







PyTorch是学术界最为推崇的深度框架。
1.模型定义
torch.nn下的容器
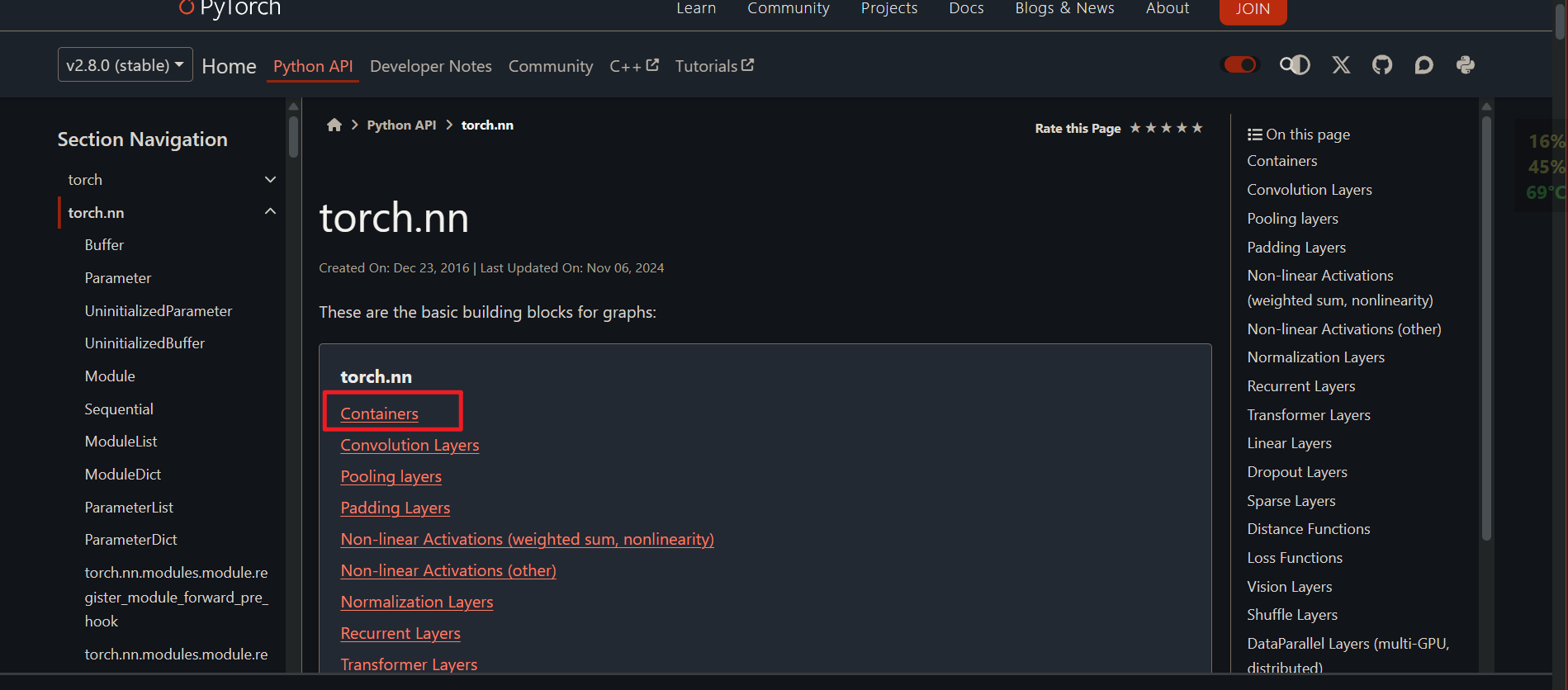
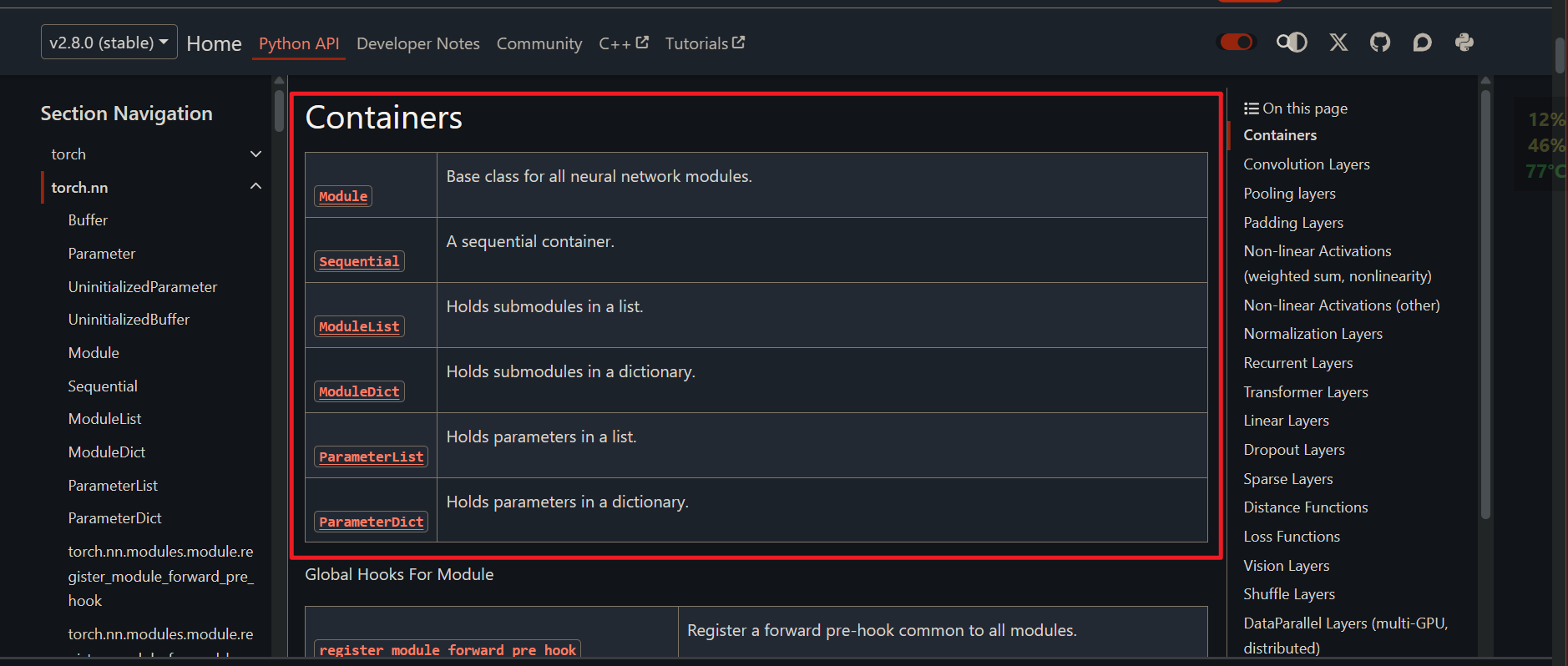
以上是PyTorch支持的所有容器类型。
1.1 Sequential
nn.Sequential()是pytorch的容器,按照顺序组合多个网络层,内部有forward方法,会定义前向传播的逻辑。
import torch
import numpy as np
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# 2. 定义前向模型
import torch.nn as nn
# 方案1:顺序容器——支持多参数网络,本例非常简单,只有一层
model = nn.Sequential(
nn.Linear(1, 1) # 顺序容器的网络内容:线性,1输入1输出
)
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数
for n in range(1, epochs + 1):
# 4.1 前向传播
y_pre = model(x_train.unsqueeze(1)) # 参数是n*m的输入矩阵
# print(y_pre) # 预测值
# 计算损失函数
loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
y_train # 参数2: 真实值
)
# 清空之前优化器重存储的梯度参数,以便于本次epoch重新进行反向传播
optimizer.zero_grad()
# 4.2 反向传播
loss.backward()
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{loss}")
print("-----------------------------------")
# 更新参数,例如w新 = 学习率与w旧的计算
optimizer.step()
1.2 ModuleList
nn.ModuleList() 和python的基础数据类型list类似,按照顺序,没有forward方法,不可以定义名字,可以用append加网络。
如果使用需要重写继承nn.Module
import torch
import numpy as np
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# 2. 定义前向模型
import torch.nn as nn
# -------------------------------------------------------
# 方案2:继承nn.Module
class LinearModel(nn.Module):
# 构造函数:初始化
def __init__(self):
# 调用父类的构造函数
super(LinearModel, self).__init__()
# ModuleList,支持多网络结构(本例只有一个网络层)
self.layers = nn.ModuleList(
[nn.Linear(1, 1)] # 参数为多个网络层结构,使用list传入
)
def forward(self, x):
"""
前向传播方法
:param x: 输入张量
:return: 网络层处理后的输出张量
"""
# 遍历列表多个网络层
for layer in self.layers:
x = layer(x)
return x
# 创建模型对象
model = LinearModel()
# -------------------------------------------------------
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数
for n in range(1, epochs + 1):
# 4.1 前向传播
y_pre = model(x_train.unsqueeze(1)) # 参数是n*m的输入矩阵
# print(y_pre) # 预测值
# 计算损失函数
loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
y_train # 参数2: 真实值
)
# 清空之前优化器重存储的梯度参数,以便于本次epoch重新进行反向传播
optimizer.zero_grad()
# 4.2 反向传播
loss.backward()
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{loss}")
print("-----------------------------------")
# 更新参数,例如w新 = 学习率与w旧的计算
optimizer.step()
