










最近大模型特别火,大家都在讨论它背后的技术。经常听到Transformer 网络,今天咱们聊聊大模型里超重要的 Transformer 网络和 Attention 机制!在第一讲中,已经讲过DeepSeek大模型的MLA机制,属于一种Attention的改进机制,今天重点从历史溯源开始讲Transformer网络。
一、背景简介
Transformer英文翻译 记忆/变压器,查阅了比较多的文献确实没有很好的中文汉字能够表达这个意思,如果非找个汉字表达,或许“变换器”或“转换器”比较合适,他通过自带encode-decode模式,实现A->B的自由转换,尤其适合在翻译、文本生成等场景
二、Transformer 网络架构
Transformer模型架构是2017年Google在论文Attentions is All you need 【1】中提出的模型,官方翻译是“其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构”。这一句话非常重要,但是非常拗口,有两点关键点:
- 什么叫Self-Attention?
- RNN网络又是什么,为什么需要取代之?
2.1 整体流程
Transformer模型结构如下图所示,模型图箭头方向,从下往上看,左边(1)是用户encode的全量输入构建转换网络 (图中红圈C),(2)输出预测过程中的带mask的输入,(3)是基于(1)和(2)输入进一步推理而得到输出,最终得到映射的输出,通过更替映射的词表就可以实现不同语言的翻译。
简单举例,用户输入“我要去乘车”:
首先 起始编码:(1)=“我要去乘车”,构建出encode
第1轮翻译解码:(2)=“<begin>”,经过Decode得到输出为(3)=“I”
第1轮翻译解码:(2)=“我”,经过Decode得到输出为(3)=“I need”
第1轮翻译解码:(2)=“我要”,经过Decode得到输出为(3)=“I need to”
第1轮翻译解码:(2)=“我要去”,经过Decode得到输出为(3)=“I need to take”
第1轮翻译解码:(2)=“我要去乘”,经过Decode得到输出为(3)=“I need to take car”
经过不断地叠加输入、历史输出、叠加字符的位置信息进行预测输出。在架构中间存在N x Layer的重复,该layer内结构与“白话文讲大模型(一):DeepSeek V3/R1的技术创新”类似,属于DeepSeek的先祖。内部主要由两大部分组成:多头注意力机制(Multi - Head Attention)和前馈神经网络(Feed - Forward Network),这两部分还搭配了一些辅助的层,像归一化层(Normalization)。就好比一个工厂,有不同的车间分工合作,每个车间都有自己的任务,共同完成复杂的生产流程。
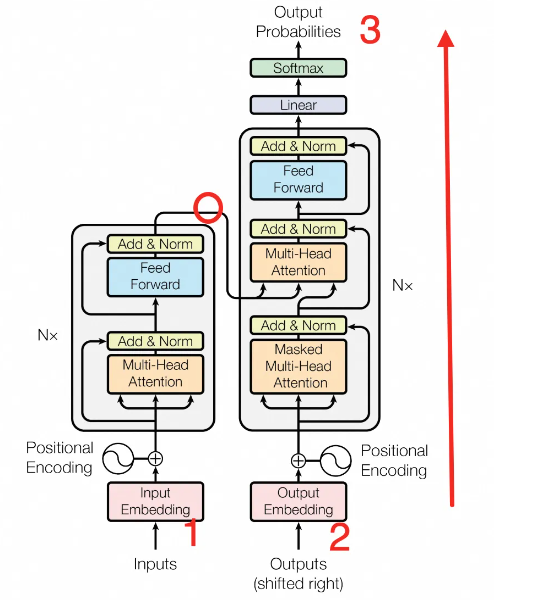
Transformer 网络里的层是一层一层 “接力” 工作的。数据就像接力赛中的接力棒,从输入层开始,依次经过各个中间层,最后到达输出层。每一层都会对数据进行加工处理,让数据变得越来越符合我们的需求。以翻译任务为例,输入的是一种语言的句子,经过 Transformer 网络各层的处理,输出的就是另一种语言的翻译结果。每一层都像是一个 “翻译小助手”,不断优化翻译的质量,让最终的译文更准确、更通顺。
