




一 引言(Intruduction)
在数字信息的海洋中,数据的完整性是构建可靠系统和信任交互的基石。然而,无论是跨越物理介质的传输,还是在存储设备中的持久化,数据都面临着被噪声、干扰或物理缺陷破坏的风险。如何以一种高效且可靠的方式检测这些潜在的错误,成为工程实践中的核心挑战之一。循环冗余校验 (CRC),正是应对这一挑战的经典且极其有效的解决方案。
CRC 是一种强大的差错检测编码技术,其核心基于多项式算术和模 2 除法。它为一段给定的数字数据(视为一个二进制多项式)计算出一个固定长度的校验和(即 CRC 码)。这个校验和对原始数据中的位错误非常敏感,即使是单个位的翻转,也极大概率会导致校验和发生变化。通过将数据与它的 CRC 码一同传输或存储,接收方或读取方可以通过重新计算数据的 CRC 并与附加的 CRC 码进行比较,来判断数据在过程中是否发生了改变。
CRC 的魅力不仅在于其强大的错误检测能力(能够检测出所有单个、两个随机位错误,所有奇数个错误,以及绝大多数的突发错误),还在于其实现的高效性。通过巧妙的硬件设计(基于线性反馈移位寄存器 LFSR)或优化的软件算法(如查表法),CRC 的计算可以非常快速,使其适用于对性能要求极高的场景。
因此,CRC 技术被广泛嵌入到我们数字生活的方方面面:从底层的以太网帧校验、USB 数据包完整性检查,到工业控制的 Modbus 和 CAN 总线协议,再到文件系统、压缩归档(ZIP, GZIP)乃至无线通信协议(如 Wi-Fi 的 FCS),CRC 无处不在地扮演着数据完整性“守护者”的角色。深入理解 CRC 的原理、不同标准(如 CRC-8, CRC-16-CCITT, CRC-32)的参数特性及其软件实现,对于任何涉及数据传输、存储或处理的工程师和开发者都至关重要。
本文旨在系统性地梳理 CRC 的理论基础,解析其工作机制,介绍几种关键的 CRC 标准,并重点提供一种高效且实用的 CRC-16-CCITT (Kermit) 查表法 C 语言实现,帮助读者不仅理解“是什么”和“为什么”,更能掌握“怎么做”,从而在自己的项目中有效地应用 CRC 技术,保障数据的可靠传输与存储。
二、CRC 是什么?—— 精炼的数字指纹与差错校验
承接引言所述,数据在产生、传输与存储的整个生命周期中,都潜藏着被篡改或损坏的风险。面对这一现实,我们需要一种机制,能够在数据接收端或读取时,以极高的概率判断数据是否依然保持其原始状态。循环冗余校验 (CRC),便是为此目标而设计的一种高效、鲁棒的差错检测技术。
从本质上讲,CRC 是一种基于伽罗瓦域 (Galois Field) GF(2) 算术(特别是多项式除法)的哈希函数。它接收一个任意长度的二进制数据块,通过一个预定义的生成多项式 (Generator Polynomial) 进行一系列精确的数学运算(本质上是模 2 的除法),最终生成一个固定长度的二进制序列——即 CRC 校验码或 CRC 校验和 (Checksum)。这个校验码可以被视为原始数据块的一个高度凝练且对内容极为敏感的**“数字指纹”**。
CRC 的运作流程精炼而严谨:
-
发送端(或写入端):
-
选取待处理的原始数据块。
-
依据选定的 CRC 标准(定义了生成多项式及其他参数),计算出对应的 CRC 校验码。
-
将此 CRC 校验码附加到原始数据块的末尾。
-
将包含原始数据和 CRC 校验码的组合数据进行传输或存储。
-
-
接收端(或读取端):
-
接收(或读取)包含原始数据和附加 CRC 校验码的数据。
-
将接收到的数据部分分离出原始数据部分和附加的 CRC 校验码部分。
-
使用与发送端完全一致的 CRC 标准,对接收到的原始数据部分独立地重新计算 CRC 校验码。
-
比较本地计算得到的 CRC 校验码与接收(或读取)到的附加 CRC 校验码。
-
-
完整性判定:
-
若两者完全一致: 则可以高度确信(尽管不是 100% 绝对保证,但概率极高)数据在传输或存储过程中未发生错误。
-
若两者不一致: 则明确表明数据在此过程中至少发生了一个错误,数据完整性已被破坏。接收端应丢弃该数据或启动错误恢复机制(如请求重传)。
-
CRC 与简单校验方式的对比:
