






人工智能常面临数据匮乏难题,如医疗影像、稀有物种检测等场景,仅能获取数十至数百例高质量标注样本,传统模型易因数据不足过拟合。小样本学习旨在让模型通过1-5个标注样本快速适配新任务,打破“数据依赖”。
其核心挑战在于样本少导致的特征覆盖不足,以及新旧知识迁移难题。早期度量学习方法(如孪生网络)在复杂场景中性能有限。近年,元学习与预训练技术融合成主流:Transformer的上下文学习通过提示激活知识,实现小样本推理;图神经网络结合最优传输校准数据分布。这些技术推动模型在小样本下逼近传统精度,加速向医疗、遥感等数据敏感领域落地。
如果打算深入研究,建议看看我整理的12篇小样本机器学习论文,都是前沿成果,有参考会更容易找到思路,代码也附上了,方便各位复现。
关注VX公众号【学长论文指导】发送暗号 9 领取

【论文1:Nature】Accurate predictions on small data with a tabular foundation model
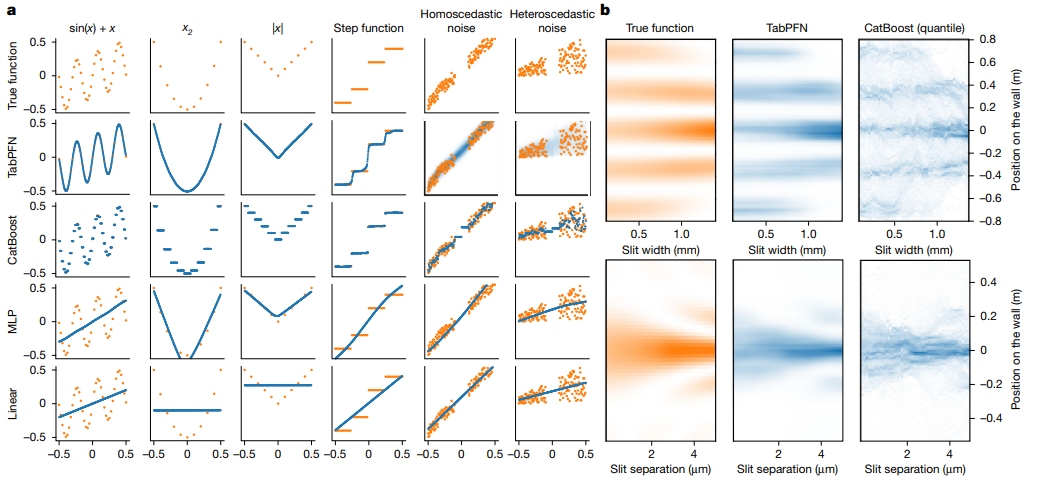
The behaviour of TabPFN and a set of baselines on simple functions
方法
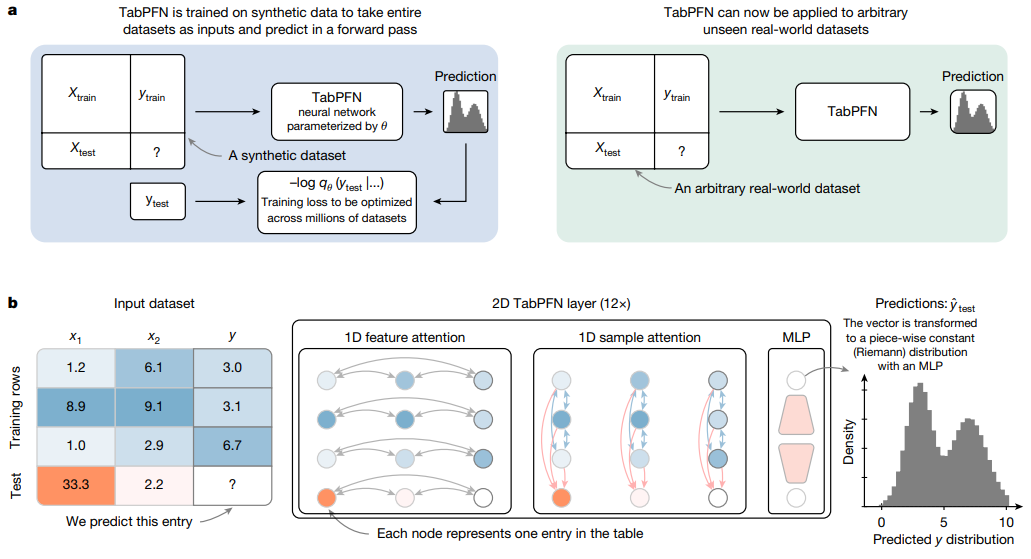
