







一、可合法克隆的网站类型
1. 开源项目克隆(学习用途)
- 典型案例:
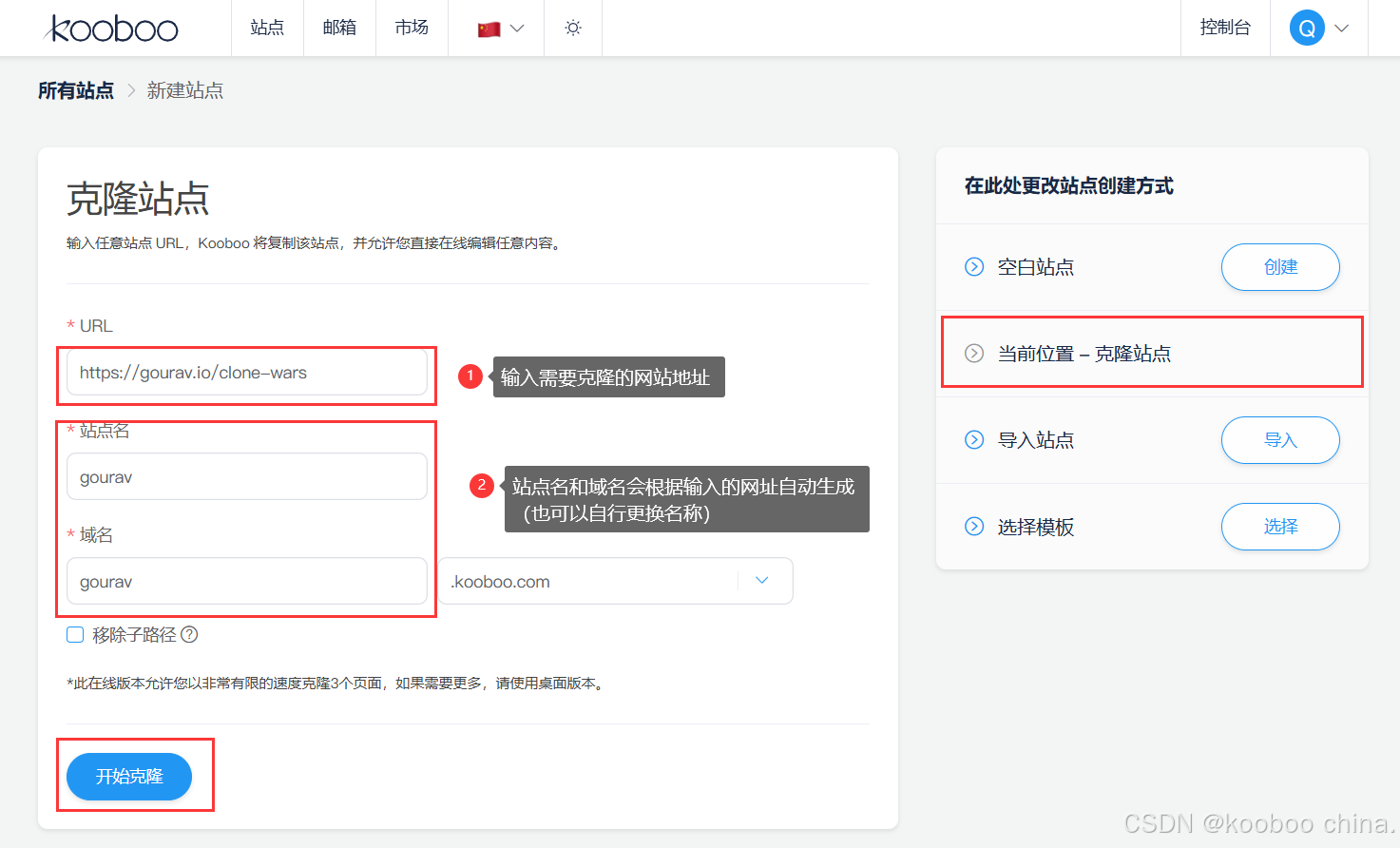
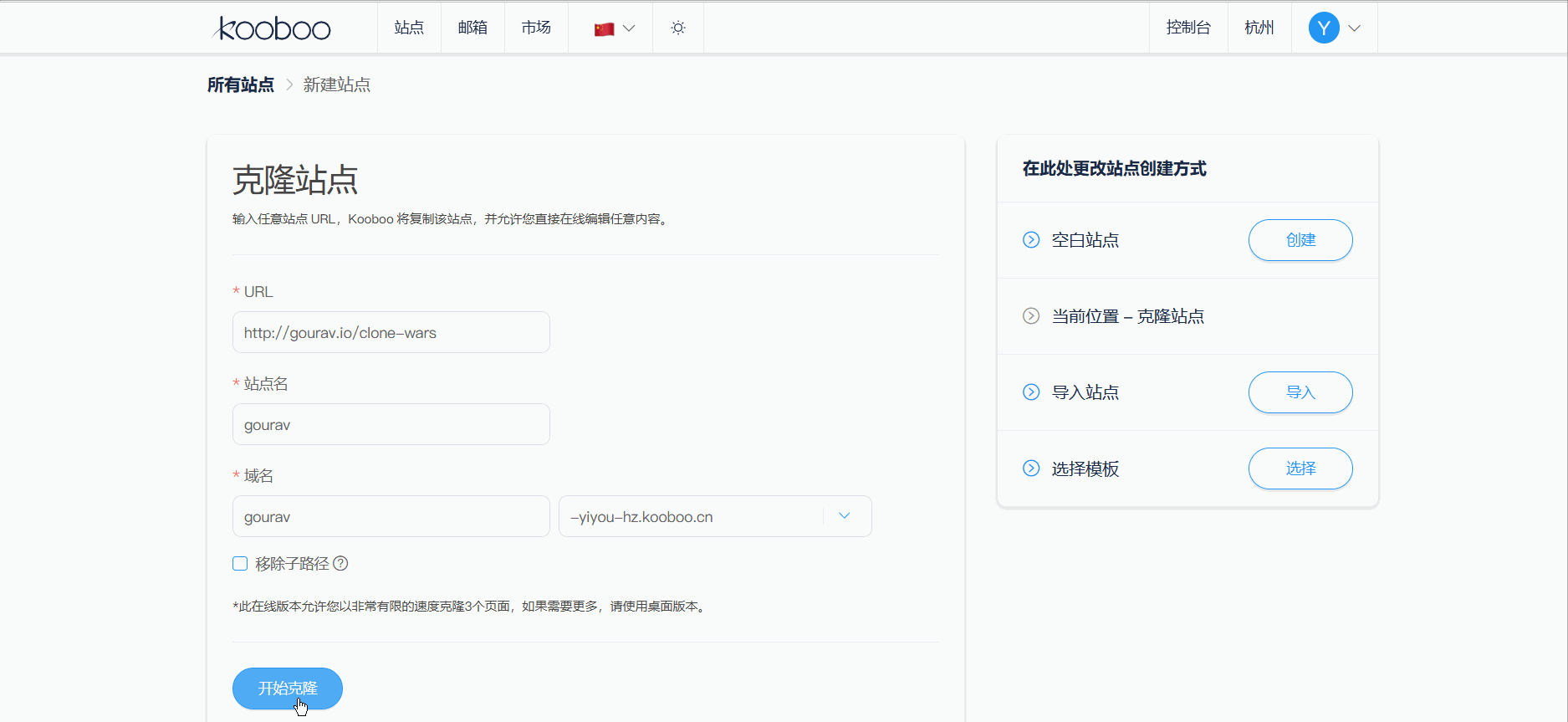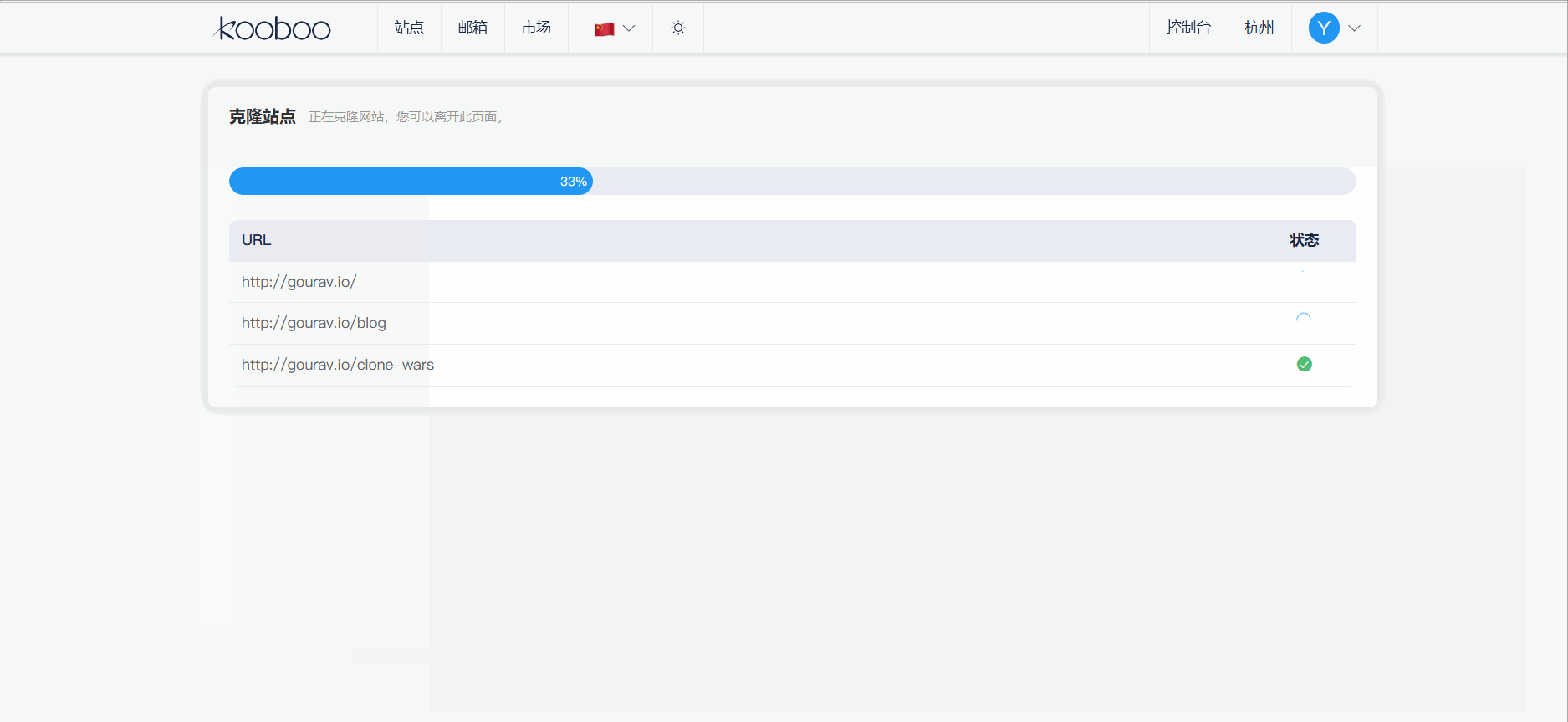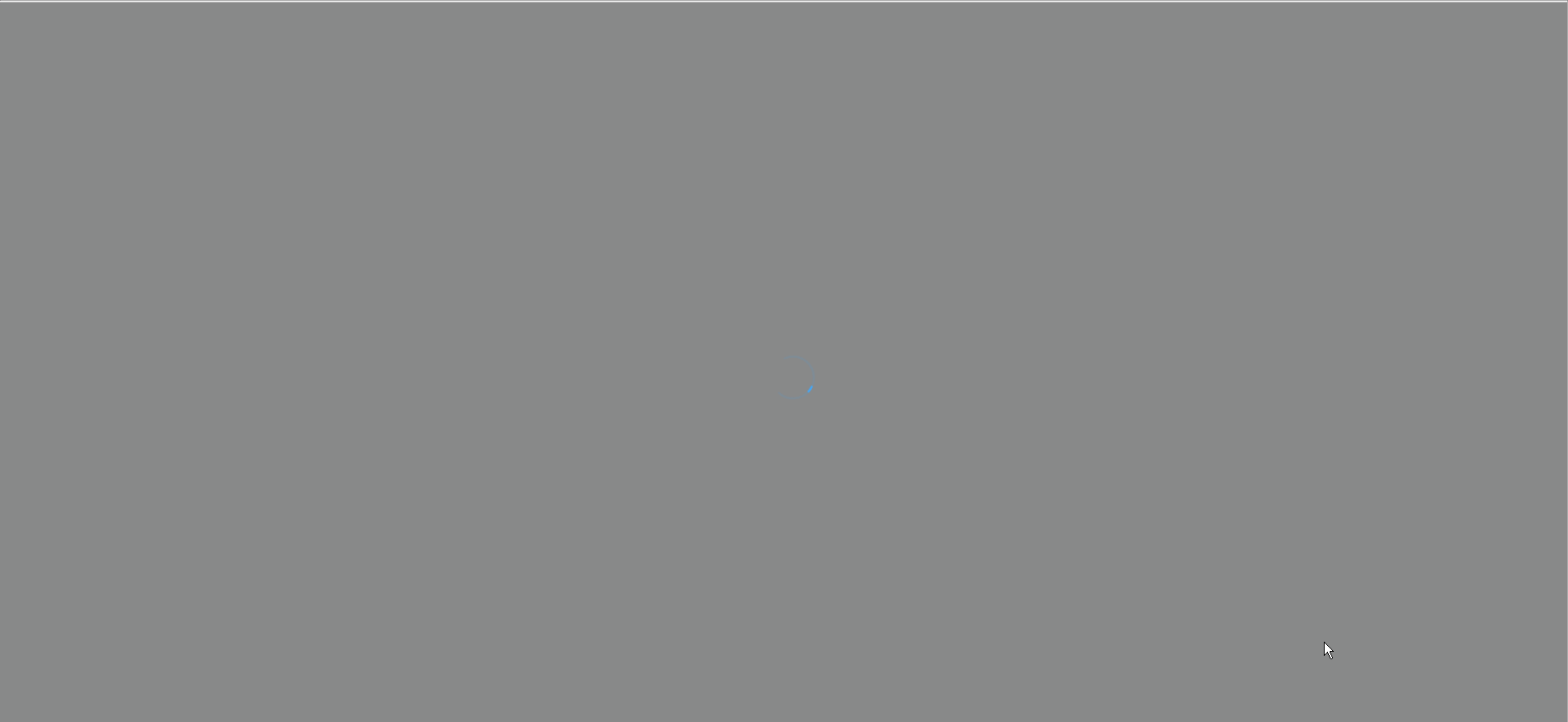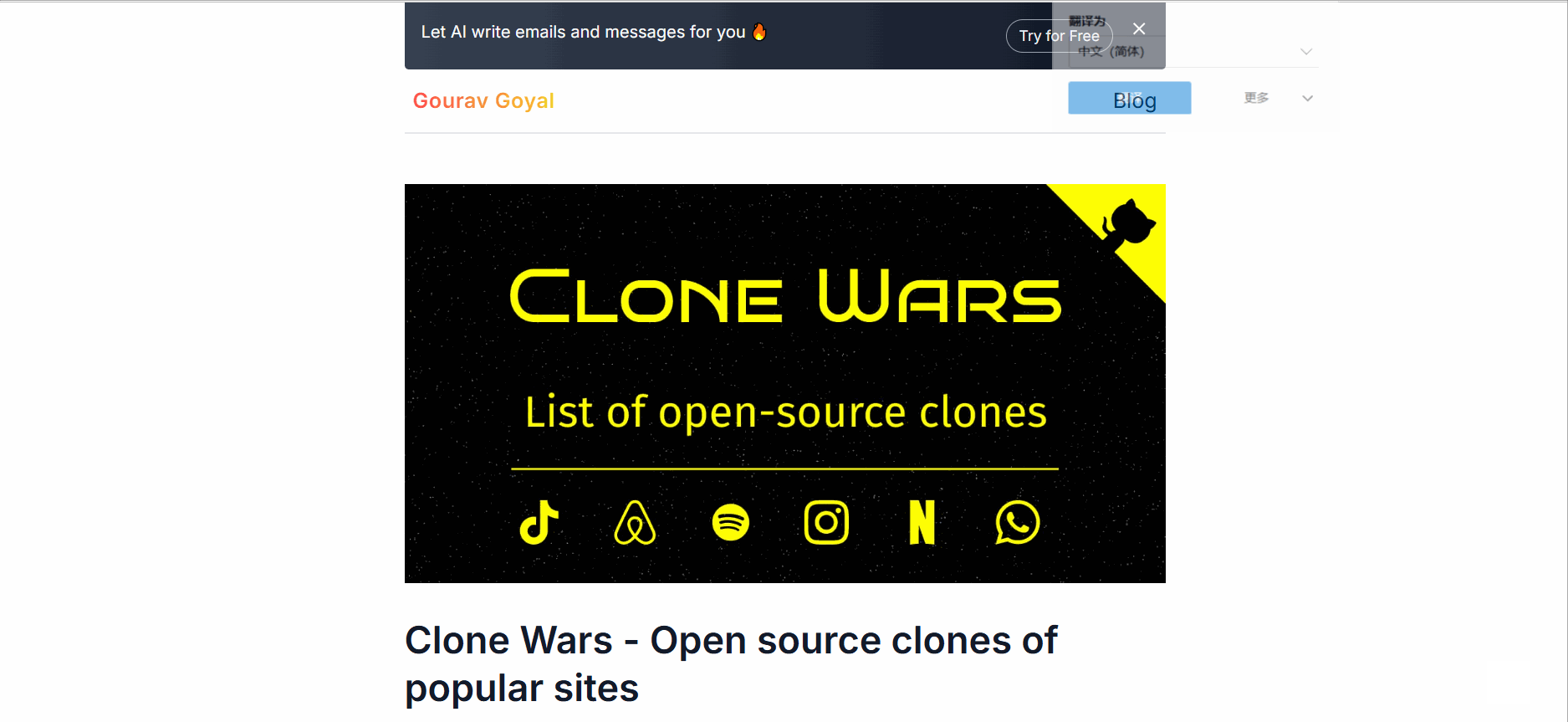
- 合法性:开源项目遵循 MIT、Apache 等许可,允许非商业学习,但需保留版权声明。
2. 无版权声明的静态网站
- 适用场景:个人博客、非营利组织网站(如公益机构、教育平台)、政府公开信息页面(需确认版权归属)。
- 操作方式:使用浏览器开发者工具或爬虫工具(如 HTTrack)下载 HTML、CSS、图片等静态资源,仅用于本地学习或技术研究。
