



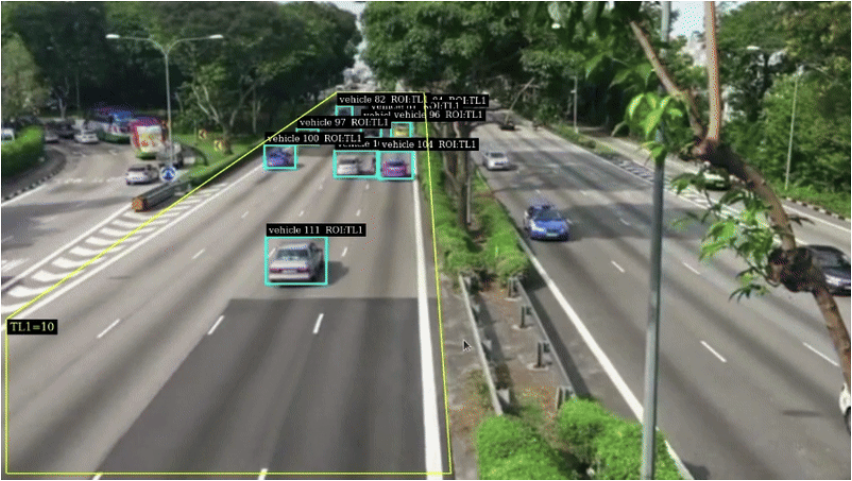
带有 Triton 推理服务器的 Deepstream 应用程序
计算机视觉应用程序通常需要在其生命周期内定期更新。这些更新可能包括修改代码以满足不断变化的业务需求,或更新权重以提高模型准确性。生产级机器学习系统中对高效代码交付工具的需求催生了 MLops 这一快速发展的领域,该领域大量借鉴了传统的软件工程 CI/CD 原则。
边缘设备给部署流程增加了额外的复杂性。首先,需要可靠的协议来保证代码交付到目标设备。其次,相关设备的硬件配置可能多种多样,这会导致潜在的兼容性问题。
在本教程中,我们将探索不可知机器学习系统的概念。接下来,我们将使用 ONNX、Nvidia Triton 和 AWS GreengrassV2 将流量检测模型部署到 Jetson 设备上。
不可知论机器学习
不可知机器学习平台是一个专为兼容性而设计的系统。兼容性可能体现在以下几种形式:
- 硬件无关——设计用于在不同类型的硬件上运行,例如移动、嵌入式和云。硬件无关的机器学习系统应该能够充分利用目标设备上可用的任何加速器(GPU、TPU、FPGA),并且只需进行少量修改。
- 模型无关——能够服务于一系列机器学习模型类型,例如法学硕士 (LLM)、目标检测器和场景分类器。此外,它们还应兼容不同的实现框架,例如 PyTorch、Tensorflow、MXnet 等。
- 与应用程序无关——支持各种应用场景和要求,包括低到高的推理负载、多个并发模型、延迟需求。
机器学习中的互操作性尤其具有挑战性,因为几乎所有神经网络模型都需要专门的硬件或软件优化才能在合理的时间内运行。
为了满足互操作性需求且不影响性能,业内人士合作开发了以下工具:
- ONNX ——ONNX 的全称是开放神经网络交换 (Open Neural Network Exchange),是一个兼容各种硬件平台的开源模型框架。其他框架(例如 PyTorch)中的模型可以在训练后进行转换,并通过 ONNX Runtime 进行部署,以加速推理。
- Nvidia Triton 推理服务器——Triton 作为独立的容器化微服务提供推理功能,并更进一步,为 ONNX 和 Tensorflow 模型提供 Nvidia 芯片组专属优化。Triton 包含用于扩展机器学习系统的内置工具,例如并行推理,并允许同一模型的多个实例同时运行。
建立Triton模型
我们的教程从 RT-DETR 物体检测模型开始。本教程中的模型基于 500 张交通图像的数据集进行了微调,
Triton Inference Server 需要按照以下文件结构设置模型存储库:
<span style="background-color:#f9f9f9"><span style="color:#242424">models_repo
|
+-- 模型名称
|
+-- config.pbtxt
+-- 1
|
+-- 模型.onnx</span></span>目录名称 [1] 表示模型版本,版本越新,该数字就越大。此文件夹包含模型权重,在本例中为 .onnx 文件。用户还必须在 config.pbtxt 文件中定义模型的配置。以下示例适用于 RT-DETR 模型。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">名称:</span> <span style="color:#c41a16">“rtdetr”</span>
<span style="color:#836c28">平台:</span> <span style="color:#c41a16">“onnxruntime_onnx” </span>
<span style="color:#836c28">max_batch_size:</span> <span style="color:#1c00cf">4 </span>
<span style="color:#836c28">default_model_filename:</span> <span style="color:#c41a16">“model.onnx”</span>
<span style="color:#c41a16">输入</span>[
{
<span style="color:#836c28">名称:</span> <span style="color:#c41a16">“input”</span>
<span style="color:#836c28">数据类型:</span> <span style="color:#c41a16">TYPE_FP32</span>
<span style="color:#836c28">格式:</span> <span style="color:#c41a16">FORMAT_NCHW</span>
<span style="color:#836c28">尺寸:</span> [ <span style="color:#1c00cf">3</span> , <span style="color:#1c00cf">640</span> , <span style="color:#1c00cf">640</span> ]
}
]
<span style="color:#c41a16">输出</span>[
{
<span style="color:#836c28">名称:</span> <span style="color:#c41a16">“output”</span>
