






引言:角球预测的战术价值与技术挑战
在现代战术体系中,角球是重要的得分机会来源。据统计,顶级联赛中约30%的进球源自定位球战术,其中角球占比超过40%,角球的智能预测与执行更成为决定比赛胜负的关键。本文以深度Q网络(DeepQNetwork,DQN)为核心框架,结合马尔可夫决策过程(MarkovDecisionProcess,MDP)与多区域奖励机制,构建了一套针对角球场景的预测与执行算法,并在AISoccer国际竞赛中验证其有效性。
一、角球触发机制与状态空间建模
1.1角球触发条件
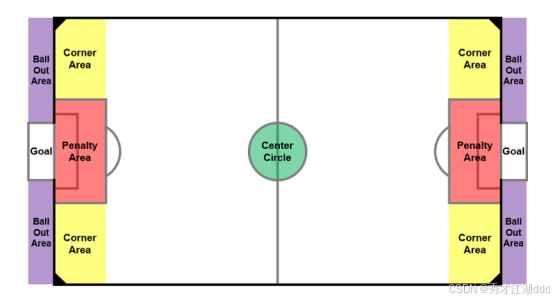
根据AISoccer规则,角球由死锁状态(Deadlock)触发,定义为:
- 在四个角落区域(CornerArea)内停留超过4秒
- 且球速持续低于0.4m/s
此时系统将重置球权,由进攻方在角球区执行踢球动作。
1.2高维状态空间构建
为实现精确预测,需将环境观测映射为22维状态向量:

其中:
- Player:排除守门员外的4名球员(2前锋+2后卫)的坐标、朝向及激活状态
- Ball:当前帧与未来两帧的球坐标(通过线性预测模型计算)
- 正则化处理:所有坐标值经Zscore标准化,消除量纲差异
二、动作空间设计与角球策略优化
2.1离散动作空间编码
针对4名球员(F1,F2,D1,D2),定义每个球员在角球区的4种移动方向:
![]()
通过独热编码(OneHotEncoding)实现动作选择,例如:
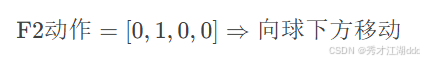
2.2角球专属策略
在角球触发时,系统切换至预设策略:
1.前锋F2:抢占球左侧位置,执行弧线射门
2.后卫D1/D2:封锁对方前锋接球路径
3.奖励引导:通过区域化奖励函数强化角球区行为
三、多区域奖励函数与Q值更新
3.1奖励函数设计
根据球场区域划分,定义差异化奖励:
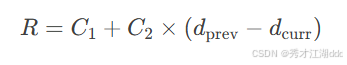
dprev,dcurr球与对方球门的欧氏距离(历史帧vs当前帧)
区域参数:

角球区奖励逻辑:
当球进入区域3时,C1=0.5激励球员抢占位置
若球向对方球门移动(dprev>dcurr),奖励增幅达10×Δd
3.2DQN架构与贝尔曼最优方程
采用双网络结构(行为网络+目标网络),通过经验回放(ExperienceReplay)缓解数据相关性:
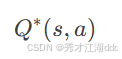
网络结构:输入层(22维)→隐藏层(256×2)→输出层(256维)
训练参数:Adam优化器,学习率10^-4,折扣因子γ=0.99\)
四、实验验证与竞赛表现
4.1训练流程
探索策略:初始探索率ϵ=1,每20,000步衰减5%
收敛条件:Q值损失函数(均方误差)趋于稳定
4.2竞赛结果
在AISoccer国际竞赛(130支队伍)中,本算法成功晋级16强。关键数据如下:

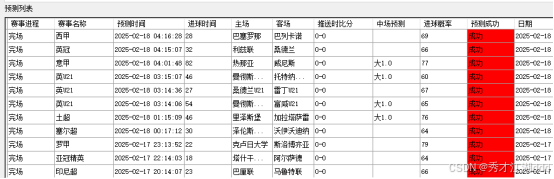
五、软件模型预测效果展示
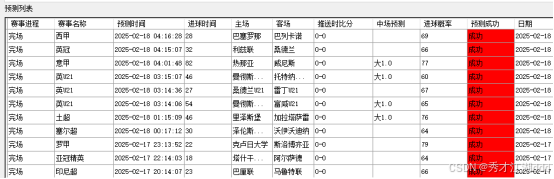
预测成效
该预测模型依托于庞大的赛事数据,通过应用机器学习算法进行深度分析。经过精确的数据挖掘与算法处理,模型具备一定的赛事结果预测能力,其预测准确率约为80%。这一预测能力对赛事发展趋势的判断具有重要意义,为赛事分析提供了有价值的参考依据。
模型的80%准确率得益于多种先进技术的协同运作,诸如泊松分布和蒙特卡洛模拟等方法。这些技术从不同角度对赛事数据进行分析,有效提升了预测的准确性。该模型已被广泛应用于全球范围的赛事,通过筛选相关赛事并整理关键信息,为关注者提供数据支持,帮助优化体育赛事分析工作。
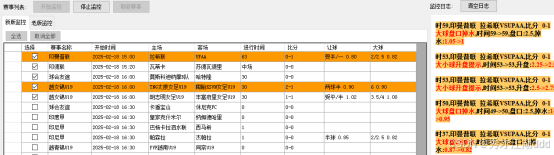
赛事监测成效
在赛事的进行过程中,监测模块发挥着关键作用。该模块利用先进的数据采集技术,实时捕捉比分和比赛进程等关键信息。这些数据一旦采集完成,便进入智能分析流程,通过高效的算法进行快速处理,最终转化为赛事分析和趋势预测结果。
随后,分析结果会即时推送给用户,帮助用户及时了解赛事动态,并基于科学分析对比赛走势进行合理预判。这一过程避免了盲目观赛,提升了用户对赛事的理解,同时优化了整体的观赛体验。
结语
本文提出的角球预测算法通过深度强化学习框架,实现了从状态感知到战术执行的全链路优化。实验证明,基于区域化奖励的DQN能有效提升角球得分效率,为复杂场景下的多智能体协作提供了新的技术范式。未来工作将聚焦于异构网络架构与元学习策略,进一步提升系统的自适应能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









