






概览
-
系统阐述了大模型训练的微调方法,涵盖prompt tuning、prefix tuning、LoRA、p-tuning及AdaLoRA等技术方案。
-
详细解析了基于deepspeed框架结合LoRA技术的大模型训练实现代码。
-
介绍了petals分布式训练框架,其通过将模型划分为多个模块,由不同用户设备分别负责计算,有效实现了计算压力的分布式处理。
理解篇
prompt tuning
20210302
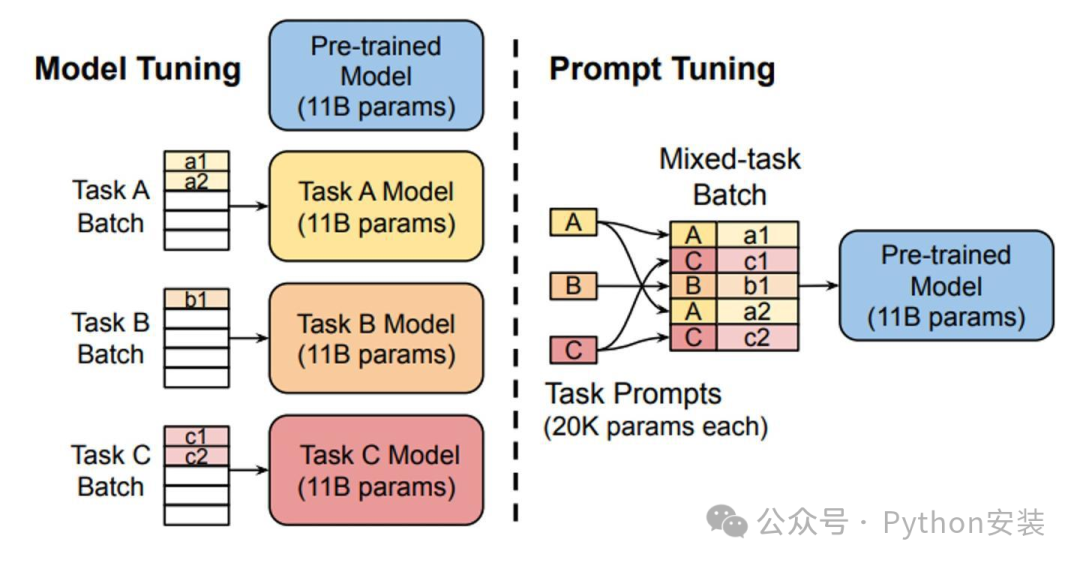
采用固定预训练参数的方法,为每个任务单独引入一个或多个可训练的embedding向量。这些embedding与query进行拼接后,作为常规输入传递给大语言模型(LLM),且仅对这些embedding进行训练。图中左侧展示了单任务全参数微调的方法,右侧则呈现了prompt tuning的实现方式。
-
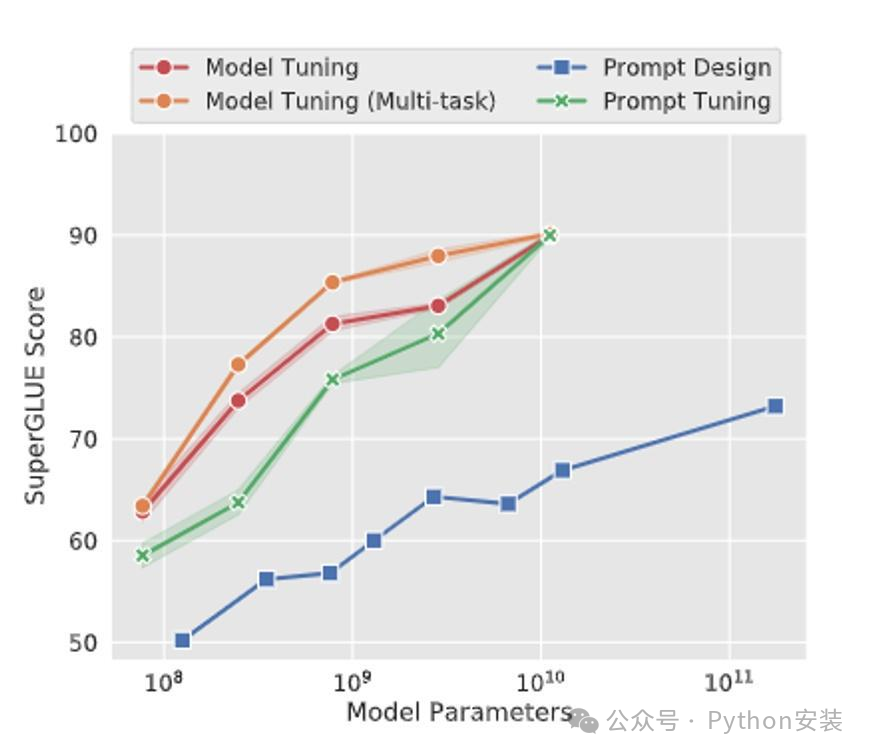
标准的T5模型(橙色线)多任务微调实现了强大的性能,但需要为每个任务存储单独的模型副本。
-
prompt tuning也会随着参数量增大而效果变好,同时使得单个冻结模型可重复使用于所有任务。
-
显著优于使用GPT-3进行fewshot prompt设计。
-
当参数达到100亿规模与全参数微调方式效果无异。
代码样例:
from peft import PromptTuningConfig, get_peft_model
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
prefix tuning
20210801
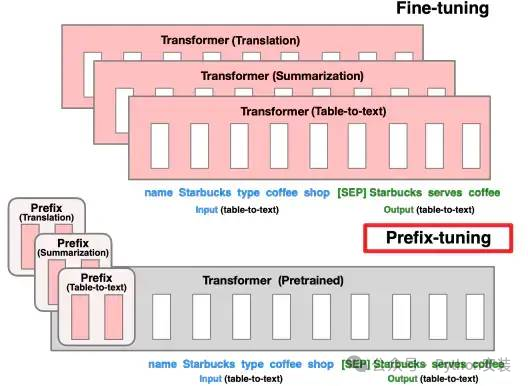
Prefix tuning 在保持预训练模型参数固定的基础上,通过为每个任务引入额外的 embedding 来实现任务适配。与 prompt tuning 不同,它采用多层感知机(MLP)作为 prefix 的编码器,而非将 prefix 直接输入到大型语言模型(LLM)中。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
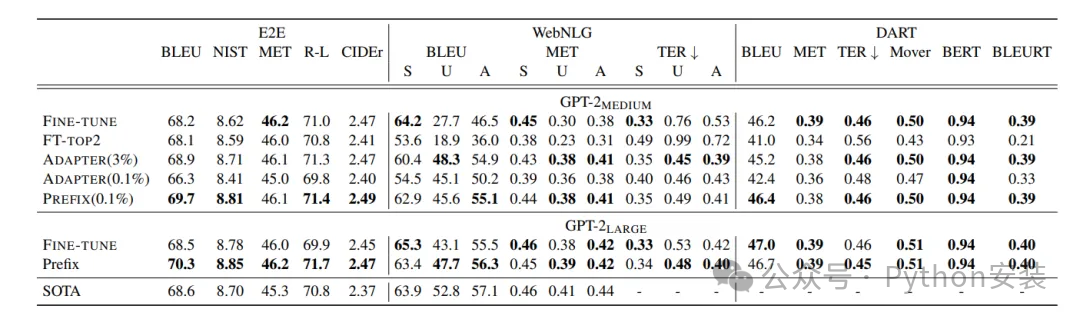
在三个数据集中prefix和全参数微调的表现对比:
代码样例:
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
LoRA
20210816
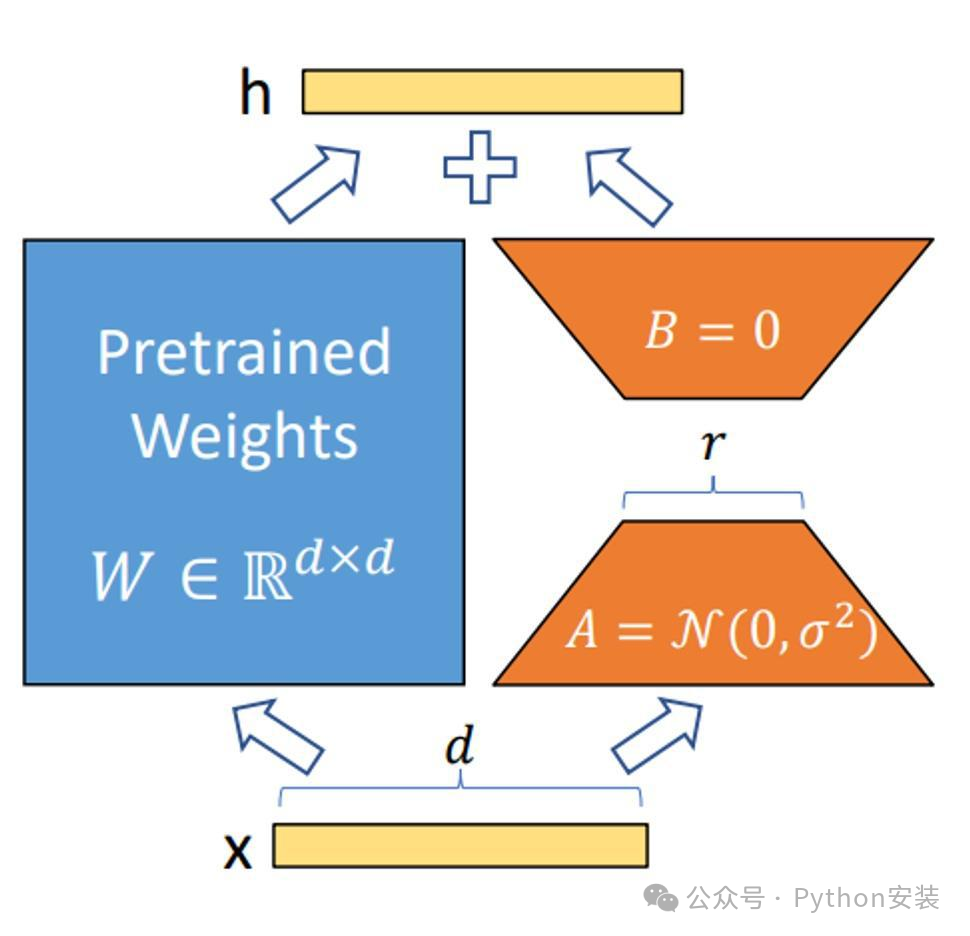
LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数
那么,LoRA是否能达到全参数微调的性能呢?
根据实验可知,全参数微调要比LoRA方式好的多,但在低资源的情况下也不失为一种选择
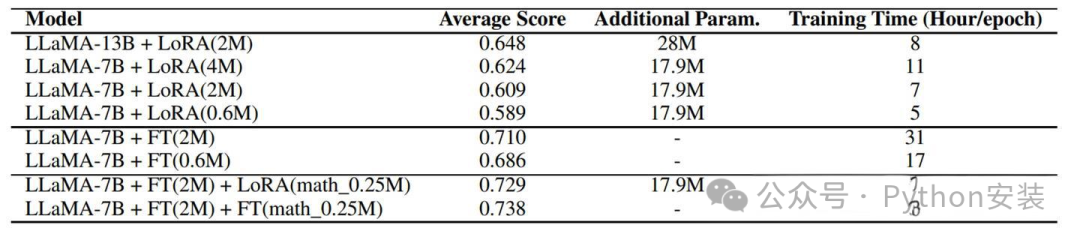
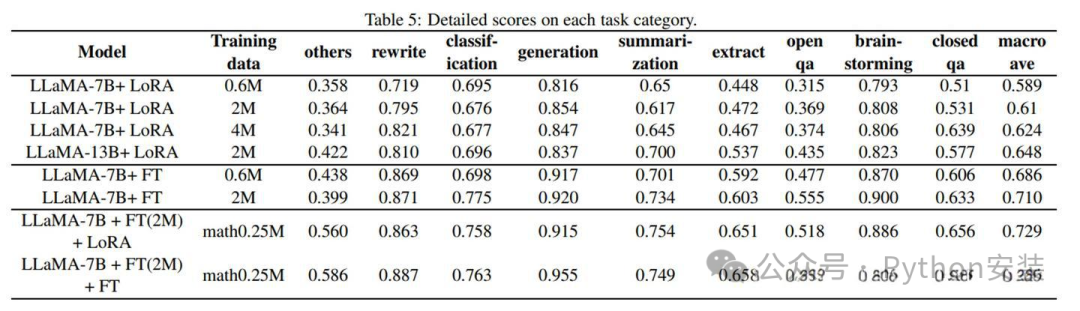
细致到每个任务中的差距如下图:
代码样例:
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
p-tuning
20211102
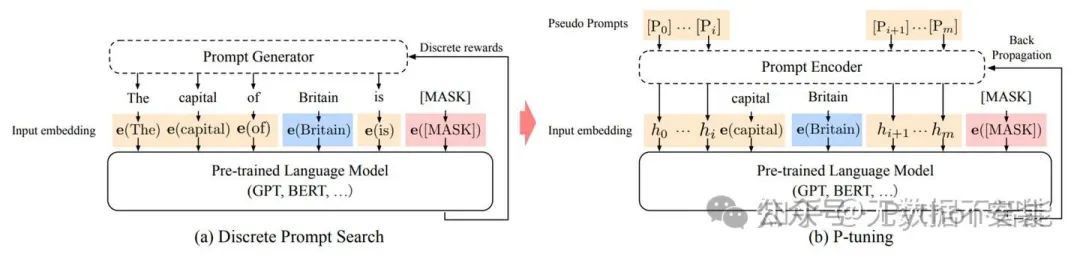
手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法(作图),但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
self.lstm_head = torch.nn.LSTM(
input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
dropout=lstm_dropout,
bidirectional=True,
batch_first=True,
)
self.mlp_head = torch.nn.Sequential(
torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),
torch.nn.ReLU(),
torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
以上代码可清晰展示出prompt编码器的结构。
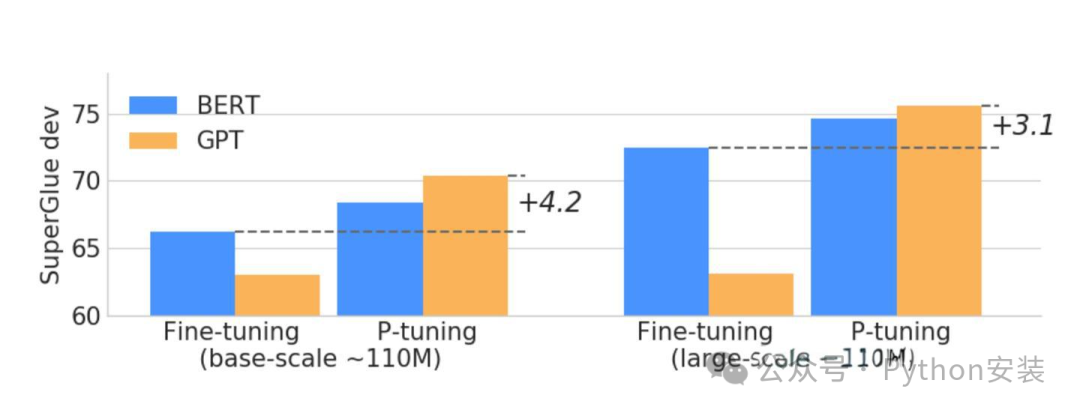
如上图所示,GPT在P-tuning的加持下可达到甚至超过BERT在NLU领域的性能。下图是细致的对比:
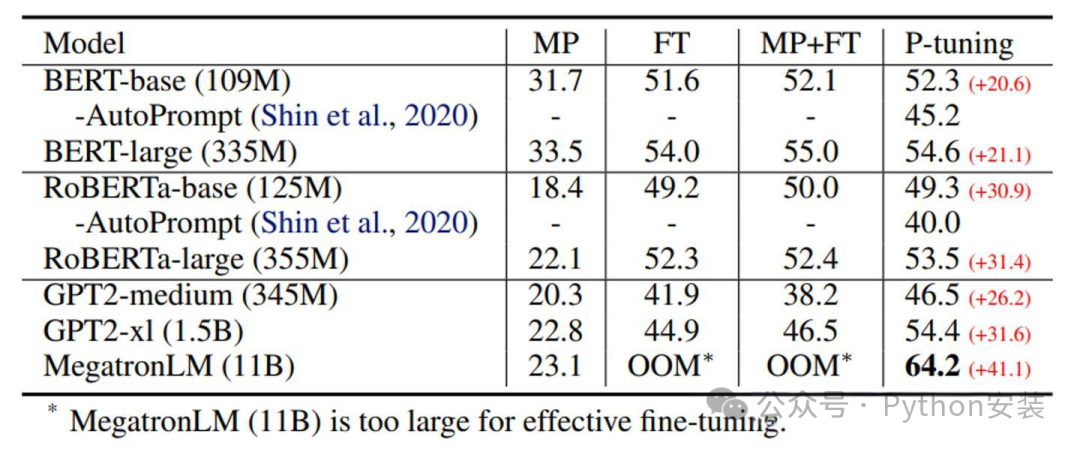
MP: Manual prompt
FT: Fine-tuning
MP+FT: Manual prompt augmented fine-tuning
PT: P-tuning
代码样例:
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
p-tuning v2
20220320
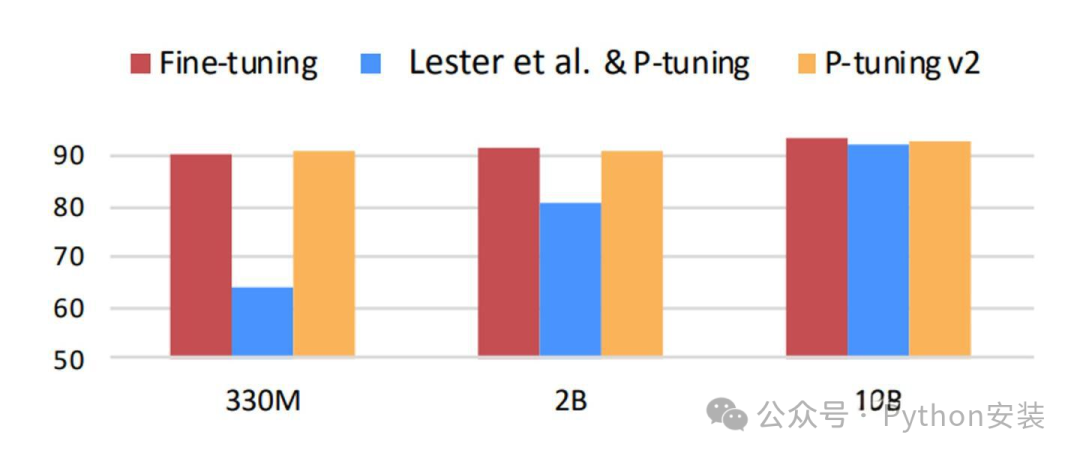
