






1. 【导读】

论文信息
标题:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
论文链接:https://arxiv.org/abs/2502.20087v3
作者:Meng Lou、Yizhou Yu
作者机构:School of Computing and Data Science, The University of Hong Kong

2. 【摘要】
现代卷积神经网络(ConvNets)常采用金字塔结构,忽略了人类视觉系统中自上而下注意力机制这一仿生原理。本文提出的OverLoCK是首个集成该机制的纯卷积骨干网络架构,它通过Base-Net、Overview-Net和Focus-Net三个协同子网络实现“先概览、后细看”的功能 。同时,论文提出上下文混合动态卷积(ContMix),能有效建模长距离依赖关系并保留局部归纳偏差。实验显示,OverLoCK在多项视觉任务上性能出色,如在ImageNet-1K数据集上,OverLoCK-T的Top-1准确率达84.2%,在目标检测和语义分割任务中也超越了多个模型。
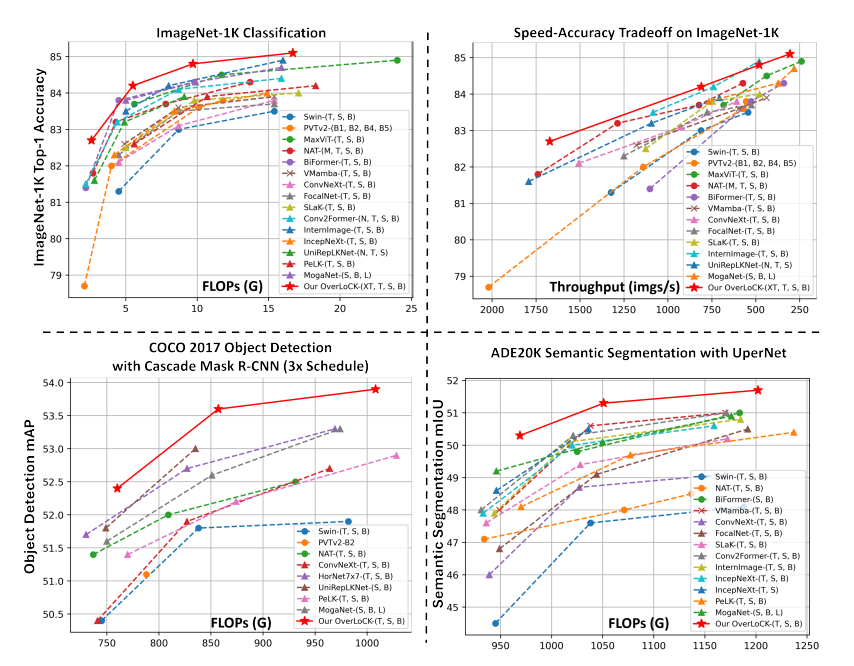
3. 【研究背景】
-
自上而下的注意力机制在人类视觉系统中的重要性:自上而下的神经注意力是人类视觉系统的关键感知机制。大脑在处理视觉场景时,首先会快速形成整体的高层次感知,然后与感官输入融合,从而更准确地判断物体的位置、形状和类别等。这种机制通过反馈信号明确引导,在场景中定位有意义的区域。
-
现有视觉模型对该机制的应用情况:许多研究尝试将自上而下的注意力机制融入视觉模型,但部分方法因模型设计不兼容,不适合构建现代视觉骨干网络;其余方法大多聚焦于循环架构,循环操作带来额外计算开销,导致性能与计算复杂度难以平衡。
-
现有视觉骨干网络架构的局限性:大多数现有视觉骨干网络采用经典的分层架构,从低到高逐步编码特征,中间层操作缺乏自上而下的语义指导。研究通过可视化Swin-T、ConvNeXt-T和VMamba-T等模型的类激活图和有效感受野发现,这些模型在特征图中难以准确对物体进行定位和分类,尤其是距离分类器层较远的阶段。
-
现有卷积方法的不足:在卷积方法方面,现有卷积无法同时满足在不同输入分辨率下建模长距离依赖关系和保持强局部归纳偏差的要求。大内核卷积和动态卷积受固定内核大小限制,长距离建模能力弱;可变形卷积虽能缓解部分问题,但牺牲了卷积的固有归纳偏差,局部感知能力较弱。
4.【主要贡献】
论文的主要贡献在于提出了一种基于仿生学的深度学习架构和动态卷积方法,显著提升了卷积神经网络在多种视觉任务上的性能,具体如下:
-
