










目标:
前文已经有了调用AI大模型的经验,现在搞点自己的实际需求,就是翻译大藏经,大藏经内容太多了,就想着用AI来批量翻译。
结果呢,是成功也是失败的,成功,就是真的翻译出来了,可以看,失败是说,翻译出来的内容,还是不如高僧大德们翻译的好。
结论:如果要了解一下实现过程,作为一篇技术文档,这一篇可以看看。
准备:
必须具备的运行环境,参考之前的文章:
【菜鸟飞】用vsCode搭建python运行环境_vscode python插件下载-CSDN博客
特别特别推荐的,有了代码助手,基本动动嘴,代码就出来了,所以特别推荐,给代码环境增加代码助手:
【菜鸟飞】给vsCode安装AI的翅膀 TONGYI Lingma(通义灵码)-CSDN博客
然后,就是准备大模型的调用,也是必须的,参考:
【菜鸟飞】AI多模态:vsCode下python访问阿里云通义文生图API-CSDN博客
实践过程
1、打开vscode,在通义灵码里说出自己的要求,让其推荐大模型,如:
把文档中的佛经内容,翻译成白话文,尽量保持其原意和语境,用那个大模型好?
2、然后,进一步提出要求,让通义生成代码
生成具体的代码:用推荐的模型,把“e:\01pycode2\fores”的文件,翻译成白话文,输出到“e:\01pycode2\fores2”下面,并把翻译原文和译文结合的文件,输出到“e:\01pycode2\fores3”
3、 根据输出的代码,生成.py文件,修改你自己的api-key,进行测试,测试过程,如果出现错误,就让通义修改代码,并可以根据测试情况,不对的提优化,如这样
优化:避免超大文件一下加载的风险,逐段加载,逐段翻译
操作界面:
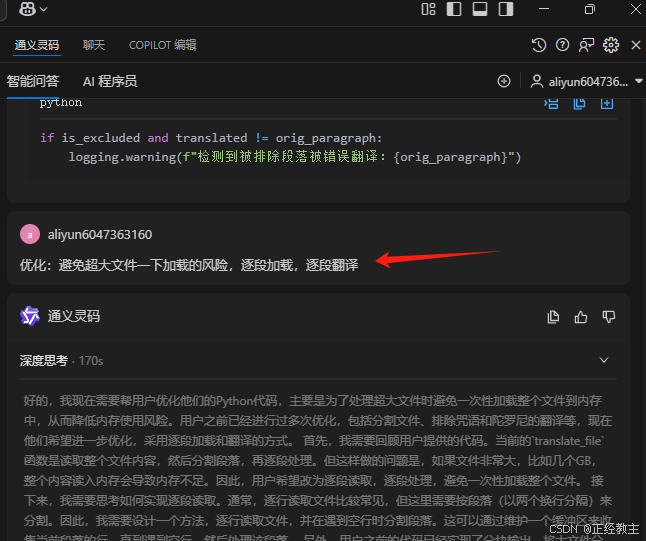
经过分析,通义会给出调整后的代码,可以拷贝替换原代码,也可以新建一个.py文件:
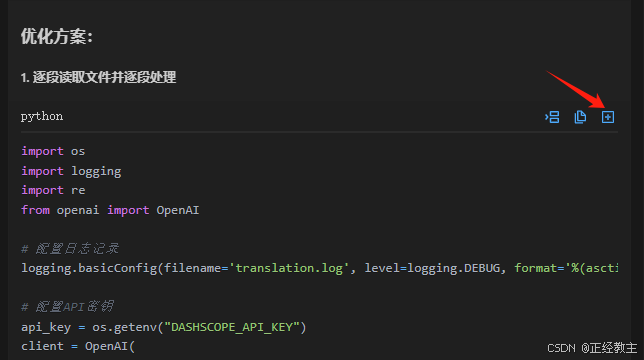
经过上面反复的过程,就能出结果了。
成果
测试的原文件:
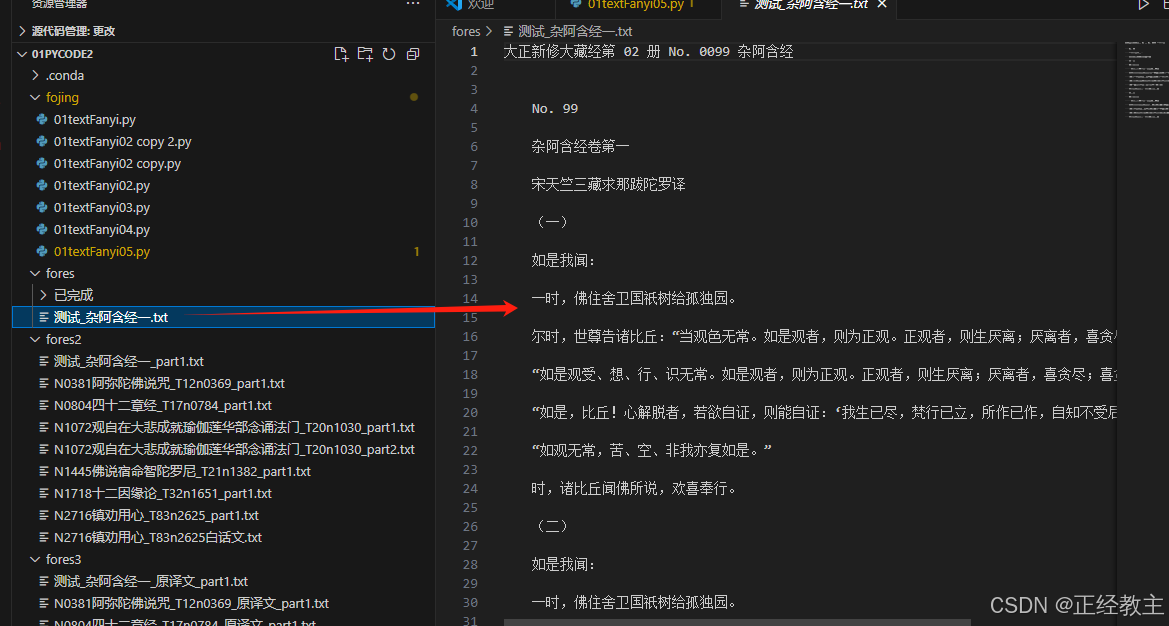
翻译的成果:
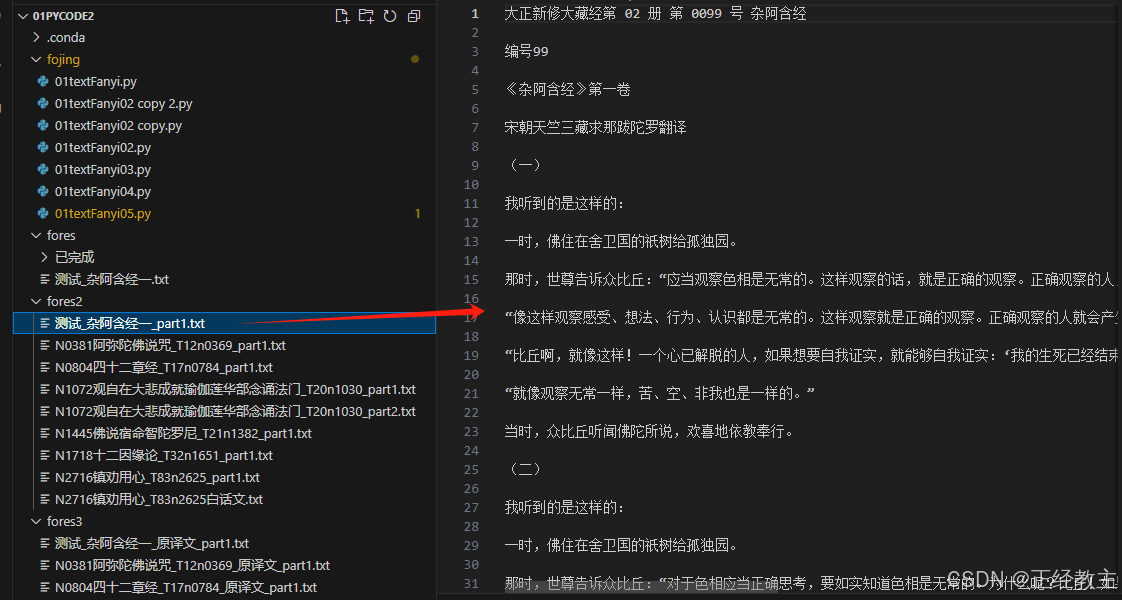
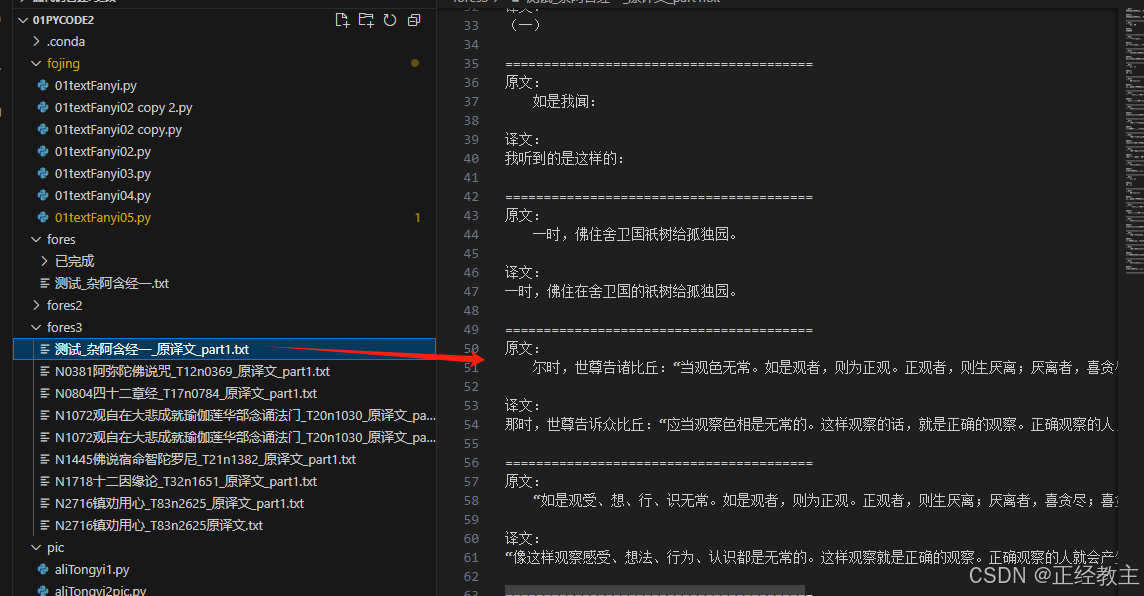
从上面看,AI翻译的非常不错,但没有对比就没有伤害~
对比一下
悟慈大德的翻译:
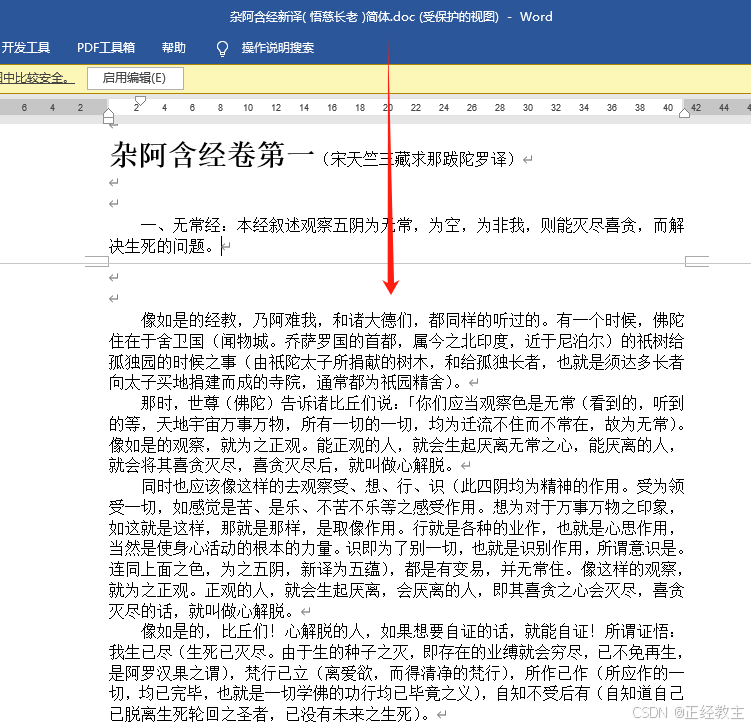
成果代码:
"""
佛经白话文翻译工具 v2.0
功能说明:
1. 支持批量处理文本文件,自动分割超大文件为多个分块