1.3 ModuleDict
nn.ModuleDict(),和dict类似,不按照顺序,没有forward方法,可以定义每层的名字。
import torch
import numpy as np
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# 2. 定义前向模型
import torch.nn as nn
# -------------------------------------------------------
# 方案3:
class LinearModel(nn.Module):
# 构造函数:初始化
def __init__(self):
# 调用父类的构造函数
super(LinearModel, self).__init__()
# ModuleDict,支持多网络结构(本例只有一个网络层)
self.layers = nn.ModuleDict(
{"Linear1": nn.Linear(1, 1)} # 参数为多个网络层结构,使用dict传入
)
def forward(self, x):
"""
前向传播方法
:param x: 输入张量
:return: 网络层处理后的输出张量
"""
# 遍历列表多个网络层
for key in self.layers:
x = self.layers[key](x)
return x
# -------------------------------------------------------
# 创建模型对象
model = LinearModel()
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数
for n in range(1, epochs + 1):
# 4.1 前向传播
y_pre = model(x_train.unsqueeze(1)) # 参数是n*m的输入矩阵
# print(y_pre) # 预测值
# 计算损失函数
loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
y_train # 参数2: 真实值
)
# 清空之前优化器重存储的梯度参数,以便于本次epoch重新进行反向传播
optimizer.zero_grad()
# 4.2 反向传播
loss.backward()
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{loss}")
print("-----------------------------------")
# 更新参数,例如w新 = 学习率与w旧的计算
optimizer.step()
1.4 手动编写
最常用的网络结构,直接重写继承nn.Module
import torch
import numpy as np
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# 2. 定义前向模型
import torch.nn as nn
# -------------------------------------------------------
# 方案4:
class LinearModel(nn.Module):
# 构造函数:初始化
def __init__(self):
# 调用父类的构造函数
super(LinearModel, self).__init__()
# ModuleDict,支持多网络结构(本例只有一个网络层)
self.layer1 = nn.Linear(1, 1)
# self.layer2 = nn.Linear(1, 1) # 如果是两个网络层是这样的
def forward(self, x):
"""
前向传播方法
:param x: 输入张量
:return: 网络层处理后的输出张量
"""
# 多个网络层连接
x = self.layer1(x)
# x = self.layer2(x)
return x
# -------------------------------------------------------
# 创建模型对象
model = LinearModel()
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数
for n in range(1, epochs + 1):
# 4.1 前向传播
y_pre = model(x_train.unsqueeze(1)) # 参数是n*m的输入矩阵
# print(y_pre) # 预测值
# 计算损失函数
loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
y_train # 参数2: 真实值
)
