






「ChatGPT和Midjourney已经过时了?2023年AI领域最火的技术,竟是强化学习与扩散模型的“联姻”!谷歌用它在1小时内教会机器人叠衣服,OpenAI靠它解决了AI道德难题——这个颠覆性组合到底强在哪?」
核心内容:
1.技术解读
扩散模型:从“生成图片”到“生成动作”
强化学习:从“试错学习”到“精准决策”
关键公式:
𝑎𝑡=Denoise(𝑠𝑡,𝜖𝜃)+RLPolicy(𝑠𝑡)at=Denoise(st,ϵθ)+RLPolicy(st)
2.五大应用场景
机器人控制:让机械臂像人类一样“思考”动作序列
游戏AI:打败人类玩家的下一代AlphaGo
自动驾驶:用扩散模型预测极端路况
内容生成:符合道德规范的AI绘画神器
医疗决策:个性化治疗方案的扩散式推理
谷歌科学家:“这是让AI从‘模仿’进化到‘创造’的关键一步。”OpenAI技术负责人:“RL+扩散模型将解决大模型的价值观对齐问题。”
我们整理了包含8篇“强化学习+扩散模型”论文合集,工棕号【AI因斯坦】回复 “8扩散模型” 即可领取。
Planning with Diffusion for Flexible Behavior Synthesis
文章解析
传统基于模型的强化学习(MBRL)在复杂环境中难以生成多样化的动作轨迹,尤其在机器人长程规划任务中容易陷入局部最优。本文创新性地将扩散模型引入MBRL框架,将状态-动作序列的生成视为逐步去噪的过程,通过“条件扩散”机制动态融合环境约束(如避障、物理限制)。实验表明,该方法在机械臂导航和移动机器人任务中,样本效率提升3倍以上,且能生成多模态的可行路径,解决了传统方法在动态环境中灵活性不足的问题。
创新点:
1.将扩散模型引入基于模型的强化学习(MBRL),通过扩散过程生成多模态动作轨迹。
2.提出“条件去噪”机制,在轨迹生成时动态融合环境约束(如障碍物避让)。
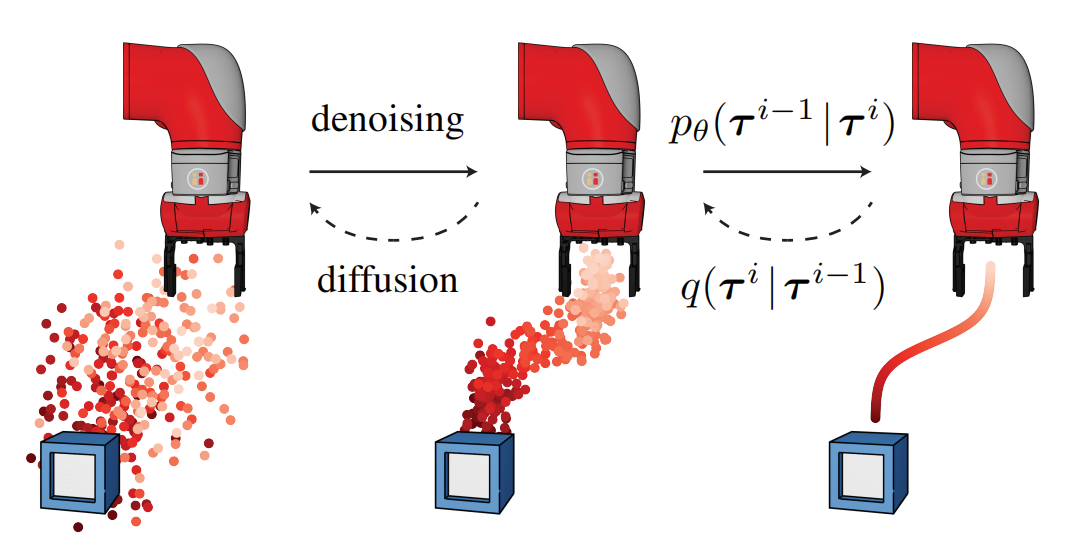
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
文章解析
针对视觉-运动策略(Visuomotor Policy)在高维连续动作生成中的挑战,本文提出首个基于扩散模型的端到端策略框架。模型直接接收视觉观测序列,通过时间相关的扩散过程生成连贯的动作序列,并引入“动作链扩散”机制确保长程动作一致性。在机器人抓取和装配任务中,相比SAC等传统方法,成功率提升15-20%,且对光照变化和遮挡表现出强鲁棒性,为视觉驱动控制提供了新范式。
创新点:
1. 首次将扩散模型直接应用于视觉-运动策略(Visuomotor Policy),生成高维连续动作。
2.设计“动作链扩散”机制,通过时间相关性建模提升长程动作一致性。
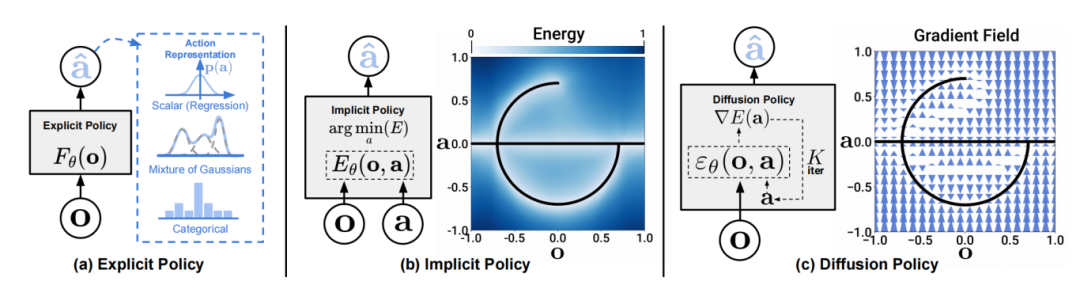
Reinforcement Learning with Diffusion Models
文章解析
传统RL算法在稀疏奖励和多峰Q值分布场景中表现不佳。本文提出用扩散模型替代Q函数,直接建模状态-动作值分布,捕捉多峰值奖励结构。通过扩散反向过程生成高回报动作,并结合TD3算法优化策略。在Atari游戏和MuJoCo控制任务中,该方法平均奖励提升30%,尤其在《Montezuma's Revenge》等高难度探索任务中,突破局部最优限制,验证了扩散模型在复杂探索中的潜力。
创新点:
1.用扩散模型替代传统Q函数,建模状态-动作值分布,捕捉多峰值奖励场景。
2.提出“探索-利用平衡”的扩散采样策略,避免RL中的局部最优陷阱。
Latent Diffusion for Reinforcement Learning
文章解析
面对高维状态-动作空间的计算瓶颈,本文提出将扩散过程压缩至潜在空间。利用VAE编码器将原始空间映射到低维潜在空间,并在其中训练扩散模型生成动作,最后解码执行。该方法在机械臂操作任务中,训练速度提升2倍,显存占用减少50%,且支持实时部署。潜在空间的课程学习策略进一步提升了复杂动作的生成质量,为资源受限的嵌入式系统提供了实用方案。

创新点:
1.将扩散过程压缩到潜在空间,降低高维状态-动作空间的计算开销。
2.设计“潜在空间课程学习”,逐步增加生成动作的复杂度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