<span style="color:#836c28">数据类型:</span> <span style="color:#c41a16">TYPE_FP32</span>
<span style="color:#836c28">尺寸:</span> [ <span style="color:#1c00cf">300</span> , <span style="color:#1c00cf">6</span> ]
}
]
<span style="color:#c41a16">实例组</span>[
{
<span style="color:#836c28">种类:</span> <span style="color:#c41a16">KIND_GPU</span>
<span style="color:#836c28">计数:</span> <span style="color:#1c00cf">1 </span>
<span style="color:#836c28">gpus:</span> <span style="color:#1c00cf">0</span>
}
]</span></span>让我们看一下这个文件的内容。
第一部分包含基本详细信息,包括模型名称和权重文件。max_batch_size 参数可以调整为使用动态批处理,这在对多个视频源进行推理时非常有用。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#1c00cf">名称:</span> <span style="color:#c41a16">“rtdetr”</span>
<span style="color:#1c00cf">平台:</span> <span style="color:#c41a16">“onnxruntime_onnx” </span>
<span style="color:#1c00cf">max_batch_size:</span> <span style="color:#1c00cf">1</span>
<span style="color:#1c00cf">默认模型文件名:</span> <span style="color:#c41a16">“model.onnx”</span></span></span>请注意“plattorm”字段,该字段需要一个由所需执行运行时和模型文件格式组成的字符串。每个模型类型都有其独有的格式。例如,TensorRT 模型将使用以下内容:
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#1c00cf">名称:</span> <span style="color:#c41a16">“rtdetr”</span>
<span style="color:#1c00cf">平台:</span> <span style="color:#c41a16">“tensorrt_plan” </span>
<span style="color:#1c00cf">max_batch_size:</span> <span style="color:#1c00cf">1</span>
<span style="color:#1c00cf">默认模型文件名:</span> <span style="color:#c41a16">“model_b1_gpu0_fp16.engine”</span></span></span>下一节定义输入和输出张量的形状。在本例中,模型期望输入一个 32 位浮点 640 x 640 的 RGB 图像。张量的顺序为颜色通道 → 高度 → 宽度。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#c41a16">输入</span>[
{
<span style="color:#836c28">名称:</span> “<span style="color:#c41a16">输入”</span>
<span style="color:#836c28">数据类型</span> :TYPE_FP32<span style="color:#c41a16">格式</span>
<span style="color:#836c28">:</span> <span style="color:#c41a16">FORMAT_NCHW</span><span style="color:#1c00cf">尺寸</span>
<span style="color:#836c28">:</span> [ <span style="color:#1c00cf">3,640,640</span> ] } <span style="color:#1c00cf">]</span>
</span></span>ONNX 后端支持动态批次大小,但并非所有后端都支持。对于固定批次大小,必须在“dims”字段中定义该大小:
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#c41a16">输入</span>[
{
<span style="color:#836c28">name: </span> <span style="color:#c41a16">"inputs" </span>
<span style="color:#836c28">data_type: </span> <span style="color:#c41a16">TYPE_FP32 </span>
<span style="color:#007400"># 此模型遵循高度、宽度、通道顺序</span>