2.2 Self-Attention
Attention 机制可以说是 Transformer 网络的 “秘密武器”。它就像我们看东西时的注意力一样,能让模型在处理数据的时候,把重点放在更重要的部分。想象一下,你在看一篇很长的文章,当你想要回答某个问题时,肯定不会逐字逐句地看,而是会快速找到和问题相关的关键部分。
Attention 机制就是让模型具备了这种 “找重点” 的能力。在处理数据时,它会给不同的数据部分分配不同的 “注意力权重”。权重高的部分,模型就会重点关注;权重低的部分,模型就不会花太多精力。这就好比我们在一张照片里,把焦点对准了想要突出的物体,其他部分就会相对虚化。
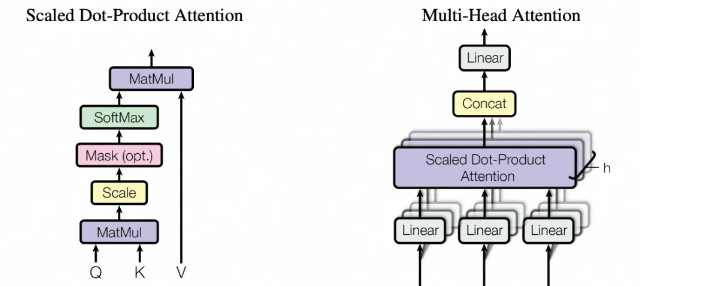
google在提出Transformer网络的时候,引入的MHA如上图所示,输入上重点依赖Q(输入的query,包含原始输入及位置+历史的输出及位置的转换后的,下图输入x)、K(Attention的key,可以理解是一种特定的记忆的思考)、V(Attention的value,可以理解是一种特定的记忆的思考),其中V/K/Q然后按照Linear的转换矩阵(Wq_i)进行转换[6],让每个attention在一个低维度上进行计算。
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出,下一步将进行Attention的输出计算:
由于上述QKV向量本身已经变成了 query单词数n x dk 维度,因此QK^T的转置后,本身变成了 n x n的query内部的Attention关系
进一步通过softmax进行即可实现计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z,相当于z1=QK^T(1)*v矩阵,代表了当前单词下跟其他所有单词的关系。
对于multi-head Attention而言,是在上述基础上,进一步对产出的zi进行concat升维度(恢复至原始维度)
2.3 对比RNN架构优势
循环神经网络(Recurrent Neural Network, RNN)是一种专门用于处理序列数据的神经网络架构。它的核心特点是能够捕捉序列数据中的时间依赖关系,通过隐藏状态(Hidden State)保存之前时间步的信息,从而在处理当前输入时利用历史数据。
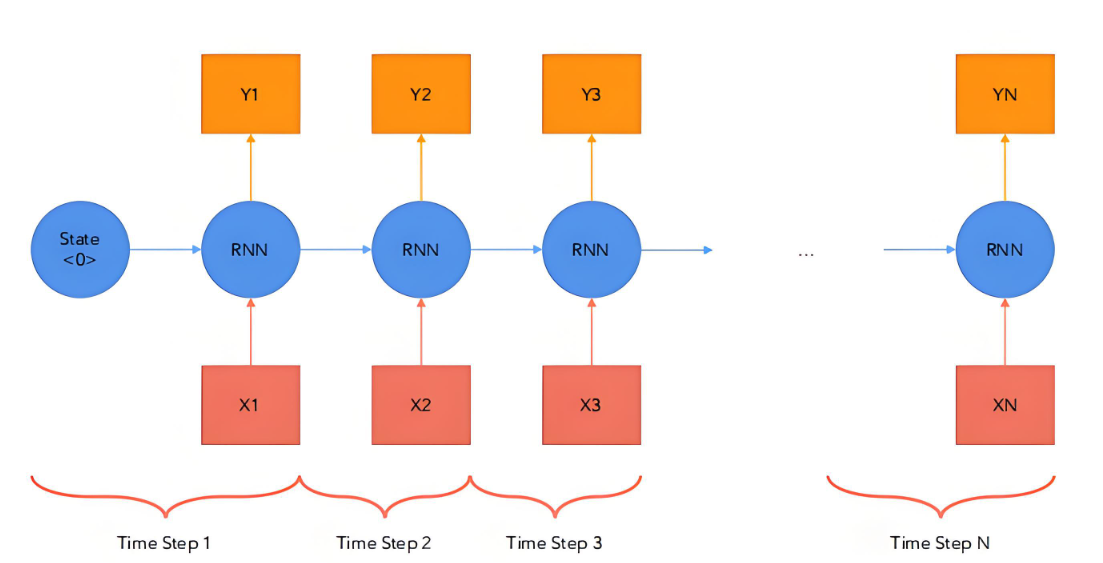
RNN相比CNN,重点在隐层2的输出可以反馈给隐层1,形成了历史序列的输入,RNN这就要求必须一个个字符toten的输入x1,,xn,逐步形成转换矩阵C,然后再输出y1..yn,相比Transformer的设计,输入的序列先后顺序也就决定了输入不能充分并行,而Transformer解决toten的先后顺序问题,使用了位置编码来表达,将输入和对应的位置编码一起送入attention网络。
QKV的attention相比以往的FFN、RNN等优势到底在哪里,这个需要把这个计算放到MLA整体的计算模式上进行看待,到底得到了哪些好处?
