










Transformer 的作用是什么?
Transformer 是目前处理序列任务的最先进模型类型,其中最突出的应用是文本处理任务,尤其是机器翻译。事实上,Transformer 及其衍生模型已经渗透到自然语言处理(NLP)的几乎每一个基准测试排行榜,从问答系统到语法纠错。在许多方面,Transformer 架构的快速发展类似于 2012 年 ImageNet 竞赛后卷积神经网络(CNN)的爆发式增长,无论是好的方面还是坏的方面。

Transformer 被表示为一个黑箱。整个序列(图中的 x)以前馈的方式同时被解析,产生一个经过变换的输出张量。在这个图中,输出序列比输入序列更为简洁。对于实际的自然语言处理任务,单词的顺序和句子的长度可能会有显著的变化。
与之前的 NLP 主流架构(如 RNN 和 LSTM 的各种变体)不同,Transformer 没有循环连接,因此没有对先前状态的真实记忆。Transformer 通过同时感知整个序列来解决这一问题。严格来说,在训练期间通常会对未来元素进行掩码处理,但除此之外,模型可以自由学习整个序列中的长期语义依赖关系。
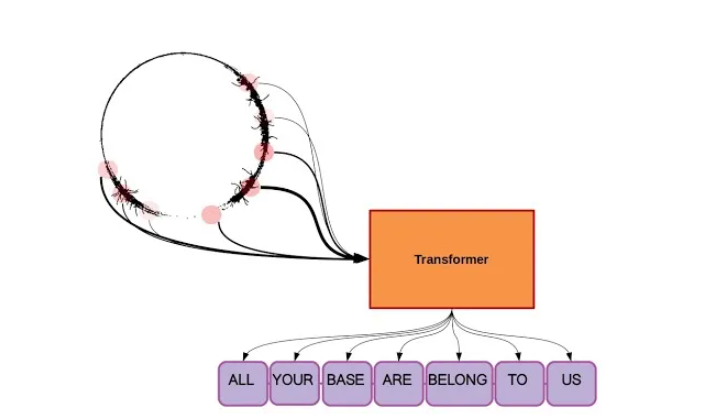
Transformer 摒弃了循环连接,能够同时解析整个序列,有点像电影《降临》中的七肢桶(Heptapods)。你可以使用 FlxB2 提供的开源 Python2 代码库来制作自己的象形文字(logograms)
作为仅使用前馈的模型,Transformer 在硬件需求上需要稍微不同的方法。与循环网络不同,Transformer 不需要按顺序处理元素来构建有用的隐藏单元状态。因此,Transformer 更适合在现代机器学习加速器上运行。尽管 Transformer 在训练期间可能需要大量内存,但使用低精度训练或推理可以减轻内存需求。
迁移学习是实现文本任务顶级性能的重要捷径,坦率地说,对于大多数实际预算有限的研究人员来说,这也是必需的。训练一个大型现代 Transformer 的能源和财务成本可能轻松超过个人研究人员一整年的能源消耗,如果使用云计算,成本可能高达数千美元。幸运的是,类似于计算机视觉中的深度学习,针对特定任务的新技能可以迁移到大型预训练的 Transformer 模型中,例如从 HuggingFace 仓库下载的模型。
Transformer 架构中的注意力机制是什么?