<span style="color:#836c28">dims:</span> [ <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">640</span> , <span style="color:#1c00cf">640</span> , <span style="color:#1c00cf">3</span> ]
}
]</span></span>还必须定义输出形状。RT-DETR 预测前 300 个对象的类别、置信度和四个边界框参数,从而给出 300 x 6 的输出张量形状。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#c41a16">输出</span>[
{
<span style="color:#836c28">名称:</span> “<span style="color:#c41a16">输出”</span>
<span style="color:#836c28">数据类型:</span> <span style="color:#c41a16">TYPE_FP32</span>尺寸
<span style="color:#836c28">:</span> [ <span style="color:#1c00cf">300,6 </span><span style="color:#1c00cf">]</span> }
]
</span></span>如果您不确定模型的输入和输出,请考虑使用模型可视化工具,例如Netron。
最后一部分表示 Triton 应该在设备 GPU 还是 CPU 上运行模型。如果目标设备上有多个 GPU,用户还可以定义使用哪个 GPU。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#c41a16">实例组</span>[
{
<span style="color:#836c28">种类:</span> <span style="color:#c41a16">KIND_GPU</span>
<span style="color:#836c28">数量:</span> <span style="color:#1c00cf">1 </span>
<span style="color:#836c28">gpus:</span> <span style="color:#1c00cf">0</span>
}
]</span></span>兼容的 ONNX 和 Tensorflow 模型可以在运行时选择性地编译为 Nvidia 专有的 TensorRT 格式,以进一步提升性能。此外,模型还可以量化到更低的精度,从而加快推理速度,但对于较大的模型,此过程通常较长(约 45 分钟)。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400">## 可选</span>
<span style="color:#c41a16">优化</span>{ <span style="color:#c41a16">execution_accelerators</span> {
<span style="color:#836c28">gpu_execution_accelerator :</span> [ {
<span style="color:#836c28">name : </span> <span style="color:#c41a16">"tensorrt"</span>
<span style="color:#c41a16">参数</span>{ <span style="color:#836c28">key: </span> <span style="color:#c41a16">"precision_mode"</span> <span style="color:#836c28">值: </span> <span style="color:#c41a16">"FP16"</span> } <span style="color:#007400">#量化权重</span>
}]
}}</span></span>(智能)物联网
2010 年代智能设备的普及带来了一波设备管理平台的浪潮。除了支持无线更新外,这些平台还提供基于角色的访问、设备监控和故障检测等附加工具,使其适合将小型视觉模型安全地部署到边缘。
在本教程中,我们将使用 AWS Greengrass,因为它支持大多数 Windows 和 Linux 设备,包括我们的目标 Jetson AGX Xavier。更重要的是,Greengrass 提供设备身份验证和自动回滚策略等支持功能,以确保我们的代码安全到达。
Greengrass 部署包(称为组件)包含以下项目:
- 工件——源文件包括应用程序代码、模型权重、媒体文件等。可以使用 AWS Lambda 函数将 Docker 容器部署为工件,从托管容器注册表中提取映像。
- Recipes——配置文件,其中包含运行应用程序生命周期事件的指令。用户指定 Shell 命令来安装、运行和关闭工件中包含的应用程序。
首先,我们在 AWS 控制台上创建一个新的 IAM 用户并附加以下权限策略:
- AWSGreengrassFullAccess —授予对 AWS Greengrass 部署服务的访问权限
- AmazonS3FullAccess —授予对存储在 AWS S3 bucket 中的工件的访问权限
在此之后,我们创建一个新的 S3 存储桶并附加以下 GetObject 策略以允许 Greengrass 用户从中提取存储的对象。