3. 企业公开的 “克隆示例”
- 典型案例:华为 “手机克隆” 工具(数据迁移)、云克隆科技(科研试剂官网)等,其官网展示内容可用于非商业性技术分析(需避免复制商标、专利内容)。
4. 公益或教育性质的网站
- 示例:学术论文平台(如 arXiv)、开源社区论坛(如 Stack Overflow 克隆版),克隆后用于教学或技术研究(需遵守平台用户协议)。
二、需谨慎克隆的网站(高风险)
| 网站类型 | 风险点 |
|---|---|
| 商业盈利网站 | 复制商品图片、文字描述可能侵犯著作权(如 EXDOLL 人偶官网)。 |
| 用户数据敏感型网站 | 涉及登录、支付等功能(如银行、电商),克隆后端逻辑可能触犯《网络安全法》。 |
| 动态交互型网站 | 依赖后端 API(如社交媒体),克隆前端无法实现真实功能,且可能触发反爬机制。 |
| AI 生成内容平台 | 克隆声音、图像(如 MyVocal.AI)涉及隐私泄露和深度伪造风险(违反《个人信息保护法》)。 |
三、克隆的法律边界与建议
-
合法前提:
- 非商业用途:仅限学习、研究,不得用于盈利或误导公众。
- 明确授权:克隆前确认网站是否提供开源许可(如 GitHub 项目)或明确放弃版权(如 CC0 协议)。
- 内容原创:克隆前端结构后,替换所有原创内容(文字、图片),避免直接复制。
-
技术合规:
- 遵守 robots 协议:避免爬取禁止访问的页面(如
/robots.txt声明)。 - 静态资源克隆:仅下载公开可见的前端文件,不侵入服务器获取后端代码。
- 开源工具优先:使用 Goclone、HTTrack 等合规工具,避免逆向工程或绕过反爬措施。
- 遵守 robots 协议:避免爬取禁止访问的页面(如
-
典型合法场景:
- 学习前端布局:克隆 Clone-Wars 中的 Netflix 界面,学习响应式设计。
- 离线文档备份:克隆政府公开政策页面(如法律法规),用于本地查阅。
