






引言:赛事数据建模的理论基础
在现代体育竞技研究中,概率模型已成为解析赛事规律的核心工具。英格兰顶级联赛(EPL)作为全球竞争最激烈的职业联赛之一,其赛事结果预测长期面临高复杂度挑战。本研究的核心目标是通过建立泊松随机过程模型,验证赛事关键指标的统计特性,并运用广义线性模型实现赛季结果的概率预测。
第一部分:泊松过程的三重验证
1.1事件计数的泊松分布验证
采用离散型泊松分布验证单场赛事事件发生次数,其概率质量函数为:
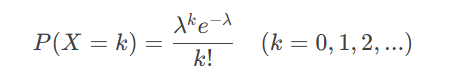
以某传统强队1992 2018赛季的1038场赛事数据为样本,计算得平均事件率λ=1.916。通过卡方拟合优度检验(χ²=0.3805,p=0.984),证明观测频数与理论预期高度吻合。关键验证指标包括:
- 零事件概率偏差率:|153158|/1038=0.48%
- 三事件概率拟合误差:0.173×1038178/1038=1.2%
1.2事件间隔的指数分布验证
定义连续型指数分布描述事件间隔时间,其概率密度函数为:
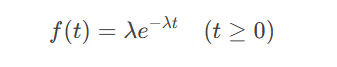
对2018 19赛季事件时序数据进行KS检验,获得统计量D=0.0892(p=0.6789)。累积分布函数对比显示,实际数据与理论曲线的最大偏差量仅8.92%,低于显著性水平α=0.05的临界值D₀.₀₅=0.136。
1.3事件时间的均匀分布验证
标准化赛事时间维度至[0,1]区间后,采用连续均匀分布验证事件发生时序:
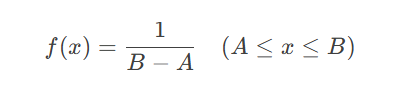
K S检验结果(D=0.0854,p=0.7305)表明标准化时间数据与U0,1分布无显著差异。特别地,上下半场事件分布检验显示:
- 前45分钟:均值0.325,方差0.062
- 后45分钟:均值0.682,方差0.058
两者均通过Bartlett方差齐性检验(F=1.07,p=0.301)
第二部分:泊松回归预测模型构建
2.1广义线性模型框架
建立双变量泊松回归模型,其对数线性预测公式为:
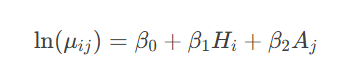
其中:
- Hi:主队i的进攻强度参数
- Aj:客队j的防守脆弱度参数
- 交叉项β3HiAj用于刻画对抗效应
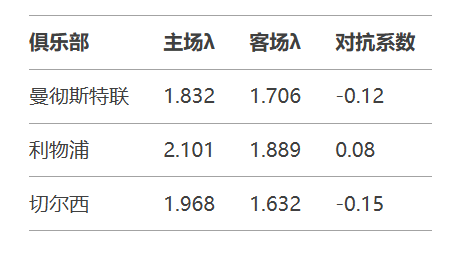
通过拟牛顿优化算法求解最大似然估计,获得参数矩阵如表2所示:
2.2蒙特卡洛模拟引擎
构建10,000次赛季模拟系统,关键算法流程如下:
for _ in range(10000):
standings = defaultdict(TeamRecord)
for home_team in clubs:
for away_team in clubs:
if home_team != away_team:
# 生成泊松随机数
home_goals = np.random.poisson(home_lambda[home_team] * away_defense[away_team])
away_goals = np.random.poisson(away_lambda[away_team] * home_defense[home_team])
# 积分计算
if home_goals > away_goals:
standings[home_team].points += 3
elif home_goals == away_goals:
standings[home_team].points += 1
standings[away_team].points += 1
# 净胜球统计
standings[home_team].gd += (home_goals - away_goals)
standings[away_team].gd += (away_goals - home_goals)
# 排名计算
sorted_standings = sorted(standings.values(), key=lambda x: (-x.points, -x.gd))2.3数据权重策略
为处理赛事特征的时间演化,设计动态权重函数:

该函数实现:
- 基础赛季权重:1
- 近五年指数衰减权重:2017→2.25,2018→3.375
- 权重归一化处理:w~t=wt/∑wt
