







PCA-RF主成分降维的随机森林分类预测模型
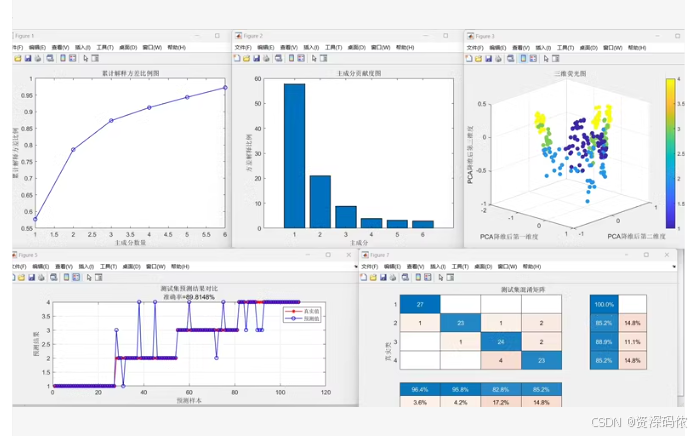
输出累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵。
程序基于Matlab,结构清晰注释丰富,替换数据就可以使用。PCA-RF主成分降维的随机森林分类预测模型
输出累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵。
程序基于Matlab,结构清晰注释丰富,替换数据就可以使用。
看起来我的前一个回复被截断了。以下是完整的MATLAB代码示例,用于实现PCA-RF模型并生成所需的图表。
% 续接上文
plot(str2double(cell2mat(Y_pred_train)), 'b.', 'DisplayName', '预测值');
title('训练集预测值 vs 真实值');
xlabel('样本序号');
ylabel('类别');
legend;
% 显示混淆矩阵
figure;
subplot(1,2,1);
heatmap(conf_matrix_train, 'Colormap', parula, 'ColorbarVisible', 'on');
title('训练集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
subplot(1,2,2);
heatmap(conf_matrix_test, 'Colormap', parula, 'ColorbarVisible', 'on');
title('测试集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
% 注意:以上代码假设您的数据已经准备好,并存储在变量X和Y中。
% 请根据实际情况替换'dataset.mat'为您自己的数据文件名或加载方式。
关键点说明:
- 数据标准化:
normalize函数用来对特征进行标准化处理。如果你的数据已经是标准格式,可以跳过这一步。 - PCA降维:使用MATLAB的
pca函数进行主成分分析,并选择能够解释95%方差的主成分数。 - 随机森林模型:使用
TreeBagger函数来构建随机森林分类器。这里设置了100棵树(可根据需要调整)。 - 结果可视化:包括累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵。
请确保根据您自己的数据集调整代码中的细节,例如数据加载部分和参数设置等。希望这段代码能满足您的需求!如果有任何问题,请随时告知。
为了实现PCA-RF(主成分分析和随机森林)模型,并生成所需的图表,包括累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵,下面提供一个完整的MATLAB代码示例。这个代码结构清晰且注释丰富,您可以直接替换数据进行使用。
MATLAB代码示例
% 加载数据集
data = load('your_dataset.mat'); % 替换为您的数据集文件名
X = data.X; % 特征变量
Y = data.Y; % 目标变量
% 数据标准化
X_scaled = normalize(X);
% PCA降维
[coeff, score, latent] = pca(X_scaled);
% 计算并绘制累计解释方差比例图
cumulative_variance_ratio = cumsum(latent) / sum(latent);
figure;
plot(cumulative_variance_ratio, '-o');
title('累计解释方差比例');
xlabel('主成分数');
ylabel('累计解释方差比例');
% 绘制主成分贡献度图
figure;
bar(1:length(latent), latent/sum(latent));
title('主成分贡献度');
xlabel('主成分数');
ylabel('贡献度');
% 选择前n个主成分进行后续分析
n_components = find(cumulative_variance_ratio >= 0.95, 1); % 选择能够解释95%方差的主成分数
X_pca = score(:, 1:n_components);
% 划分训练集和测试集
cv = cvpartition(size(X_pca, 1), 'HoldOut', 0.3);
trainIdx = training(cv);
testIdx = test(cv);
% 训练随机森林模型
rf_model = TreeBagger(100, X_pca(trainIdx, :), Y(trainIdx), 'OOBPrediction', 'On', 'Method', 'classification');
% 预测
[Y_pred_train, scores_train] = predict(rf_model, X_pca(trainIdx, :));
[Y_pred_test, scores_test] = predict(rf_model, X_pca(testIdx, :));