-
本质上个人理解是为了降低参数规模,降低复杂度?[读到前面的时候看到猜测,后来论文中得到了证实],“One is the total computational complexity per layer”。在Transformer网络中,输入不仅包括input的tokens,还包括已经预测输出的ouput tokens,因此实际的Q、K、V并不是当前toten的三组向量,而是历史输入的输入encode后的整体向量。以上图中 dmodel=512为例,如果不进行attention转换,n个toten直接做FFN则计算量在 O(n*512*512),而通过隐层转换至 dk=dv=64以后,本质上计算复杂度降低至O(n*64*64),解决了推理加速,也解约了显存,这带来的一个直观好处是能支撑更长的预测序列,这个在DeepSeek的MLA中,也有提到,通过进一步优化V/K/Q的历史向量,进一步节省缓存。
-
另一个原因是更好的支持了并行?“r. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required”,因为拆分了更小的网络,各个attention内部可以充分并行,实际还有一个额外的好处是,可以充分利用gpu内的SRAM缓存来计算,因为单个attention的参数较小,在SRAM内就可以放置完整,而如果是FNN等,基本都需要用到GPU的显存。
-
-
此处需要补一下GPU的结构,比如A100,内部实际存在108个流式处理器,并且每个处理器的片上SRAM(缓存)是192K,因此SRAM总大小是 192K*108=20MB,吞吐量能达到19TB/s,而显存在80GB,但带宽只有1.5TB/s,这里有一个量级的gap
-
每个attention的子网络计算,可以在一个流式处理器上进行计算,并且GPU天然适合计算标量计算(矩阵计算),而Attention的计算方式,可以将所有输入通过n*dk的形式直接计算,没有严格的先后顺序,并且MHA内部还可以进一步实现多Attention的并行
-
-
论文中还提到一个优势:能解决长距离的依赖问题,尤其是翻译问题中的代词,比如“我有一个同事,他今天去上班,他在路上碰到一个小混混,他挡在路中间,他挡住了他的去路不让他通过”,这里边有大量的他,那个他是同事,哪个他是“小混混”,哪个是“同事”,人类可以结合上下文给出答案,但这可要了机器的老命了,需要大量的操作才能实现长距离依赖,而自注意力机制提供了一种方式与历史的输入产生链接,通过权重选择出最大概率的指代词。
通俗的理解,Attention 机制的工作过程可以简单理解为 “拆解 - 加权 - 汇总”。好比我们需要耕种1km*1km的农田,是一个人慢慢的耕种,还是分给100个人,每人负载一个10m*10m的区域,因为每个人负责的区域较小,大家可以并行,耗时更短,同时每个人也不用做大的移动就可以完成周边耕种,更节能。
2.4 Transformer 与 Attention二者关系:相辅相成的 “好搭档”
Transformer 网络和 Attention 机制是相辅相成的关系。Transformer 网络为 Attention 机制提供了一个稳定的框架,让 Attention 机制能够在这个框架里发挥作用;而 Attention 机制则让 Transformer 网络在处理数据时更加高效、准确,能够更好地捕捉数据中的关键信息。