**提出仿生的Deep-stage Decomposition Strategy (DDS)**:受人类视觉系统中自上而下注意力机制的启发,提出DDS。该策略将网络分解为Base-Net、Overview-Net和Focus-Net三个子网络,模拟人类视觉“先概览、后细看”的过程,增强了特征图和卷积核权重的动态语义上下文引导。
-
**设计Context-Mixing Dynamic Convolution (ContMix)**:为使卷积具备长距离依赖建模能力,同时保持强归纳偏差,提出ContMix。它通过计算输入特征图中每个标记与自上而下上下文特征图中区域中心的亲和力,生成动态卷积核,有效融合全局信息,解决了现有卷积的局限性。
-
构建OverLoCK网络架构:基于DDS和ContMix,提出OverLoCK网络。该网络在速度与精度之间实现了出色的平衡,在多个视觉任务上性能卓越。在ImageNet-1K数据集上,OverLoCK-T的Top-1准确率达84.2% ,超越了多个强大的基线模型;在目标检测和语义分割任务中,同样取得了领先成果。
5.【研究方法与基本原理】
1. 深阶段分解 (DDS):
受人类视觉系统“先概览后细看”机制启发,将网络分解为三个子网络:Base - Net、Overview - Net 和 Focus - Net 。
Base - Net:通过三个嵌入层将输入图像逐步下采样到,生成中级特征图。
Overview - Net:对中级特征图快速下采样到,生成语义有意义但质量较低的概览特征图,作为上下文先验 (context prior)。在预训练时,该网络连接自己的分类器头并施加分类损失;在下游任务中,不再应用辅助监督信号 。
Focus - Net:在上下文先验的指导下,逐步细化中级特征图,扩大感受野以获得更准确和丰富的高级表示。其使用更复杂的动态块 (Dynamic Block),包括残差 3×3 深度可分离卷积 (DWConv)、门控动态空间聚合器 (Gated Dynamic Spatial Aggregator, GDSA) 和卷积前馈网络 (ConvFFN) 。
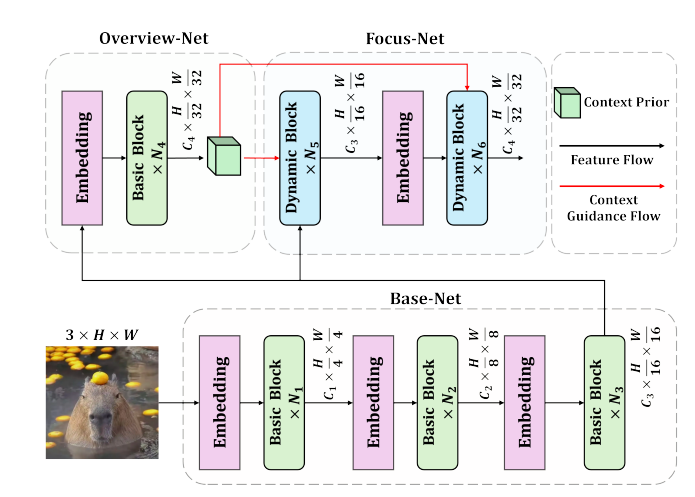
上下文流动 (Context Flow):上下文先验在 Focus - Net 中不仅在特征和内核权重层面提供指导,还在每次前向传递时更新。假设第 i 个块入口处的上下文先验和特征图分别为 和 ,它们通过连接融合后输入块中。在块内,GDSA 通过计算动态门来调制特征图实现特征级指导;上下文先验通过 ContMix 计算动态内核权重注入动态卷积实现权重级指导。在块结束前,融合的特征图被拆分为 和 ,为防止上下文先验被稀释,更新公式为 ,其中 α 和 β 是可学习标量,训练前初始化为 1 。
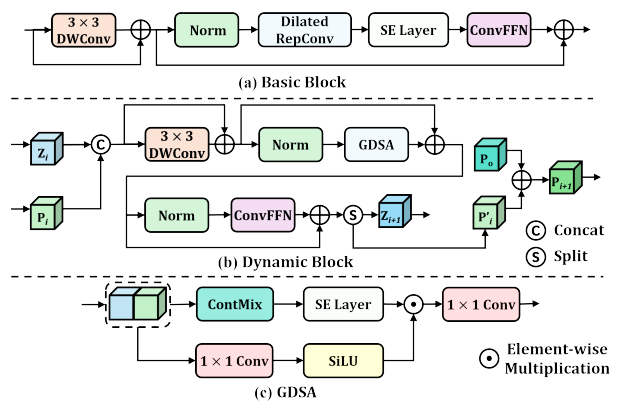
Structures of network building blocks.
