







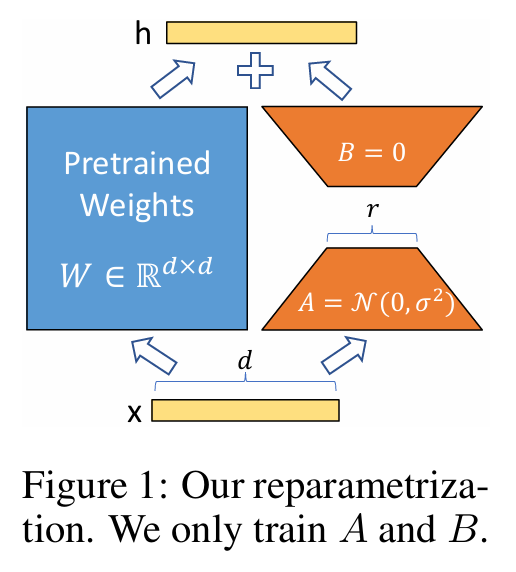
一、LoraConfig 模块详解
LoraConfig 是用于配置 LoRA(Low-Rank Adaptation) 微调方法的核心模块,它继承自 PeftConfig,提供了一系列参数来控制 LoRA 的行为。以下是关键参数及其对模型微调的影响:
1.1 核心参数及其作用
1.1.1 r(秩)
作用
定义 LoRA 适配器的低秩矩阵的维度(即“秩”),决定了参数更新的规模。
影响
-
较大的
r会增加适配器的参数数量,提升模型灵活性,但可能过拟合。 -
较小的
r减少计算量,但可能限制模型适应新任务的能力。 -
推荐范围:通常设置为
8、16或32,具体取决于任务复杂度。
1.1.2 target_modules(目标模块)
作用
指定需要应用 LoRA 的模型层(如 q_proj(查询投影)、v_proj(键投影)),支持正则表达式或列表。
影响
-
若未指定,PEFT 会自动推断架构,但对未知模型可能报错。
-
合理选择目标模块(如注意力层的
q、v)直接影响微调效果。
示例
target_modules=["q_proj", "v_proj"] 或 "all-linear"(选择所有的 linear/Conv1D 模块,除了输出层)。
注意力机制的核心层
选择q_proj(查询投影)和k_proj(键投影)的原因是:
-
这些层负责将输入映射到注意力空间的查询和键向量,直接影响模型对输入关系的建模能力。
-
相较于
v_proj(值投影)和o_proj(输出投影),调整q_proj和k_proj能更高效地改变注意力权重的分布,从而适应下游任务。
计算效率
仅选择部分模块(如q_proj和k_proj)而非全部注意力层,可以显著减少可训练参数量,提升训练速度。
1.1.3 lora_alpha(缩放因子)
作用
控制低秩矩阵的缩放幅度,与 r 共同决定权重更新的最终幅度。
影响
-
默认
lora_alpha/r(或lora_alpha/sqrt(r),若启用use_rslora)。 -
较大的
alpha会放大低秩矩阵的作用,增强适配效果,但需与r平衡。
1.1.4 lora_dropout(Dropout 率)
作用
在 LoRA 层中应用 Dropout 防止过拟合。
影响
-
较高的值(如
0.1)增强正则化,但可能削弱适配能力。 -
通常设为
0.0(默认)或较低值(如0.1)。
1.1.5 bias(偏置)
作用
是否在微调过程中更新模型的偏置(bias)参数。
参数选项
-
"none"(默认)
行为:冻结所有偏置参数,不进行更新。
适用场景:
-
希望保持预训练模型的稳定性,减少过拟合风险。
-
数据集较小,需要严格控制可训练参数数量。
-
"all"
行为:更新所有偏置参数,包括原始模型中的偏置和适配器可能引入的偏置(如有)。
适用场景:
-
需要最大灵活性,允许模型通过调整偏置更好地适配新任务。
-
数据集较大,能够支持更复杂的参数更新。
-
"lora_only"
行为:仅更新由 LoRA 适配器引入的偏置参数(若有)。
如果适配器未显式添加偏置(标准 LoRA 通常不引入偏置),则此选项无实际效果。
1.1.6 use_rslora(bool)
作用
用于控制是否启用 Rank-Stabilized LoRA(RS-LoRA)。
缩放因子调整
-
默认 LoRA:适配器的权重更新幅度由
lora_alpha / r控制。 -
RS-LoRA:将缩放因子调整为
lora_alpha / sqrt(r)。 -
数学意义:
-
当秩(
r)较小时,RS-LoRA 的缩放因子衰减更慢,避免因r过小导致更新幅度过大。 -
当
r增大时,缩放因子更平缓,提升训练稳定性。
-
性能优势
-
低秩场景(如
r=2或r=4):RS-LoRA 在实验中表现更优,尤其是在复杂任务(如生成、多分类)中,能更高效地利用低秩参数适配模型。 -
训练稳定性:通过调整缩放因子,减少梯度爆炸/消失风险,尤其适合深层模型或长序列任务。
适用场景
-
资源受限的低秩微调
-
复杂生成任务
-
长序列建模
1.1.7 modules_to_save(额外训练模块)
作用
指定除 LoRA 层外需要参与训练的其他模块(如分类头)。
示例
modules_to_save=["classifier"],适用于分类任务。
1.1.8 init_lora_weights(权重初始化)
作用
控制适配器权重的初始化方式,支持多种策略:
-
True:默认初始化。 -