它们就像一对配合默契的搭档,在大模型里共同努力,让模型能够完成各种复杂的任务,比如文本生成、问答系统、图像识别等等。要是没有 Transformer 网络,Attention 机制就像没有舞台的演员,无处施展身手;要是没有 Attention 机制,Transformer 网络处理数据时就会像没头的苍蝇,找不到重点。
2.5 前馈神经网络对Transformer的作用
在 Transformer 网络里,前馈神经网络就像是一个 “信息加工站”,对经过注意力机制处理的数据进行进一步的加工和提炼,在整个模型中发挥着不可或缺的作用。可以从以下几个直观的角度来理解它的作用:
- 知识深化与特征提取:把前馈神经网络看作是一个知识深化的 “加工厂”。当数据经过注意力机制筛选出关键信息后,就像原材料被送到了加工厂。前馈神经网络通过多层神经元的计算,对这些信息进行深度加工。它可以挖掘数据中更复杂、更抽象的特征,将简单的信息转化为更有价值的知识表示。以处理文本为例,它能从单词组合中提取出语义关联、情感倾向等深层次的特征,让模型对文本的理解更加深入 。
- 增强泛化能力:在模型训练过程中,前馈神经网络通过学习不同数据的特征模式,让模型具备更好的泛化能力。这就好比一个人学习了很多不同类型的知识,面对新的问题时,能够运用已有的知识储备进行分析和解决。前馈神经网络学习到的特征模式越多,模型在遇到未见过的数据时,就越能准确地进行处理和预测,不会局限于训练数据中的特定情况 。
- 整合全局信息:前馈神经网络能整合来自注意力机制的局部信息,形成更全面的全局信息表示。注意力机制关注的是数据的局部重点,而前馈神经网络将这些局部重点信息综合起来,让模型对整体数据有更完整的理解。例如在图像识别中,注意力机制可能关注到图像中不同的物体局部特征,前馈神经网络则将这些特征整合,判断出整个图像所表达的场景或物体类别 。
- 提升表达能力:它为 Transformer 网络提供了更丰富的表达能力。简单的线性模型难以表达复杂的关系,而前馈神经网络通过非线性激活函数(如 ReLU 等),可以引入非线性变换,使模型能够学习到更复杂的函数关系。这就好比在绘画中,只用直线很难画出复杂的图案,而通过曲线和各种形状的组合,就能创造出丰富多彩的画面。前馈神经网络的非线性变换让模型可以对数据进行更复杂的建模,从而提升其在各种任务中的表现 。
三、Transformer如何改变的世界?
3.1 Transformer发展状态原因?
transformer出来后,对文本生成和翻译等产生了极大的影响,包括当下的LLM大模型,核心骨架基本都是Transformer结构,所以这个原因可能得原因是啥?
#1 架构与算法的双向奔赴:从前面2.2的self attention分析就可以看出,Transformer本质上是在有限算力约束下的架构调优,通过模型网络设计降低了复杂度,同时充分利用了硬件的cache带宽优势。由于这种架构优势,会导致该类模型的迭代和收敛速度变快,进一步加快研究与探索
#2 框架组件封装的迭代提效:torch等框架提供了成熟的包供引入,降低了算法module的理解成本。torch框架也是在2017年同期快速成长起来
#3 模型本身的优势:模型数据等天然存在大量的噪音,就像人类在学习一段知识的过程中,也是提取其中一部分重点内容进行加强记忆,Attention提供了这种局部增强的范式,不得不说,google的这个Attention命名确实有点意思,如果我们改良模型,取名大概率是子区域增强啥的“model optization by sub-domain enhancement”,想想就不如 “Attention is all you need”上档次🐶