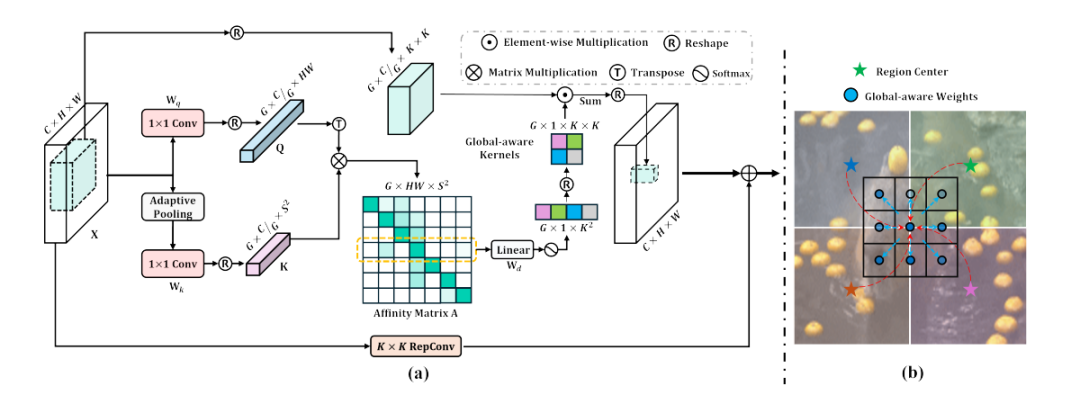
2. 上下文混合动态卷积(ContMix):
为使卷积具备长程依赖建模能力并保留强归纳偏差,提出 ContMix。基于令牌的全局上下文表示(Token-wise Global Context Representation):给定输入特征图,先将其变换为两部分 和,其中 和 是 卷积层, 是重塑操作, 是通过自适应平均池化将 聚合到 区域中心的结果。然后将 和 的通道均匀分为 组,得到 和,计算 个亲和矩阵 ,其中 , 的第 行 表示 中第 个令牌与 中所有令牌的亲和值
基于令牌的全局上下文混合(Token-wise Global Context Mixing):定义 个空间变化的 动态内核。使用可学习线性层 对亲和矩阵 进行聚合,再通过 softmax 函数归一化,公式为。最后将 的每一行重塑为目标内核形状,得到每个令牌位置的输入相关内核。在卷积操作时,特征图 的通道也均匀分为 组,同一组内的通道共享相同的动态内核。
6.【实验结果】
论文对OverLoCK进行了多方面实验,涵盖图像分类、目标检测与实例分割、语义分割,还开展消融研究,全面评估其性能,具体结果分析如下:
-
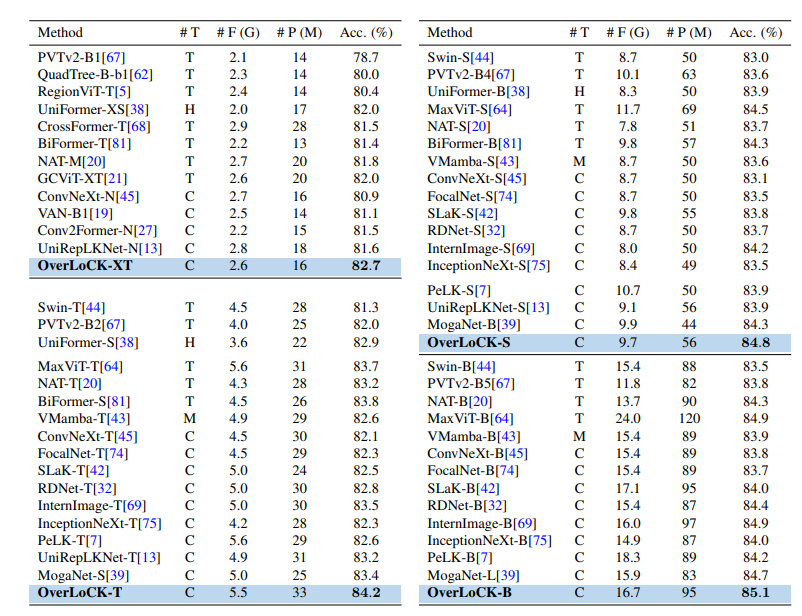
图像分类
-
实验设置:在ImageNet-1K数据集上,按DeiT的设置,用AdamW优化器训练300轮,不同模型设置不同随机深度率,在8个NVIDIA H800 GPU上实验。
-
实验结果:OverLoCK各模型表现优异。如OverLoCK-XT的Top-1准确率比BiFormer-T和UniRepLKNet-N分别高1.3%和1.1%;OverLoCK-T达到84.2% ,超越MogaNet-S和PeLK-T;OverLoCK-S和OverLoCK-B也在同类模型中领先,且计算复杂度相当甚至更低。在高分辨率(384×384)输入下,OverLock-B的Top-1准确率达86.2% ,超越MaxViT-B ,参数减少超三分之一。同时,OverLoCK在速度与准确率的平衡上表现出色,如OverLoCK-XT的吞吐量为1672imgs/s ,比Swin-T快300imgs/s以上,Top-1准确率提高1.4%。
-
-
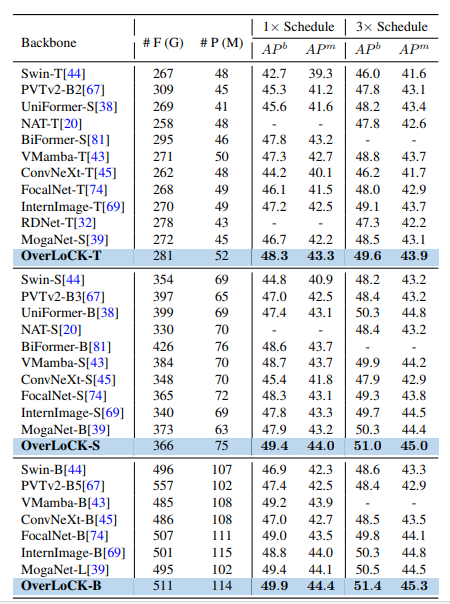
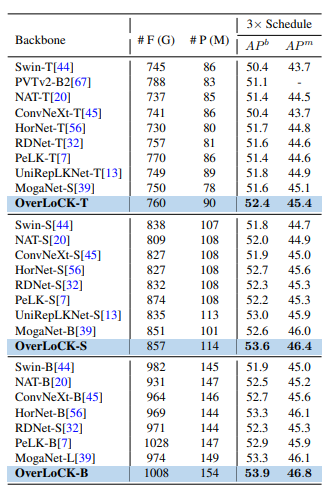
目标检测和实例分割
-
实验设置:在COCO 2017数据集上,用Mask R-CNN和Cascade Mask R-CNN框架,按Swin的设置,预训练后分别微调12轮(1× schedule)和36轮(3× schedule)。
-