这篇论文提出的研究理论方法是利用上下文学习(ICL)机制,基于数百万合成表格数据集训练 Transformer 架构的 TabPFN 模型,使其能在单次前向传播中完成对新数据集的训练和预测,实现对小样本表格数据的高效建模。
创新点
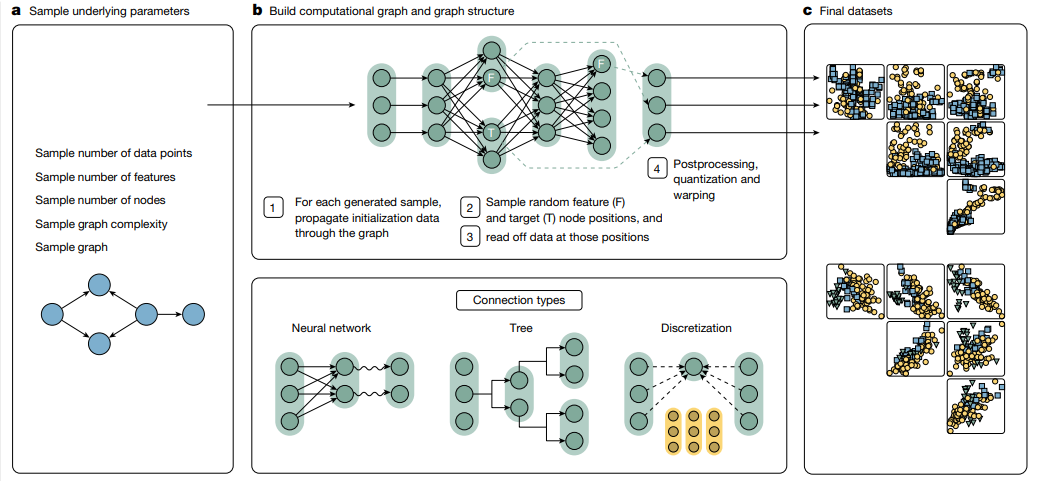
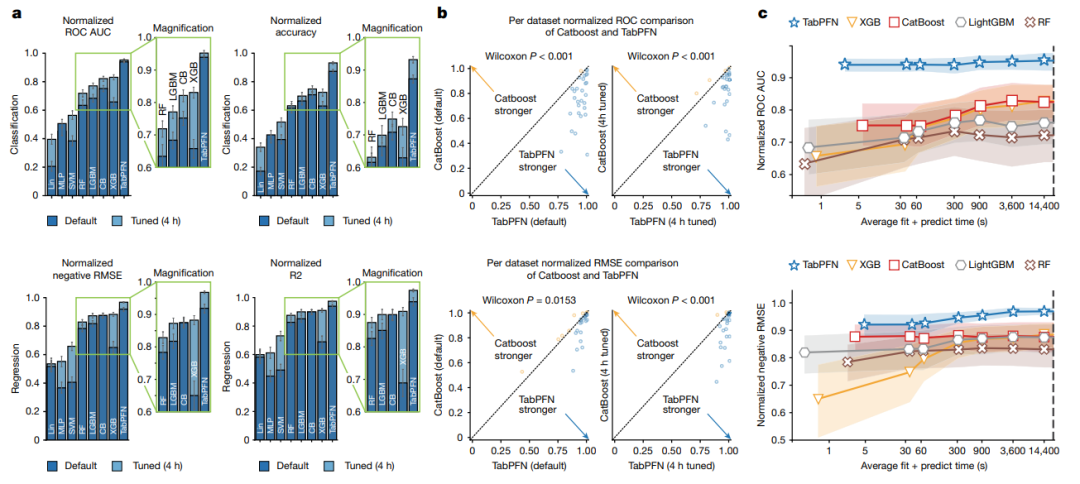
1. 开发出TabPFN模型,在小至中等规模数据集(最多10,000样本、500特征)上性能远超传统梯度提升决策树等方法,且训练时间大幅减少。
2. 引入基于结构因果模型(SCMs)的合成数据生成方法,使模型能学习处理真实数据中的缺失值、异常值等复杂挑战。
3. 实现表格数据的上下文学习,模型具备数据生成、密度估计、特征嵌入学习和微调等基础模型能力,拓展了小样本学习的应用场景。
论文链接:https://www.nature.com/articles/s41586-024-08328-6
【论文2】Enhancing Unsupervised Graph Few - shot Learning via Set Functions and Optimal Transport
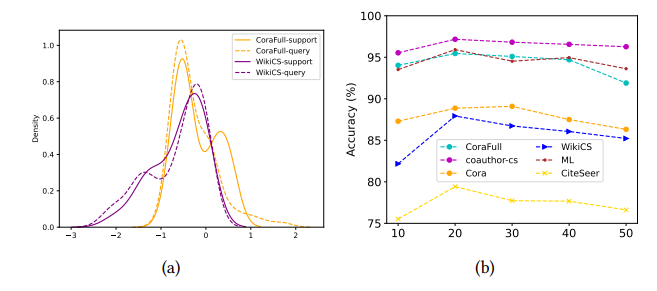
