










前言
n8n是一款开源的低代码自动化工具,专注于AI工作流构建,支持灵活的自定义与集成。
就是可以把大模型和其他工具联合起来,这就厉害了。而且,免费功能又强大,目前很火,来研究一下。
功能说明
本节目标:n8n调用公网的大数据模型,完成一个简单的工作流。
技术准备
1、n8n的安装见前面文档:
【AI平台】n8n入门1:详细介绍n8n的多种安装方式(含docer图形化安装n8n)-CSDN博客
2、n8n是英文版(没找到中文切换到地方![]() ),我给浏览器安装了翻译插件,需要的可以参考:
),我给浏览器安装了翻译插件,需要的可以参考:
3、其他(参考可选):
n8n工作流 ,链接本地大模型,见
【AI平台】n8n入门2:第一个工作流,调用本地大模型-CSDN博客
本节涉及的三种调用方式
n8n对大语言模型调用,有不同方式:
一种,内置了大语言模型的信息,只要提供API-key就行了,如 DeepSeek、Gemini
另一种,用request调用,像硅基流动、阿里平台支持很多模型,就用这种,相对复杂一点点,但平台有免费token可以用,优先介绍这种:
第三种,和上面类似,是通过Open API标准协议,调用各种大模型,包括各平台的大模型,当然也可以是大模型原厂的,最后介绍这种。
request调用方式
公网大数据模型准备
没有大语言模型可以的,参考我之前文档,注册及API-key(用的是硅基流动200万免费tocken)
【AI入门】获得DeepSeek免费token(含其他大模型)-CSDN博客
然后,需要收集三个信息:模型名称和cURL,以及API-key。
在硅基流动模型广场,选一个模型: Models
注意,如果是免费tocken,不要选带Pro前缀的,这个免费tocken用不了:
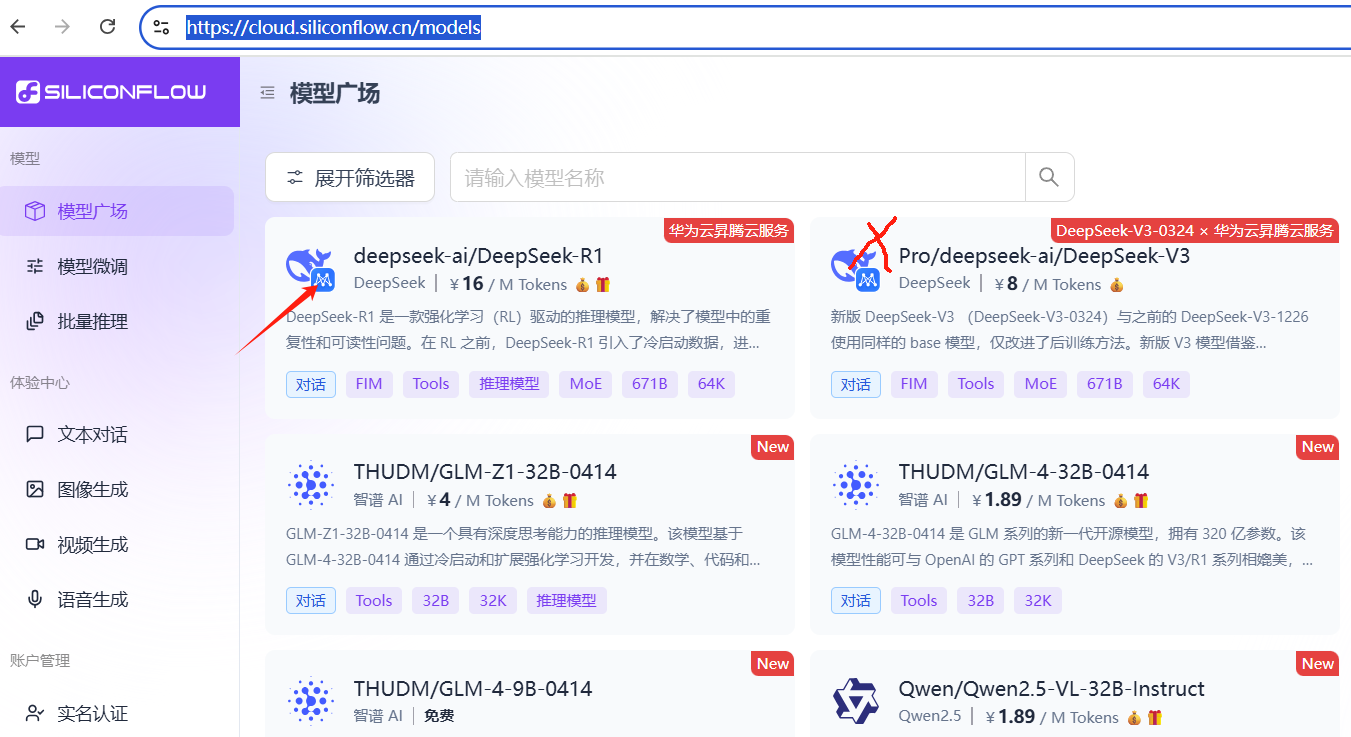
我这里以R1 为例,点击,可以查看详细信息,
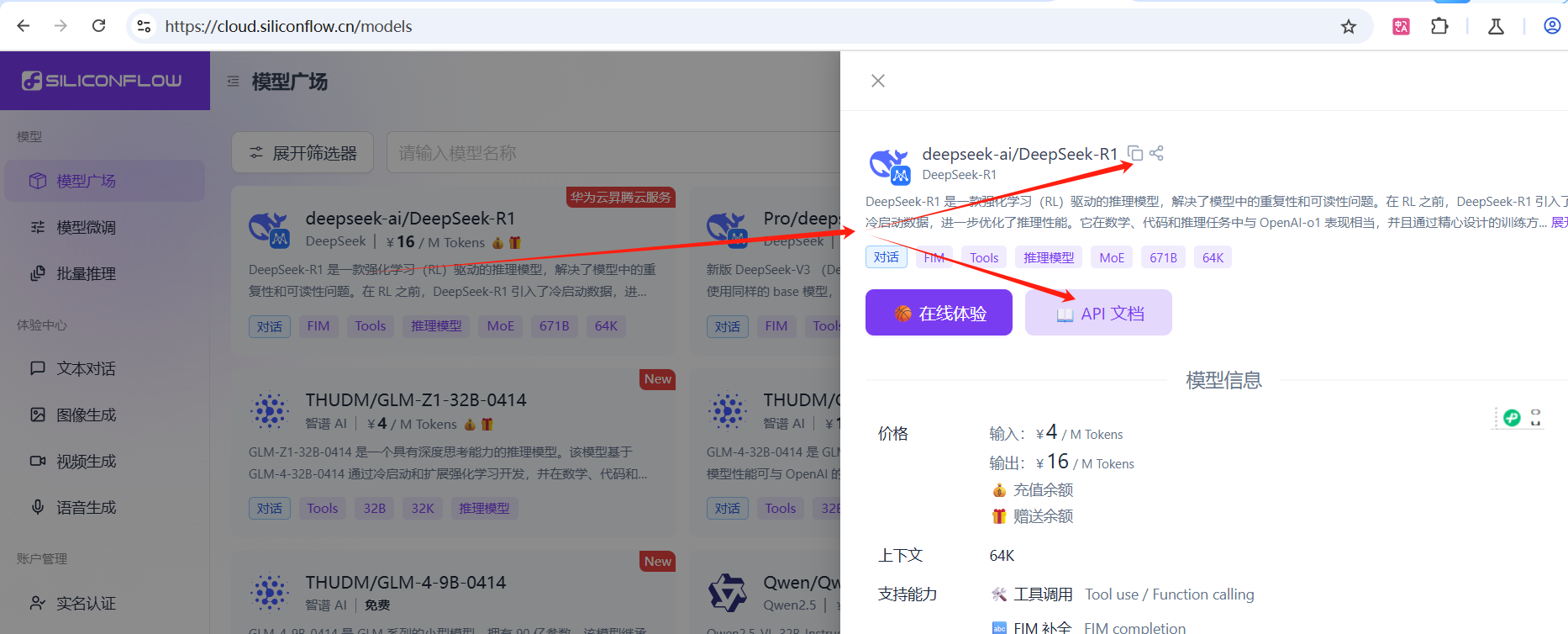
拷贝模型名称备用:deepseek-ai/DeepSeek-R1
然后,点击API文档,进一步查看页面信息:
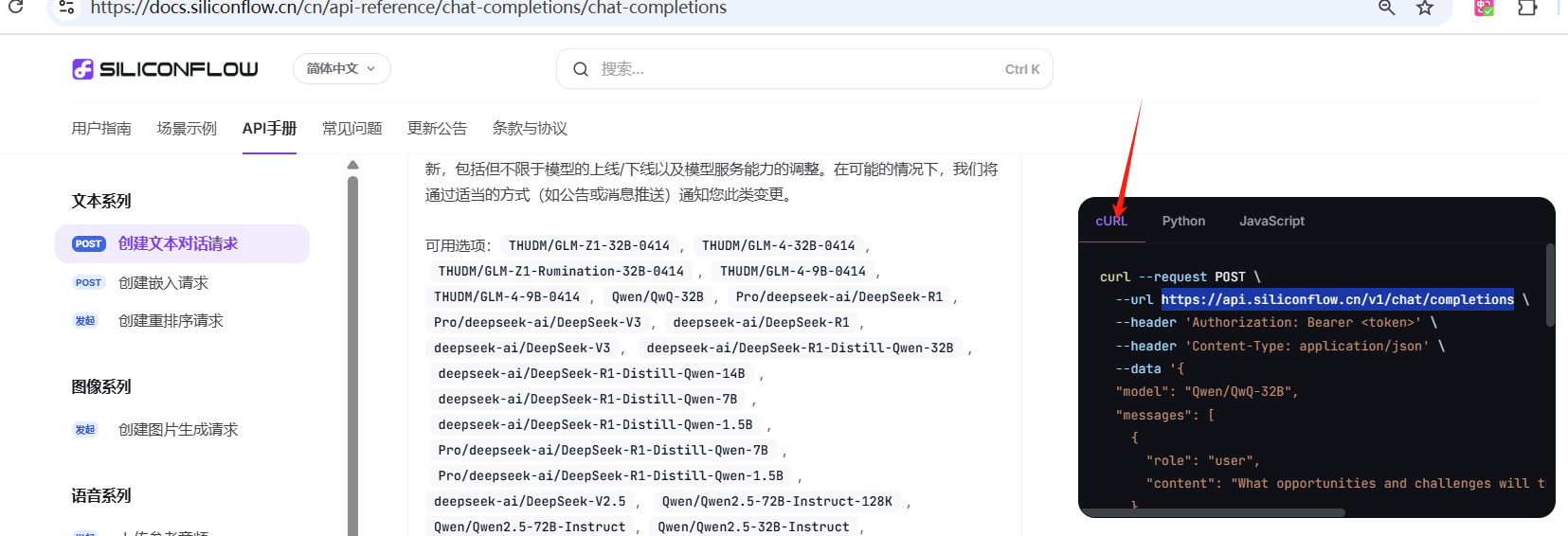
把其中cURL信息拷贝下来,备用:
curl --request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen/QwQ-32B",
"messages": [
{
"role": "user",
"content": "What opportunities and challenges will the Chinese large model industry face in 2025?"
}
],
"stream": false,
"max_tokens": 512,
"stop": null,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {
"type": "text"
},
"tools": [
{
"type": "function",
"function": {
"description": "<string>",
"name": "<string>",
"parameters": {},
"strict": false
}
}
]
}'在有就是,把自己的API-key拷贝下来,备用:
大模型的信息准备完了,可是正式配置u8n工作流了。
创建工作流
进入n8n软件:http://localhost:5678/,创建工作流:
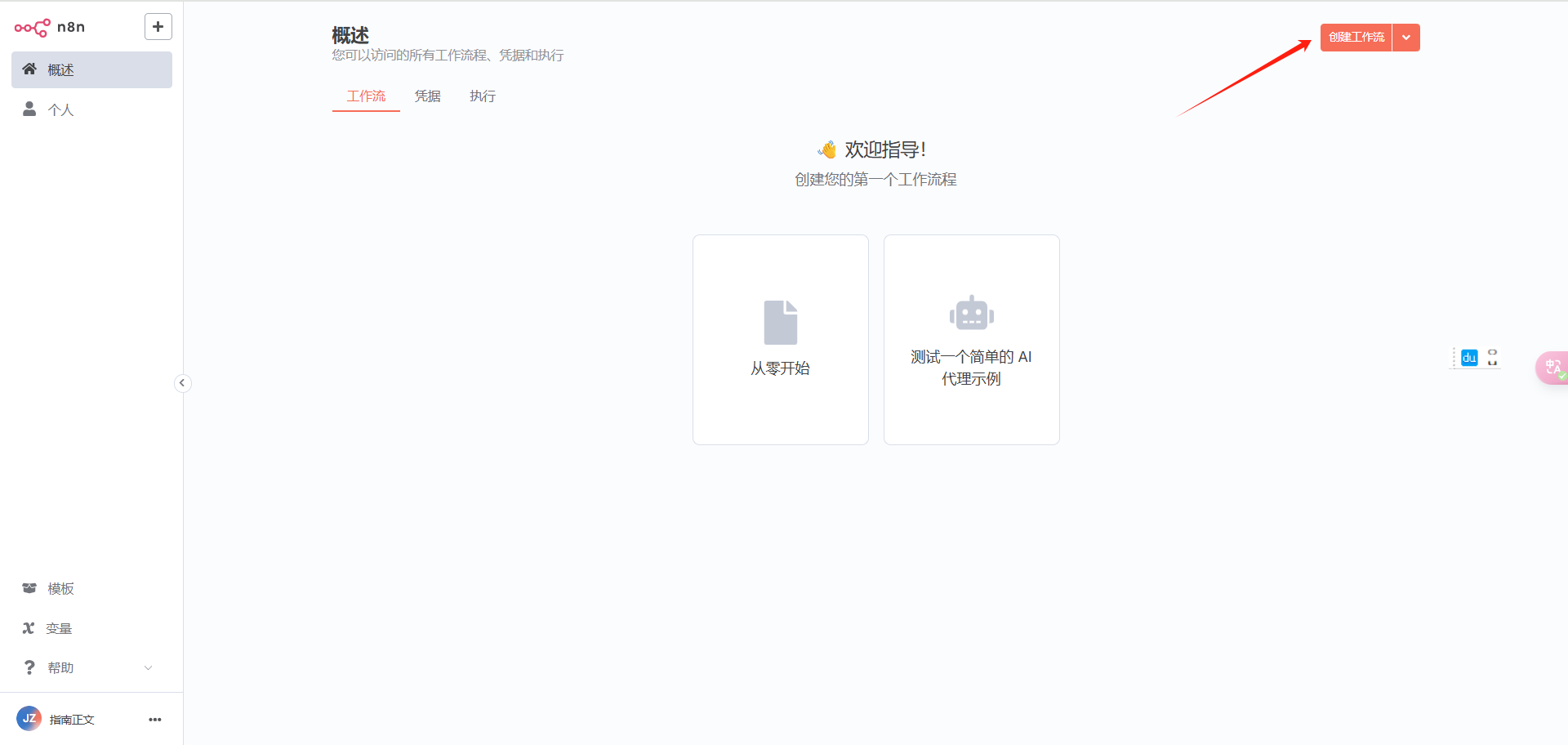
改名,我这里取名“firstExample”,然后点击“添加第一步”,触发选择“在聊天信息时”:
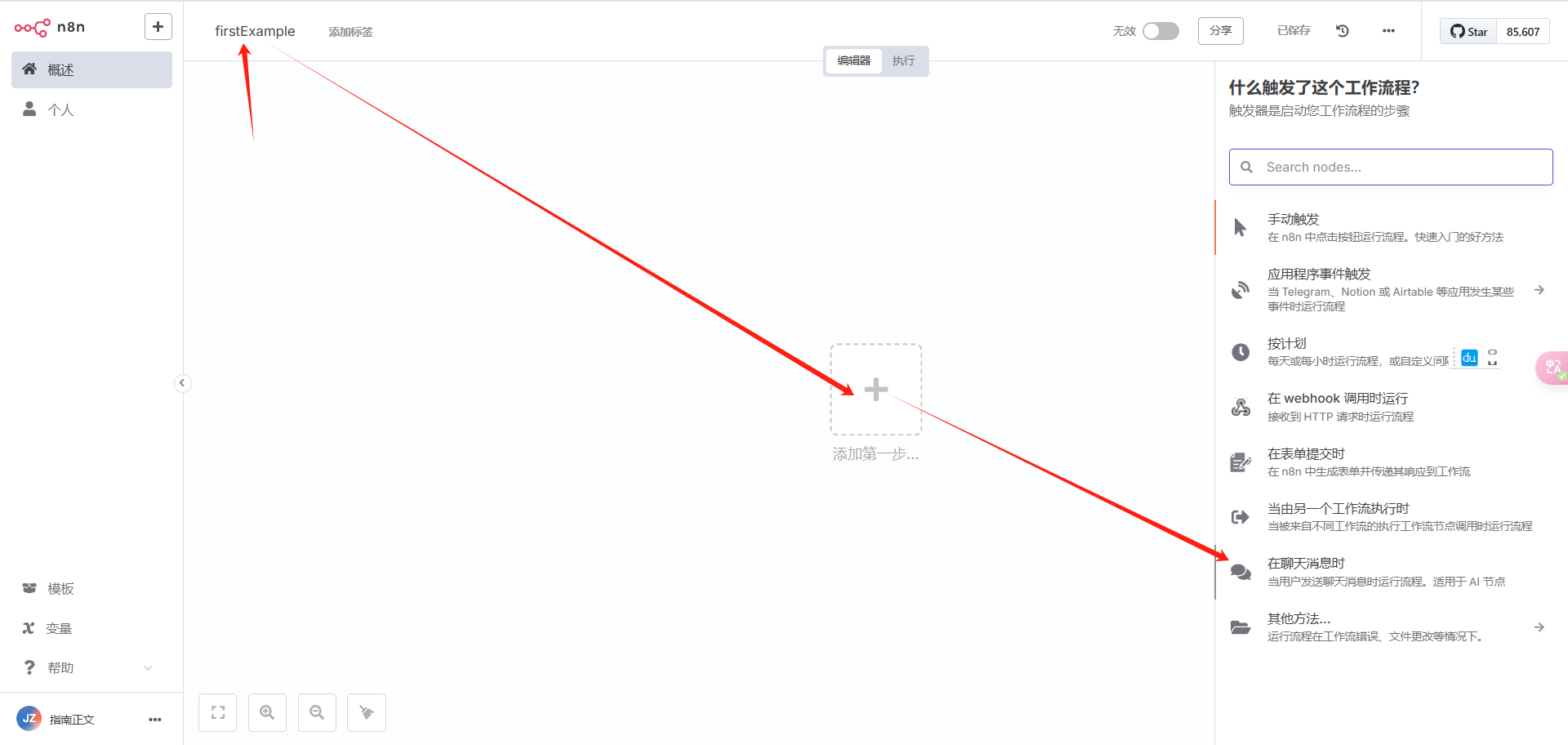
然后,打开聊天设置窗口:
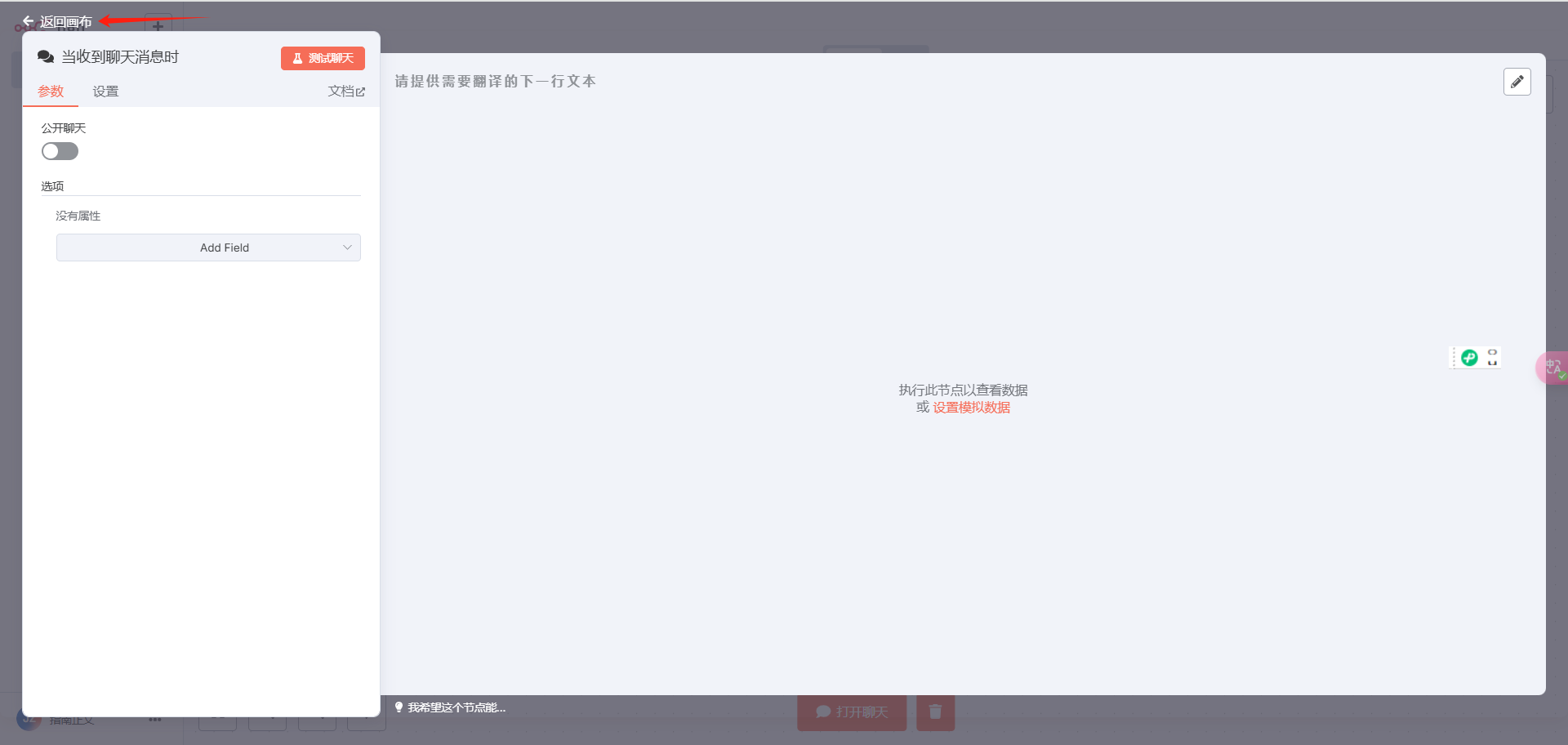
点击“测试聊天”,输入一个测试数据,后面配置看着方便,
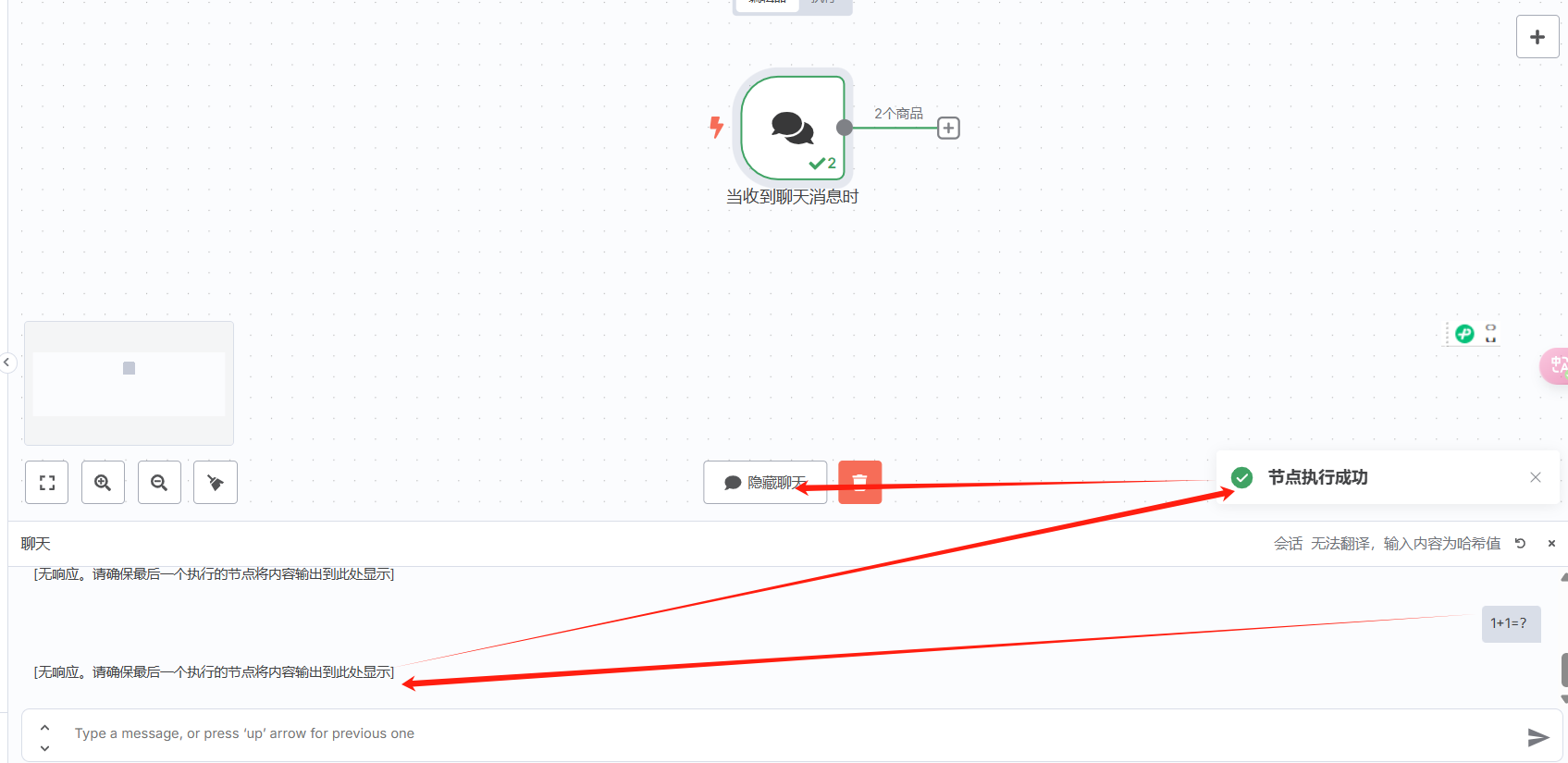
关联平台的大语言模型
因为没有关联程序,返回“无响应”=》节点执行成功,关闭聊天,继续配置就行了:
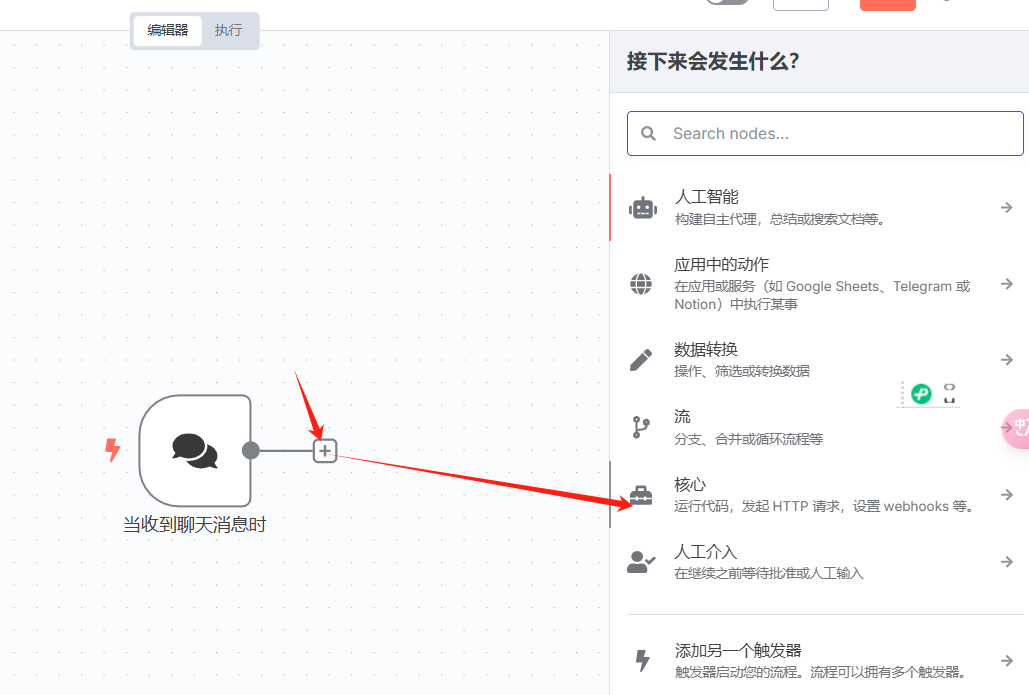
在主界面,点击“+”,选择“核心”:
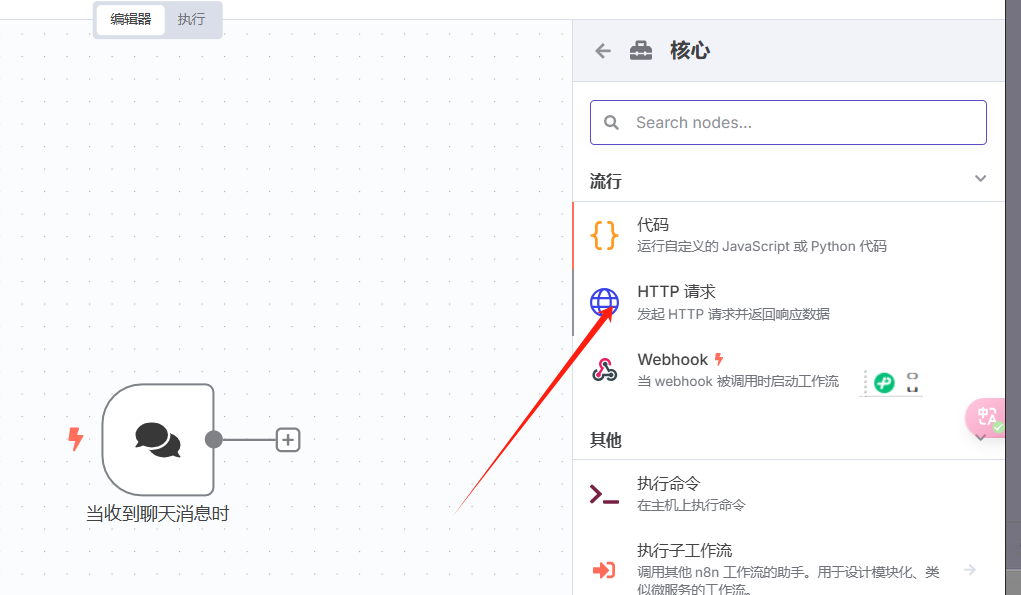