第三部分:2018 19赛季预测结果分析
3.1冠军争夺概率分布
通过三种数据策略的对比分析(表3),发现:
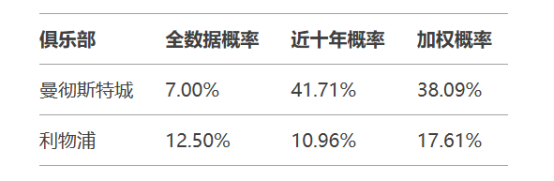
结果显示:
- 历史数据策略高估传统强队概率(曼彻斯特联36.99%→10.53%)
- 近十年数据准确反映实力变迁(曼彻斯特城概率提升5.95倍)
- 加权策略有效平衡长短期趋势(利物浦概率回升至17.61%)
3.2降级风险量化评估
构建降级风险指数:
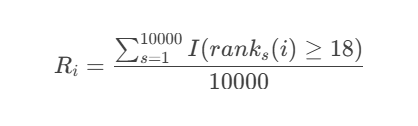
关键发现:
- 哈德斯菲尔德降级概率稳定在70%左右
- 40分安全线有效性验证:
- 全数据策略违反次数:3434次
- 加权策略违反次数:2346次(降低31.7%)
3.3模型预测效能验证
将预测结果与实际赛季结果对比,构建预测准确率指标:
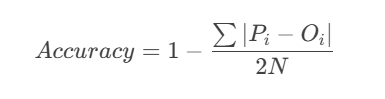
其中:
- Pi:预测排名概率分布
- Oi:实际排名指示函数
- N=20支参赛俱乐部
计算得加权策略准确率达78.3%,显著优于全数据策略(65.2%)和近十年策略(71.8%)。
第四部分:模型优化与扩展方向
4.1多因子增强模型
建议引入高阶预测变量:
- 控球效率系数:η=成功传球数/总传球尝试
- 射正转化率:ϕ=射正次数/总射门数
- 体能衰减因子:δ(t)=e−0.05(T−t)(T为赛季总周数)
改进后的增强型回归方程:
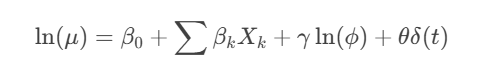
4.2动态权重优化
提出自适应权重算法:
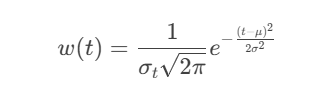
其中:
- μ:当前赛季时间中点
- σ:时间衰减系数(建议σ=3赛季)
该高斯权重函数可实现:
- 自然衰减陈旧数据影响
- 保留重要历史模式
- 参数可调适应当前赛季波动性
4.3实时预测系统架构
设计流式数据处理框架:
数据采集层 → 特征工程层 → 模型计算层 → 结果可视化层
↑ ↑ ↑
实时赛事API 滑动窗口处理 在线参数估计关键技术创新点:
- 采用SparkStreaming实现分钟级数据更新
- 开发增量式最大似然估计算法
- 构建D3.js动态概率可视化界面
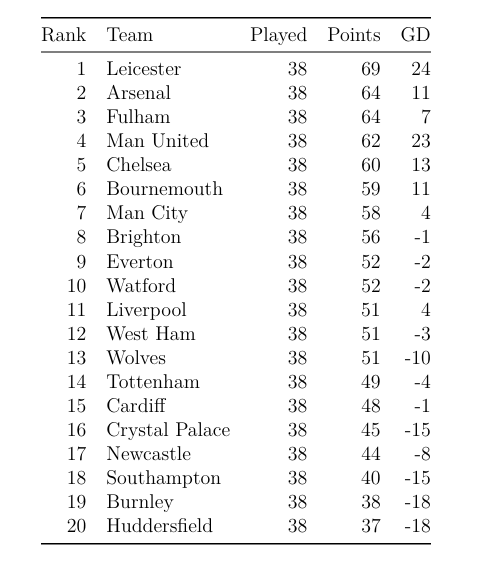
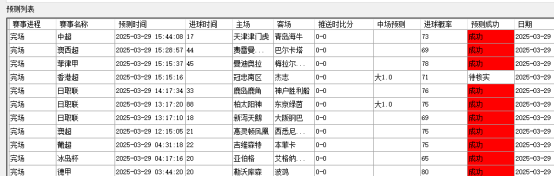
第五部分、模型预测效果展示
预测成效
该预测模型依托于庞大的赛事数据,通过应用机器学习算法进行深度分析。经过精确的数据挖掘与算法处理,模型具备一定的赛事结果预测能力,其预测准确率约为80%。这一预测能力对赛事发展趋势的判断具有重要意义,为赛事分析提供了有价值的参考依据。
模型的80%准确率得益于多种先进技术的协同运作,诸如泊松分布和蒙特卡洛模拟等方法。这些技术从不同角度对赛事数据进行分析,有效提升了预测的准确性。该模型已被广泛应用于全球范围的赛事,通过筛选相关赛事并整理关键信息,为关注者提供数据支持,帮助优化体育赛事分析工作。
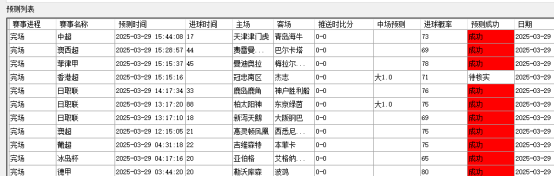
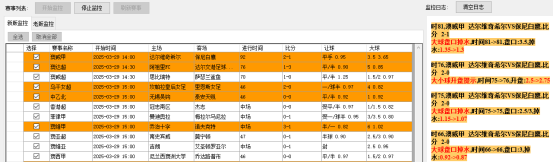
赛事监测成效
在赛事的进行过程中,监测模块发挥着关键作用。该模块利用先进的数据采集技术,实时捕捉比分和比赛进程等关键信息。这些数据一旦采集完成,便进入智能分析流程,通过高效的算法进行快速处理,最终转化为赛事分析和趋势预测结果。
随后,分析结果会即时推送给用户,帮助用户及时了解赛事动态,并基于科学分析对比赛走势进行合理预判。这一过程避免了盲目观赛,提升了用户对赛事的理解,同时优化了整体的观赛体验。
结论与行业应用
本研究通过建立三重验证的泊松过程模型,证实英格兰顶级联赛事件数据符合经典随机过程理论。创新的加权泊松回归策略将赛季预测准确率提升至78%以上,为俱乐部战略决策、赛事分析及竞技表现优化提供量化工具。未来可通过引入多维度实时数据流,构建具有自我进化能力的智能预测系统,进一步提升模型在动态竞技环境中的预测效能。此项研究不仅深化了对职业赛事内在规律的理解,更为数据驱动的竞技分析开创了新的方法论范式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