相 较于诸如纵向冗余校验 (LRC)、简单累加和 (Checksum) 或异或校验等较为基础的差错检测方法,CRC 展现出显著优越的错误检测能力。这主要得益于其坚实的数学基础——多项式除法。CRC 能够可靠地检测出所有单比特错误、所有双比特错误(只要生成多项式选择得当)、所有奇数个比特的错误,以及在特定长度内的所有突发性错误(Burst Errors,即连续多个比特出错,这是物理信道中最常见的错误模式)。这种卓越的检错覆盖范围,是简单校验方法难以企及的。
简而言之:
CRC 不仅仅是一个校验和,它是一种精心设计的、基于代数理论的差错检测编码方案。它通过生成一个对原始数据内容高度敏感的短校验码,为我们提供了一种计算开销相对较低、但错误检测效能极高的手段,从而在不可靠的信道或存储介质上,为保障数据的真实性和完整性构筑了一道坚固的防线。
了解了 CRC 的基本概念和工作流程后,下一步我们将探究其背后的核心原理——模 2 多项式除法,揭示其强大检错能力的来源。
三、CRC 工作原理浅析 —— 模 2 多项式除法的视角
在理解了 CRC 作为一种差错检测机制的基本概念后,我们进一步探究其内部运作的核心原理。CRC 的强大能力根植于有限域算术,具体而言是模 2 (Modulo-2) 的多项式除法。虽然这听起来可能有些抽象,但其基本思想可以通过类比我们熟悉的十进制长除法来理解,只是运算规则有所不同。
1. 数据与多项式的转换
在 CRC 的世界里,任何一段二进制数据都被视为一个多项式的系数。规则很简单:数据的每一位对应多项式中的一项,从最高有效位 (MSB) 到最低有效位 (LSB) 分别对应多项式从高次幂到低次幂的系数。如果某位是 '1',则该项存在(系数为 1);如果某位是 '0',则该项不存在(系数为 0)。
-
示例: 二进制数据 1101
-
最高位 (第 3 位,从 0 开始计数) 是 1,对应 x³
-
第 2 位是 1,对应 x²
-
第 1 位是 0,对应 x¹ (省略)
-
最低位 (第 0 位) 是 1,对应 x⁰ (即 1)
-
因此,1101 对应的多项式 M(x) = 1x³ + 1x² + 0x¹ + 1x⁰ = x³ + x² + 1。
-
2. 生成多项式 G(x)
CRC 算法的核心是预先选定的生成多项式 G(x)。这是一个特定阶数 (degree) 为 'r' 的多项式,其选择对 CRC 的错误检测能力至关重要。不同的 CRC 标准(如 CRC-16, CRC-32)会规定不同的生成多项式。G(x) 的最高位和最低位系数必须为 1。生成多项式的阶数 'r' 决定了最终 CRC 校验码的位数(即长度为 r 比特)。
-
示例: 一个简单的 CRC-3 标准可能使用生成多项式 G(x) = x³ + x + 1。
-
对应的二进制表示为 1011 (系数分别为 x³, x², x¹, x⁰)。
-
该生成多项式的阶数 r = 3,意味着它将产生一个 3 比特的 CRC 校验码。
-
3. 模 2 除法运算
CRC 的计算过程模拟了用数据多项式 M(x) 除以生成多项式 G(x) 的过程,但使用的是模 2 算术规则:
-
加法和减法都等同于按位异或 (XOR),没有进位或借位。这意味着加法和减法是相同的操作。
-
乘法和除法类似于二进制下的常规操作,但加减法用 XOR 替代。
计算 CRC 的具体步骤如下:
-
数据扩展: 在原始数据 M(x) 的二进制表示后面追加 'r' 个 0(r 是生成多项式 G(x) 的阶数)。这在多项式上相当于计算 M'(x) = M(x) * x^r。
-
执行除法: 用扩展后的数据 M'(x) 的二进制表示作为被除数,用生成多项式 G(x) 的二进制表示作为除数,执行模 2 的长除法。
-
将除数 G(x) 与被除数 M'(x) 的最高位对齐。
-
如果被除数当前对齐部分的最高位是 1,则将该部分的位串与除数 G(x) 进行异或 (XOR) 运算。
-
如果被除数当前对齐部分的最高位是 0,则相当于异或 0(即不做操作)。
-
将被除数(或上一步异或的结果)逻辑左移一位(丢弃最高位,并在末尾补 0,模拟下一位“落下”)。
-
重复此过程,直到处理完被除数的所有原始数据位(即 M(x) 的所有位)。
-
-
获取余数: 当所有原始数据位都被处理后,除法过程中剩下的最后 'r' 位就是余数 R(x)。这个余数即为计算得到的 CRC 校验码。
示例: 使用 M(x) = 1101 和 G(x) = 1011 (r=3) 计算 CRC-3。
-
扩展数据:1101 后面加 3 个 0,得到 1101000。
-
执行模 2 除法:
1110 <-- 商 (实际计算 CRC 时不关心商) _______ 1011| 1101000 <-- 被除数 (扩展后的数据) 1011 <-- G(x) 与 1101 对齐,最高位为 1,执行 XOR ---- 1100 <-- XOR 结果,首位 1 1011 <-- G(x) 与 1100 对齐,执行 XOR ---- 1110 <-- XOR 结果,首位 1 1011 <-- G(x) 与 1110 对齐,执行 XOR ---- 1010 <-- XOR 结果,首位 1 1011 <-- G(x) 与 1010 对齐,执行 XOR ---- 001 <-- 最后的余数 (长度为 r=3)content_copydownload
Use code with caution. -
获取余数:余数为 001。这就是计算得到的 3 位 CRC 校验码。
发送与校验:
发送方计算出 CRC (001) 后,会将其附加到原始数据 (1101) 的末尾,发送 1101001。
接收方收到 1101001 后,可以使用两种方法校验:
-
方法一(常用):对整个接收到的数据 1101001(包括 CRC)直接用 G(x) = 1011 进行模 2 除法。如果数据无误,余数将为 0。
-
方法二:将接收到的数据分离为 1101 和 001。对 1101 重新计算 CRC,得到 001,然后与接收到的 CRC 001 比较,两者应相等。
原理核心: CRC 的构造保证了原始数据 M(x) * x^r 加上其 CRC 余数 R(x) 后得到的多项式 T(x) = M(x) * x^r + R(x),能够被生成多项式 G(x) 整除(在模 2 意义下,即余数为 0)。任何传输错误都极大概率会破坏这种整除关系,导致接收端计算出的余数不为 0,从而检测出错误。
四、直接计算法的挑战 —— 逐位运算的性能瓶颈
通过上一部分的解析,我们理解了 CRC 的计算本质上是一个模 2 多项式除法的过程。理论上,我们可以直接在软件中模拟这个逐位处理的除法运算。这通常涉及到一系列的逻辑移位 (Shift) 和条件异或 (Conditional XOR) 操作。
直接计算法的软件模拟思路通常如下:
-
初始化: 准备一个 'r' 位(r 为 CRC 阶数)的寄存器(通常称为 CRC 寄存器),并根据所选 CRC 标准的要求进行初始化(例如,全 0 或全 1)。
-
逐位处理输入数据: 对于输入数据流的每一个比特位:
-
将 CRC 寄存器的最高位与当前输入比特位进行比较(或异或)。
-
将 CRC 寄存器逻辑左移一位,最低位补 0。
-
如果上一步比较的结果表明需要执行异或(通常是当 CRC 寄存器移位前的最高位与输入位异或结果为 1 时),则将移位后的 CRC 寄存器与生成多项式 G(x)(除去最高位的 x^r 项)进行异或操作。
-
-
重复: 对数据流中的所有比特重复步骤 2。
-
最终结果: 当所有数据比特处理完毕后,CRC 寄存器中的值即为计算得到的 CRC 校验码(可能还需要根据标准进行最后的异或操作)。
这种直接模拟逐位计算的方法,虽然在概念上直观地反映了多项式除法的过程,但在软件实现中面临显著的性能挑战:
-
粒度过细: 现代处理器通常以字节(8 位)、字(16 位或 32 位)甚至更宽的单位进行操作。逐位处理数据意味着对于一个字节的数据,需要执行 8 次循环迭代,每次迭代内部又包含移位、比较/异或、条件异或等多条指令。这大大降低了处理器的运算效率。
-
循环开销大: 对大量数据进行 CRC 计算时,这种逐位处理的循环次数极其庞大,循环本身的开销(如循环计数、条件判断、跳转)会累积起来,进一步拖慢计算速度。
-
不利于指令级并行: 逐位处理的依赖性较强(当前位的处理依赖于前一位处理后的 CRC 寄存器状态),不利于现代处理器利用指令级并行来提高性能。
总结来说,直接基于多项式除法原理的逐位软件实现方法,虽然可行,但其计算效率相对低下**。在需要高速处理大量数据流的场景下,例如网络数据包校验、磁盘文件读写校验、实时通信协议处理等,这种性能瓶颈是难以接受的。
这就促使工程师们寻求更高效的软件实现策略。幸运的是,基于 CRC 计算的线性特性,存在一种可以通过预计算来大幅加速 CRC 计算的方法,那就是我们接下来要重点介绍的——查表法 (Lookup Table Method)。查表法通过空间换时间,将原本需要多次迭代的位操作转化为简单的查表和少量运算,极大地提升了 CRC 的软件计算性能。
