






典型的QA 系统包括在线客户服务系统、QA 聊天机器人等。大多数问答系统可以分为:生成式或检索式、单轮或多轮、开放域或特定问答系统。
传统的问答机器人大都是基于规则的知识图谱方式实现,这种方式需要对大量的语料进行分类整理。
而基于深度学习模型的实现方式可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,通过自然语言处理的语义分析模型对问题库提取语义特征向量存入Milvus中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配就可以实现自动回复,轻松实现智能客服等应用。
一、理论准备
我们先来看看这个项目的描述。
This project combines Milvus and BERT to build a question and answer system. This aims to provide a solution to achieve semantic similarity matching with Milvus combined with AI models.
直译为:
本项目结合 Milvus 和 BERT 构建问答系统。旨在提供一种解决方案,通过 Milvus 结合 AI 模型实现语义相似度匹配。
Milvus是什么?
Milvus是一款全球领先的开源向量数据库,赋能 AI 应用和向量相似度搜索,加速非结构化数据检索。
Milvus is the most advanced open-source vector database built for AI applications and supports nearest neighbor embedding search across tens of millions of entries, and Towhee is a framework that provides ETL for unstructured data using SoTA machine learning models.

BERT 是什么?
BERT是Google开发的一种基于Transformer的机器学习技术,用于自然语言处理(NLP) 预训练。
BERT 是一个算法模型,它的出现打破了大量的自然语言处理任务的记录。在 BERT 的论文发布不久后,Google 的研发团队还开放了该模型的代码,并提供了一些在大量数据集上预训练好的算法模型下载方式。Goole 开源这个模型,并提供预训练好的模型,这使得所有人都可以通过它来构建一个涉及NLP 的算法模型,节约了大量训练语言模型所需的时间,精力,知识和资源。BERT模型的全称是:BERT(Bidirectional Encoder Representations from Transformers)。从名字中可以看出,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation。
| BERT模型简介 |
| BERT BASE: 与OpenAI Transformer 的尺寸相当,以便比较性能。 |
| BERT LARGE: 一个非常庞大的模型,是原文介绍的最先进的结果。 |
| BERT的基础集成单元是Transformer的Encoder。 |
BERT是一个多任务模型,它的任务是由两个自监督任务组成,即MLM和NSP。
所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。
Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。
BERT其中的一个重要作用是可以生成词向量,它可以解决word2vec中无法解决的一词多义问题。获取完BERT词向量后还可以结合CNN、RNN等模型来实现自己的任务。

我们现在可以来看下系统的架构原理图
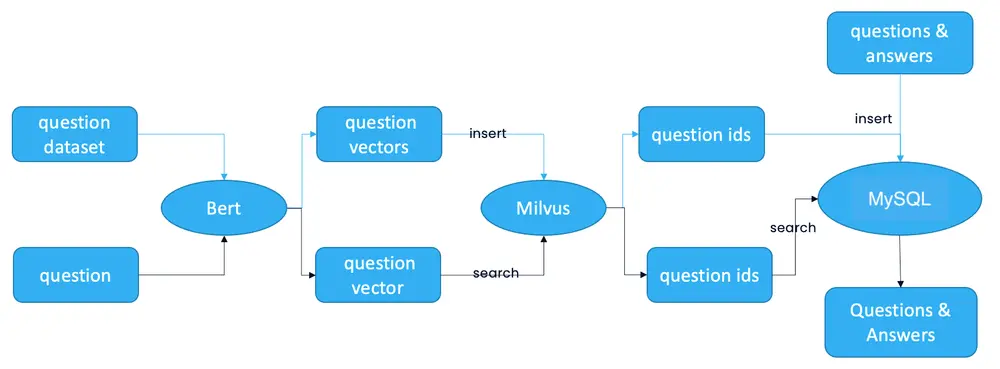

该系统可以将新的用户问题与先前存储在向量数据库中的大量答案联系起来。要构建这样的聊天机器人,请准备您自己的问题数据集和相应的答案。将问题和答案存储在关系数据库 MySQL中。然后使用用于自然语言处理 (NLP) 的机器学习 (ML) 模型BERT将问题转换为向量。这些问题向量在 Milvus 中存储和索引。当用户输入一个新问题时,BERT 模型也会将其转换为一个向量,Milvus 会搜索与这个新向量最相似的问题向量。问答系统对最相似的问题返回相应的答案。
系统会使用 Milvus 存储和搜索特征向量数据,Mysql 用于存储 Milvus 返回的 id 与问题数据集的对应关系,此时需要先启动 Milvus 和 Mysql。
二、快速部署
根据教程,我们需要安装 Milvus and MySQL。
本人的操作系统是ubuntu,并已安装了docker
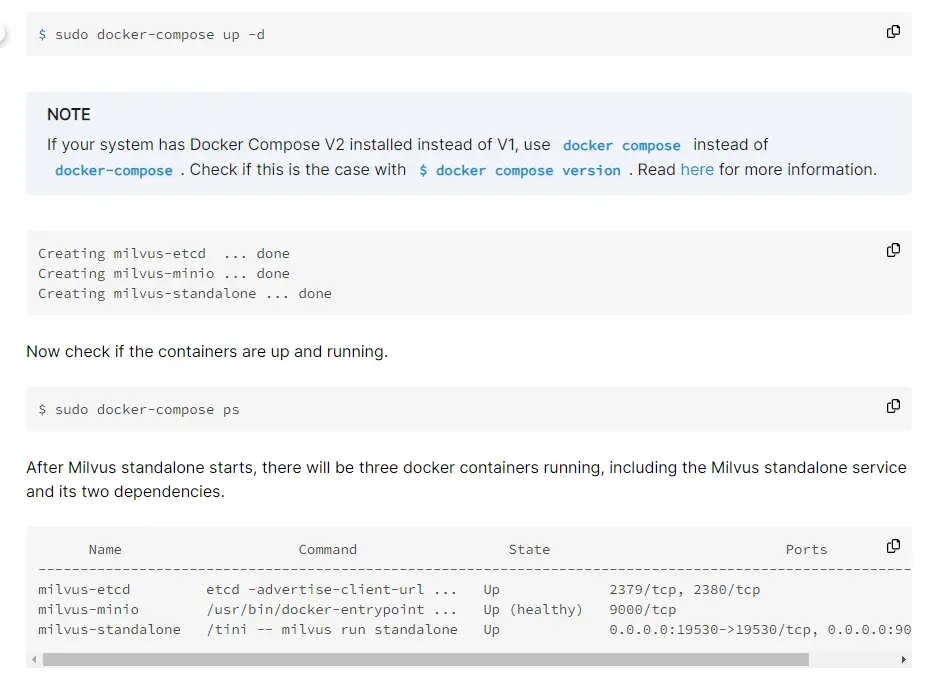
1. Start Milvus and MySQL
Start Milvus v2.0
基于docker直接安装好Milvus,Install Milvus Standalone这一步相对比较简单照着教程敲就可以跑起来。
如果以上链接打不开,可以参考这个官方英文版教程