# 清空之前优化器重存储的梯度参数,以便于本次epoch重新进行反向传播
optimizer.zero_grad()
# 4.2 反向传播
loss.backward()
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{loss}")
print("-----------------------------------")
# 更新参数,例如w新 = 学习率与w旧的计算
optmizer.step()
2. 数据集加载
pytroch文档中的数据集加载的API
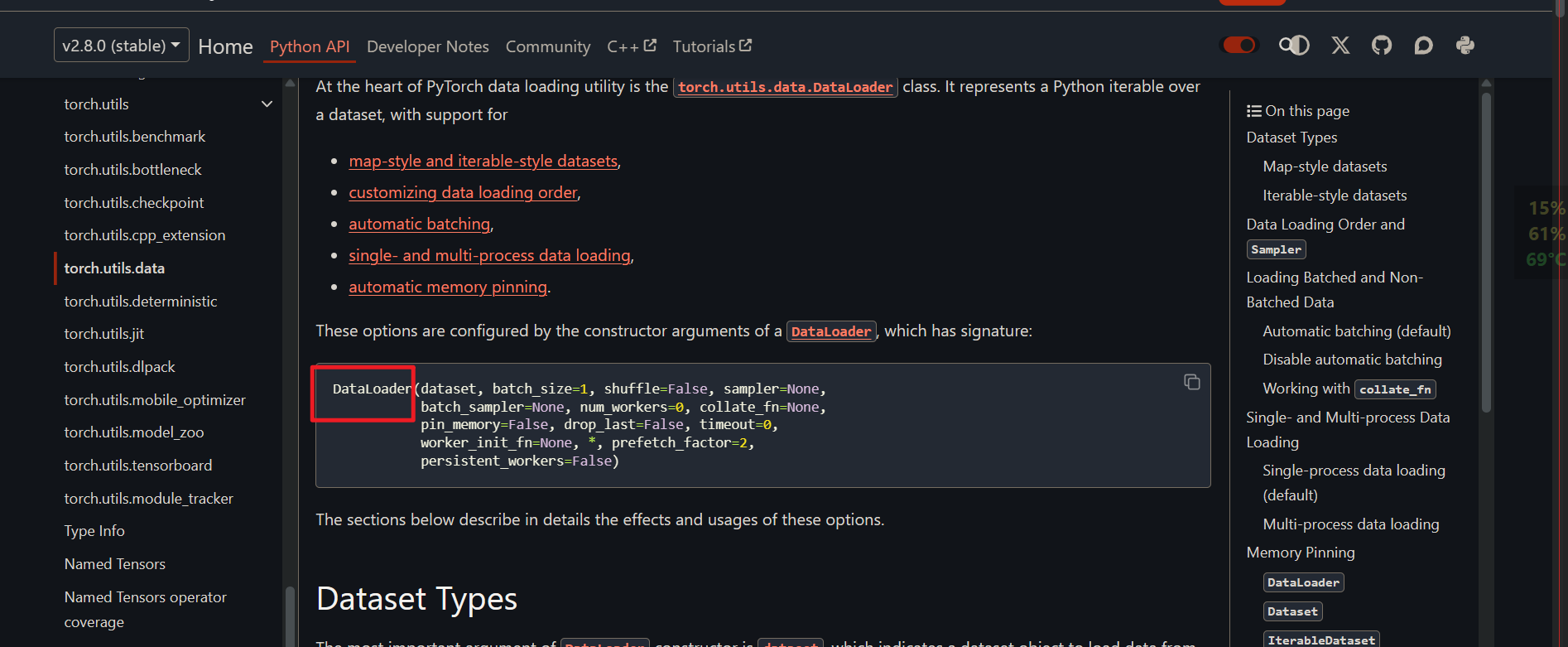
应用场景或者作用:
数据集比较大的时候,无法一次性加载到内存中,就分批次进行加载。
import torch
import numpy as np
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# --------------------------start--------------------------------
# 导入
from torch.utils.data import TensorDataset, DataLoader
# 使用TensorDataset对象封装张量
dataset = TensorDataset(
x_train, # 输入特征张量
y_train # 输出特征张量
)
print(dataset[0]) # 第一个样本的输入输出
print(dataset[1][0]) # 第二个样本的输入
# 使用DataLoader加载数据集
dataloader = DataLoader(
dataset, # 数据集
batch_size=5, # 一个批次五个数据
shuffle=True # 随机
)
# 观察dataloader内部数据
for data in dataloader:
print(data)
# --------------------------end----------------------------
# 2. 定义前向模型
import torch.nn as nn
# 方案4:
class LinearModel(nn.Module):
# 构造函数:初始化
def __init__(self):
# 调用父类的构造函数
super(LinearModel, self).__init__()
# ModuleDict,支持多网络结构(本例只有一个网络层)
self.layer1 = nn.Linear(1, 1)
# self.layer2 = nn.Linear(1, 1) # 如果是两个网络层是这样的
def forward(self, x):
"""
前向传播方法
:param x: 输入张量
:return: 网络层处理后的输出张量
"""
# 多个网络层连接
x = self.layer1(x)
# x = self.layer2(x)
return x
# 创建模型对象
model = LinearModel()
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# --------------------------start--------------------------------
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数(训练次数)
for n in range(1, epochs + 1):
# 分不同的批次训练多次,最后求平均损失
epoch_loss = 0 # 一个迭代的多个批次的损失函数和
for batch_x, batch_y in dataloader: # 每一个迭代(epoch)的批次
# print(batch_x)
# print(batch_y)
# 预测
y_pre = model(batch_x.unsqueeze(1))
# 计算批损失
batch_loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
batch_y # 参数2: 真实值
)
epoch_loss += batch_loss
optimizer.zero_grad() # 清空梯度
batch_loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算当前epoch多个批次的平均损失值
avg_loss = epoch_loss / len(dataloader)
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{avg_loss}")
print("-----------------------------------")