p-tuning 在小参数量模型上的表现欠佳(如图所示),这促使了 V2 版本的诞生。该版本借鉴了 LoRA 的思路,在每层网络中嵌入新的参数(称为 Deep FT)。从图中可以明显看出,p-tuning v2 整合了多种微调方法。它在多个任务上进行微调后,针对不同任务(如 token classification 和 sentence classification)采用了随机初始化的任务头(AutoModelForTokenClassification、AutoModelForSequenceClassification),而非依赖自然语言方式。可以说,V2 版本是集多种优势于一体的解决方案。
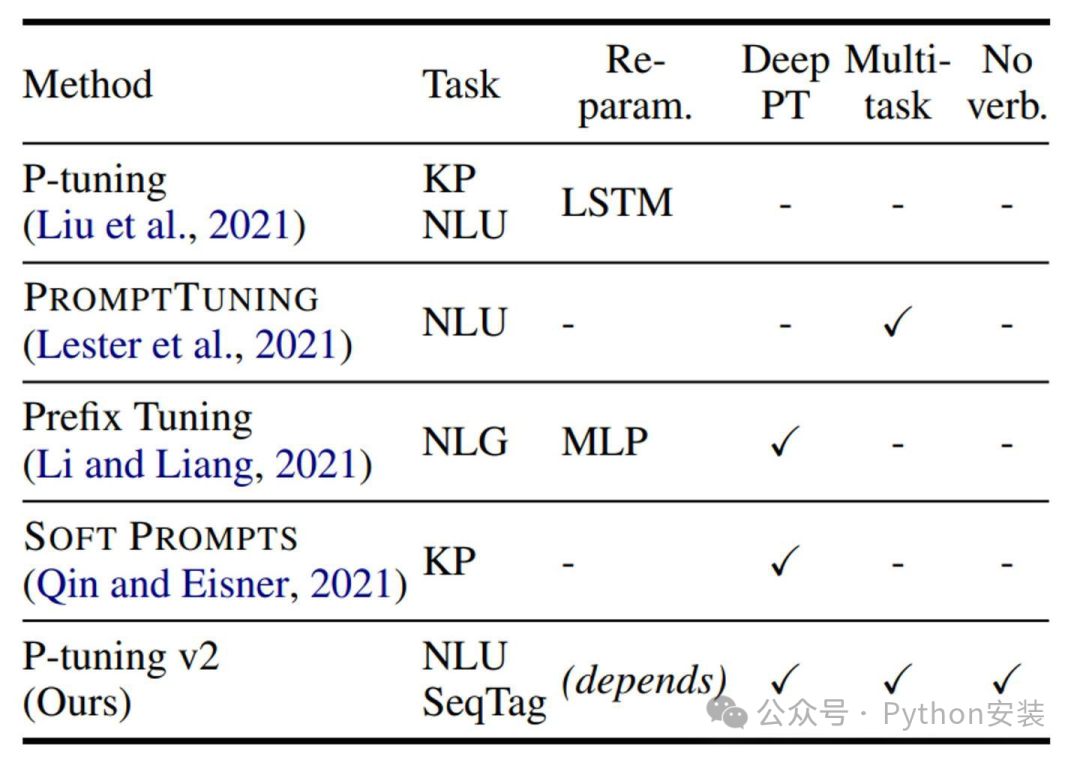
KP: Knowledge Probe,知识探针,用于检测LLM的世界知识掌握能力:
SeqTag: Sequence Tagging,如抽取式问答、命名实体识别
Re-param.:Reparameterization,对提示词做单独的编码器
No verb.: No verbalizer,不直接使用LLM head而接一个随机初始化的linear head
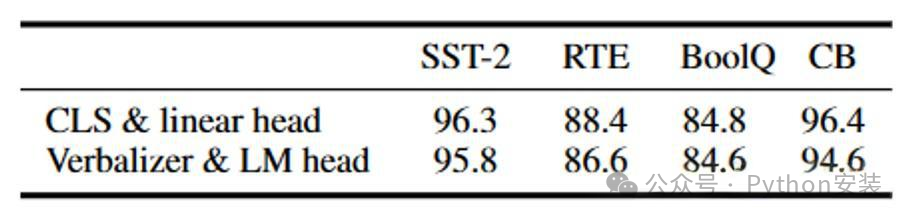
以下表格对比了[CLS] label linear head 和 verbalizer with LM head,[CLS] label linear head的方式药略好。
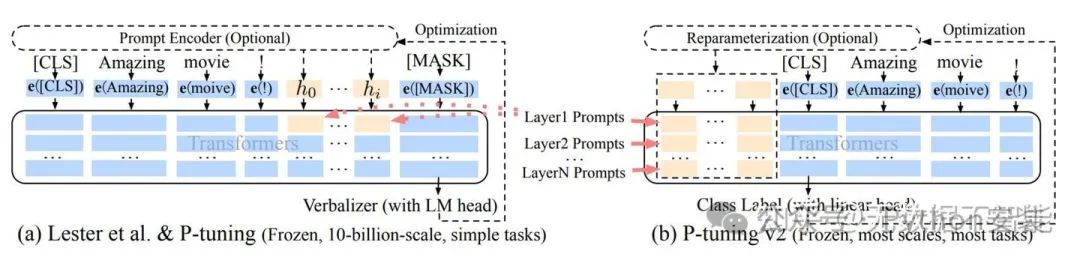
v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分
下图中对比了FT、PT、PT-2三种方法,粗体为性能最好的,下划线为性能次好的。

代码样例:
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
AdaLoRA
20230318
预训练语言模型中,各权重参数对下游任务的影响程度存在显著差异。为提升微调效率,需要采用智能化的参数预算分配策略,优先更新对模型性能提升贡献更大的关键参数。
具体而言,我们采用奇异值分解技术将权重矩阵分解为增量矩阵,并基于新定义的重要性度量指标动态调节各增量矩阵中的奇异值。这种机制确保在模型微调过程中,仅对性能提升显著或关键性参数进行更新,从而在提升模型性能的同时,显著提高了参数使用效率。
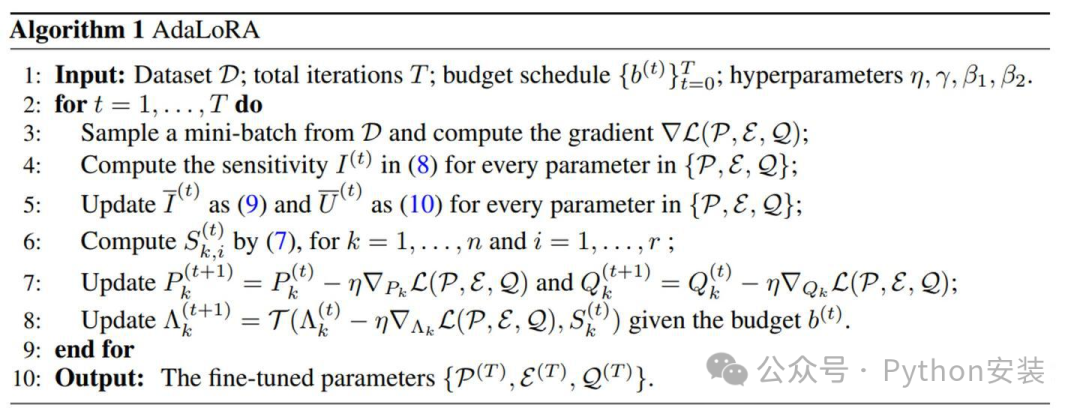
详细的算法如下:
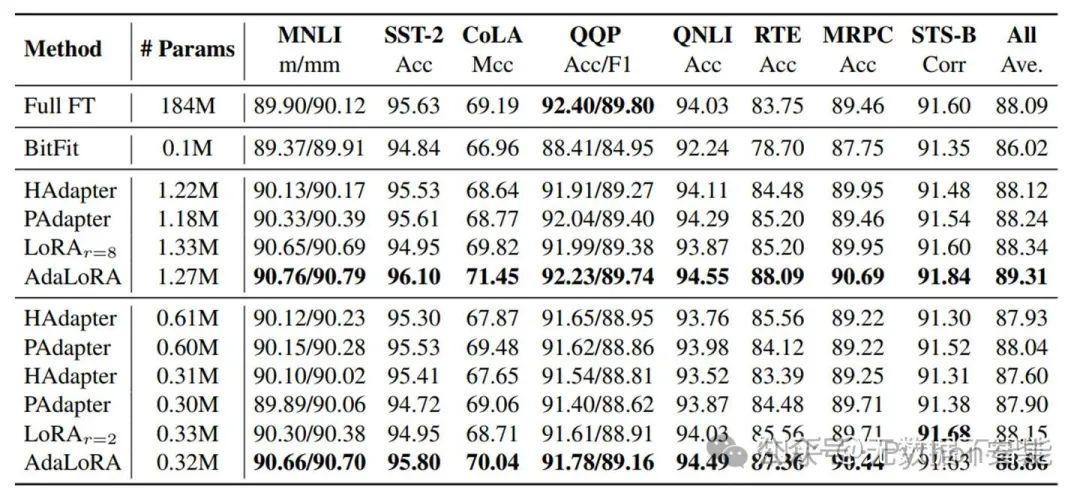
对比不同方法的性能:
代码样例:
peft_config = AdaLoraConfig(peft_type="ADALORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],lora_dropout=0.01)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
代码篇
注:以下代码在pytorch 1.12.1版本下运行,其他包都是最新版本
deepspeed
官方的demo所需要的配置如下:
| GPU SKUs | OPT-1.3B | OPT-6.7B | OPT-13.2B | OPT-30B | OPT-66B | Bloom-175B |
|---|---|---|---|---|---|---|
| 1x V100 32G | 1.8 days |
|
|
|
|
|
| 1x A6000 48G | 1.1 days | 5.6 days |
|
|
|
|
| 1x A100 40G | 15.4 hrs | 3.4 days |
|
|
|
|
| 1x A100 80G | 11.7 hrs | 1.7 days | 4.9 days |
|
|
|
| 8x A100 40G | 2 hrs | 5.7 hrs | 10.8 hrs | 1.85 days |
|
|
| 8x A100 80G | 1.4 hrs($45) | 4.1 hrs ($132) | 9 hrs ($290) | 18 hrs ($580) | 2.1 days ($1620) |
|
| 64x A100 80G | 31 minutes | 51 minutes | 1.25 hrs ($320) | 4 hrs ($1024) | 7.5 hrs ($1920) | 20 hrs ($5120) |
注意到官方给的样例单卡V100只能训练13亿规模的模型,如果换成67亿是否能跑起来呢?
按照官方文档搭建环境:
pip install deepspeed>=0.9.0
git clone <https://github.com/microsoft/DeepSpeedExamples.git>
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
pip install -r requirements.txt
请注意如果你之前装了deepspeed,请更新至0.9.0
试试全参数微调,这毫无疑问OOM