2. 智能识别并排除咒语/陀罗尼内容(保留原文不翻译)
3. 生成翻译对照文件,保留原文与译文对照
4. 自动处理异常并记录日志
依赖项:
- openai库
- DASHSCOPE_API_KEY环境变量
使用方法:
1. 将待翻译文件放入输入目录 (directory)
2. 运行脚本后自动生成:
- 白话文文件 → fores2目录
- 原译对照文件 → fores3目录
"""
import os
import logging
import re
from openai import OpenAI
# 配置日志记录(记录错误和关键操作)
logging.basicConfig(
filename='translation.log',
level=logging.DEBUG,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# 配置API密钥(优先读取环境变量)
api_key = os.getenv("DASHSCOPE_API_KEY")
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def read_paragraphs(file_path: str) -> str:
"""逐行读取文件并分割段落
参数:
file_path (str): 输入文件路径
生成器返回:
paragraph (str): 每个段落内容(由连续非空行组成)
逻辑:
- 空行(strip后为空)作为段落分隔符
- 连续非空行合并为一个段落
"""
current_paragraph = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
stripped_line = line.strip()
if stripped_line:
current_paragraph.append(line)
else:
if current_paragraph:
yield ''.join(current_paragraph)
current_paragraph = []
if current_paragraph:
yield ''.join(current_paragraph)
def translate_paragraph(paragraph: str) -> str:
"""调用Qwen-Max模型进行翻译
参数:
paragraph (str): 需要翻译的原文段落
返回:
str: 翻译结果或错误信息
特性:
- 固定使用temperature=0.1保证翻译稳定性
- 自动捕获API异常并记录日志
"""
try:
completion = client.chat.completions.create(