- 开源项目二次开发:基于 Matomo(Google Analytics 克隆版)定制企业数据分析工具(需遵循开源协议)。
四、总结:可克隆的网站清单
| 网站类型 | 示例网站(克隆用途) | 合法性依据 |
|---|---|---|
| 开源项目克隆 | GitHub 上的 Clone-Wars(学习全栈开发) | MIT 许可,非商业用途 |
| 静态展示型网站 | 个人博客、公益组织官网(技术练习) | 无版权声明或默认允许非商业复制 |
| 企业公开技术案例 | 华为手机克隆指南(界面设计参考) | 公开内容,合理使用原则 |
| 教育 / 学术网站 | arXiv 论文平台(离线学习) | 知识共享许可(CC BY-NC) |
| 小游戏 / 工具克隆 | 2048、JSPaint(前端交互练习) | 开源代码,允许学习模仿 |
五、避坑指南
- 禁止克隆:
✘ 涉及用户隐私的网站(如社交平台、电商)。
✘ 加密或混淆的商业网站(如在线游戏、付费内容平台)。
✘ 政府、军事等敏感网站(违反《网络安全法》)。 - 安全建议:
✓ 克隆前检查网站底部的版权声明(如 “All rights reserved” 需谨慎)。
✓ 使用 “网页另存为” 或合规爬虫工具,避免抓取动态数据。
✓ 在克隆站点显著位置标注 “学习示例,非商业用途”。
结论:克隆的核心原则
“克隆结构,原创内容;学习用途,规避商用;尊重版权,技术向善。”
合法的网站克隆是技术学习的重要途径,但需严格区分 “模仿表现层” 与 “复制知识产权”。建议优先选择开源项目(如 Clone-Wars)或明确授权的资源,通过自主创新实现功能迭代,而非直接复制。任何商业用途的克隆均需获得权利人书面许可,否则面临法律风险。


















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









