






先按照示例代码过一遍,然后完成下列题目
现在在py文件中 一次性处理data数据中所有的连续变量和离散变量
1. 读取data数据
2. 对离散变量进行one-hot编码
3. 对独热编码后的变量转化为int类型
4.对所有缺失值进行填充
流程:
1.读取data数据
import pandas as pd
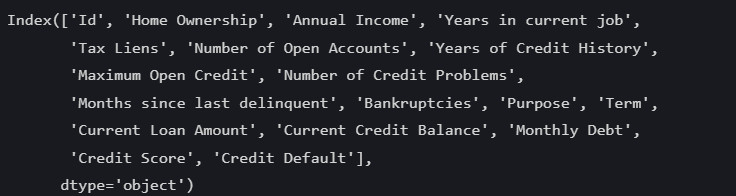
data = pd.read_csv(C:\Users\Lenovo\Desktop\python60-days-challenge-master\data.csv)打印查看所有的变量:
print(data.co;umns)打印结果为:
2.对离散变量进行one-hot编码
先查找离散变量:
#找到离散型数据
discrect_lists = []
for discrect_feature in data.columns:
if data[discrect_feature].dtype == "object":
discrect_lists.append(discrect_feature)
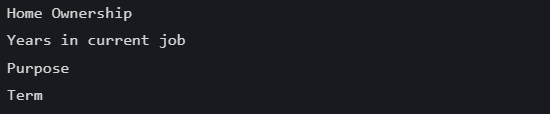
print(discrect_lists)
找到的离散变量结果为:
选择一个离散变量进行独热编码:
以Home Ownership为例,进行独热编码
#对数据进行独热编码
data = pd.get_dummies(data,columns=discrect_lists,drop_first=True)
data.columnsps:pd.get_dummies() 是 Pandas 库中的一个函数,用于将分类变量转换为独热编码的形式。独热编码是一种将分类变量转换为二进制列的方法,每一列代表一个类别,若某行数据属于该类别,则对应列的值为 1,否则为 0。data 是传入的 Pandas DataFrame 对象。columns=['Home Ownership'] 指定需要进行独热编码的列名,这里是 "Home Ownership" 列。最后data = 表示将编码后的新 DataFrame 重新赋值给 data 变量。
运行结果为:
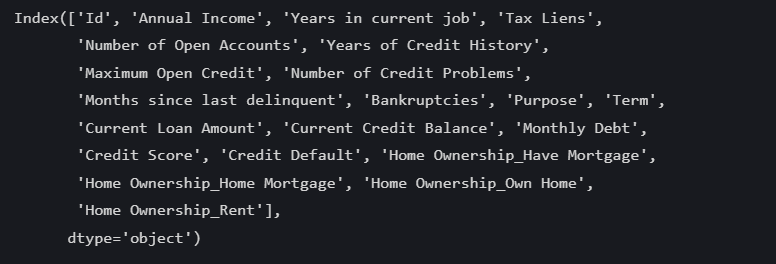 可以看到之前的Home Ownership已经被替换成了'Home Ownership_Have Mortgage','Home Ownership_Home Mortgage', 'Home Ownership_Own Home','Home Ownership_Rent'
可以看到之前的Home Ownership已经被替换成了'Home Ownership_Have Mortgage','Home Ownership_Home Mortgage', 'Home Ownership_Own Home','Home Ownership_Rent'
到这里已经掌握了对于离散变量做独热编码的方法,接下来对所有离散变量做独热编码
# 重新读取数据
data = pd.read_csv("data.csv")
# 找到离散变量
discrete_lists = [] # 新建一个空列表,用于存放离散变量名
for discrete_features in data.columns:
if data[discrete_features].dtype == 'object':
discrete_lists.append(discrete_features)
# 离散变量独热编码
data = pd.get_dummies(data, columns=discrete_lists, drop_first=True)
data.columns为了找到新定义的富热编码特征名,定义一个新列表
data2 = pd.read_csv("data.csv")
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
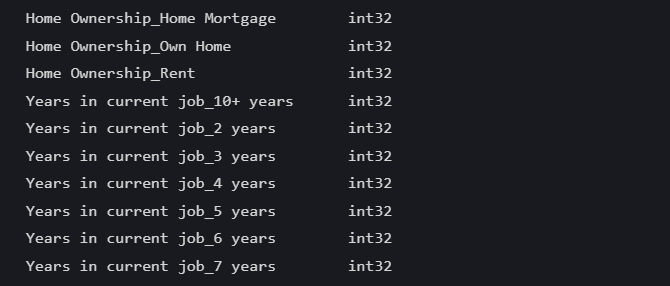
list_final3.对独热编码后的变量进行从bool到int的类型转换
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名data.dtypes #查看变量类型部分运行结果如下:
4.对所有缺失值进行补充
先统计每一列的缺失值数量:
data.isnull().sum() 部分运行结果如下:
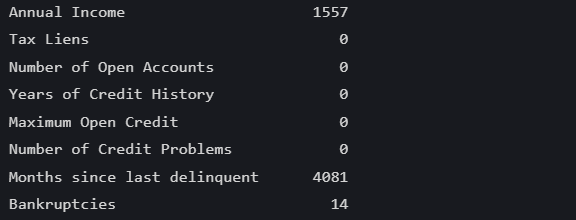
此时循环过列表的每一列,可以用均值来填补缺失
for i in data.columns:
if data[i].isnull().sum() > 0: # 找到存在缺失值的列
#计算该列的均值
fill_value = data[i].mean()
#用均值填充缺失值
data[i] = data[i].fillna(fill_value)再次查看:
data.isnull().sum()部分运行结果如下:
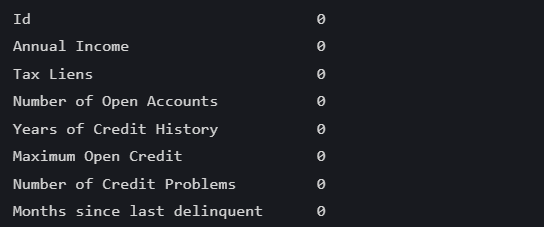
此时说明完成了确实值得填补


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