<span style="background-color:#f9f9f9"><span style="color:#242424">{
<span style="color:#836c28">“版本” </span>: <span style="color:#c41a16">“2012-10-17” </span>,
<span style="color:#836c28">“声明” </span>: [
{
<span style="color:#836c28">“效果” </span>: <span style="color:#c41a16">“允许” </span>,
<span style="color:#836c28">“委托人” </span>: {
<span style="color:#836c28">“AWS” </span>: <span style="color:#c41a16">“arn:aws:iam :: YOUR_ACCOUNT_ID:user / USER_NAME” </span>
} ,
<span style="color:#836c28">“操作” </span>: <span style="color:#c41a16">“s3:GetObject” </span>,
<span style="color:#836c28">“资源” </span>: <span style="color:#c41a16">“arn:aws:s3 ::: YOUR_BUCKET_NAME / *” </span>
}
]
}</span></span>完成这些后,我们可以继续在目标 Jetson 设备上安装 Greengrass IoT Core软件。安装完成后,Jetson 会注册为属于某个 Thing 组的核心设备,之后我们就可以向其部署 Greengrass 组件了。
重新审视推理管道
我们探索了如何使用 Nvidia Deepstream SDK 实现加速视觉应用。我们将基于 Python 示例,并将以下插件添加到我们的推理管道中:
- Nvinferserver — 初始化 Triton 推理服务器并加载选定的模型。使用 Triton 而不是 Deepstream 的原生nvinfer插件,我们可以在 TensorRT 框架之外使用更多模型。
- Nvtracker——通过为每个检测分配唯一的 ID 来跨帧跟踪对象。持续性对象跟踪允许对移动车辆进行更复杂的分析,例如交通流量。
- Nvdsanalytics — 提供感兴趣区域过滤。在本场景中,我们只关注单向流量,因此将使用此插件来删除不需要的检测。
- Nvmsgconv和Nvmsgbroker —检测元数据将作为 Kafka 消息主题发布,以便进一步进行下游处理。这可能涉及时间序列数据的存储和分析、警报触发器或其他基于云的操作。
此外,我们将修改接收器元素,将边界框可视化结果输出到 RTSP 流,而不是屏幕显示。这一点至关重要,因为 Greengrass 部署的 Deepstream Python 应用无法打开屏幕显示窗口,并且会报错退出。完整的应用程序代码↓
克隆代码库后,压缩源文件夹的内容,并将生成的存档文件上传到上一节中创建的 S3 存储桶中。部署为 Greengrass 组件后,文件中包含的 Deepstream 应用程序将作为子进程启动,进而初始化 ONNX 权重并将其加载到 Triton Server 实例中。
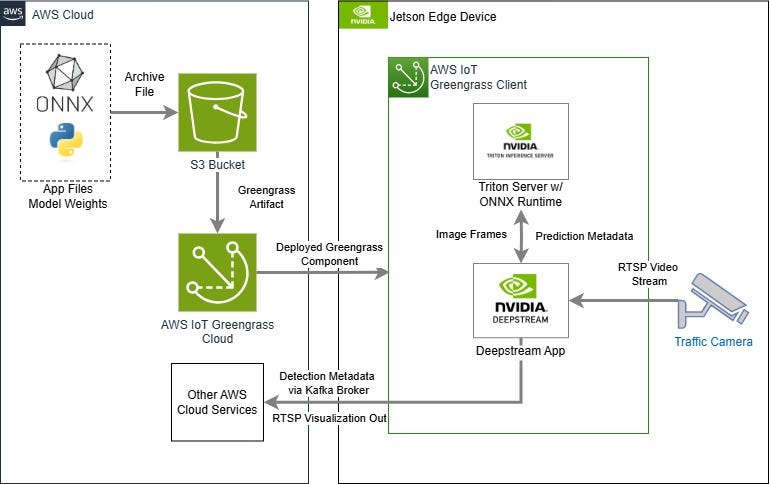
Greengrass 部署架构
如果目标设备缺少 Nvidia GPU,则可以使用与平台无关的库(例如 OpenCV 或 Roboflow Inference)来实现推理流程。详情请参阅我之前的文章。
烹饪风暴
要组装我们的部署包,请在 AWS 控制台上创建一个新的 Greengrass 组件。这将提示用户提供 JSON 或 YAML 格式的组件配方。我们将使用以下配方:
<span style="background-color:#f9f9f9"><span style="color:#242424">{
<span style="color:#836c28">“RecipeFormatVersion” </span>: <span style="color:#c41a16">“2020-01-25” </span>,
<span style="color:#836c28">“ComponentName” </span>: <span style="color:#c41a16">“nvds-awsgg-deployment” </span>,
<span style="color:#836c28">“ComponentVersion” </span>: <span style="color:#c41a16">“1.0.xx” </span>,
<span style="color:#836c28">“ComponentType” </span>: <span style="color:#c41a16">“aws.greengrass.generic” </span>,
<span style="color:#836c28">“ComponentDescription” </span>: <span style="color:#c41a16">“我的第一个 deepstream 应用程序” </span>,