deepspeed --num_gpus 1 main.py \\
--data_path Dahoas/rm-static \\
--data_split 2,4,4 \\
--model_name_or_path facebook/opt-6.5b \\
--gradient_accumulation_steps 2 \\
--lora_dim 128 \\
--zero_stage 0 \\
--deepspeed \\
--output_dir $OUTPUT \\
&> $OUTPUT/training.log
答案是:我们需要卸载,这次便能愉快的run起来了
deepspeed main.py \\
--data_path Dahoas/rm-static \\
--data_split 2,4,4 \\
--model_name_or_path facebook/opt-6.7b \\
--per_device_train_batch_size 4 \\
--per_device_eval_batch_size 4 \\
--max_seq_len 512 \\
--learning_rate 9.65e-6 \\
--weight_decay 0.1 \\
--num_train_epochs 2 \\
--gradient_accumulation_steps 1 \\
--lr_scheduler_type cosine \\
--num_warmup_steps 0 \\
--seed 1234 \\
--lora_dim 128 \\
--gradient_checkpointing \\
--zero_stage 3 \\
--deepspeed \\
--output_dir $OUTPUT_PATH \\
&> $OUTPUT_PATH/training.log
可以加上LoRA
deepspeed --num_gpus 1 main.py \\
--data_path Dahoas/rm-static \\
--data_split 2,4,4 \\
--model_name_or_path facebook/opt-6.7b \\
--per_device_train_batch_size 8 \\
--per_device_eval_batch_size 8 \\
--max_seq_len 512 \\
--learning_rate 1e-3 \\
--weight_decay 0.1 \\
--num_train_epochs 2 \\
--gradient_accumulation_steps 16 \\