# --------------------------end----------------------------
# # 4.1 前向传播
# y_pre = model(x_train.unsqueeze(1)) # 参数是n*m的输入矩阵
# # print(y_pre) # 预测值
# # 计算损失函数
# loss = criterion(
# y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
# y_train # 参数2: 真实值
# )
#
# # 清空之前优化器重存储的梯度参数,以便于本次epoch重新进行反向传播
# optimizer.zero_grad()
#
# # 4.2 反向传播
# loss.backward()
#
# # 5. 显示频率设置
# if n == 1 or n % 10 == 0:
# # 遍历模型参数
# for name, param in model.named_parameters():
# # 如有,取出当前计算的梯度
# if param.grad is not None:
# print(f"梯度:{name}:{param.grad}")
# # 如有,取出当前计算的w和b
# if param.data is not None:
# print(f"w和b的值:{param.data}")
# # 每隔10次显示一次损失函数
# print(f"epoch:{n},loss:{loss}")
# print("-----------------------------------")
#
# # 更新参数,例如w新 = 学习率与w旧的计算
# optimizer.step()
3. 保存模型
模型保存的主要目的是为了避免重复训练和提高效率,包括:
- 避免重复训练:模型训练通常需要大量的时间和计算资源,尤其是对于复杂的模型和大规模的数据集。如果训练过程中断,保存的模型可以避免从头开始训练,从而节省时间和资源。
- 提高效率:在迭代开发过程中,保存模型可以快速加载之前的训练状态,进行进一步的调整和优化,而无需重新训练整个模型。
- 模型共享:保存的模型可以方便地共享给其他研究人员或部署到生产环境中,而无需重新训练。
- 防止过拟合:在某些情况下,保存中间状态的模型可以帮助防止过拟合,因为可以从不同的训练阶段选择最佳模型。
有两种保存方式:
- 保存模型的权重和其他参数
- 保存整个模型
3.1 方式1:保存模型的权重和其他参数
使用torch.save()保存,该函数将模型的状态字典保存到文件中,其中包括模型的权重和其他参数。

- 参数1:model.state_dict()返回模型的状态字典,其中包含模型的所有参数。
- 参数2:保存的路径
torch.save()函数将这个状态字典保存到名为model.pth的文件中 pth是pytorch的标准的一个模型文件。官方推荐这种保存方式。
3.2 方式2:保存整个模型
保存整个模型,包括其结构和参数,也使用torch.save()函数。

- 参数1:模型对象。
- 参数2:保存的路径
需要注意的是,保存整个模型可能会占用更多的磁盘空间,并且不如保存状态字典灵活,因为状态字典可以与不同的模型结构兼容。
3.3 代码
import torch
import numpy as np
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
# 1、散点输入
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]]
# 转换为np数组
data = np.array(data)
data
# 提取每个点的x_data和y_data
x_data = data[:, 0]
y_data = data[:, 1]
print(x_data)
print(y_data)
# 将x_data 和 y_data 转换成tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
print(x_train)
print(y_train)
# 使用TensorDataset对象封装张量
dataset = TensorDataset(
x_train, # 输入特征张量
y_train # 输出特征张量
)
print(dataset[0]) # 第一个样本的输入输出
print(dataset[1][0]) # 第二个样本的输入
# 使用DataLoader加载数据集
dataloader = DataLoader(
dataset, # 数据集
batch_size=5, # 一个批次五个数据
shuffle=True # 随机
)
# 观察dataloader内部数据
for data in dataloader:
print(data)
# 2. 定义前向模型
# 方案4:
class LinearModel(nn.Module):
# 构造函数:初始化
def __init__(self):