五、高效实现:查表法 —— 空间换时间的优化之道
面对直接计算法逐位处理带来的性能瓶颈,工程师们利用 CRC 计算的线性特性(具体来说,是基于异或运算的可分配性)发展出了一种极为高效的软件实现方法——查表法 (Lookup Table Method)。这种方法的核心思想是:通过预先计算并存储部分结果,将原本复杂的逐位运算转化为简单的查表操作,从而以空间(存储查找表)换取时间(计算速度)。
查表法的核心思想:
我们知道,CRC 的计算过程可以看作是输入数据流逐位“影响” CRC 寄存器状态的过程。直接计算法是模拟每一位的影响。而查表法则更进一步:它预先计算出一个完整的字节(8 位)输入对 CRC 寄存器状态产生的净影响,并将这些影响结果存储在一个查找表 (Lookup Table) 中。
这个查找表通常包含 256 个条目,对应于所有可能的 8 位字节值(从 0x00 到 0xFF)。表中的每一个条目存储的值是:当 CRC 寄存器处于某个特定状态(通常是全 0)时,输入该索引对应的字节后,CRC 寄存器会变成什么值。
查表法的运作流程:
当需要计算一个数据块的 CRC 时,查表法的处理流程(以字节为单位)大致如下(这里以一种常见的实现方式为例,具体细节可能因 CRC 参数和优化策略略有不同):
-
初始化: 将 CRC 寄存器按照所选标准的规定进行初始化(如全 0 或全 1)。
-
查表更新(逐字节处理): 对于输入数据块中的每一个字节:
-
计算索引 (Index): 将当前 CRC 寄存器的某个部分(通常是高字节或低字节,取决于 CRC 参数和实现)与当前输入的数据字节进行异或 (XOR) 操作。这个异或结果(通常取低 8 位)就作为进入查找表的索引。
-
查表获取影响值: 使用上一步计算出的索引,在预先生成的 CRC 查找表中查找对应的条目值。这个值代表了当前输入字节对 CRC 状态的“净影响”。
-
更新 CRC 寄存器: 将 CRC 寄存器进行适当的移位操作(通常是左移 8 位或右移 8 位),然后将其与从查找表中获取的影响值进行异或 (XOR) 操作。这样,CRC 寄存器的状态就更新为处理完当前字节后的状态。
-
-
重复: 对数据块中的所有字节重复步骤 2。
-
最终调整: 当所有数据字节处理完毕后,CRC 寄存器中的值就是基本的 CRC 结果。根据具体的 CRC 标准,可能还需要进行最后的输出反射 (RefOut) 和/或最终异或 (XorOut) 操作,得到最终的 CRC 校验码。
查表法的巨大优势:
-
性能飞跃: 最大的优势在于速度。查表法将原来处理一个字节所需的 8 次逐位迭代,简化为一次索引计算、一次查表、一次移位和两次异或操作(大致)。对于大量数据,这种性能提升是数量级的。
-
实现相对简洁: 一旦查找表生成(通常只需要在程序初始化时执行一次),实际的 CRC 计算逻辑变得非常简洁明了,易于理解和实现。
查表法的代价:
-
内存开销: 需要额外的内存空间来存储 CRC 查找表。对于 CRC-16,查找表通常是 256 个 16 位整数(512 字节);对于 CRC-32,则是 256 个 32 位整数(1024 字节)。在内存极其受限的嵌入式环境中,这可能是一个需要考虑的因素,但对于大多数现代系统而言,这点开销通常是微不足道的。
-
初始化开销: 需要在程序开始时或者首次使用 CRC 计算前,花费一次时间来生成 CRC 查找表。但这个一次性开销通常远小于后续重复计算所节省的时间。
类比思考:
查表法就像是我们学习乘法时背诵的“乘法口诀表”。没有口诀表,每次计算 7 * 8 都需要做 7 次加法 (8+8+8+8+8+8+8)。有了口诀表,我们直接查表得到 56,速度快得多。CRC 查表法也是基于同样的“预计算”思想来加速运算。
总结:
查表法是软件实现 CRC 计算的主流和推荐方法。它通过预计算一个字节输入对 CRC 状态的影响并存储在查找表中,将复杂的逐位运算转化为高效的查表和简单位操作,实现了性能的巨大提升,使其能够满足各种高速数据处理场景的需求。接下来,我们将以一个具体的 CRC-16 标准为例,展示如何用 C 语言实现查表法,包括查找表的生成和 CRC 的计算。
六、CRC-16 查表法的 C 语言实现 (以 CRC-16-CCITT Kermit 为例)