wget https://github.com/milvus-io/milvus/releases/download/v2.2.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
Start MySQL
照着命令敲就可以跑起来。

2. Start Server
现在我们需要起服务,教程提供了两种方式:通过运行docker、运行源码。如果是前者,需要注意参照教程设置好环境变量,而且需要注意跑起来的时候可能需要下依赖,其中报错不好排查。为了更清晰直观地学习,本人采用后者的方式运行服务。
Install the Python packages
先将代码拉取到本地,如果遇到git clone 等命令报错等问题,请先解决git问题,不是本文重点不再赘述。
我们进去源码的server目录,cd server,进行pythone依赖包的安装pip install -r requirements.txt。可以看一眼依赖文件。
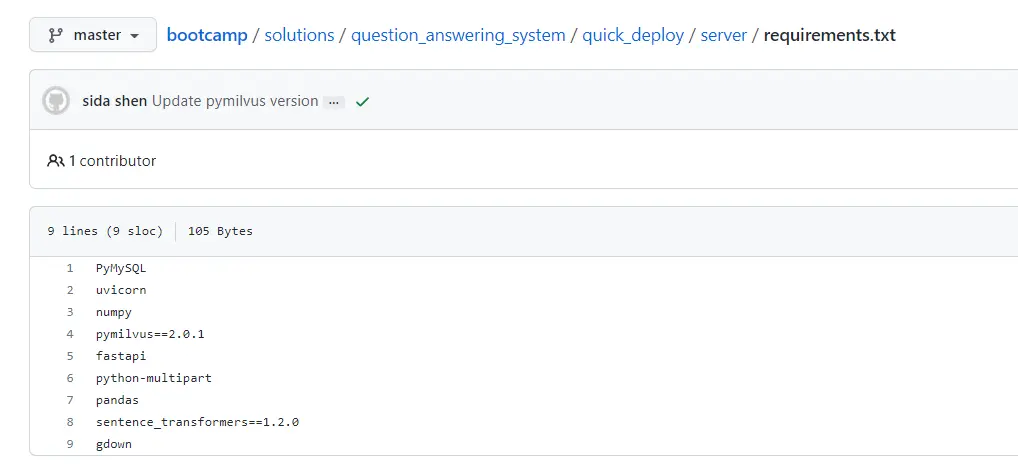
这一步命令的运行可能会遇到各种报错,请自行寻找解决方案。
比如,pymilvus只支持python >= 3.4,在3.4、3.5、3.6、3.7下进行了全面测试。所以如果系统默认的python命名运行的是python2.7版本的,就会报错,需要更改命令执行的默认版本或者更新pip到3版本等等。pip3 install -r requirements.txt,如果不行还可以尝试更换源pip3 install -r requirements.txt -i https://pypi.douban.com/simple,或者直接指定命令版本python3 -m pip install -r requirements.txt来运行。总之,这里要特别注意以py版本和源导致的报错为解决方向。
wget the model
安装完python依赖包之后,我们需要到cd server/src/model目录下进行模型下载(注意如果是docker运行的server指定的模型文件解压后目录是server/src/models,这取决于配置文件的配置)。教程里指定的地址是英文的模型https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/paraphrase-mpnet-base-v2.zip,这个模型将句子和段落映射到768维的密集向量空间,可用于聚类或语义搜索等任务。号称是支持中英文的,本人亲测,中文效果不佳。于是很多教程是建议换成中文模型的(即:要更换为中文训练模型,项目bootcamp默认是支持西文的。 bootcamp中text_search_engine默认使用的是paraphrase-mpnet-base-v2预训练模型的,通过上面的修改也能对中文进行搜索,但其主要针对的是西文,如果要使用中文进行NLP检索的话最好更换预训练模型)。于是本人就着手把这里的模型文件进行更换。
sentence-transformers框架包(如paraphrase-multilingual-MiniLM-L12-v2模型可以支持NLP文本相似度的计算),SBERT的作者发布了他们预训练的SBERT模型。所有预训练的模型可以在这里找到(也是教程默认的模型包含目录),可惜没有中文版的。sentence-transformers开源地址:https://github.com/UKPLab/sentence-transformers
资料包+学习路线图↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