<span style="color:#836c28">“ComponentPublisher” </span>: <span style="color:#c41a16">“Amazon” </span>,
<span style="color:#836c28">“ComponentConfiguration” </span>: {
<span style="color:#836c28">“DefaultConfiguration” </span>: {
<span style="color:#836c28">“ConnString” </span>: <span style="color:#c41a16">“localhost; 9092; quickstart-events” </span>
}
} ,
<span style="color:#836c28">“Manifests” </span>: [
{
<span style="color:#836c28">“Platform” </span>: {
<span style="color:#836c28">“os” </span>: <span style="color:#c41a16">“linux” </span>
} ,
<span style="color:#836c28">“Name” </span>: <span style="color:#c41a16">“Linux” </span>,
<span style="color:#836c28">“Lifecycle” </span>: {
<span style="color:#836c28">“Run” </span>: {
<span style="color:#836c28">“Script” </span>: <span style="color:#c41a16">“#!/bin/bash\ncd {artifacts:decompressedPath} /nvds-aws-gg \npython3 deepstream_app.py -g nvinferserver -c config_infer_primary_rtdetr_triton.yml -i file://$(pwd)/awsgg-example.mp4 --conn-str='{configuration:/ConnString}' --silent -d rtsp" </span>,
<span style="color:#836c28">"RequiresPrivilege" </span>: <span style="color:#aa0d91"><span style="color:#aa0d91">true</span></span>
}
} ,
<span style="color:#836c28">"Artifacts" </span>: [
{
<span style="color:#836c28">"Uri" </span>: <span style="color:#c41a16">"s3://your/s3/uri/package.zip" </span>,
<span style="color:#836c28">"Unarchive" </span>: <span style="color:#c41a16">"ZIP" </span>,
<span style="color:#836c28">"Permission" </span>: {
<span style="color:#836c28">"Read" </span>: <span style="color:#c41a16">"ALL" </span>,
<span style="color:#836c28">"Execute" </span>: <span style="color:#c41a16">"ALL" </span>
}
}
]
}
] ,
<span style="color:#836c28">"Lifecycle" </span>: { }
}</span></span>让我们分解一下这个配方。顶部部分包含组件的通用元数据,包括其名称和版本号。需要注意的是,版本号必须递增才能触发或重新触发未来的部署。我们还定义了一个配置变量,其中包含 Kafka 服务器的连接字符串。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">“RecipeFormatVersion” </span>: <span style="color:#c41a16">“2020-01-25” </span>,
<span style="color:#836c28">“ComponentName” </span>: <span style="color:#c41a16">“nvds-awsgg-deployment” </span>,
<span style="color:#836c28">“ComponentVersion” </span>: <span style="color:#c41a16">“1.0.xx” </span>,
<span style="color:#836c28">“ComponentType” </span>: <span style="color:#c41a16">“aws.greengrass.generic” </span>,
<span style="color:#836c28">“ComponentDescription” </span>: <span style="color:#c41a16">“我的第一个 deepstream 应用程序” </span>,