3.2 Google的Transformer与LLM Transformer的差异点?
虽然Google的Transformer与LLM的Transformer同属于一个祖先系列,但是实际上两者在计算流程与预测模式上,已经发生了较大的变化:
-
2017年提出来的Transformer更多的是在解决翻译问题,翻译问题有个天然的前提就是,上下文长度有限,典型的就是一句话或一段话进行翻译,解决的y(1,...,n)=f(x1, ..., xn)的映射,不会涉及特别长的上下文,因此这时候的LLM的Attention机制输入,是可以将输入query直接并行做encode,然后计算Q、K、V进异步计算出转换参数矩阵 Q*K^T,此处是可以n个输入query充分并行
-
DeepSeek等LLM大模型解决的大语言的生成与预测,因此输入的上下文就需要不断地包含进来,这也就衍变成了 t(n+1)=f(t1, ... , tn),即基于已经生成的全部历史文本生成下一个词,这就要求Transformer在Attention时依赖了历史的输入。
四、About feature
围绕这个问题,我分别咨询了豆包、DeepSeek、通义这三位AI助理的帮助,相关回答在4.1-4.3中直接呈现,接着我又让大模型替我对比了三者回答的优劣势整理表格如下:
| 维度 | DeepSeek | 豆包 | 通义 |
| 核心优势 | 系统性全面:覆盖效率优化、混合架构、多模态、可解释性等全链条技术方向。 | 应用驱动:聚焦实际落地场景(边缘部署、长上下文AI Agent),量化技术指标(如70%计算成本降低)。 | 技术深度:结合最新模型(RetNet、Mamba、RWKV)和硬件协同优化(存算一体芯片)。 |
| 效率优化 | 稀疏Attention、分块处理、硬件协同优化,强调通用性。 | 线性注意力(如MiniMax)、渐进量化(INT8→INT2)、边缘部署适配。 | 线性/稀疏注意力、低秩近似,探索新型架构(RetNet、Mamba)替代Transformer。 |
| 多模态扩展 | 统一语义空间建模、跨模态Attention(如DALL·E)。 | 多模态融合(医疗影像、自动驾驶)、跨模态硬件协同优化。 | 视频时空注意力、3D场景建模(AR/VR)、动态模态融合。 |
| 动态机制 | 混合架构(CNN+Transformer、SSM+Attention)、动态路径(MoE)。 | 动态资源分配、自适应学习策略(支持动态环境)。 | 动态计算资源分配、模块化设计(如ViT块结构)、渐进式训练。 |
| 可解释性与鲁棒性 | 注意力可视化、因果推理、逻辑约束。 | 透明化决策机制(减少偏见)、对抗鲁棒性优化。 | 注意力热图分析、对抗攻击防御(正则化权重)、符号推理模块。 |
| 硬件协同 | 算法-硬件协同(如FlashAttention显存优化)。 | 边缘设备NPU适配、量化/剪枝技术。 | 专用芯片(NVIDIA Transformer Engine)、存算一体架构、分布式通信优化(NVLink)。 |
| 替代架构探索 | 超越Transformer的新架构(Mamba、RWKV)、量子计算结合。 | 稀疏模型、MoE混合专家架构、类脑模型。 | RetNet(RNN+Transformer)、Mamba(SSM+Attention)、RWKV(无限上下文)。 |
| 垂直领域应用 | 通用AI演进(AGI)、生物启发式模型。 | 医疗、金融、电力等垂直领域深化。 | 自动驾驶、教育、医疗等场景,结合视频与3D数据。 |
| 训练与数据策略 | 自监督学习、终身学习、绿色AI(低碳训练)。 | 自监督/少样本学习、高质量数据生产。 | 元学习(Meta-Learning)、无监督Re-ID、知识库集成。 |
| 劣势 | 方向分散,缺乏优先级;对最新模型(如RetNet、Mamba)讨论较少。 | 技术细节较浅,未深入生物启发式架构或量子计算等前沿方向。 | 分类存在重叠(如动态架构与自适应设计);对边缘设备部署讨论较少。 |
| 适用场景 | 学术研究:全面了解技术全景;企业战略:制定长期技术路线。 | 工业落地:关注成本优化和边缘端部署;垂直领域开发者:快速适配行业需求。 | 技术研发:探索新型架构与硬件协同;视频/3D领域:时空建模与多模态融合。 |
4.1 DeepSeek