Transformer 架构的核心在于某种形式的注意力机制,2017 年的原始 Transformer 也不例外。为了避免混淆,我们将 Vaswani 等人提出的模型称为原始 Transformer 或 vanilla Transformer,以区别于后续的类似模型(如 Transformer-XL)。我们将从注意力机制开始,逐步构建对整个模型的高层次理解。
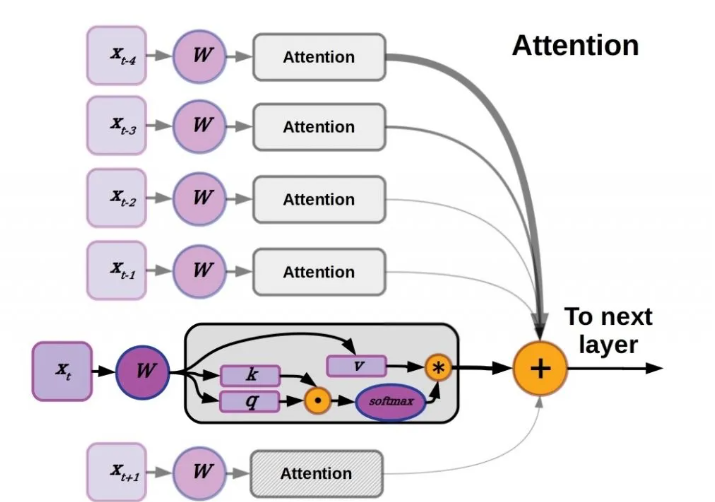
注意力机制的详细解析
如上图,注意力机制是一种选择性地对输入数据的不同元素进行加权的方法,从而调整它们对下游层隐藏状态的影响。原始 Transformer 通过将输入词向量解析为键(key)、查询(query)和值(value)向量来实现注意力机制。键和查询的点积提供了注意力权重,这些权重通过 softmax 函数进行归一化,使得总权重之和为 1。然后根据注意力权重对值向量进行加权求和,并将结果传递到后续层。这可能有点复杂,让我们逐步拆解。
词向量嵌入赋予语义意义
从构成句子的单词序列开始,序列中的每个元素(单词)首先被转换为一种称为词向量的嵌入表示。词向量嵌入是一种比独热编码的词袋模型更精细的表示方法,例如 Salakhutidinov 和 Hinton 在 2007 年的语义哈希论文中使用的模型。
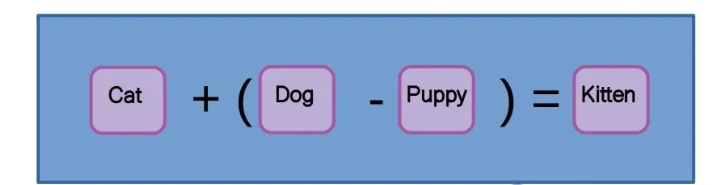
词向量嵌入(有时也称为标记)非常有用,因为它们以神经网络可以理解的数值方式赋予语义意义。学习得到的词向量可以包含上下文和关系信息,例如“dog”和“puppy”之间的语义关系大致等同于“cat”和“kitten”,因此我们可以像以下公式那样操作它们的词向量:
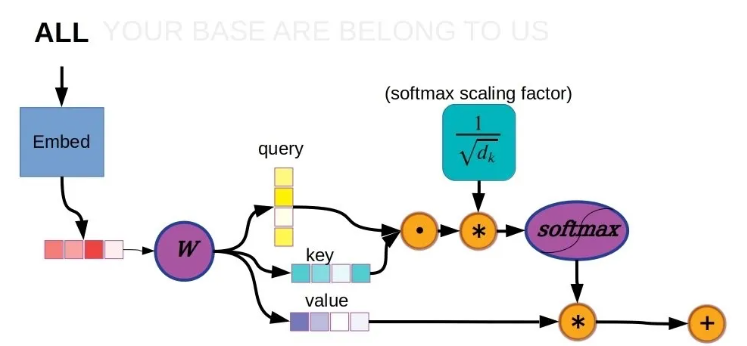
原始Transformer注意力机制的细节
从上图的左上角开始,输入单词首先通过嵌入函数进行标记化,将字符串“ALL”替换为一个数值向量,作为注意力层的输入。注意,只有第一个编码器层具有嵌入函数,其他层只是将前一层的输出向量作为输入。注意力层(图中的 W)基于输入计算三个向量,分别称为键、查询和值。键和查询的点积是一个标量,表示给定位置的相对权重。
注意力机制在序列的每个元素上并行应用,因此每个其他元素也有一个注意力分数。这些注意力分数经过 softmax 函数处理,以确保总权重之和为 1.0,然后与对应的值向量相乘。所有元素的值向量(现在按注意力分数加权)被求和。结果向量是构成输入序列内部表示的一系列向量中的新值,然后将其传递到前馈全连接层。