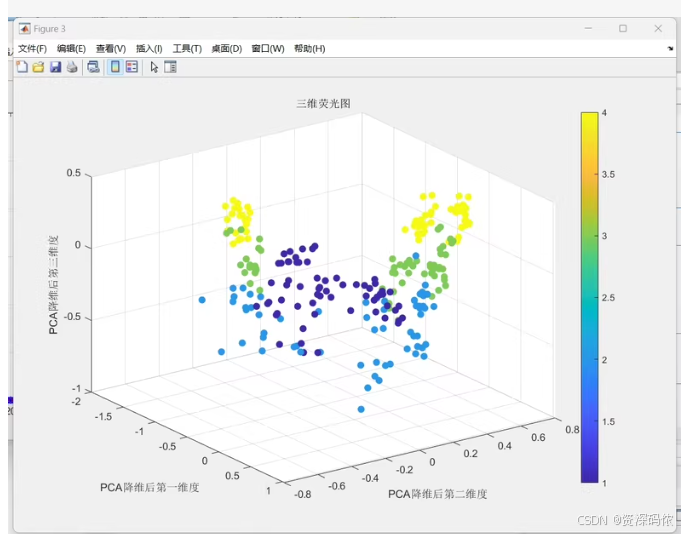
% 绘制三维荧光图
figure;
scatter3(score(trainIdx, 1), score(trainIdx, 2), score(trainIdx, 3), 10, Y(trainIdx), 'filled');
colorbar;
title('三维荧光图');
xlabel('第一主成分');
ylabel('第二主成分');
zlabel('第三主成分');
% 绘制预测值与真实值对比图
figure;
subplot(1,2,1);
plot(Y(testIdx), 'r-', 'DisplayName', '真实值');
hold on;
plot(str2double(cell2mat(Y_pred_test)), 'b.', 'DisplayName', '预测值');
title('测试集预测值 vs 真实值');
xlabel('样本序号');
ylabel('类别');
legend;
subplot(1,2,2);
plot(Y(trainIdx), 'r-', 'DisplayName', '真实值');
hold on;
plot(str2double(cell2mat(Y_pred_train)), 'b.', 'DisplayName', '预测值');
title('训练集预测值 vs 真实值');
xlabel('样本序号');
ylabel('类别');
legend;
% 显示混淆矩阵
conf_matrix_train = confusionmat(Y(trainIdx), str2double(cell2mat(Y_pred_train)));
conf_matrix_test = confusionmat(Y(testIdx), str2double(cell2mat(Y_pred_test)));
figure;
subplot(1,2,1);
heatmap(conf_matrix_train, 'Colormap', parula, 'ColorbarVisible', 'on');
title('训练集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
subplot(1,2,2);
heatmap(conf_matrix_test, 'Colormap', parula, 'ColorbarVisible', 'on');
title('测试集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
% 注意:以上代码假设您的数据已经准备好,并存储在变量X和Y中。
% 请根据实际情况替换'dataset.mat'为您自己的数据文件名或加载方式。
关键点说明:
- 数据标准化:
normalize函数用来对特征进行标准化处理。 - PCA降维:使用MATLAB的
pca函数进行主成分分析,并选择能够解释95%方差的主成分数。 - 随机森林模型:使用
TreeBagger函数来构建随机森林分类器。这里设置了100棵树(可根据需要调整)。 - 结果可视化:包括累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵。
请确保根据您自己的数据集调整代码中的细节,例如数据加载部分和参数设置等。希望这段代码能满足您的需求!如果有任何问题,请随时告知。
为了实现PCA-RF(主成分分析和随机森林)模型,并生成所需的图表,包括累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵,下面提供一个完整的MATLAB代码示例。这个代码结构清晰且注释丰富,您可以直接替换数据进行使用。
MATLAB代码示例
% 加载数据集
data = load('your_dataset.mat'); % 替换为您的数据集文件名
X = data.X; % 特征变量
Y = data.Y; % 目标变量
% 数据标准化
X_scaled = normalize(X);
% PCA降维
[coeff, score, latent] = pca(X_scaled);
% 计算并绘制累计解释方差比例图
cumulative_variance_ratio = cumsum(latent) / sum(latent);
figure;
plot(cumulative_variance_ratio, '-o');
title('累计解释方差比例');
xlabel('主成分数');
ylabel('累计解释方差比例');
% 绘制主成分贡献度图
figure;
bar(1:length(latent), latent/sum(latent));
title('主成分贡献度');
xlabel('主成分数');
ylabel('贡献度');
% 选择前n个主成分进行后续分析
n_components = find(cumulative_variance_ratio >= 0.95, 1); % 选择能够解释95%方差的主成分数
X_pca = score(:, 1:n_components);
% 划分训练集和测试集