# 调用父类的构造函数
super(LinearModel, self).__init__()
# ModuleDict,支持多网络结构(本例只有一个网络层)
self.layer1 = nn.Linear(1, 1)
# self.layer2 = nn.Linear(1, 1) # 如果是两个网络层是这样的
def forward(self, x):
"""
前向传播方法
:param x: 输入张量
:return: 网络层处理后的输出张量
"""
# 多个网络层连接
x = self.layer1(x)
# x = self.layer2(x)
return x
# 创建模型对象
model = LinearModel()
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
# 定义随机梯度下降的优化器
optimizer = torch.optim.SGD(
model.parameters(), # 模型参数
lr=0.01 # 学习率
)
# unsqueeze可以增加维度,参数是增加的维度是哪一维度
print(x_train.unsqueeze(0)) # 一个样本点(行数),十个特征(列数)
print(x_train.unsqueeze(1)) # 十个样本点(行数),一个特征(列数)
# 4. 开始迭代
epochs = 500 # 迭代次数(训练次数)
for n in range(1, epochs + 1):
# 分不同的批次训练多次,最后求平均损失
epoch_loss = 0 # 一个迭代的多个批次的损失函数和
for batch_x, batch_y in dataloader: # 每一个迭代(epoch)的批次
# print(batch_x)
# print(batch_y)
# 预测
y_pre = model(batch_x.unsqueeze(1))
# 计算批损失
batch_loss = criterion(
y_pre.squeeze(1), # 参数1:预测值(移除第二维,恢复一维)
batch_y # 参数2: 真实值
)
epoch_loss += batch_loss
optimizer.zero_grad() # 清空梯度
batch_loss.backward() # 反向传播
optimizer.step() # 更新参数
# 计算当前epoch多个批次的平均损失值
avg_loss = epoch_loss / len(dataloader)
# 5. 显示频率设置
if n == 1 or n % 10 == 0:
# 遍历模型参数
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
# 每隔10次显示一次损失函数
print(f"epoch:{n},loss:{avg_loss}")
print("-----------------------------------")
# --------------------------start-----------------------------
# 开始保存
torch.save(
model.state_dict(), # 保存什么内容:模型字典表示方式1
'model.pth' # 保存文件的名称
)
torch.save(
model, # 保存什么内容:整个模型表示方式2
'entire_model.pth' # 保存文件的名称
)
4. 加载模型
4.1 方式1:加载模型参数(对应保存方式1)
步骤:
- 步骤1:复现模型对象
- 步骤2:使用torch.load("model.pth")加载模型参数
- 步骤3:使用model.load_state_dict(torch.load("model.pth"))将model和参数结合起来。
import torch
import torch.nn as nn
# 1. 复现模型对象
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
return x
# 创建模型对象
model = LinearModel()
# 2. 先把模型的参数读出来
model_dict = torch.load('model.pth',
weights_only=True) # 有这个参数可以提升安全性
# 3. 再把参数给模型
model.load_state_dict(model_dict)
# 让模型进入评估模式
model.eval()
# 使用之前训练500的结果对数据进行预测
x_test = torch.tensor(
[[-0.5], [2.5], [1.25]],
dtype=torch.float32
)
# 开始预测
with torch.no_grad(): # 评估模式下不需要再计算梯度了,可以提升预测速度
y_prd = model(x_test)