model="qwen-max-latest",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': f"请将以下内容翻译成白话文,保持其原意和语境,特别是准确性,仅输出翻译结果,不要添加任何解释或注释:\n{paragraph}"}
],
temperature=0.1
)
return completion.choices[0].message.content
except Exception as e:
logging.error(f"翻译段落时出错: {paragraph}\n错误信息: {e}")
return f"翻译错误: {e}"
def translate_file(input_file_path: str, output_dir: str, comp_dir: str, max_file_size: int=5000):
"""核心翻译处理函数
参数:
input_file_path (str): 输入文件路径
output_dir (str): 白话文输出目录
comp_dir (str): 原译对照文件目录
max_file_size (int): 单个输出文件最大字符数(默认5000)
流程:
1. 逐段读取并判断是否需要排除翻译
2. 实时分块处理(按字符数控制文件大小)
3. 同时生成白话文文件和对照文件
特殊处理:
- 咒语/陀罗尼识别:正则匹配括号注音或固定开头
- 文件分割:按字符数自然分割,不破坏段落完整性
"""
current_block = []
current_size = 0
block_num = 0
base_name = os.path.splitext(os.path.basename(input_file_path))[0]
for paragraph in read_paragraphs(input_file_path):
stripped_paragraph = paragraph.strip()
if not stripped_paragraph:
continue
# 排除条件判断(咒语/陀罗尼)
is_excluded = bool(
re.search(r'\([^)]+\)', stripped_paragraph) or # 括号注音格式
stripped_paragraph.startswith(('咒曰:', '陀罗尼曰:')) # 特定开头
)
paragraph_length = len(paragraph)
# 分块处理逻辑
if current_size + paragraph_length > max_file_size:
# 写入当前块到文件
if current_block:
block_num += 1
output_path = os.path.join(output_dir, f"{base_name}_part{block_num}.txt")
comp_path = os.path.join(comp_dir, f"{base_name}_原译文_part{block_num}.txt")
with open(output_path, 'w', encoding='utf-8') as out_f, \
open(comp_path, 'w', encoding='utf-8') as comp_f:
for orig, is_exc in current_block:
translated = orig if is_exc else translate_paragraph(orig)
out_f.write(f"{translated}\n\n")
comp_f.write(f"原文:\n{orig}\n译文:\n{translated}\n\n{'='*40}\n")
# 清理末尾多余换行
with open(output_path, 'r+', encoding='utf-8') as f:
content = f.read()
if content.endswith('\n\n'):
f.seek(0)
f.write(content.rstrip('\n\n'))
f.truncate()
current_block = []
current_size = 0
current_block.append( (paragraph, is_excluded) )
current_size += paragraph_length
# 处理最后一个块
if current_block:
block_num +=1
output_path = os.path.join(output_dir, f"{base_name}_part{block_num}.txt")
comp_path = os.path.join(comp_dir, f"{base_name}_原译文_part{block_num}.txt")
with open(output_path, 'w', encoding='utf-8') as out_f, \
open(comp_path, 'w', encoding='utf-8') as comp_f:
for orig, is_exc in current_block:
translated = orig if is_exc else translate_paragraph(orig)