另一个可能被忽略的重要细节是用于稳定 softmax 函数的缩放因子,即在将值输入注意力层使用的 softmax 函数之前,这些值按键向量单元数的平方根的倒数进行缩放。这对于确保学习效果良好至关重要,无论键和查询向量的大小如何。如果没有缩放因子,使用长键和查询向量时点积往往会很大,将 softmax 函数的梯度推向相对平坦的区域,使得误差信息难以传播。
编码器层:原始 Transformer 的六种类型
如前所述,摒弃循环连接的一个有益结果是整个序列可以一次性以并行方式处理。当我们把上述的自注意力层与一个密集前馈层结合起来时,就得到了一个编码器层。前馈层由两个线性层和一个整流线性单元(ReLU)组成。也就是说,输入首先通过一个线性层(矩阵乘法)进行变换,得到的值然后被截断为始终大于或等于 0,最后结果被输入到第二个线性层以产生前馈层的输出。o
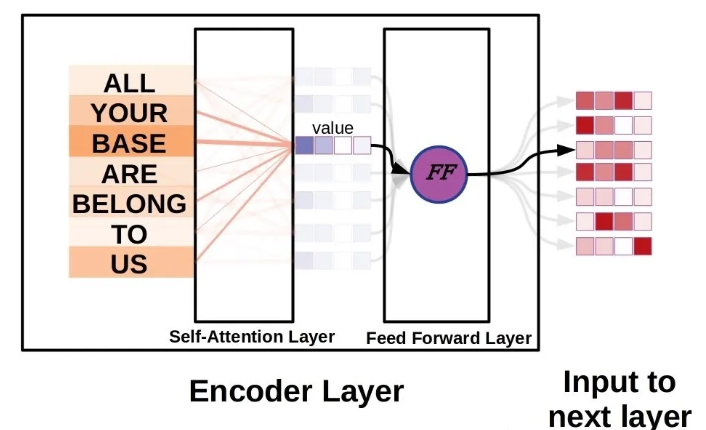
原始 Transformer 使用六个这样的编码器层(自注意力层 + 前馈层),后面跟着六个解码器层。Transformer 使用一种称为多头注意力的自注意力变体,因此实际上注意力层将为每个序列元素计算 8 组不同的键、查询和值向量。然后将这些向量连接成一个矩阵,并通过另一个矩阵乘法,得到适当大小的输出向量。
解码器层:原始 Transformer 的六种类型
解码器层与编码器层有许多相似之处,但增加了第二个注意力层,即所谓的编码器-解码器注意力层。与自注意力层不同,查询向量仅来自解码器层本身。键和值向量来自编码器堆栈的输出。解码器层也包含一个自注意力层,与编码器中看到的一样,查询、键和值向量由解码器堆栈生成。
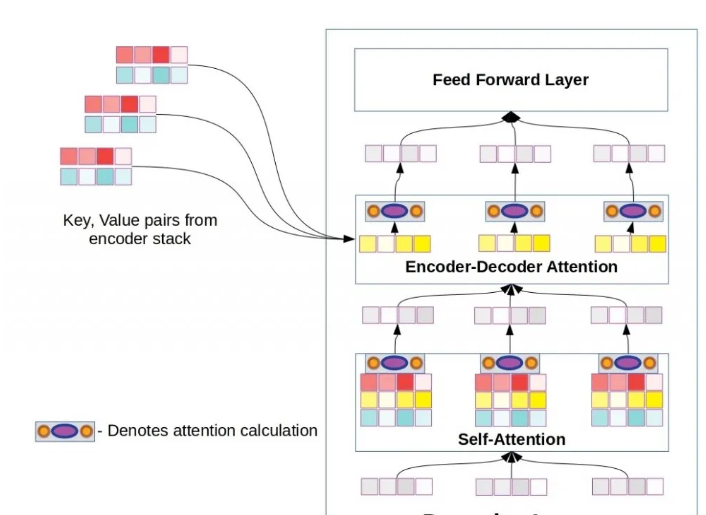
解码器层与编码器层的区别在于增加了一个编码器-解码器注意力子层。六个这样的解码器层构成了原始Transformer中的解码器
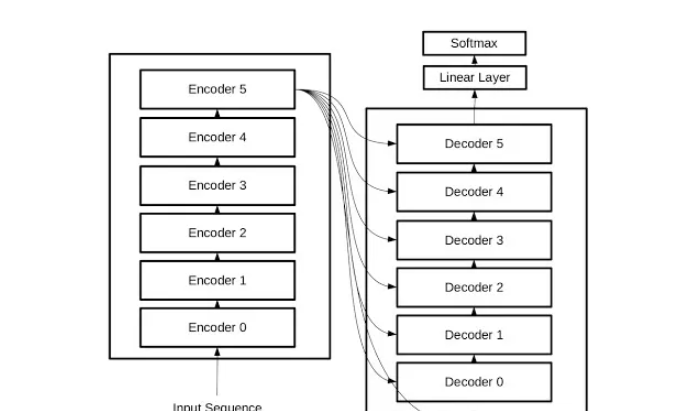
现在我们有了编码器层和解码器层的构建方法。要构建一个 Transformer,只需构建两个堆栈,每个堆栈分别包含六个编码器层或六个解码器层。编码器堆栈的输出流入解码器堆栈,解码器堆栈中的每一层也可以访问编码器的输出。
最终部分:残差连接、层归一化和位置编码