<span style="color:#836c28">“ComponentPublisher” </span>: <span style="color:#c41a16">“Amazon” </span>,
<span style="color:#836c28">“ComponentConfiguration” </span>: {
<span style="color:#836c28">“DefaultConfiguration” </span>: {
<span style="color:#836c28">“ConnString” </span>: <span style="color:#c41a16">“localhost; 9092; quickstart-events” </span>
}
} ,</span></span>在清单部分,我们通过提供其唯一资源标识符(即 URI)来指示 Greengrass 将 S3 存储桶中的存档文件用作工件。我们将此资源设置为在设备接收到后立即解压缩。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">“工件” </span>: [
{
<span style="color:#836c28">“Uri” </span>: <span style="color:#c41a16">“s3://your/s3/uri/package.zip” </span>,
<span style="color:#836c28">“取消存档” </span>: <span style="color:#c41a16">“ZIP” </span>,
<span style="color:#836c28">“权限” </span>: {
<span style="color:#836c28">“读取” </span>: <span style="color:#c41a16">“全部” </span>,
<span style="color:#836c28">“执行” </span>: <span style="color:#c41a16">“全部” </span>
}
}
]</span></span>解压后的构件位置随后可用作组件生命周期事件中的变量。本例中的脚本只是启动一个 Bash 环境,切换到解压后的构件目录,最后使用所需的命令行参数运行 Deepstream 应用。注意,命令之间以 \n 字符分隔。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">“生命周期” </span>: {
<span style="color:#836c28">“运行” </span>: {
<span style="color:#836c28">“脚本” </span>: <span style="color:#c41a16">“#!/ bin / bash \ n
cd {artifacts:decompressedPath} / nvds-aws-gg \ n
python3 deepstream_app.py -g nvinferserver -c config_infer_primary_rtdetr_triton.yml -i file://$(pwd)/awsgg-example.mp4 --conn-str ='{configuration:/ ConnString}'--silent -d rtsp” </span>,
<span style="color:#836c28">“RequiresPrivilege” </span>: <span style="color:#aa0d91"><span style="color:#aa0d91">true</span></span>
}
} ,</span></span>如果需要在应用程序运行之前安装依赖项,则可以按照以下方式进行。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">“生命周期” </span>: {
<span style="color:#836c28">“安装” </span>: {
<span style="color:#836c28">“脚本” </span>: <span style="color:#c41a16">“#!/bin/bash\n
cd {artifacts:decompressedPath}/nvds-aws-gg\n
pip3 install -qr requirements.txt” </span>,
<span style="color:#836c28">“RequiresPrivilege” </span>: <span style="color:#aa0d91"><span style="color:#aa0d91">true</span></span>
}
} ,</span></span>检查您的配方详情后,选择目标设备或设备组并选择“部署”。
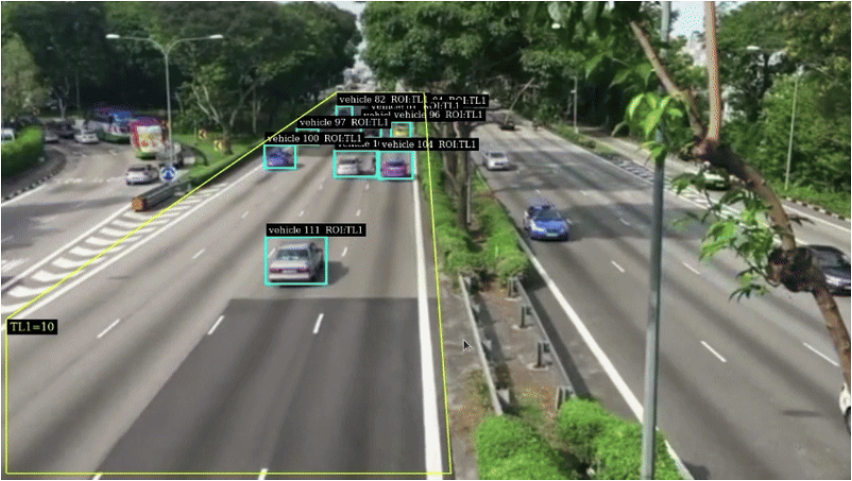
RTSP 输出中的车辆检测框
恭喜!如果一切顺利,您应该会在几分钟内看到消息发布到您的 Kafka 主题。您可以使用 VLC Media Player 等工具连接到设备已发布的 RTSP 地址来查看输出可视化效果。如果出现错误,可以在目标 Jetson 设备的 /opt/greengrass/v2/ 目录下找到日志文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









