







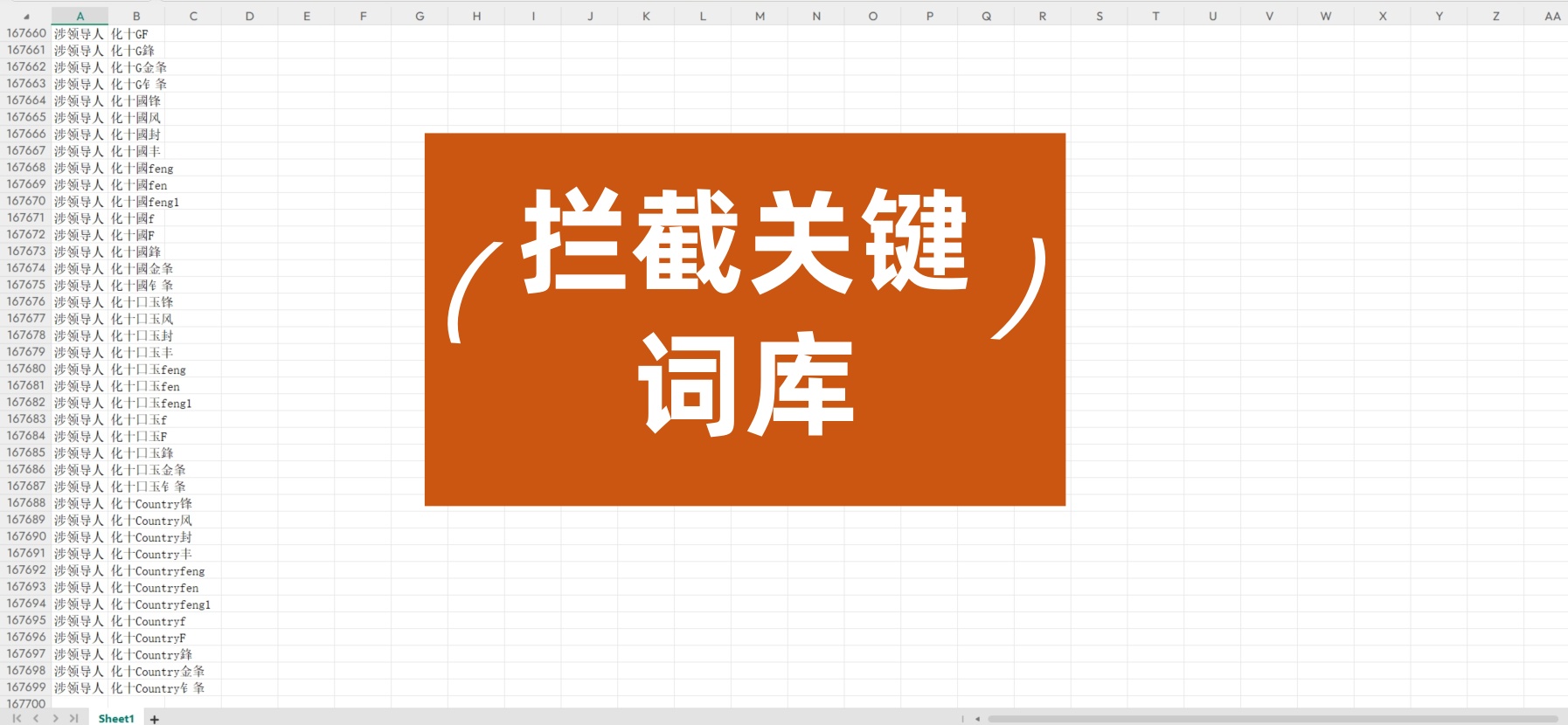
一、大模型备案关键词不同地区要求不同
如广州等一些地区,需要针对《生成式人工智能服务安全基本要求》 A1、A2中的17类别完成关键词,且总量要求在一万以上。企业需要围绕这 17 类关键词,建立起全面且精准的拦截体系。如浙江涉及《生成式人工智能服务安全基本要求》附录 A 中的 31 类关键词拦截,总量同样要求达到 1 万以上。
其中如有的地区的要求也是涉及《生成式人工智能服务安全基本要求》附录 A 中的 31 类关键词拦截。这意味着在浙江和一些地区,企业不仅要保证关键词数量达标,还需确保每个类别都具备足够的覆盖度。
北京的拦截关键词要求更加严格。可参照北京市网信办发布的《大模型内容安全审核指引》,这一要求源于其作为全国政治中心、文化中心和国际交往中心的特殊定位。
二、大模型备案不同地区流程不同
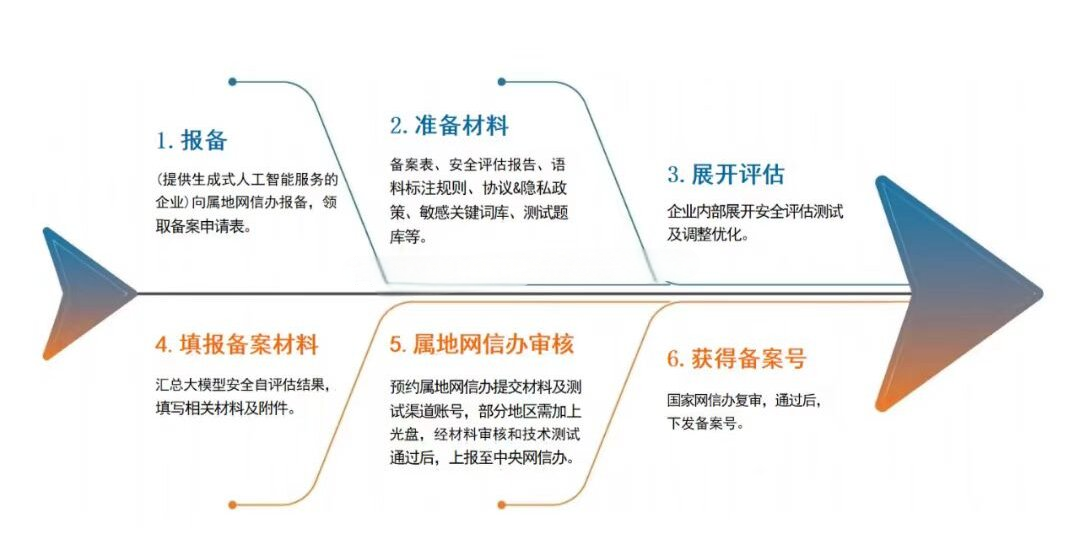
据我所了解有一些区域的大模型备案流程是这样子的:
演示→领取申请表→然后根据申请表进行写材料→编写好材料给属地网信办→如果属地网信办有反馈意见我们就按意见进行修改→前面材料通过之后,属地网信办测试→通过属地网信办的测试,就到中央网信办处审核→然后就开我们的评审会啦→最后我们就等待公示就好了
上海、浙江、福建等区域就是可以线上申请完成大模型备案的。而北京则是全程是线下完成大模型备案。
三、大模型备案材料
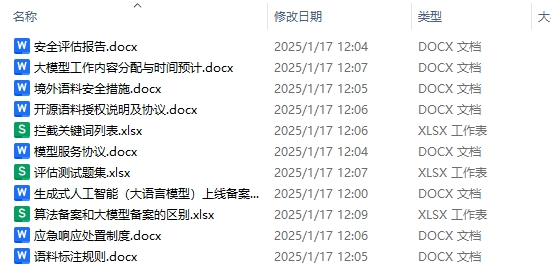
首先是大模型上线备案表,要填清模型名称、功能、适用人群、服务范围,阐述模型研制情况,像训练算力、语料来源等,说明服务与安全防范措施,附上安全评估情况,并做真实性承诺 。
还需安全评估报告,从语料安全、模型安全、安全措施等方面全面评估。模型服务协议明确服务范围、双方权利义务、数据使用保护等条款。语料标注规则介绍标注团队资质、细则、流程等。拦截关键词列表不少于 1 万个,覆盖各类风险。最后是评估测试题集,涵盖生成内容、拒答内容、非拒答测试题库


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