"gaussian":高斯分布初始化。 -
"pissa":基于奇异值分解的快速初始化(收敛更快)。 -
"loftq":结合量化初始化(需配置loftq_config)。
影响
初始化策略直接影响训练稳定性和收敛速度。
1.1.9 use_dora(DoRA 开关)
作用
启用 权重分解低秩适应(DoRA),将权重更新分解为幅度和方向。
影响
-
在低秩(如
r=8)下性能显著优于普通 LoRA,但增加计算开销。 -
推荐在资源允许时启用。
1.2 微调时需重点关注的能力
1.2.1 任务适应能力
-
关键参数:
target_modules、r、lora_alpha。 -
通过调整目标模块和秩,控制模型对特定任务的适配程度。例如,选择注意力层的
q、v能有效提升模型对输入的理解能力。
1.2.2 参数效率与计算开销
-
关键参数:
r、use_dora、init_lora_weights。 -
较小的
r和高效初始化(如"pissa")可减少训练成本,同时保持性能。DoRA 虽增加开销,但能提升低秩下的表现。
1.2.3 抗过拟合能力
-
关键参数:
lora_dropout、modules_to_save。 -
合理设置 Dropout 和限制额外训练模块(如仅训练分类头)可防止过拟合。
1.2.4 量化与内存优化
-
关键参数:
loftq_config、init_lora_weights="loftq"。 -
通过 LoftQ 量化主干模型权重,可在有限内存下训练大模型(如 4-bit 量化)。
1.2.5 分布式训练兼容性
-
关键参数:
megatron_config、megatron_core。 -
在 Megatron 框架下训练时,需正确配置并行线性层参数。
1.3 使用建议
-
需要量化时,启用
loftq_config并设置init_lora_weights="loftq"。 -
追求更高性能时,启用
use_dora=True并适当增大r。 -
分布式训练需配置
megatron_config和megatron_core。
1.4 unsloth 中额外参数
finetune_vision_layers=True, # False if not finetuning vision layers
finetune_language_layers=True, # False if not finetuning language layers
finetune_attention_modules=True, # False if not finetuning attention layers
finetune_mlp_modules=True, # False if not finetuning MLP layers
二、TaskType 模块概述
TaskType 是一个枚举类,用于标准化 PEFT 框架支持的任务类型。它定义了模型微调过程中不同的下游任务类型,帮助用户明确任务目标并适配相应的参数高效微调策略。
2.1 支持的 TaskType 枚举值及含义
2.1.1 SEQ_CLS(文本分类)
-
任务类型:对整段文本进行分类(如情感分析、主题分类)。
-
模型输出:分类标签(如
positive/negative)。 -
示例场景:
from peft import TaskType config = LoraConfig(task_type=TaskType.SEQ_CLS)
2.1.2 SEQ_2_SEQ_LM(序列到序列语言建模)
-
任务类型:生成式任务,输入和输出均为序列(如翻译、摘要)。
-
模型输出:生成的目标序列。
-
示例场景:
config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM)2.1.3 CAUSAL_LM(因果语言建模)
-
任务类型:自回归生成任务(如文本续写、对话生成)。
-
模型输出:基于上文预测下一个词。
-
示例场景:
config = LoraConfig(task_type=TaskType.CAUSAL_LM)2.1.4 TOKEN_CLS(词元分类)
-
任务类型:对每个词元进行分类(如命名实体识别、词性标注)。
-
模型输出:每个词元对应的标签。
-
示例场景:
config = LoraConfig(task_type=TaskType.TOKEN_CLS)2.1.5 QUESTION_ANS(问答任务)
-
任务类型:基于上下文回答特定问题。
-
模型输出:答案的起始和结束位置。
-
示例场景:
config = LoraConfig(task_type=TaskType.QUESTION_ANS)2.1.6 FEATURE_EXTRACTION(特征提取)
-
任务类型:提取文本的隐藏表示(如生成句子嵌入)。
-
模型输出:最后一层(或指定层)的隐藏状态。
-
示例场景:
config = LoraConfig(task_type=TaskType.FEATURE_EXTRACTION)2.2 TaskType 的核心作用
2.2.1 指导模型适配器设计
-
不同任务类型需要不同的输出头(如分类器 vs 生成器),
TaskType帮助框架自动选择适配结构。 -
例如:
-
SEQ_CLS任务会在模型顶部添加分类层。 -
CAUSAL_LM任务会保留自回归生成能力。
-
2.2.2 优化训练流程
影响损失函数计算方式:
-
分类任务使用交叉熵损失。
-
生成任务使用语言建模损失(如交叉熵对生成词元的损失)。
2.2.23 控制参数更新范围
-
部分 PEFT 方法(如 IA3)会根据任务类型选择性地调整特定模块(如注意力 Key/Value 投影)。
2.3 选择 TaskType 的关键考量
2.3.1 任务本质
-
生成任务(如对话、翻译)→
SEQ_2_SEQ_LM或CAUSAL_LM。 -
结构化预测(如 NER)→
TOKEN_CLS。
2.3.2 模型架构兼容性
-
CAUSAL_LM通常用于 GPT、LLaMA 等自回归模型。 -
SEQ_2_SEQ_LM适用于 T5、BART 等编码器-解码器架构。
2.3.3 CAUSAL_LM(因果语言建模)
-
对于目前的大模型,基本上都是该类别
-
只有对于某一个专有领域的模型,才会选择其他的类别
三、加载配置
3.1 peft 加载
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained('llama-7b', device_map="auto",
torch_dtype=torch.bfloat16, use_cache=False)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=4,
target_modules=[
"q_proj", "v_proj", # 核心注意力
],
lora_dropout=0.05,
)
peft_model = get_peft_model(model, peft_config)3.2 unsloth 加载
from unsloth import FastVisionModel
model, tokenizer = FastVisionModel.from_pretrained(
"LLM-Research/Llama-3.2-11B-Vision-Instruct",
dtype=torch.bfloat16
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=True, # False if not finetuning vision layers
finetune_language_layers=True, # False if not finetuning language layers
finetune_attention_modules=True, # False if not finetuning attention layers
finetune_mlp_modules=True, # False if not finetuning MLP layers
r=16, # The larger, the higher the accuracy, but might overfit
lora_alpha=16, # Recommended alpha == r at least
lora_dropout=0,
bias="none",
random_state=3407,
use_rslora=False, # We support rank stabilized LoRA
loftq_config=None, # And LoftQ
# target_modules = "all-linear", # Optional now! Can specify a list if needed
)
















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









