划模型的鲁棒性。
2.动态权重优化机制:通过PF迭代修正网络参数的真实权重值,加速算法收敛并提高规划效率。
3.复杂场景适应性:在多AGV协同避障与路径冲突场景中,实现高维度动态环境下的实时路径规划优化。
Fast Value Tracking for Deep Reinforcement Learning
文章解析
文章介绍了一种名为LKTD的新型深度强化学习算法,该算法基于Kalman滤波范式,通过结合随机梯度马尔可夫链蒙特卡洛(SGMCMC)方法,有效地从深度神经网络参数的后验分布中抽取样本。LKTD算法在保持计算效率的同时,能够量化与价值函数和模型参数相关的不确定性,并在训练过程中监控这些不确定性。
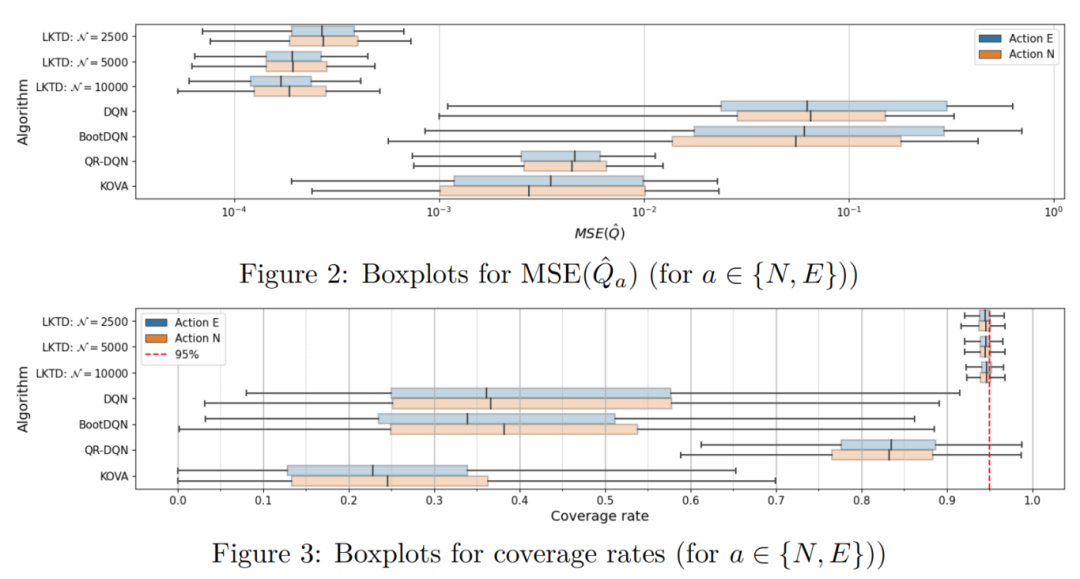
创新点:
1.卡尔曼滤波范式创新:基于卡尔曼滤波理论框架,结合SGMCMC方法,实现深度神经网络参数后验分布的高效采样。
2.动态不确定性量化:首次在深度强化学习中实时监测价值函数与模型参数的不确定性,增强训练过程的可解释性。
3.轻量化计算设计:在保持与传统DRL算法相当计算效率的前提下,引入不确定性建模能力,避免复杂后验分析的计算负担。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