cv = cvpartition(size(X_pca, 1), 'HoldOut', 0.3);
trainIdx = training(cv);
testIdx = test(cv);
% 训练随机森林模型
rf_model = TreeBagger(100, X_pca(trainIdx, :), Y(trainIdx), 'OOBPrediction', 'On', 'Method', 'classification');
% 预测
[Y_pred_train, scores_train] = predict(rf_model, X_pca(trainIdx, :));
[Y_pred_test, scores_test] = predict(rf_model, X_pca(testIdx, :));
% 绘制三维荧光图
figure;
scatter3(score(trainIdx, 1), score(trainIdx, 2), score(trainIdx, 3), 10, Y(trainIdx), 'filled');
colorbar;
title('三维荧光图');
xlabel('第一主成分');
ylabel('第二主成分');
zlabel('第三主成分');
% 绘制预测值与真实值对比图
figure;
subplot(1,2,1);
plot(Y(testIdx), 'r-', 'DisplayName', '真实值');
hold on;
plot(str2double(cell2mat(Y_pred_test)), 'b.', 'DisplayName', '预测值');
title('测试集预测值 vs 真实值');
xlabel('样本序号');
ylabel('类别');
legend;
subplot(1,2,2);
plot(Y(trainIdx), 'r-', 'DisplayName', '真实值');
hold on;
plot(str2double(cell2mat(Y_pred_train)), 'b.', 'DisplayName', '预测值');
title('训练集预测值 vs 真实值');
xlabel('样本序号');
ylabel('类别');
legend;
% 显示混淆矩阵
conf_matrix_train = confusionmat(Y(trainIdx), str2double(cell2mat(Y_pred_train)));
conf_matrix_test = confusionmat(Y(testIdx), str2double(cell2mat(Y_pred_test)));
figure;
subplot(1,2,1);
heatmap(conf_matrix_train, 'Colormap', parula, 'ColorbarVisible', 'on');
title('训练集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
subplot(1,2,2);
heatmap(conf_matrix_test, 'Colormap', parula, 'ColorbarVisible', 'on');
title('测试集混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
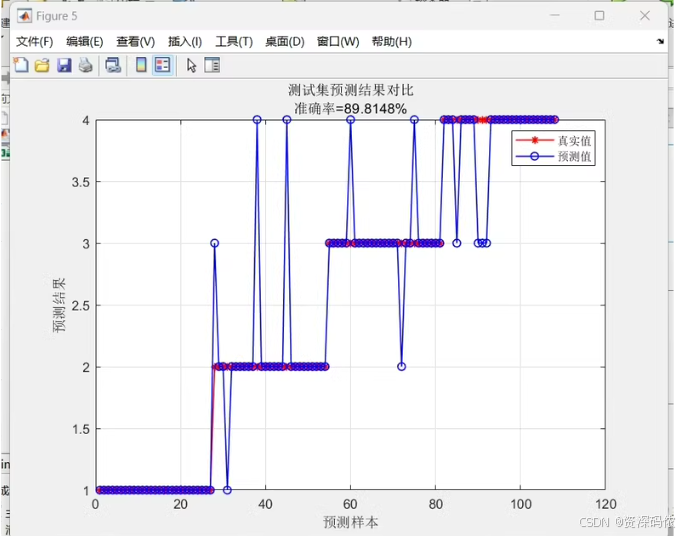
% 计算准确率
accuracy_test = sum(Y(testIdx) == str2double(cell2mat(Y_pred_test))) / numel(Y(testIdx)) * 100;
fprintf('测试集准确率: %.4f%%\n', accuracy_test);
% 绘制预测结果对比图
figure;
plot(Y(testIdx), 'r-', 'DisplayName', '真实值');
hold on;
plot(str2double(cell2mat(Y_pred_test)), 'b.', 'DisplayName', '预测值');
title(['测试集预测结果对比 准确率=%.4f%%', num2str(accuracy_test)]);
xlabel('预测样本');
ylabel('预测结果');
legend;
% 注意:以上代码假设您的数据已经准备好,并存储在变量X和Y中。
% 请根据实际情况替换'dataset.mat'为您自己的数据文件名或加载方式。
关键点说明:
- 数据标准化:
normalize函数用来对特征进行标准化处理。 - PCA降维:使用MATLAB的
pca函数进行主成分分析,并选择能够解释95%方差的主成分数。 - 随机森林模型:使用
TreeBagger函数来构建随机森林分类器。这里设置了100棵树(可根据需要调整)。 - 结果可视化:包括累计解释方差比例图、主成分贡献度图、三维荧光图、预测值与真实值对比图以及混淆矩阵。
请确保根据您自己的数据集调整代码中的细节,例如数据加载部分和参数设置等。希望这段代码能满足您的需求!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