Transformer网络及其核心的Attention机制自提出以来,已成为自然语言处理(NLP)、计算机视觉(CV)、语音处理等领域的基石。尽管其性能卓越,但仍存在计算复杂度高、可解释性不足、长序列处理效率低等挑战。未来的发展方向可能围绕以下方向展开:
1. 效率优化与计算复杂度降低
- 稀疏Attention与局部Attention
通过限制Attention的计算范围(如局部窗口、稀疏连接)降低计算复杂度。例如,Longformer、BigBird等模型通过稀疏化处理长序列。 - 线性复杂度Attention
设计近似算法(如Linformer、Performer)将复杂度从 O(N2)O(N2) 降至 O(N)O(N),利用核函数或低秩分解近似Attention矩阵。 - 层级或分块处理
将长序列分割为块(如Reformer的局部敏感哈希分块),或在多尺度层次结构中进行Attention(如Swin Transformer)。 - 硬件与算法协同优化
结合硬件特性(如GPU/TPU)设计更高效的Attention实现,例如FlashAttention的显存优化。
2. 混合架构与动态机制
- 结合其他神经网络结构
-
- 与CNN结合(如Vision Transformer中的Patch Embedding + CNN局部特征)。
- 与状态空间模型(SSM)结合(如Mamba的Selective State Space + Attention)。
- 引入记忆增强模块(如Transformer-XL的循环记忆机制)。
- 动态网络结构
-
- 根据输入动态调整Attention头数或计算路径(如Mixture-of-Experts,MoE)。
- 条件化计算(Conditional Computation),仅激活必要模块以节省资源。
3. 多模态与跨模态扩展
- 统一的多模态建模
将文本、图像、视频、音频等多模态数据映射到统一语义空间(如CLIP、Flamingo)。 - 跨模态Attention机制
设计跨模态交互的Attention(如DALL·E中的文本-图像交叉Attention),支持生成式任务(图像生成、视频合成)。
4. 可解释性与可靠性提升
- Attention可解释性分析
研究Attention权重与模型决策的关系,开发可视化工具(如Attention Rollout)。 - 鲁棒性与抗干扰
增强对抗样本的鲁棒性,减少对噪声输入的敏感度。 - 因果推理与逻辑约束
结合符号逻辑或因果推理(如因果Attention),提升模型逻辑一致性。
5. 模型规模与训练范式革新
- 高效训练技术
分布式训练优化(如ZeRO、Megatron-LM)、参数高效微调(LoRA、Adapter)。 - 模型小型化与部署
知识蒸馏(DistilBERT、TinyBERT)、量化(INT8/FP16)、剪枝(移除冗余Attention头)。 - 绿色AI与可持续性
减少训练能耗,探索低碳优化策略(如动态稀疏训练)。
6. 生物启发与神经科学融合
- 类脑注意力机制
借鉴人脑注意力机制(如选择性注意、工作记忆),设计更接近生物处理的模型(如脉冲神经网络与Attention结合)。 - 持续学习与终身学习
避免灾难性遗忘,支持动态知识更新(如Elastic Weight Consolidation应用于Transformer)。
7. 自监督与无监督学习
- 改进预训练目标
设计更高效的自监督任务(如SpanBERT的片段掩码、ELECTRA的替换检测)。 - 跨任务通用表示
探索统一预训练框架(如Unified-IO、Gato),支持多任务泛化。
8. 强化学习与决策智能
- 序列决策建模
将Transformer应用于强化学习(如Decision Transformer、Gato),处理长程依赖的决策序列。 - 世界模型与模拟
结合Transformer构建环境动态模型(如VideoGPT),支持预测与规划。
未来潜在突破点
- 超越Transformer的新架构
探索完全不同的基础模型(如Mamba的SSM、RWKV的RNN+Attention混合结构)。 - 量子计算与Attention结合
利用量子算法加速Attention计算或设计量子Attention机制。 - 通用人工智能(AGI)探索
通过多模态、多任务Transformer架构向更通用的智能系统演进。