print(y_prd)
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
4.2 方式2:加载整个模型(对应保存方式2)
步骤:
- 步骤1:需要模型结构
- 步骤2:使用torch.load("entire_model.pth")加载模型
import torch
import torch.nn as nn
# 1. 复现模型对象
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
return x
# # 创建模型对象
# model = LinearModel() 不需要手动创建模型
# 2. 直接从文件读取模型
model = torch.load('entire_model.pth') # 这种模式下不支持weights_only参数
# 让模型进入评估模式
model.eval()
# 使用之前训练500的结果对数据进行预测
x_test = torch.tensor(
[[-0.5], [2.5], [1.25]],
dtype=torch.float32
)
# 开始预测
with torch.no_grad(): # 评估模式下不需要再计算梯度了,可以提升预测速度
y_prd = model(x_test)
print(y_prd)
for name, param in model.named_parameters():
# 如有,取出当前计算的梯度
if param.grad is not None:
print(f"梯度:{name}:{param.grad}")
# 如有,取出当前计算的w和b
if param.data is not None:
print(f"w和b的值:{param.data}")
5. 查看网络结构
5.1 方法1:print
print(model) 仅能打印出网络结构,不能检测模型搭建是否正确。

import torch
import torch.nn as nn
# 1. 复现模型对象
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
self.layer2 = nn.Linear(2, 1) # 第二个网络层是两个输入
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x) # 错误:只给了一个输入
return x
# 创建模型对象
model = LinearModel()
# 打印网络结构
print(model)
5.2 方法2:summary
torchsummary 主要用于查看模型结构,如果模型搭建错误会报错。
是单独的库,
python -m pip install torchsummary -i https://pypi.tuna.tsinghua.edu.cn/simple
import torch
import torch.nn as nn
# 1. 复现模型对象
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
# self.layer2 = nn.Linear(2, 1) # 第二个网络层是两个输入
def forward(self, x):
x = self.layer1(x)
# x = self.layer2(x) # 错误:只给了一个输入
return x
# 创建模型对象
model = LinearModel()
# 导入summary
from torchsummary import summary
# 如果模型搭建错误,报错
summary(
model, # 模型
input_size=(1,), # 整个模型的输入
device="cpu" # 如果是cpu训练的,一定要写上cpu
)
5.3 方法:netron
直接启动
5.3.1 直接打开pth
缺点是无连线。
import torch
import numpy as np
# 2.定义前向模型
import torch.nn as nn
# 方案4:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
# ----------------本节开始-------------------
# 【给第二个线性层】
self.layer2 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
# 【连接两个线性层】
x = self.layer2(x)
return x
model = LinearModel()
# 保存模型
torch.save(model,"netron_model.pth")
5.3.2 转换脚本以后保存
使用 torch.jit.script 先将模型转换为JIT脚本,再使用 torch.jit.save 保存模型;
什么是 JIT?
