






开篇语
"当ChatGPT在3天内突破1亿用户时,我们正见证人类历史上最快技术革命。但AI大模型究竟是什么?它如何改变我们的工作与生活?本系列将带您穿透技术迷雾,探索AI大模型的本质与实践。"
一、AI大模型:重新定义智能的"数字大脑"
1. 核心定义
传统AI:针对单一任务训练(如人脸识别),需人工设计规则。
大模型(LLM):通过海量数据预训练的通用智能体,典型特征:
✅ 千亿级参数(GPT-4约1.8万亿)
✅ 涌现能力(未训练过的新任务也能完成)
✅ 多模态处理(文本/图像/代码/语音)
2. 突破性技术里程碑
2017:Transformer架构诞生
2020:GPT-3展现"上下文学习"能力
2023:多模态大模型爆发(GPT-4V、Gemini)
2024:RAG技术成熟:消除大模型“幻觉”
2025:DeepSeek的参数压缩与性能突破
3.大模型应用金句:
"大模型不是工具,而是新型生产力基础设施" —— 李彦宏,百度创始人
"未来十年,不会用AI的企业,就像今天不会用电的公司一样落后。" —— 黄仁勋(NVIDIA CEO)
"AI不会取代人类,但会用AI的人会取代不用AI的人。" —— 马斯克(特斯拉CEO)
"在工程设计领域,AI不是替代工程师,而是让工程师10倍高效。"—— Bentley Systems CTO
二、解剖大模型:三层核心架构
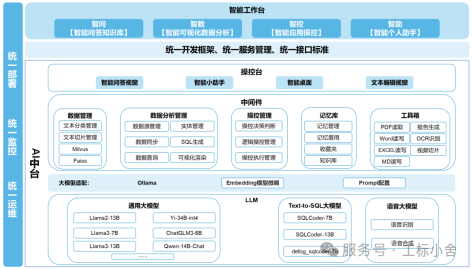
1.基础层:Transformer引擎
自注意力机制:动态捕捉词语关联
位置编码:理解文本顺序
2.能力层:预训练+微调
预训练:用互联网级数据建立通用认知
微调(Fine-tuning):注入领域知识
3.应用层:Prompt工程与工具链
Prompt设计模板
"你是一名结构工程师,请根据《GB50010-2010混凝土结构设计规范》,分析以下梁配筋方案是否合规:[输入具体参数]"
RAG技术:连接企业知识库
三、日常场景:大模型如何改变生活
| 场景 | 典型案例 | 技术原理 |
| 智能办公 | 自动生成会议纪要/PPT | 文本理解+结构化生成 |
| 教育辅助 | 数学题分步解析+错因诊断 | 逻辑推理+知识图谱关联 |
| 医疗咨询 | 症状分析+检查报告解读 | 多模态融合(文本+医学影像) |
| 创意设计 | 根据草图生成3D建模代码(如AutoCAD插件) | 图像-文本-代码跨模态转换 |
- 设计革命的"智能副驾"--行业痛点 vs 大模型解法
1:设计规范检索与知识管理
痛点:工程师需花费大量时间查阅设计规范、行业标准(如GB50010混凝土结构设计规范),人工检索效率低且易遗漏关键条款。
AI解决方案:知识库问答系统--基于RAG技术,生成行业知识库,支持自然语言提问直接定位条款。
2:多专业协同与BIM模型优化
痛点:建筑、结构、机电等专业模型易冲突,人工检查耗时且易出错。
AI解决方案:自动识别BIM模型中的管线碰撞,推荐优化方案检测。AI生成多专业协同建议,减少设计返工。
3:能源管理与低碳设计
痛点:建筑能耗高,传统节能设计依赖简单计算。
AI解决方案:能耗模拟--大模型分析建筑热力学数据,自动生成低碳方案
- 、小知识
问1:AI大模型计算为什么主要依赖GPU而不是CPU?
答1:并行计算能力差异
| CPU | GPU | |
| 1并行计算能力差异 | 体积较大通常只有只有几个到几十个核心(如Intel Xeon Platinum 8380为40核) | 拥有数千个计算核心(如NVIDIA A100有6912个CUDA核心) |
| 优化重点是低延迟的串行计算,能完成复杂任务。 | 专为并行计算设计,可同时处理大量简单计算任务 | |
| 2 内存带宽差异 | CPU内存带宽只能达到数十至数百GB/s | GPU显存带宽可达数TB/s带宽 |
| 3 专用计算架构 | CPU的AVX-512等指令集效率远低于GPU专用架构 | 现代GPU集成专用矩阵计算单元(NVIDIA的Tensor Core) 执行FP16/BF16矩阵运算速度是CPU的100倍以上。 |
正是神经网络的计算本质GPU硬件特性的高度契合,GPU中数以千个CUDA核心,可同时处理数千个矩阵元素计算。使得GPU在运算时速度提升90倍的同时,能耗降低80%。
GPU凭借其矩阵并行计算硬件化与成熟的CUDA生态,仍是支撑AI大模型发展的最优解。但随着算法演进与新型硬件突破,未来计算架构将呈现多元化发展态势。
PS:Deekseek在计算在推理场景的CPU进行适配化设计,减少了对NVIDIA CUDA的依赖,使其能够在CPU或非NVIDIA GPU(如AMD GPU、苹果M系列芯片)上运行。这一设计显著提升了在资源受限设备(如边缘计算终端、中小企业服务器)上的适用性。
问2:AI大模型的神经网络算法是什么?
答2:目前AI大模型主要依赖神经网络算法,因为神经网络具备独特的结构和能力,能够高效处理海量数据、学习复杂模式,并适应多种任务。
- 神经网络像人脑的简化版
神经网络就是模拟人脑学认物件的过程,但它用【数学公式】代替人脑的神经元。所以需要对大量的数据进行处理,这些数据通常以矩阵的形式存储。
- 神经网络的结构(像流水线)
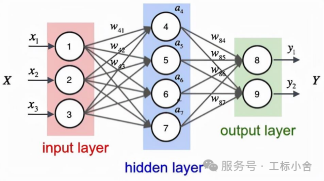
神经网络的90%计算可分解为矩阵乘法(GEMM)
1)输入层:接收数据(比如图片像素、文字、声音)
2)隐藏层:处理数据的“黑盒子”(可能有多层)
3)输出层:给出结果(比如分类、预测)
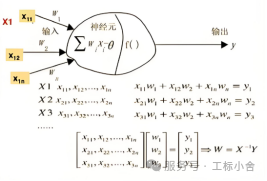
- 神经网络的“学习”就是调参数
1)权重(Weight):每条连接神经元的线都有一个权重,代表这个特征的重要性。
2)激活函数(Activation Function):决定信号是否传递下去。
- 训练过程(像老师批改作业)
1)试错:给网络大量带标签的数据
2)计算错误:比较网络输出和正确答案的差距(用损失函数)。
3)反向传播:把错误从输出层往回传,告诉每个神经元:“你该调整权重了!”
4)优化(梯度下降):微调权重和偏置,让错误越来越小。
- 为什么需要大量数据和算力?
数据:网络需要从大量例子中找规律,数据少容易学偏
算力:调整几百万个参数需要强大的计算(GPU加速)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