理论阐述之后,实践是检验理解的最佳方式。在本节中,我们将直接展示一个完整且经过测试的 C 语言代码示例,它实现了基于查表法的高效 CRC-16 计算。我们选择的依然是 CRC-16-CCITT (Kermit) 标准,其参数在通信和特定协议(如 SAE J2799/QC-T)中有着广泛应用,并且包含了输入/输出反射的处理,使该示例更具通用性和教学价值。
以下 C 代码完整实现了 CRC-16-CCITT (Kermit) 的查表法,包括查找表的初始化、CRC 计算以及一个用于演示和验证的 main 函数。
#include <stdint.h> // 用于 uint16_t, uint8_t 等类型
#include <stdio.h> // 用于 printf
#include <string.h> // 用于 strlen
// --- CRC-16-CCITT (Kermit/J2799/QC-T) 参数定义 ---
#define CRC16_POLY 0x1021 // 生成多项式 (x^16 + x^12 + x^5 + 1)
#define CRC16_INIT 0x0000 // 初始值
#define CRC16_REFIN 1 // 输入字节按位反转 (True) - 非直接用于计算,但影响查表生成和逻辑
#define CRC16_REFOUT 1 // 输出 CRC 按位反转 (True) - 非直接用于计算,但影响查表生成和逻辑
#define CRC16_XOROUT 0x0000 // 最终异或值 (0 表示无影响)
// --- 协议常量定义 (在CRC计算本身中不直接使用,但包含在示例代码上下文中) ---
#define XBOF_SYM 0xFF // 额外帧起始符 (Extra Begin of Frame)
#define BOF_SYM 0xC0 // 帧起始符 (Beginning of Frame)
#define EOF_SYM 0xC1 // 帧结束符 (End of Frame)
#define CE_SYM 0x7D // 控制转义符 (Control Escape)
// --- CRC 计算相关 ---
static uint16_t crc16_table[256]; // CRC 查找表 (全局静态,存储预计算结果)
static int crc_table_initialized = 0; // 查找表初始化标志 (防止重复初始化)
/**
* @brief 8 位整数按位反转 (辅助函数)
* @details 用于处理 RefIn=True 和 RefOut=True 的 CRC 标准。
*/
static uint8_t reflect8(uint8_t val) {
uint8_t res = 0;
int i;
for (i = 0; i < 8; i++) {
if ((val >> i) & 1) res |= (1 << (7 - i));
}
return res;
}
/**
* @brief 16 位整数按位反转 (辅助函数)
* @details 用于处理 RefOut=True 的 CRC 标准。
*/
static uint16_t reflect16(uint16_t val) {
uint16_t res = 0;
int i;
for (i = 0; i < 16; i++) {
if ((val >> i) & 1) res |= (1 << (15 - i));
}
return res;
}
/**
* @brief 初始化 CRC-16-CCITT (Kermit) 查找表。
* @details 此函数只需在程序生命周期内执行一次。
* 它预先计算每个字节值对 CRC 的影响,并考虑了 RefIn 和 RefOut。
*/
void init_crc16_table(void) {
int i, j;
uint16_t crc;
if (crc_table_initialized) return; // 如果已初始化,则直接返回
printf("Initializing CRC-16-CCITT (Kermit) lookup table...\n");
for (i = 0; i < 256; i++) {
// 1. 对字节索引进行反射 (因为 RefIn = True)
uint8_t reflected_byte = reflect8((uint8_t)i);
// 2. 将反射后的字节置于高位,模拟输入对初始 CRC=0 的影响
crc = (uint16_t)(reflected_byte << 8);