首先要知道 JIT 是一种概念,全称是 Just In Time Compilation,中文译为「即时编译」,是一种程序优化的方法。
import torch
import numpy as np
# 2.定义前向模型
import torch.nn as nn
# 方案4:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
# ----------------本节开始-------------------
# 【给第二个线性层】
self.layer2 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
# 【连接两个线性层】
x = self.layer2(x)
return x
model = LinearModel()
# 【转换模型脚本】
script_model = torch.jit.script(model)
# 保存模型脚本
torch.jit.save(script_model, 'script_model.pth')
5.3.3 转换为ONNX保存
ONNX(Open Neural Network Exchange)是一个开放的深度学习模型交换格式,它允许在不同的深度学习框架之间共享、迁移和使用模型。ONNX的目标是提供一个通用的中间表示,使得各种深度学习框架(如PyTorch、TensorFlow、MXNet等)之间能够更轻松地交换模型,并且能够在不同框架之间进行模型的部署和推理。
安装:
python -m pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
import torch
import numpy as np
# 2.定义前向模型
import torch.nn as nn
# 方案4:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
# ----------------本节开始-------------------
# 【给第二个线性层】
self.layer2 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
# 【连接两个线性层】
x = self.layer2(x)
return x
model = LinearModel()
# 【使用ONNX导出】
torch.onnx.export(
model, # 模型
torch.rand(1, 1), # 需要随机生成一个数据作为模型输入,第一个1表示batch_size,第二个1表示1维张量
"model.onnx" # 保存的文件名
)
5.4 方法4:TensorboardX
5.4.1 使用步骤
TensorboardX 这个工具使得 pytorch 框架也可以使用到 Tensorboard 的便捷功能,tensorboardX 可以记录和可视化模型训练过程中的指标以及模型结构。
如果没有安装,则手动安装:
python -m pip install TensorboardX -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后可能会出现问题,出现各种问题留意错误信息。