未来Transformer的发展将围绕效率、多模态、可解释性、规模扩展和跨领域融合展开,同时可能催生新一代架构。核心目标是在保持性能优势的同时,解决计算成本、能耗、鲁棒性等问题,推动AI技术向更高效、更智能、更普适的方向演进。
豆包
大模型中 Transformer 网络及 Attention 结构的未来发展方向可归纳为以下几个关键领域:
1. 模型效率优化与轻量化
- 线性注意力机制创新:如 MiniMax 提出的线性注意力架构,通过降低计算复杂度(接近线性复杂度),解决传统 Transformer 在长文本处理时的二次复杂度瓶颈,支持高达 400 万 token 的超长上下文输入。
- 计算成本优化:TurboAttention 等方案通过稀疏多项式近似、渐进式量化(INT8 到 INT2)和低秩矩阵分解等技术,可降低 70% 的计算成本,同时保持模型精度。
- 模型压缩与硬件适配:结合模型量化、剪枝和硬件架构优化(如边缘设备 NPU 支持),推动 Transformer 在边缘端的高效部署。
2. 多模态与跨模态融合
- 多模态特征整合:研究更高效的多模态融合方法,解决数据偏差与对齐问题,提升模型对文本、图像、音频等多模态数据的综合处理能力。
- 跨模态推理与生成:强化多模态推理能力,拓展应用场景(如医疗影像分析、自动驾驶),并探索多模态硬件与模型的协同优化。
3. 长上下文与动态适应能力
- 超长序列处理:通过架构创新(如线性注意力)支持更长的上下文窗口,满足 AI Agent 时代对长记忆和复杂任务的需求。
- 动态模型架构:设计动态注意力机制和自适应学习策略,使模型能根据输入动态调整资源分配,提升对动态环境和任务的适应能力。
4. 可解释性与鲁棒性增强
- 透明化决策机制:通过改进注意力可视化和可解释性技术,让模型决策过程更透明,减少偏见和错误。
- 对抗鲁棒性优化:提升模型在噪声数据或对抗攻击下的稳定性,增强实际应用中的可靠性。
5. 跨领域应用拓展
- 垂直领域深化:结合行业数据(如医疗、金融、电力),优化 Transformer 在专业任务中的表现,例如金融风险预测、医学图像分析等。
- 新兴技术融合:与强化学习、生成对抗网络(GAN)、自监督学习等结合,拓展应用边界(如机器人控制、智能城市管理)。
6. 新型硬件与计算范式结合
- 量子计算加速:利用量子计算的并行性提升 Transformer 训练效率,缩短训练时间并优化参数搜索。
- 专用硬件适配:开发针对 Transformer 的专用芯片(如支持线性注意力的 NPU),提升计算吞吐量和能效比。
7. 替代架构与稀疏模型探索
- 高效架构创新:探索超越 Transformer 的新型模型结构(如稀疏模型、MoE 混合专家模型),降低计算资源消耗,提升能效比。
- 生物启发式架构:借鉴人脑神经机制,设计更高效的类脑模型,缩小与人脑计算效率的差距。
8. 数据与训练策略优化
- 高质量数据生产:重视数据多样性与质量,避免重复模式数据对模型性能的负面影响,提升训练数据的有效性。
- 自监督与少样本学习:减少对大规模标注数据的依赖,发展自监督学习和少样本学习技术,降低训练成本。
综上所述,Transformer 及 Attention 结构的未来发展将围绕效率、多模态、适应性、可解释性和跨领域应用展开,同时结合硬件创新与新型算法,推动大模型向更高效、更通用的方向演进。
4.3 通义
结合知识库中的最新信息,未来Transformer及其注意力机制的发展方向可能集中在以下几个关键领域:
1. 计算效率与复杂度优化
- 线性化注意力机制
现有Transformer的自注意力机制计算复杂度为 O(n2)O(n2)(nn为序列长度),限制了其在长序列任务中的应用。未来可能通过以下方式优化:
-
- 线性注意力(Linear Attention):将注意力计算转化为线性操作(如傅里叶变换或随机特征),将复杂度降至 O(n)O(n)(如Linformer、Performers模型)。
- 稀疏注意力(Sparse Attention):仅对局部或关键位置计算注意力(如BigBird、Longformer),减少计算量。
- 低秩近似:通过矩阵分解降低注意力矩阵的维度(如Reformer模型)。
- 新型架构探索
知识库提到,研究人员正在探索替代Transformer的架构,例如:
-
- RetNet:结合RNN的递归特性与Transformer的并行化,实现训练并行化和推理效率提升。
- Mamba:融合Transformer与CNN的优势,计算复杂度线性增长,适合长序列处理。