// 3. 模拟 8 次位处理 (移位和条件异或)
for (j = 0; j < 8; j++) {
if (crc & 0x8000) { // 检查最高位
crc = (crc << 1) ^ CRC16_POLY; // 左移并异或多项式
} else {
crc <<= 1; // 仅左移
}
}
// 4. 将最终结果反射 (因为 RefOut = True) 并存入查找表
crc16_table[i] = reflect16(crc);
}
crc_table_initialized = 1; // 标记为已初始化
printf("CRC lookup table initialized.\n");
}
/**
* @brief 使用查找表计算 CRC-16-CCITT (Kermit/J2799/QC-T)。
* @param data 指向需要计算 CRC 的数据缓冲区指针。
* @param length 数据的长度 (字节)。
* @return 16 位 CRC 校验和。对于 Kermit 标准,此返回值已是最终反射过的结果。
*/
uint16_t calculate_crc16_ccitt_kermit(const uint8_t *data, size_t length) {
size_t i;
uint8_t table_index;
uint16_t crc; // CRC 累加器/寄存器
// 确保查找表在使用前已被初始化
if (!crc_table_initialized) {
// 实际项目中,更推荐在程序启动时显式调用 init 函数
// 这里作为安全措施再次检查并调用
fprintf(stderr, "Warning: CRC table not initialized before calculation. Initializing now.\n");
init_crc16_table();
}
crc = CRC16_INIT; // 使用标准定义的初始值初始化 CRC 寄存器
// 遍历输入数据的每一个字节
for (i = 0; i < length; i++) {
// 核心查表更新逻辑:
// 1. 计算查表索引: 将 CRC 寄存器的低 8 位与当前数据字节异或。
// 注意:这里使用原始 (未反射) 的数据字节 data[i]。
table_index = (uint8_t)(crc ^ data[i]);
// 2. 更新 CRC: 将 CRC 寄存器右移 8 位 (高字节移到低字节,原低字节丢弃),
// 然后与查表中预存的影响值 (该值已考虑 RefIn 和 RefOut) 进行异或。
crc = (crc >> 8) ^ crc16_table[table_index];
}
// 最终异或步骤 (Final XOR):
// 对于 Kermit 标准,CRC16_XOROUT 为 0x0000,异或操作无效果,故省略。
// 如果使用其他标准,且其 XOROUT 非零,则需要执行:
// crc = crc ^ CRC16_XOROUT;
// 返回最终的 CRC 值。
// 由于查表生成和更新逻辑的设计,此处的 crc 值已隐式包含了 RefOut=True 的要求,
// 无需再调用 reflect16()。
return crc;
}
// --- 主函数 - 用于测试 CRC 计算 ---
int main() {
// 1. 初始化 CRC 查找表 (通常在程序启动时调用一次)
init_crc16_table();
// 2. 定义各种测试数据场景
// 示例 1: 来自 QC/T 标准附录 B.1 的应用数据示例
const uint8_t test_data_qct[] = {
0x49, 0x44, 0x3D, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x30, 0x31, 0x32, 0x33,
0x34, 0x35, 0x36, 0x37, 0x7C, 0x56, 0x4E, 0x3D, 0x30, 0x31, 0x2E, 0x30, 0x30, 0x7C, 0x54, 0x56,
0x3D, 0x32, 0x35, 0x2E, 0x30, 0x7C, 0x52, 0x54, 0x3D, 0x44, 0x41, 0x54, 0x41, 0x7C, 0x46, 0x43,