实验结果:OverLoCK优势明显。使用Mask R-CNN 1× schedule时,OverLoCK-S的(AP^{b})比BiFormer-B和MogaNet-B分别高0.8%和1.5%;使用Cascade Mask R-CNN时,OverLoCK-S比PeLK-S和UniRepLKNet-S的(AP^{b})分别提升1.4%和0.6%。实验发现,基于卷积神经网络(ConvNet)的方法在目标检测任务上与基于Transformer的方法存在性能差距,而OverLoCK能有效捕捉长距离依赖,性能出色。
-
-
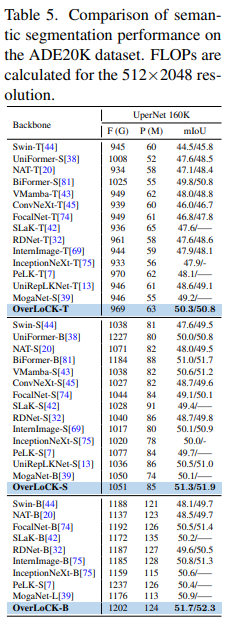
语义分割
-
实验设置:在ADE20K数据集上,用UperNet框架,骨干网络用ImageNet-1K上预训练的权重,按Swin的训练设置。
-
实验结果:OverLoCK性能领先。OverLoCK-T的mIoU比MogaNet-S和UniRepLKNet-T分别高1.1%和1.7% ,比强调全局建模的VMamba-T高2.3%。在小模型和基础模型中也有类似优势。同样,ConvNet因固定内核大小导致感受野受限影响分割性能,OverLoCK则有效缓解了该问题。
-
-
消融研究
-
构建强大的基线模型:从PlainNet开始,逐步添加Dilated RepConv、SE Layer等组件构建基线模型,性能逐步提升。
-
注入自上而下注意力的策略探索:尝试构建循环模型,性能下降;采用DDS分解网络为三个子网络的DDS Model ,性能提升;去掉Base-Net输出与Focus-Net连接的“w/o feature feed”模型,性能降低,证明了DDS中相关连接的重要性。
-
评估权重级上下文指导的影响:将Focus-Net中的现有块替换为Dynamic Block并进行系列改进,如添加辅助分类损失、引入初始上下文先验、添加门模块等,模型性能逐步提升,最终得到OverLoCK-XT模型。
-
动态令牌混合器的比较:构建Swin-like架构对比不同动态令牌混合器,ContMix在图像分类和语义分割任务上表现最佳,尤其在高分辨率输入的语义分割任务中优势明显,因其能在捕捉长距离依赖的同时保留局部归纳偏差。
-
7.【论文总结展望】
总结
论文提出了仿生的深阶段分解(DDS)机制,该机制将语义有意义的上下文注入到网络的中间阶段;同时还介绍了一种具有上下文混合能力的新型动态卷积——ContMix,它能够在保持强归纳偏差的同时捕捉长距离依赖。通过集成这些组件,论文提出了强大的、基于纯卷积神经网络的视觉骨干网络OverLoCK。与强大的基线模型相比,OverLoCK在性能上有显著提升,在速度和精度之间实现了出色的平衡,在多个视觉任务(如图像分类、目标检测和语义分割)中均展现出卓越的性能。
展望
从研究创新点及成果来看,未来可沿着提升模型性能、拓展应用领域和深化理论研究方向探索。在性能提升上,可优化DDS和ContMix,探索新网络结构和卷积方式;应用领域方面,能向医学影像分析、自动驾驶等领域拓展;理论研究上,深入剖析模型工作机制,建立更完善理论体系,为模型改进和新模型设计提供依据 。
【代码文件中文指南】https://github.com/LMMMEng/OverLoCK
1. 环境要求