- RWKV:基于RNN的变体,支持无限上下文长度且显存占用恒定,但需解决对提示词敏感的问题。
2. 跨模态与多任务学习
- 多模态统一建模
Transformer在文本、图像、视频等领域的成功(如ViT、DALL·E、SAM)表明,未来将进一步推动跨模态任务:
-
- 统一特征空间:通过多模态预训练(如CLIP、Flan-T5),将文本、图像、音频等模态映射到共享空间,提升跨模态推理能力。
- 动态模态融合:根据任务需求自适应调整不同模态的权重(如视频中的文本-视觉联合建模)。
- 视频与3D数据处理
知识库提到,Transformer在视频Re-ID、视频生成(如Sora模型)中已有应用,未来可能:
-
- 时空注意力机制:在视频帧间引入时空联合注意力,捕捉动态信息。
- 三维场景建模:将Transformer扩展到点云、网格等3D数据,推动自动驾驶、AR/VR领域发展。
3. 与CNN的融合与互补
- 混合架构设计
尽管Transformer在全局建模上占优,但CNN在局部特征提取(如边缘、纹理)仍有优势。未来可能进一步融合两者:
-
- CNN-Transformer混合模型:如DETR(CNN提取局部特征,Transformer全局推理)、TransCNN等。
- 局部-全局注意力:在自注意力中引入局部窗口机制(如Swin Transformer),平衡局部细节与全局依赖。
- 轻量化CNN与Transformer的结合
知识库[3]指出,CNN与Transformer的结合是当前主流方向,未来可能通过轻量化CNN(如MobileNet)与高效Transformer模块的结合,降低计算成本。
4. 动态与自适应架构
- 动态计算资源分配
根据任务需求动态调整注意力计算范围(如仅对关键区域计算注意力),减少冗余计算。 - 可扩展性设计
支持模型在不同硬件(如边缘设备、云端)间自适应调整参数量和计算复杂度,例如:
-
- 模块化设计:将Transformer分解为可插拔的子模块(如ViT的块结构)。
- 渐进式训练:逐步扩展模型规模,适应不同场景的计算资源限制。
5. 推理能力与小样本学习
- 强化推理与决策能力
知识库提到,未来AI需减少对大数据的依赖,提升推理能力。Transformer可能通过以下方式改进:
-
- 逻辑推理模块:结合符号推理与注意力机制,解决复杂逻辑问题(如数学证明、因果推理)。
- 外部知识库集成:通过注意力机制动态调用外部知识(如数据库、互联网信息),减少预训练数据需求。
- 小样本与无监督学习
知识库指出,Transformer在无监督Re-ID任务中已取得进展,未来可能:
-
- 自监督预训练:从无标签数据中学习通用特征表示(如掩码图像建模、对比学习)。
- 元学习(Meta-Learning):通过少样本学习快速适应新任务。
6. 硬件与软件协同优化
- 专用芯片与存算一体架构
知识库提到,针对Transformer的硬件优化是关键:
-
- 定制化芯片:如GPU中针对自注意力的加速单元(如NVIDIA的Transformer Engine)。
- 存算一体芯片:减少数据搬运开销,提升能效比。
- 分布式训练与通信优化
通过高效通信协议(如NVLink、CXL)和模型并行技术,解决大规模Transformer的训练瓶颈。
7. 可解释性与鲁棒性提升
- 注意力可视化与解释
通过可解释性技术(如注意力热图、梯度分析)揭示模型决策过程,增强用户信任。 - 对抗攻击与鲁棒性训练
改进注意力机制对噪声或对抗样本的鲁棒性(如正则化注意力权重、对抗训练)。
8. 长序列与长上下文处理
- 无限上下文长度支持
知识库[4]提到,RWKV、RetNet等架构支持长上下文,未来可能进一步优化其建模能力。 - 分层注意力结构
通过分层或分块处理长序列(如分层Transformer、分块注意力),平衡效率与性能。
总结
未来Transformer的发展将围绕效率提升、跨模态扩展、与CNN融合、动态自适应、硬件协同优化等方向展开。同时,其在推理能力、小样本学习和长序列处理上的突破将推动AI在医疗、自动驾驶、教育等领域的广泛应用。然而,如何平衡性能与计算成本,仍是研究者需要解决的核心挑战。为方便大家学习,整理了大模型学习资料包

















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









