







github:https://github.com/mlabonne/llm-course
大语言模型应用开发全流程实战指南:从运行、RAG到代理与安全部署
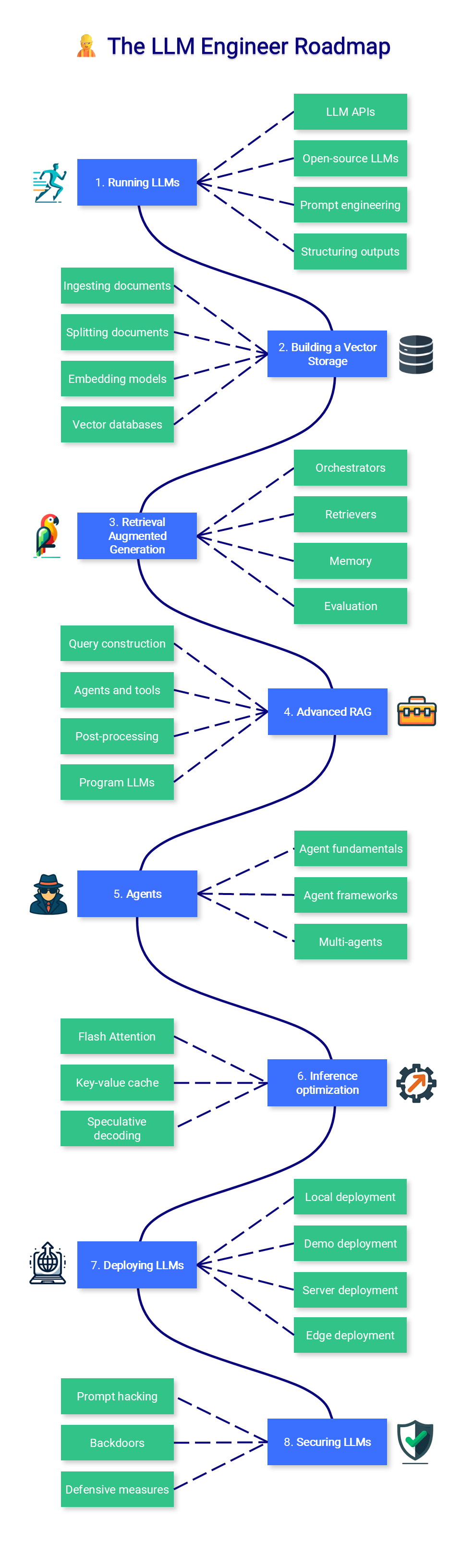
一、运行 LLM(Running LLMs)
由于硬件要求较高,运行 LLM 可能很困难。根据您的使用案例,您可能只想通过 API(如 GPT-4)使用模型或在本地运行它。在任何情况下,其他提示和指导技术都可以改进和限制应用程序的输出。
-
LLM API:API 是部署 LLM 的一种便捷方式。这个空间分为私有 LLM(OpenAI、Google、Anthropic 等)和开源 LLM(OpenRouter、Hugging Face、Together AI 等)。
-
开源 LLM:Hugging Face Hub 是查找 LLM 的好地方。您可以直接在 Hugging Face Spaces 中运行其中一些,也可以在 LM Studio 等应用程序中或通过 CLI 下载并运行它们llama.cpp 或 ollama。
-
提示工程:常见的技术包括 zero-shot prompting、few-shot prompting、chain of thought 和 ReAct。它们更适合较大的模型,但可以适应较小的模型。
-
结构化输出:许多任务需要结构化输出,例如严格模板或 JSON 格式。像 Outline 这样的库可以用来指导生成并遵循给定的结构。某些 API 还支持使用 JSON 架构原生生成结构化输出。
二、构建 Vector Storage(Building a Vector Storage)
创建矢量存储是构建检索增强生成 (RAG) 管道的第一步。文档被加载、拆分,并使用相关块来生成矢量表示(嵌入),这些向量表示(嵌入)被存储起来以备将来在推理期间使用。
-
摄取文档:文档加载器是方便的包装器,可以处理多种格式:PDF、JSON、HTML、Markdown 等。他们还可以直接从一些数据库和 API(GitHub、Reddit、Google Drive 等)中检索数据。
-
拆分文档:文本拆分器将文档分解为更小的、语义上有意义的块。与其在 n 个字符后拆分文本,不如按标题或递归方式拆分,并带有一些额外的元数据。
-
嵌入模型:嵌入模型将文本转换为矢量表示。选择特定于任务的模型可显著提高语义搜索和 RAG 的性能。
-
向量数据库:向量数据库(如 Chroma、Pinecone、Milvus、FAISS、Annoy 等)旨在存储嵌入向量。它们能够根据向量相似性高效检索与查询“最相似”的数据。
三、检索增强生成(Retrieval Augmented Generation)
借助 RAG,LLM 可以从数据库中检索上下文文档,以提高其答案的准确性。RAG 是一种无需任何微调即可增强模型知识的流行方法。
-
编排器:LangChain 和 LlamaIndex 等编排器是将 LLM 与工具和数据库连接起来的常用框架。模型上下文协议 (MCP) 引入了一个新标准,用于跨提供商将数据和上下文传递给模型。
-
检索器:查询重写器和生成检索器(如 CoRAG 和 HyDE)通过转换用户查询来增强搜索。多向量和混合检索方法将嵌入与关键字信号相结合,以提高召回率和准确性。
-
记忆:为了记住以前的说明和答案,LLM 和 ChatGPT 等聊天机器人将此历史记录添加到其上下文窗口中。该缓冲区可以通过汇总(例如,使用较小的 LLM)、载体存储 + RAG 等来改进。
-
评估:我们需要评估文档检索(上下文精度和召回率)和生成阶段(忠实度和答案相关性)。它可以通过 Ragas 和 DeepEval 工具(评估质量)进行简化。
四、高级 RAG(Advanced RAG)
实际应用程序可能需要复杂的管道,包括 SQL 或图形数据库,以及自动选择相关工具和 API。这些高级技术可以改进基线解决方案并提供其他功能。