为确保实验可重复性,强烈建议使用我们提供的依赖项:
环境配置
-
cuda==12.1
-
python==3.10
依赖安装
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121
pip install natten==0.17.1+torch230cu121 -f https://shi-labs.com/natten/wheels/
pip install timm==0.6.12
pip install mmengine==0.2.0
注意:为加速训练和推理过程,我们采用了RepLKNet中提出的高效大内核卷积。请按照相关指南安装depthwise_conv2d_implicit_gemm函数。如果在安装natten时遇到网络问题,请下载该软件包并进行本地安装。
2. 数据准备
请按照以下文件夹结构准备ImageNet数据集,可使用我们提供的脚本解压ImageNet数据集。
imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
3. 基于ImageNet-1K的预训练模型主要结果
| 模型 | 输入尺寸 | 计算量(G) | 参数数量(M) | Top-1准确率(%) | 下载链接 |
|---|---|---|---|---|---|
| OverLoCK-XT | 224x224 | 2.6 | 16 | 82.7 | model |
| OverLoCK-T | 224x224 | 5.5 | 33 | 84.2 | model |
| OverLoCK-S | 224x224 | 9.7 | 56 | 84.8 | model |
| OverLoCK-B | 224x224 | 16.7 | 95 | 85.1 | model |
4. 模型训练
使用8块GPU(单节点)在ImageNet-1K上训练OverLoCK模型,可运行以下命令:
bash scripts/train_xt_model.sh # 训练OverLoCK-XT模型
bash scripts/train_t_model.sh # 训练OverLoCK-T模型
bash scripts/train_s_model.sh # 训练OverLoCK-S模型
bash scripts/train_b_model.sh # 训练OverLoCK-B模型
5. 模型验证
在ImageNet-1K上评估OverLoCK模型,运行以下命令:
MODEL=overlock_xt # 可选overlock_{xt, t, s, b}
python3 validate.py \
/path/to/imagenet \
--model $MODEL -b 128 \
--pretrained # 或者使用--checkpoint指定检查点路径


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