--lr_scheduler_type cosine \\
--num_warmup_steps 0 \\
--seed 1234 \\
--gradient_checkpointing \\
--zero_stage 0 \\
--lora_dim 128 \\
--lora_module_name decoder.layers. \\
--deepspeed \\
--output_dir $OUTPUT_PATH \\
&> $OUTPUT_PATH/training.log
peft
以下代码省略了数据处理
初始化
from datasets import load_dataset,load_from_disk
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,default_data_collator
from peft import prepare_model_for_int8_training, LoraConfig, get_peft_model
MICRO_BATCH_SIZE = 1
BATCH_SIZE = 1
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
EPOCHS = 3
LEARNING_RATE = 3e-6
CUTOFF_LEN = 256
LORA_R = 16
LORA_ALPHA = 32
LORA_DROPOUT = 0.05
模型加载,并使用int8进行训练
model_path = "facebook/opt-6.7b"
output_dir = "model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, add_eos_token=True)
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=None,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
tokenizer.pad_token_id = 0
data = load_from_disk("data")
训练与保存
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
eval_dataset=data["validation"],
args=transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
per_device_eval_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
warmup_steps=1000,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
# bf16=True,
fp16=True,
logging_steps=1,
output_dir=output_dir,
save_total_limit=4,
),
data_collator=default_data_collator,
)
model.config.use_cache = False
trainer.train(resume_from_checkpoint=False)
model.save_pretrained(output_dir)
直接这么启动当然会OOM,依然需要卸载
编写accelerate配置文件accelerate.yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'yes'
dynamo_backend: 'yes'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: fp16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
use_cpu: true
deepspeed配置文件:ds.json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 500,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": 1e-8,
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 2e-05,
"warmup_num_steps": 0
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": false
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps":2,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": 4,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": false
}
启动
accelerate launch --dynamo_backend=nvfuser --config_file accelearte.yaml finetune.py