out_f.write(f"{translated}\n\n")
comp_f.write(f"原文:\n{orig}\n译文:\n{translated}\n\n{'='*40}\n")
with open(output_path, 'r+', encoding='utf-8') as f:
content = f.read()
if content.endswith('\n\n'):
f.seek(0)
f.write(content.rstrip('\n\n'))
f.truncate()
def process_files_in_directory(directory: str):
"""批量处理目录中的文本文件
参数:
directory (str): 输入目录路径
流程:
1. 遍历目录中所有.txt文件
2. 调用translate_file进行翻译处理
3. 输出进度信息
注意事项:
- 自动创建输出目录(如果不存在)
- 支持大小写文件扩展名(.txt/.TXT)
"""
for filename in os.listdir(directory):
if filename.endswith(('.txt', '.TXT')):
base_name = filename.rsplit('.', 1)[0]
input_path = os.path.join(directory, filename)
print(f"正在翻译文件: {input_path}")
translate_file(
input_path,
directory2,
directory3
)
print(f"翻译完成,输出到目录: {directory2} 和 {directory3}")
# 配置目录路径
if __name__ == "__main__":
directory = r'e:\01pycode2\fores' # 输入目录
directory2 = r'e:\01pycode2\fores2' # 白话文输出目录
directory3 = r'e:\01pycode2\fores3' # 对照文件输出目录
# 确保输出目录存在
os.makedirs(directory2, exist_ok=True)
os.makedirs(directory3, exist_ok=True)
# 启动批量处理
process_files_in_directory(directory)结论:
怎么说呢,只能是根据实际情况选择,哇哈哈~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