选择http请求,进入配置页面,
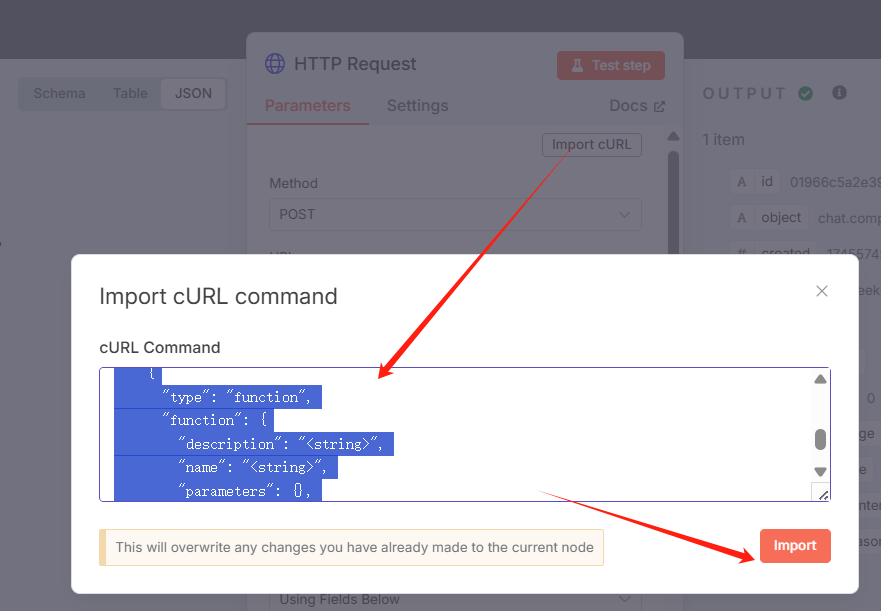
点击“import cURL”,把刚才拷贝的大模型的cURL粘贴过来,导入,系统自动读入参数:
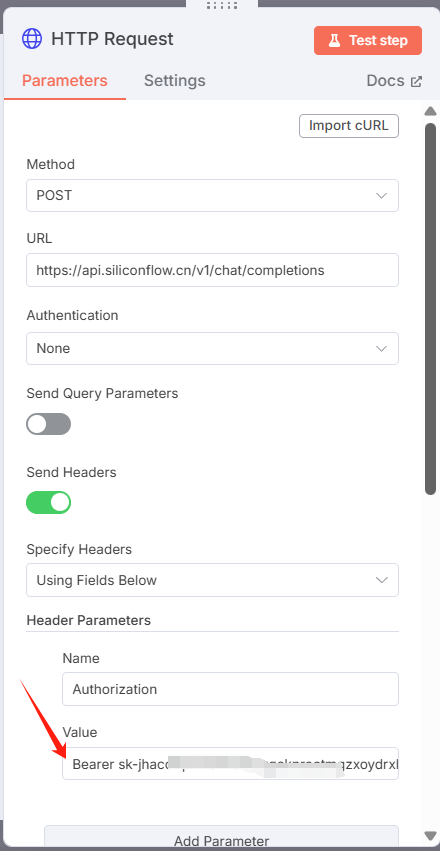
把API-key替换到Bearer后面,注意这中间要留空格,
修改json,在json框中,修改model名称为刚才选的模型名称,然后content是推给大模型的问题,我们用起始节点的输入内容,修改代码参考如下:
{
"model": "deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "{{ $json.chatInput }}"
}
],
"stream": false,
"max_tokens": 512,
"stop": null,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {
"type": "text"
},
"tools": [
{
"type": "function",