注:其他方法与Lora使用方法差距不大,不再赘述,在peft项目中均有代码样例。
顺便提一嘴:petals
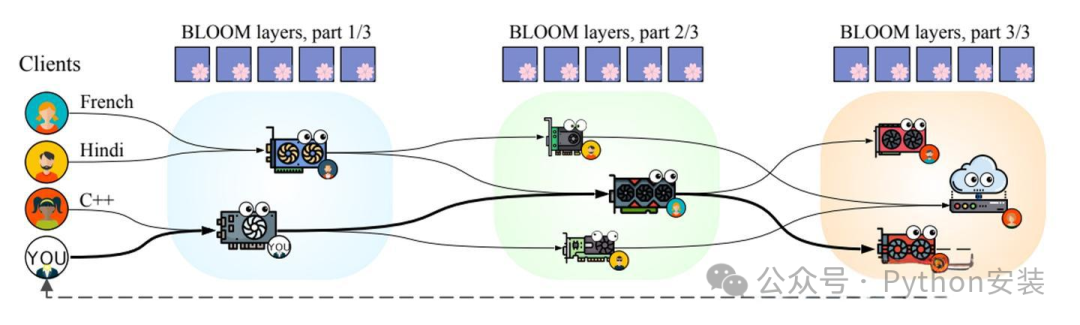
petals采用分布式架构,将模型划分为多个块并分配给不同用户的设备,有效分摊了计算负载。这一机制类似于磁力链接下载工具的分片原理,并借助hivemind库实现去中心化的训练与推理。此外,用户还可创建局域网群组,对私有模型进行分块处理等定制化操作。
import torch
import torch.nn.functional as F
import transformers
from petals import DistributedBloomForCausalLM
initial_peers = [TODO_put_one_or_more_server_addresses_here] # e.g. ["/ip4/127.0.0.1/tcp/more/stuff/here"]
tokenizer = transformers.BloomTokenizerFast.from_pretrained("bigscience/bloom-petals")
model = DistributedBloomForCausalLM.from_pretrained("bigscience/bloom-petals", initial_peers=initial_peers)
inputs = tokenizer("a cat sat", return_tensors="pt")["input_ids"]
remote_outputs = model.generate(inputs, max_length=10)
print(tokenizer.decode(remote_outputs[0]))
model.transformer.word_embeddings.weight.requires_grad = True
outputs = model.forward(input_ids=inputs)
loss = F.cross_entropy(outputs.logits.flatten(0, 1), inputs.flatten())
loss.backward()
print("Gradients (norm):", model.transformer.word_embeddings.weight.grad.norm())


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