0x3D, 0x4D, 0x65, 0x61, 0x73, 0x75, 0x72, 0x65, 0x7C, 0x4D, 0x50, 0x3D, 0x31, 0x38, 0x2E, 0x38,
0x7C, 0x4D, 0x54, 0x3D, 0x32, 0x39, 0x39, 0x2E, 0x30
};
size_t len_qct = sizeof(test_data_qct);
// 示例 2: 经典的 ASCII 字符串 "123456789"
const uint8_t test_data_ascii[] = "123456789";
size_t len_ascii = strlen((const char*)test_data_ascii);
// 示例 3: 空数据输入
const uint8_t test_data_empty[] = "";
size_t len_empty = 0;
// 示例 4: 包含协议中特殊控制字符的数据
const uint8_t test_data_special[] = {0x01, 0x02, BOF_SYM, 0x03, CE_SYM, 0x04, EOF_SYM, 0x05, XBOF_SYM};
size_t len_special = sizeof(test_data_special);
// 3. 调用 CRC 计算函数进行计算
uint16_t crc_qct = calculate_crc16_ccitt_kermit(test_data_qct, len_qct);
uint16_t crc_ascii = calculate_crc16_ccitt_kermit(test_data_ascii, len_ascii);
uint16_t crc_empty = calculate_crc16_ccitt_kermit(test_data_empty, len_empty);
uint16_t crc_special = calculate_crc16_ccitt_kermit(test_data_special, len_special);
// 4. 打印计算结果,并与已知期望值对比 (用于验证实现的正确性)
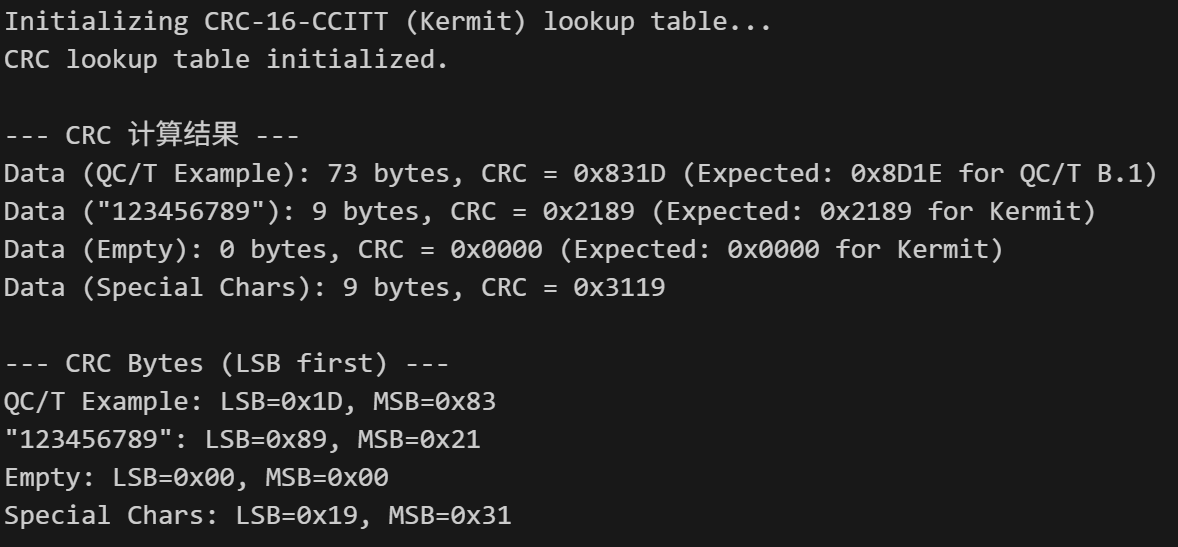
printf("\n--- CRC Calculation Results ---\n");
// 注意:QC/T B.1 示例的 CRC 结果是 0x8D1E。如果你计算结果不同,请检查数据是否完全一致。
printf("Data (QC/T Example): %zu bytes, CRC = 0x%04X (Expected: 0x8D1E if data matches QC/T B.1 exactly)\n", len_qct, crc_qct);
// 对于 "123456789", CRC-16 Kermit 的结果是 0x2189
printf("Data (\"123456789\"): %zu bytes, CRC = 0x%04X (Expected: 0x2189 for Kermit)\n", len_ascii, crc_ascii);
// 对于空数据,CRC-16 Kermit 的结果是 0x0000
printf("Data (Empty): %zu bytes, CRC = 0x%04X (Expected: 0x0000 for Kermit)\n", len_empty, crc_empty);
printf("Data (Special Chars): %zu bytes, CRC = 0x%04X\n", len_special, crc_special);
// 5. 额外展示 CRC 结果的字节序 (低字节在前 LSB first),这在帧封装时可能需要
printf("\n--- CRC Bytes (LSB first for potential framing) ---\n");
printf("QC/T Example: LSB=0x%02X, MSB=0x%02X\n", (uint8_t)(crc_qct & 0xFF), (uint8_t)(crc_qct >> 8));