import torch
import numpy as np
# 2.定义前向模型
import torch.nn as nn
# 方案4:
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.layer1 = nn.Linear(1, 1)
self.layer2 = nn.Linear(1, 1)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
model = LinearModel()
# 【导出TensorBoardX的logs(日志)】
from tensorboardX import SummaryWriter
# 创建一个日志文件夹存储日志
writer = SummaryWriter(log_dir='logs')
# 将模型结构(计算图)添加到SummaryWriter对象中
writer.add_graph(
model, # 模型
torch.rand(1) # 给一个随机的一维张量
)
writer.close() # 关闭
使用TensorBoardX加载日志的操作步骤如下:
1. 打环境终端,定位到项目路径下(logs所在的文件夹)。
2. 执行命令
"D:\HQYJ\FS_AISIMS\tools\Python\python.exe" "D:\HQYJ\FS_AISIMS\tools\Python\Scripts\tensorboard.exe" --logdir=logs
上面的命令分为三部分:
- Python使用的解释器
"D:\HQYJ\FS_AISIMS\tools\Python\python.exe"
- TensorBoard执行文件
"D:\HQYJ\FS_AISIMS\tools\Python\Scripts\tensorboard.exe"
- 日志文件夹名称
--logdir=logs
根据自己的电脑修改命令并执行。
3. 成功运行后,提示在浏览器中打开下面的地址:

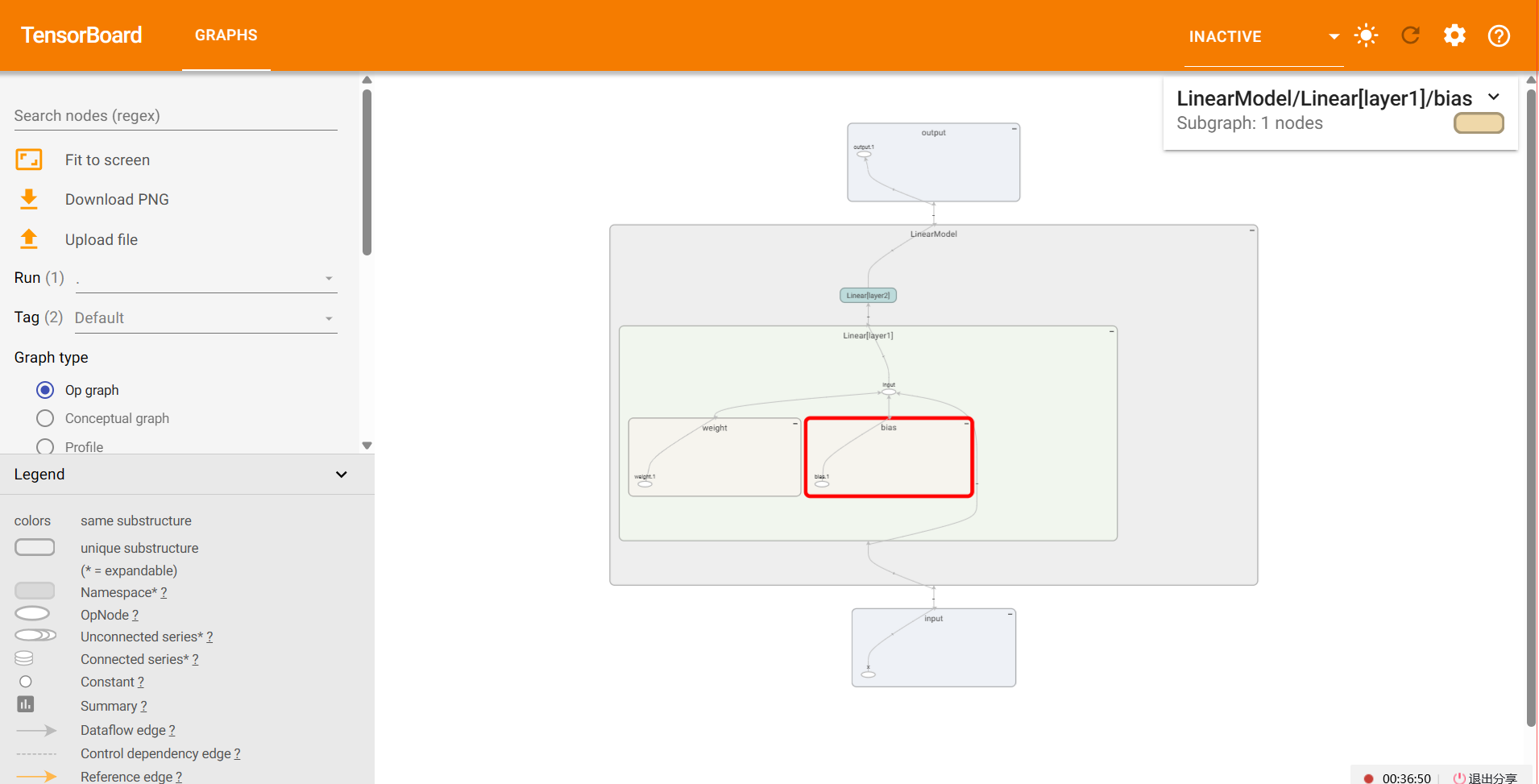
5.4.2 问题解决
1. protobuf版本不匹配
主要是受到ONNX的影响,两边都用这个库,但版本不一样。因此需要重新设置protobuf的版本为最高3.20.x。
python -m pip uninstall protobuf
python -m pip install protobuf==3.20.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
2. tensorboard库缺失

只需要安装tensorboard库即可。
python -m pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple
3. C盘权限问题
建议项目不要放在C盘下,访问权限较高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