像许多其他具有大量参数的极深神经网络一样,训练它们有时会因为梯度无法很好地从输入流向输出而变得困难。在计算机视觉领域,这导致了强大的 ResNet 风格的卷积神经网络。ResNet(残差网络)通过将最后一层的输入添加到其输出中,从而显式地保留残差。通过这种方式,残差可以通过整个层堆栈保留下来,梯度可以更容易地从输出端的损失函数回流到输入端。在原始 Transformer 模型中,残差求和操作后面跟着层归一化,这是一种改进训练的方法,与批归一化不同,它对小批量大小不敏感。
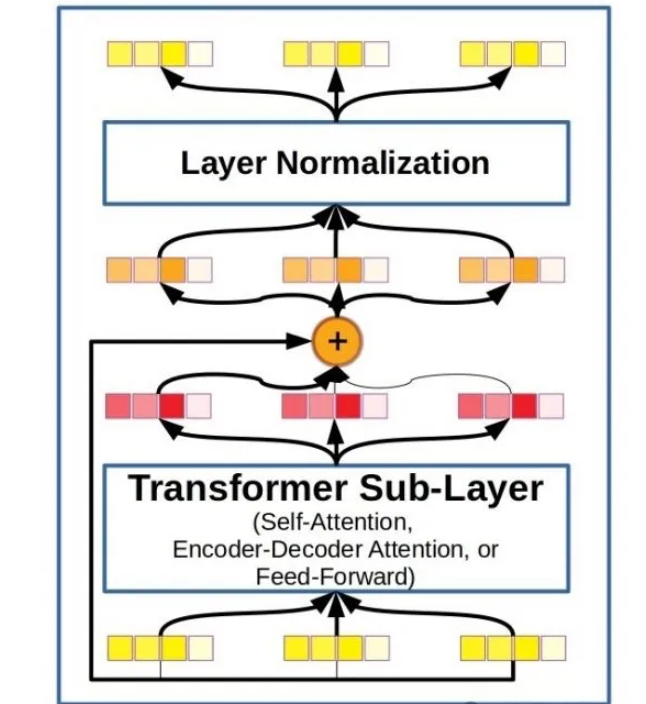
残差连接和层归一化的示意图。在原始Transformer的编码器层和解码器层的每一个子层中都采用了这种结构
在循环架构(如 LSTM)中,模型可以学习内部计数并评估序列距离。原始 Transformer 不使用循环连接,而是同时感知整个序列,那么它是如何学习序列中元素的顺序,尤其是当序列长度可以变化时?答案是基于衰减正弦函数的位置编码,该编码与序列元素嵌入连接。Vaswani 等人还尝试了学习位置编码,结果几乎相同,但推断使用正弦编码应该允许模型更好地泛化到训练期间未见过的序列长度。
Transformer 在深度学习中的影响和未来
2017 年引入的原始 Transformer 对基于序列的深度学习产生了重大影响。通过完全摒弃循环连接,Transformer 架构更适合在现代机器学习加速硬件上进行大规模并行计算。令人惊讶的是,原始 Transformer 能够学习序列中的长期依赖关系,实际上,原始 Transformer 可以轻松学习关系的距离是有限的。
Transformer-XL (https://arxiv.org/abs/1901.02860)由 Dai 等人在 2019 年引入,以解决这一问题,采用新的位置编码,并引入了一种伪循环连接,其中键和值向量部分依赖于前一个隐藏状态以及当前状态。其他 Transformer 变体包括仅解码器的 Transformer(例如 OpenAI 的 GPT ),增加双向性(即基于 BERT 的 Transformer)等。Transformer 被设计为处理序列,并在自然语言处理中找到了最突出的应用,但 Transformer 架构也已被适应于图像生成、强化学习(通过修改 Transformer-XL)以及其他大模型应用领域。
另外给大家准备了一些学习资料


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