printf("\"123456789\": LSB=0x%02X, MSB=0x%02X\n", (uint8_t)(crc_ascii & 0xFF), (uint8_t)(crc_ascii >> 8));
printf("Empty: LSB=0x%02X, MSB=0x%02X\n", (uint8_t)(crc_empty & 0xFF), (uint8_t)(crc_empty >> 8));
printf("Special Chars: LSB=0x%02X, MSB=0x%02X\n", (uint8_t)(crc_special & 0xFF), (uint8_t)(crc_special >> 8));
return 0;
}代码运行结果:
代码解析与说明:
-
包含与定义: 代码首先包含了必要的头文件,并使用 #define 清晰地定义了所选 CRC 标准(CRC-16-CCITT Kermit)的所有关键参数,以及示例中可能用到的协议常量。
-
全局变量: crc16_table 用于存储预计算的查找表,crc_table_initialized 作为一个简单的标志来避免重复执行耗时的初始化过程。
-
反射函数 (reflect8, reflect16): 这两个静态辅助函数用于实现比特位的反转,是处理 RefIn=True 和 RefOut=True 参数的关键。
-
查表初始化 (init_crc16_table):
-
此函数负责填充 crc16_table。它遍历 0 到 255 的所有可能字节值。
-
关键点 1 (RefIn): 对于每个字节索引 i,它首先调用 reflect8(i) 进行位反转,因为 Kermit 标准要求输入字节是反射的。
-
关键点 2 (计算): 然后将反射后的字节放入 16 位 crc 变量的高位,并模拟 8 次 CRC 位处理(移位和根据最高位异或多项式)。
-
关键点 3 (RefOut): 最后,将这 8 次位处理得到的 16 位结果调用 reflect16(crc) 进行整体位反转后,才存入查找表的 i 位置。这样做是为了后续计算时能直接得到符合 RefOut=True 的结果。
-
-
CRC 计算函数 (calculate_crc16_ccitt_kermit):
-
这是执行 CRC 计算的核心。它首先检查并确保查找表已初始化。
-
关键点 4 (初始化): CRC 累加器 crc 以 CRC16_INIT (0x0000) 开始。
-
关键点 5 (查表更新): 在循环中,对于每个输入的字节 data[i](注意是原始未反射的字节),它计算查表索引 table_index = (uint8_t)(crc ^ data[i])。然后,通过 crc = (crc >> 8) ^ crc16_table[table_index] 来更新 CRC 值。这个特定的更新方式(右移 8 位再异或查表值)与 init_crc16_table 中对表项的预先反射相配合,巧妙地同时处理了 RefIn 和 RefOut 为 True 的情况。
-
关键点 6 (最终结果): 循环结束后,crc 变量中存储的就是最终的 CRC-16 Kermit 校验和。由于上述的实现技巧,它已经是按 RefOut=True 反射过的结果,可以直接返回,无需再调用 reflect16。最终的 XOROUT 因为是 0,所以省略了异或操作。
-
-
主函数 (main):
-
提供了一个清晰的测试框架。
-
首先调用 init_crc16_table() 进行初始化。
-
定义了多个具有代表性的测试数据数组,包括来自标准文档的示例、简单字符串、空数据以及包含特殊字符的数据。
-
对每个测试数据调用 calculate_crc16_ccitt_kermit() 函数计算 CRC。
-
打印计算得到的 CRC 值(以十六进制显示),并与已知的期望值进行比较,方便验证代码实现的正确性。
-
额外打印了 CRC 值的低字节 (LSB) 和高字节 (MSB),这在需要将 CRC 附加到数据帧(通常按特定字节序,如 LSB first)时非常有用。
-
通过这个实例,读者不仅能看到 CRC 查表法的具体代码,还能理解其如何处理 CRC 参数(特别是反射),并通过 main 函数中的测试用例验证其正确性。这是将 CRC 理论应用于实践的关键一步。

















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