"function": {
"description": "<string>",
"name": "<string>",
"parameters": {},
"strict": false
}
}
]
}
修改完,点击顶部的“Test step”,返回大模型的答复信息,就是调用成功了。
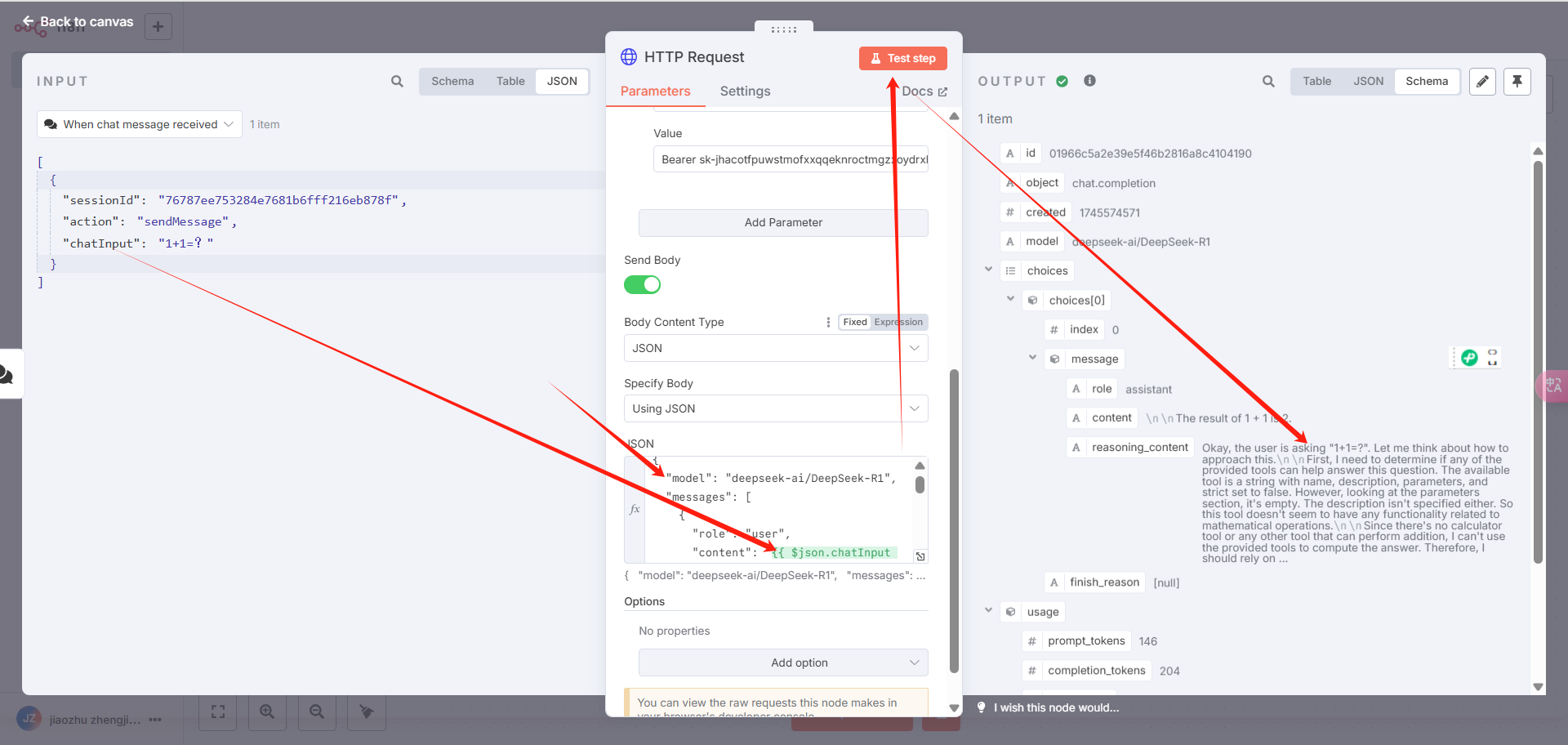
就可以聊天使用了:

n8n内置大模型的方式
准备大模型数据
以DeepSeek为例,注册账号,进入API开发平台:
 创建API密钥,并拷贝备用:
创建API密钥,并拷贝备用: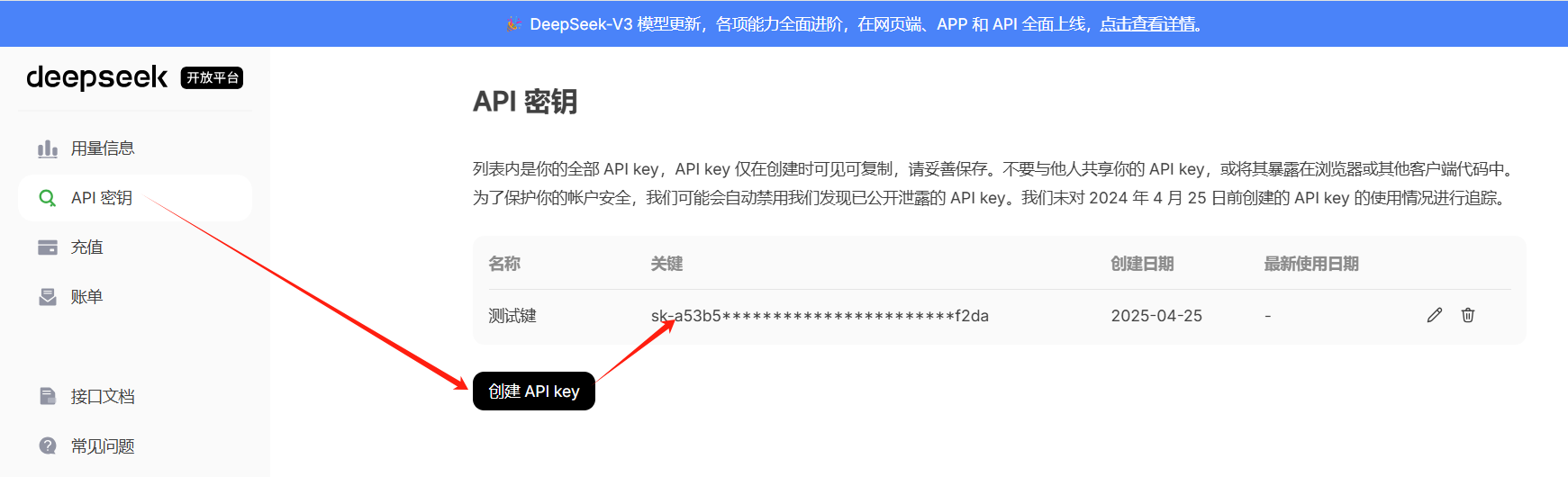
还需要充值。
创建工作流
创建一个新工作流,以聊天信息触发,作为开始节点,这和上边相同, 然后增加节点,选“人工智能”:
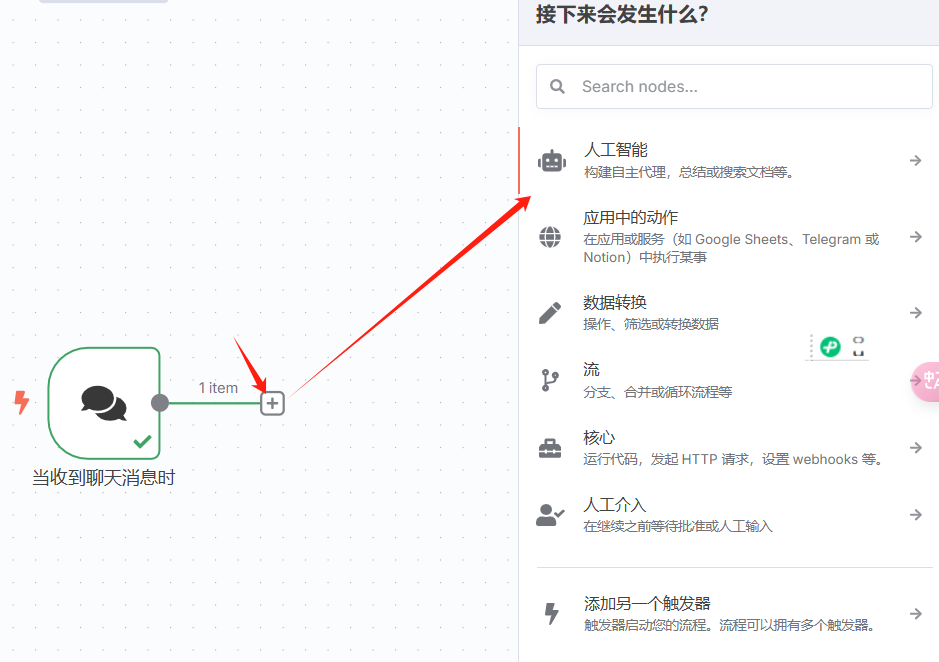
在选"人工智能代理":
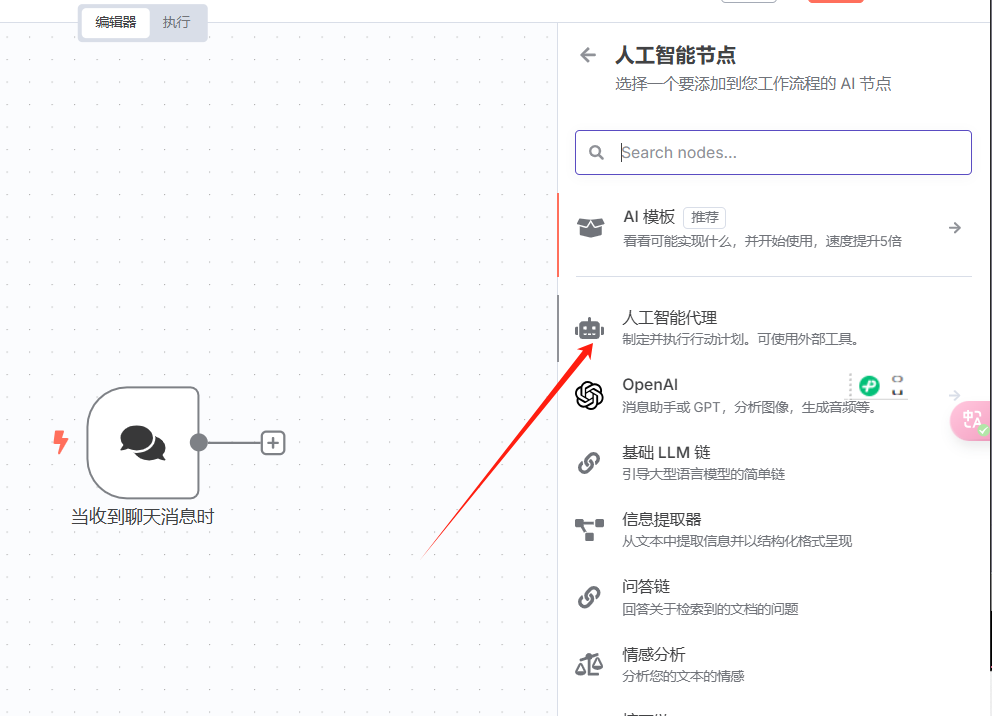 在弹出页面,选择添加聊天模型:
在弹出页面,选择添加聊天模型:
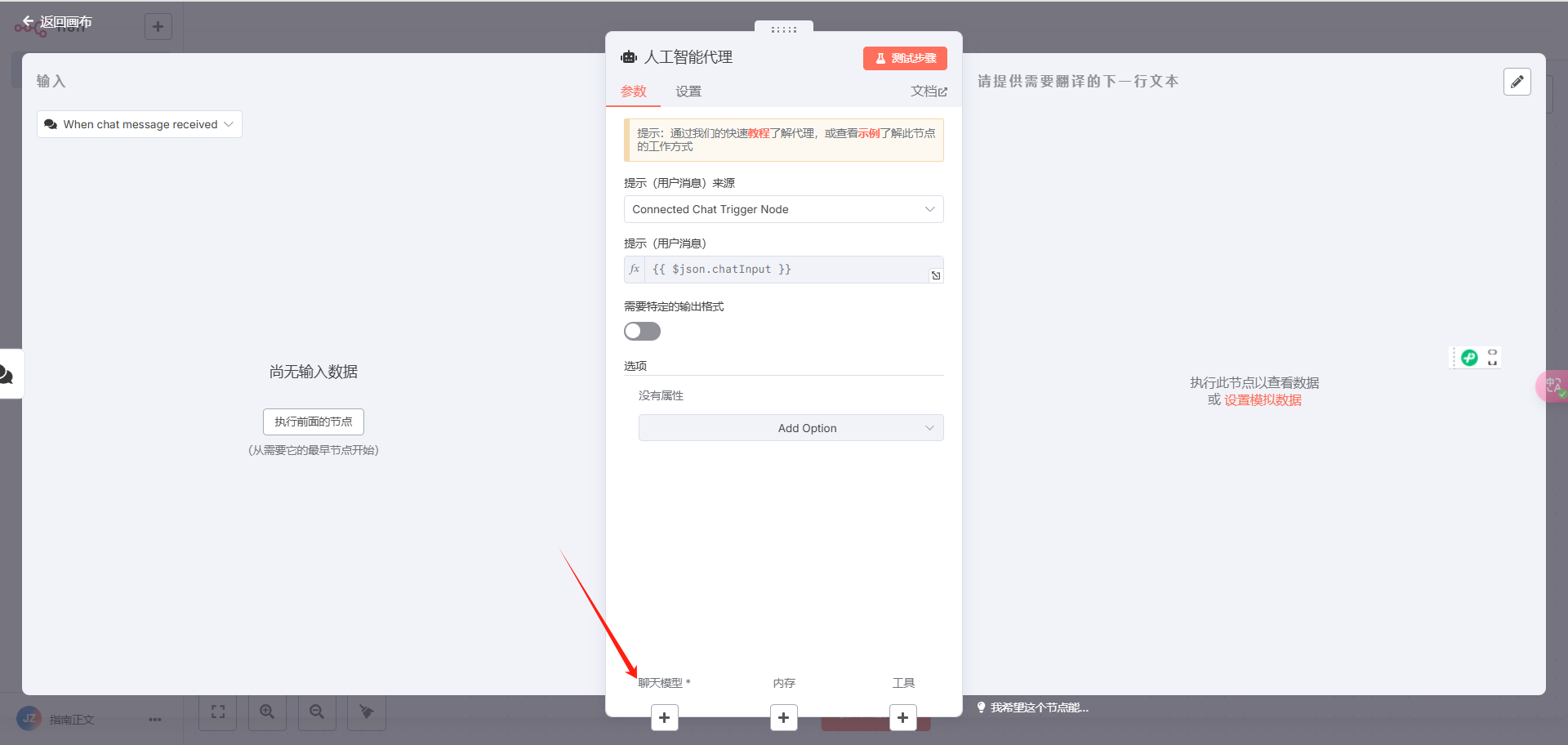
选择DeepSeek:
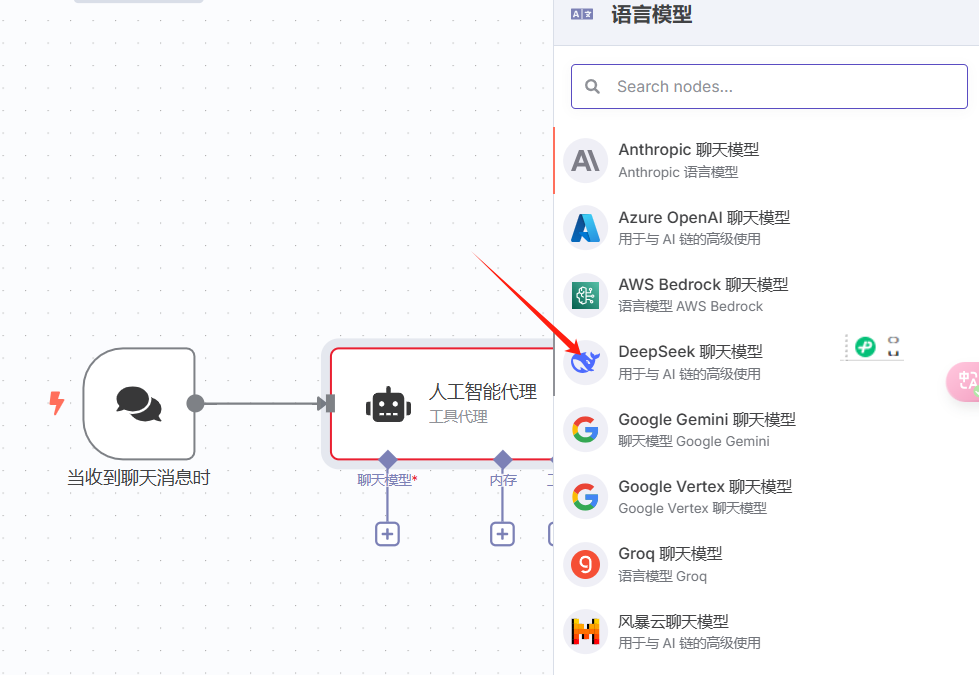
创建新凭证:
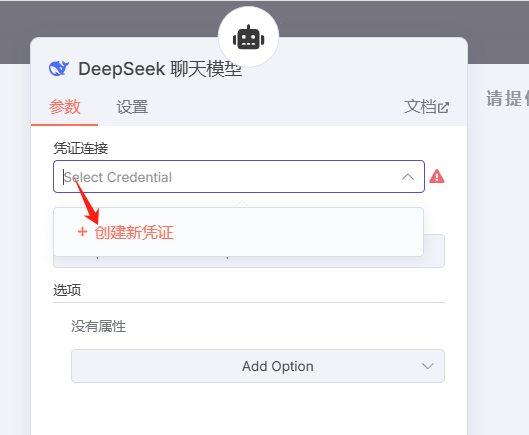
添加在DeepSeek网站注册的APK-key:
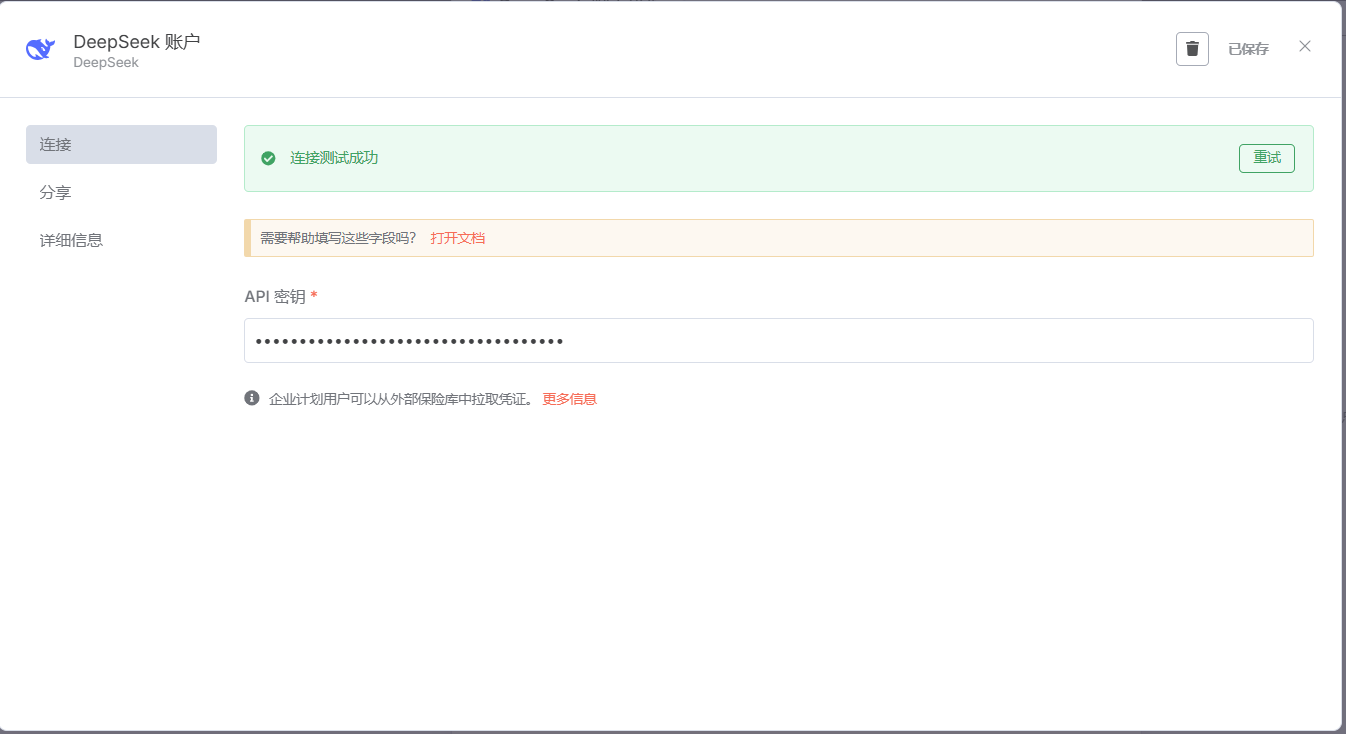
然后,选择模型,需要平台充值,模型才能用
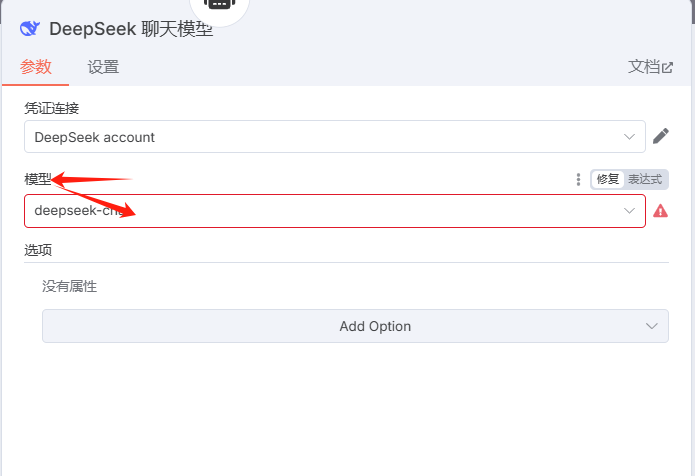
后面的步骤就是类似的了。
Open API的调用方式
准备大数据OpenAPI信息
硅基流动官网API调用方式见文档:快速上手 - SiliconFlow
拷贝其中的base_url,备用:
base_url="https://api.siliconflow.cn/v1"
还有大模型名称、API-key,和request调用方式中的相同。
创建工作流
创建一个新工作流,以聊天信息触发,作为开始节点,这和上边相同, 然后增加节点,选“人工智能”:
在选"人工智能代理",【注,不要选这个界面的OpenAI,这是openAI他家的模型,不是用Open AI协议的模型】:
在弹出页面,选择添加聊天模型:
选择OpenAI聊天模型:
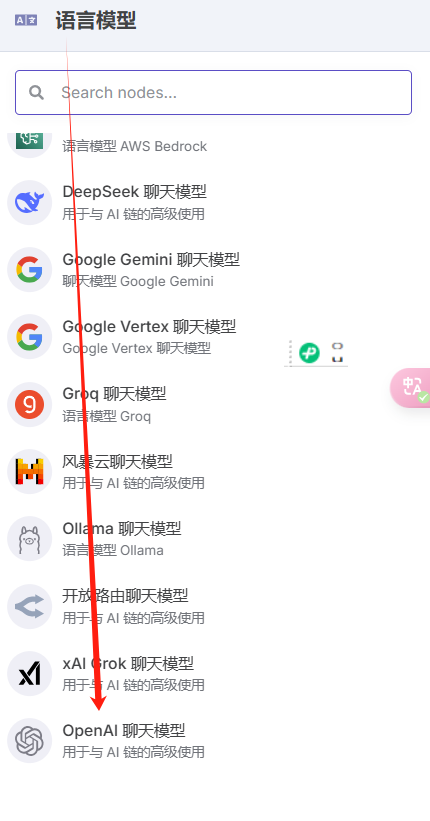
弹出对话框,配置凭证,
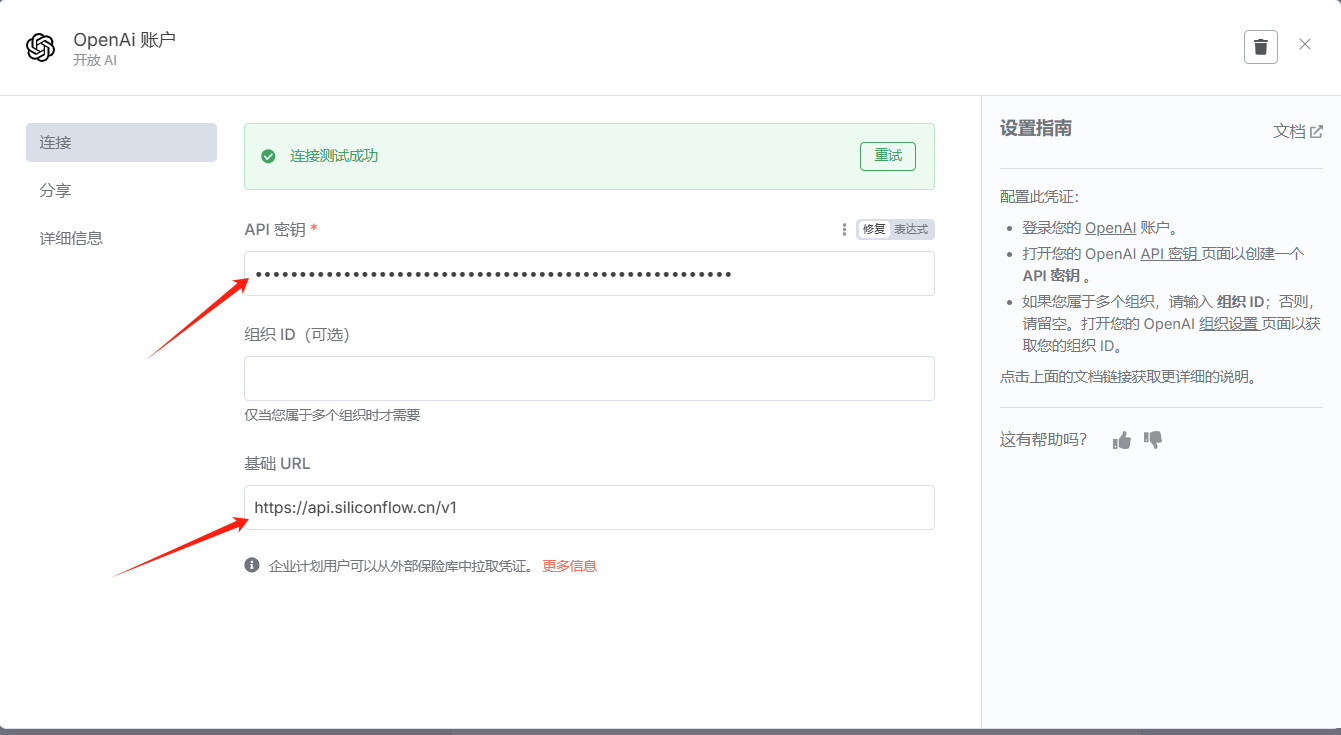
输入硅基流动的base_url,和API-key,保存,回到模型配置界面,选择一个大模型就可以了:
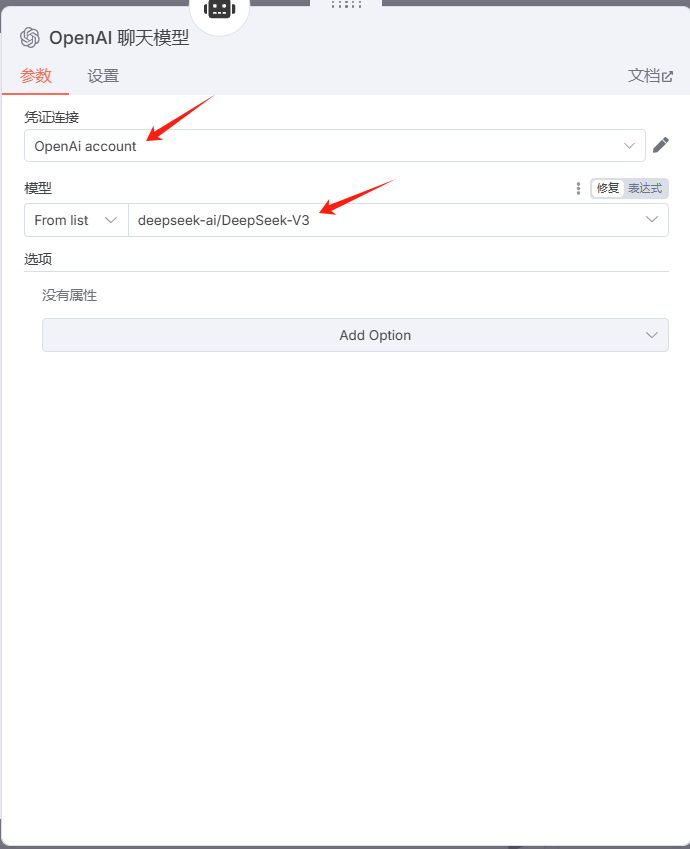
返回主页面,测试一下,通过的节点都是标绿的。
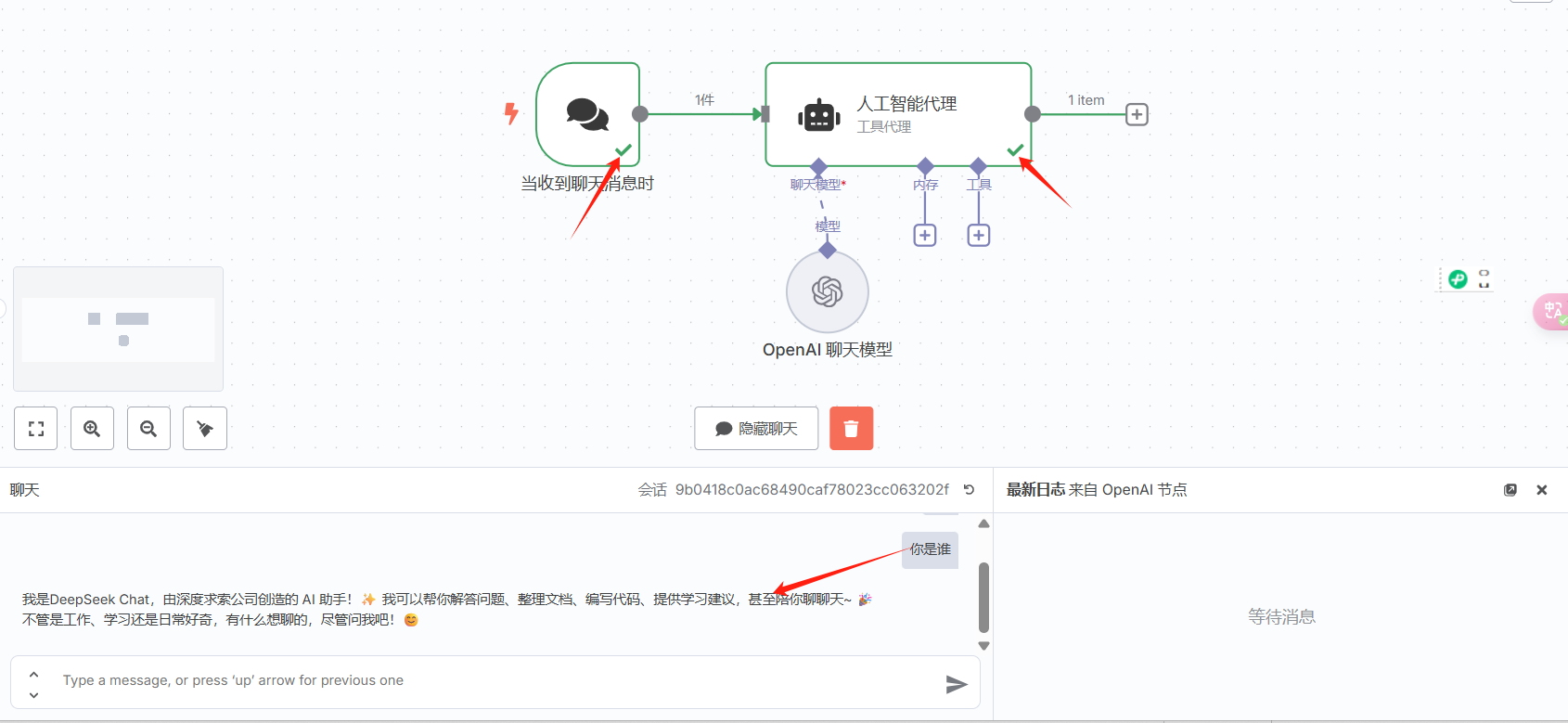
结尾
这么简单的功能,弄起来也不简单,但复杂的功能,是简单的功能拼起来的,会越来越强大的,💪💪💪


















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











