






上市公司创新信息披露(1991-2023)
1863
数据简介
与传统词典法不同,本文采用“种子词集+Word2Vec相似词扩充”方法构建描述性创新信息指标。参考相关文献[11,28],对年报多次研读校验得到种子词集。相较于传统词法,Word2Vec神经网络模型可以根据语义信息将词汇转换为多维向量,并通过计算向量的相似度得到相似词。本文采用其中的CBOW(ContinuousBag-of-wordsModel)模型对中文语料进行训练。描述性创新关键词如见表1所示。
在构建描述性创新关键词词集后,本文以年报中描述性创新信息的总词频/年报总词频衡量描述性创新信息披露水平。在此基础上,本文采用当年除目标企业外其余同行企业描述性创新信息披露水平的算术平均数衡量同行描述性创新信息披露水平(Inno_Dis)。

数据来源
由数据皮皮侠团队人工整理,全部内容真实有效。
时间跨度
1991-2023
数据范围
中国A 股上市公司
数据形式
数据格式为Excel形式
数据指标

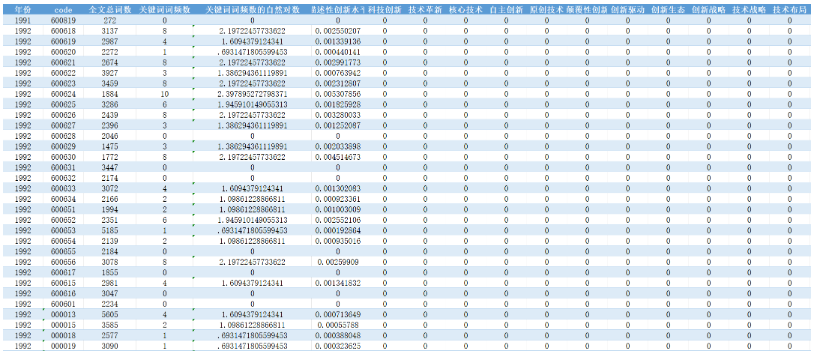
数据展示
参考文献
陈怡欣,张婷,马晨. 同行企业描述性创新信息披露的溢出效应——基于机器学习与文本分析法 [J]. 科技进步与对策, 2024, 41 (15): 22-32.
声明:本数据由数据皮皮侠团队整理,仅用于学术研究

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









