







基于YOLOv8的行人车辆识别系统
文件:环境、UI、模型训练文件,环境配置文档,测试图片视频,训练、测试及界面代码。
功能:基于深度学习的行人车辆检测计数系统,pyqt界面。能检测图像、视频并保存结果,展示目标位置、置信度等信息。可检测目标数目,支持摄像头实时检测、展示、记录与保存,能切换目标查看位置,提供数据集和训练代码用于重新训练。
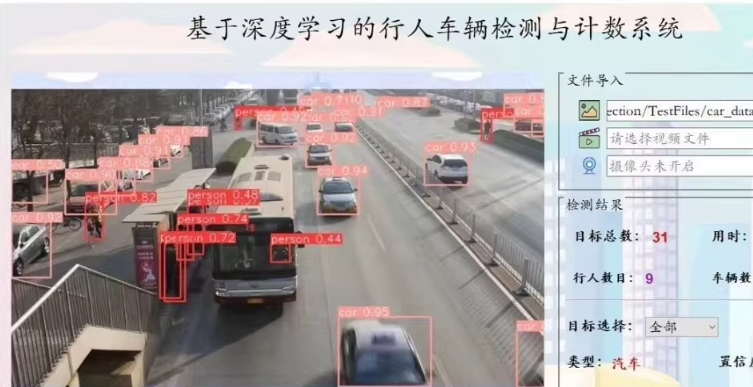
基于YOLOv8的行人车辆识别系统可以实现对图像或视频中行人和车辆的高效识别。下面将提供一个简单的指南,包括如何设置环境、加载模型以及使用YOLOv8进行行人和车辆的识别。请注意,由于YOLOv8是较新的版本,确保你的环境中安装了最新版的ultralytics库。
环境配置
首先,你需要安装必要的依赖。可以通过pip来安装ultralytics库,该库包含了YOLOv8的所有变体。
pip install ultralytics
加载模型并进行预测
下面是一个完整的Python脚本示例,演示了如何使用YOLOv8模型来检测图像中的行人和车辆。
from ultralytics import YOLO
import cv2
def load_model(model_path=None):
"""
加载预训练的YOLOv8模型。如果没有指定路径,则自动下载并使用默认的预训练模型。
:param model_path: 预训练模型的路径(可选)
:return: 加载的YOLO模型
"""
if model_path:
model = YOLO(model_path)
else:
# 使用YOLOv8n作为示例,也可以选择其他如YOLOv8s, YOLOv8m等
model = YOLO('yolov8n.pt')
return model
def detect_objects(image_path, model):
"""
对给定的图像进行目标检测。
:param image_path: 输入图像的路径
:param model: 已加载的YOLO模型
"""
results = model(image_path) # 进行预测
img = cv2.imread(image_path)
for result in results:
boxes = result.boxes.numpy()
for box in boxes:
r = box.xyxy
# 绘制边界框
cv2.rectangle(img, (int(r[0]), int(r[1])), (int(r[2]), int(r[3])), (0, 255, 0), 2)
# 显示类别和置信度分数
label = f"{model.names[int(box.cls)]} {box.conf:.2f}"
cv2.putText(img, label, (int(r[0]), int(r[1])-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
# 显示结果图像
cv2.imshow("Detected Objects", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
# 加载模型
model = load_model()
# 检测对象
detect_objects("path/to/your/image.jpg", model)
说明
- 模型选择:在上面的例子中,默认使用的是
yolov8n.pt,这是YOLOv8系列中的一个小型模型。根据实际需要,可以选择更大规模的模型以获得更好的性能,比如yolov8s.pt,yolov8m.pt等。你可以从YOLO官方GitHub获取这些模型。 - 输入输出:这个例子假设你有一个图像文件,并且会显示带有检测到的对象边界框的图像。你可以修改此代码以处理视频流或其他类型的输入。
- 实时检测:如果想要实现实时行人和车辆检测,可以考虑从摄像头捕获视频帧,并将其逐帧传递给YOLO模型进行分析。
环境配置
软件:Pycharm+Anaconda
环境:python=3.9 opencv PyQt5 torch1.9


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