-
查询构建:存储在传统数据库中的结构化数据需要特定的查询语言,如 SQL、Cypher、元数据等。我们可以直接将用户指令翻译成查询,通过查询构造来访问数据。
-
工具:代理通过自动选择最相关的工具来提供答案来增强 LLM。这些工具可以像使用 Google 或 Wikipedia 一样简单,也可以像 Python 解释器或 Jira 一样复杂。
-
Post-processing(后处理):处理馈送到 LLM 的输入的最后一步。它通过重新排序、RAG 融合和分类增强了检索到的文档的相关性和多样性。
-
程序 LLM:DSPy 等框架允许您以编程方式基于自动评估优化提示和权重。
五、代理(Agents)
LLM 代理可以通过根据对其环境的推理采取行动来自主执行任务,通常是通过使用工具或功能与外部系统交互。
-
代理基础:代理使用思想(内部推理来决定下一步做什么)、行动(执行任务,通常通过与外部工具交互)和观察(分析反馈或结果以改进下一步)来运作。
-
代理框架:可以使用不同的框架简化代理开发,例如 LangGraph(工作流的设计和可视化)、LlamaIndex(使用 RAG 的数据增强代理)或 smolagents(初学者友好的轻量级选项)。
-
多代理:更多实验性框架包括不同代理之间的协作,例如 CrewAI(基于角色的团队编排)、AutoGen(对话驱动的多代理系统)和 OpenAI Agents SDK(具有强大的 OpenAI 模型集成的生产就绪)。
六、推理优化 (Inference optimization)
文本生成是一个成本高昂的过程,需要昂贵的硬件。除了量化之外,还提出了各种技术来最大限度地提高吞吐量并降低推理成本。
-
Flash Attention:优化注意力机制,将其复杂度从二次转换为线性,从而加快训练和推理速度。
-
键值缓存:了解键值缓存以及多查询注意力 (MQA) 和分组查询注意力 (GQA) 中引入的改进。
-
推测性解码:使用小型模型生成草稿,然后由大型模型进行审查,以加快文本生成速度。
七、部署 LLM(Deploying LLMs)
大规模部署 LLM 是一项工程壮举,可能需要多个 GPU 集群。在其他场景中,可以以低得多的复杂度实现演示和本地应用程序。
-
本地部署:隐私是开源 LLM 相对于私有 LLM 的重要优势。本地 LLM 服务器(LM Studio、Ollama、oobabooga、kobold.cpp 等)利用这一优势来支持本地应用程序。
-
演示部署:Gradio 和 Streamlit 等框架有助于构建应用程序原型和共享演示。您还可以轻松地在线托管它们,例如使用 Hugging Face Spaces。
-
服务器部署:大规模部署 LLM 需要云(另请参阅 SkyPilot)或本地基础设施,并且通常利用优化的文本生成框架,如 TGI、vLLM 等。
-
边缘部署:在受限环境中,MLC LLM 和 mnn-llm 等高性能框架可以在 Web 浏览器、Android 和 iOS 中部署 LLM。
八、LLM 安全(Securing LLMs)
除了与软件相关的传统安全问题外,LLM 由于训练和提示的方式也存在独特的弱点。
-
Prompt hacking:与提示工程相关的不同技术,包括提示注入(劫持模型答案的额外指令)、数据/提示泄漏(检索其原始数据/提示)和越狱(制作提示以绕过安全功能)。
-
后门:攻击媒介可以通过毒害训练数据(例如,使用虚假信息)或创建后门(在推理过程中改变模型行为的秘密触发器)来针对训练数据本身。
-
防御措施:保护 LLM 应用程序的最佳方法是针对这些漏洞测试它们(例如,使用 red teaming 和 garak 等检查),并在生产环境中观察它们(使用像 langfuse 这样的框架)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