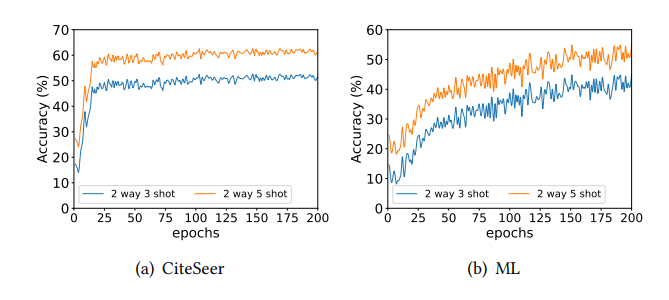
方法
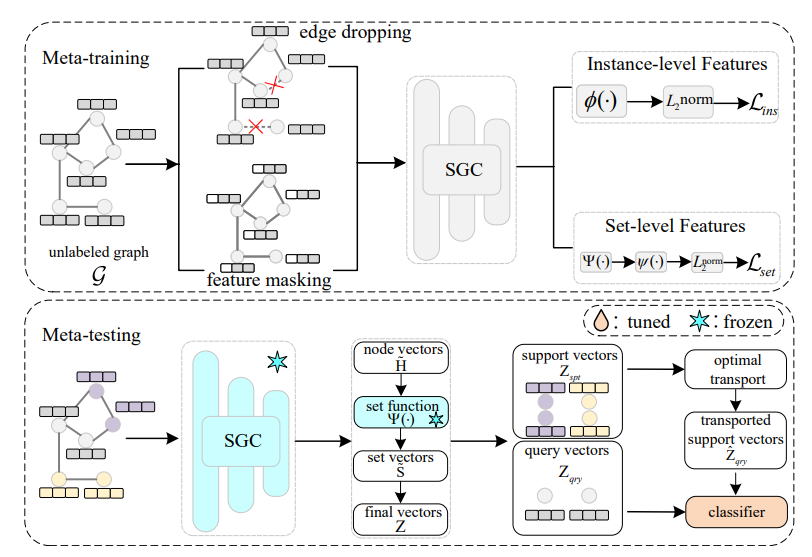
这篇论文提出的研究理论方法是在元训练阶段,通过图对比学习(GCL)提取实例级特征,利用神经集合函数构建正负样本对,进行集合级对比学习以捕捉集合级特征;在元测试阶段,基于最优传输原理校准支持集与查询集的分布,缓解分布偏移问题,最终利用校准后的支持集训练分类器实现小样本节点分类。该方法通过结合实例级与集合级特征学习,并引入分布校准机制,提升了模型在无监督图小样本学习中的性能。
创新点

1. 提出STAR模型,首次将集合函数与最优传输结合,分别用于提取图数据中的集合级特征和校准支持集与查询集的分布,解决了现有模型忽视集合级特征和分布偏移的问题。
2. 理论证明STAR能捕获更多任务相关信息,收紧泛化误差上界,增强了模型的理论可解释性和泛化能力。
3. 设计无监督图小样本学习框架,无需基础类标签数据即可进行元训练,适用于真实场景中标签稀缺的情况,拓展了小样本学习的应用范围。
论文链接:https://arxiv.org/abs/2501.05635**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









