







2.AlexNet
AlexNet网络参加了ILSVRC2012年大赛,以高出第二名10%的性能优势取得了冠军,由传统的70%多的准确率提升到80%多。
AlexNet是2012年ImageNet(ImageNet是224x224尺寸的)竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的,在那之后,更多的更深的神经网络被提出,掀起了一波深度学习的浪潮,一个具有里程碑意义的网络。
论文地址:https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
NIPS-2012-imagenet-classification-with-deep-convolutional-neural-networks-Paper.pdf
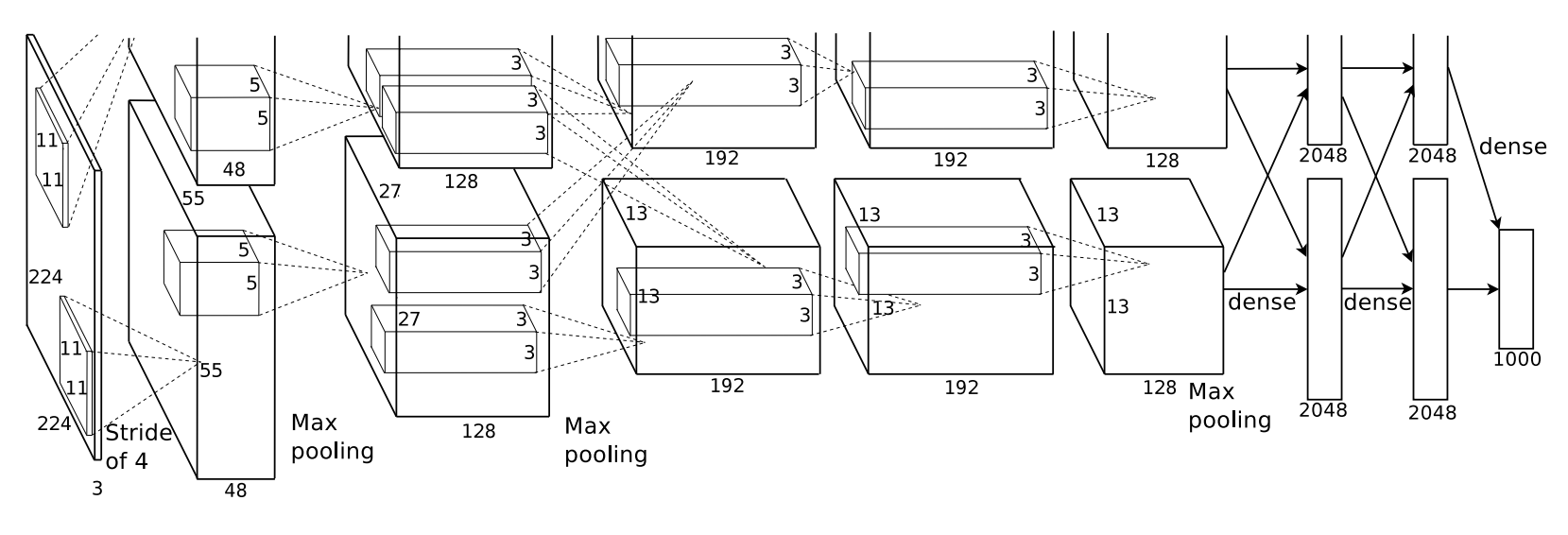
网络结构
网络结构的图,如下图所示:
3. 网络的创新
3.1 首次使用GPU训练网络
在AlexNet中使用了CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。 因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。
因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。 同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
3.2 使用Relu激活函数
在Relu激活函数被提出前,非线性激活函数被sigmoid激活函数和tanh激活函数占据着,所以在介绍Relu激活函数的优势前,需要先了解一下sigmoid激活函数和tanh激活函数。
sigmoid激活函数和tanh激活函数
sigmoid激活函数是一个非常受欢迎的神经网络激活函数。函数的输入被转换成介于0.0和1.0之间的值。大于1.0的输入被转换为值1.0,同样,小于0.0的值被折断为0.0。所有可能的输入函数的形状都是从0到0.5到1.0的 s 形。在很长一段时间里,直到20世纪90年代早期,这是神经网络的默认激活方式,它的表达式是:
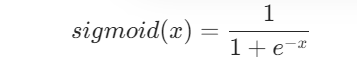
由于sigmoid激活函数的输出不是零中心的(Zero-centered),会导致优化的效率十分低下,但是sigmoid天然适合做概率值处理,例如用于LSTM中的门控制。
Tanh激活函数是一个形状类似的非线性激活函数,输出值介于-1.0和1.0之间。在20世纪90年代后期和21世纪初期,由于使用 tanh 函数的模型更容易训练,而且往往具有更好的预测性能,因此 tanh 函数比sigmoid激活函数更受青睐,它的表达式是:
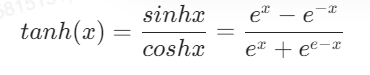
3.3 Relu激活函数
Relu激活函数的图像如下图:
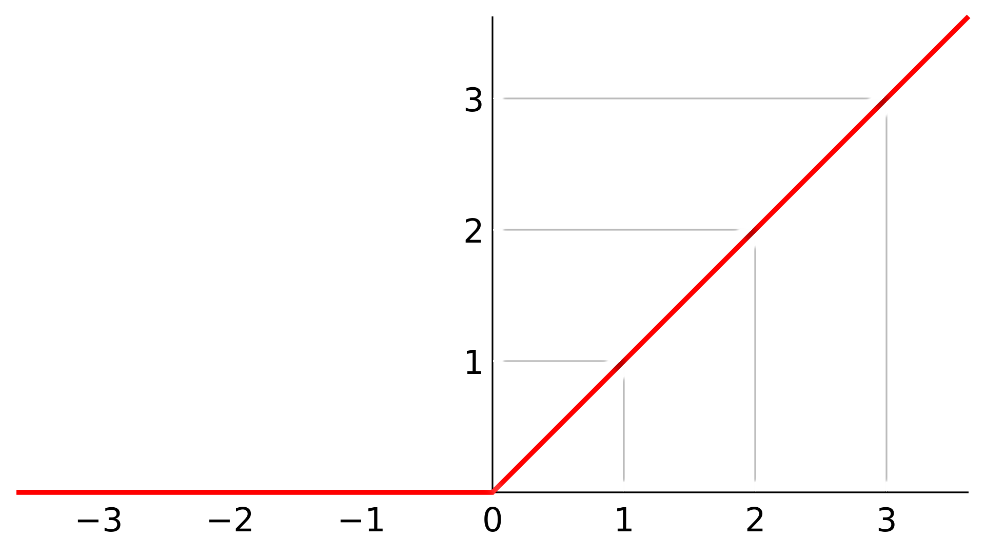
Relu激活函数相对于sigmoid激活函数和tanh激活函数速度可快太多了,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
在sigmoid激活函数和tanh激活函数接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练,Relu激活函数并不会有这种情况发生。
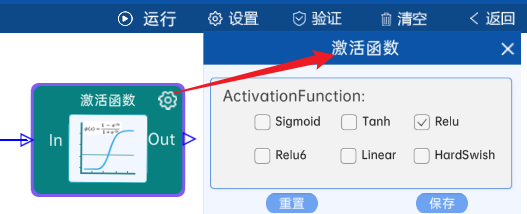
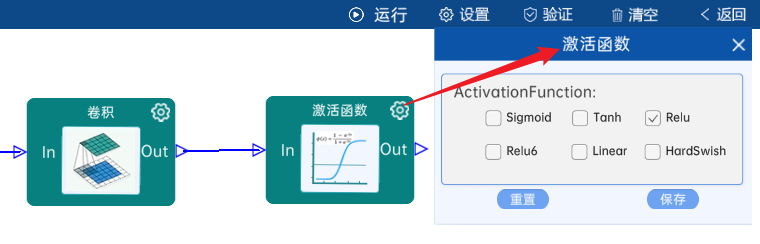
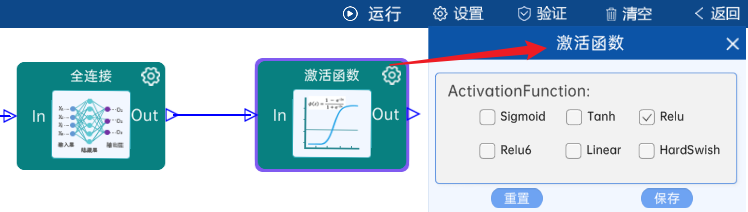
在AlexNet神经网络中,激活函数全部使用Relu。
3.4 使用LRN局部响应归一化
LRN 首先是在 AlexNet 中首先,被定义,它的目的在于卷积(即 Relu 激活函数出来之后的)值进行局部的归一化。
在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio),指的是被激活的神经元会抑制它周围的神经元,而归一化(normalization)的目的就是“抑制”,两者不谋而合,这就是局部归一化的动机,它就是借鉴“侧抑制”的思想来实现局部抑制,当我们使用Relu激活函数的时候,这种局部抑制显得很有效果。
LRN的主要思想是在神经元输出的局部范围内进行归一化操作,使得激活值较大的神经元对后续神经元的影响降低,从而减少梯度消失和梯度爆炸的问题。具体来说,对于每个神经元,LRN会将其输出按照局部范围进行加权平均,然后将加权平均值除以一个尺度因子(通常为2),最后将结果取平方根并减去均值,得到归一化后的输出。
LRN的公式为:
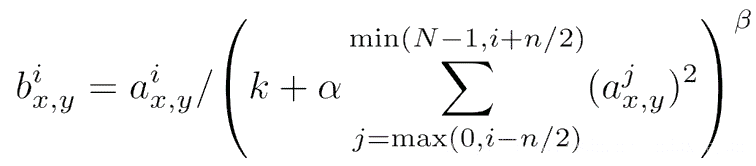
其中:
- $x_{i,j,k,l}$ 是输入张量的元素。
- $N$ 是通道数。
- $n$ 是 LRN 的窗口大小。
- $\alpha$、$\beta$、$k$ 是超参数,分别用于调整归一化的强度。
由于2015年该方法被Very Deep Convolutional Networks for Large-Scale Image Recognition指出并没有什么用,所以这里我们就不做详细的参数介绍和举例了,就知道这是为了归一化而做出的当年的一个解决方案就好。
后续提出了更加有说服能力的批量归一化(Batch Normalization)的概念,所以现在归一化几乎都用batchNorm的方法实现归一化了。
3.5在全连接层加入Dropout
在AlexNet中最后2个全连接层中使用了Dropout,因为全连接层容易过拟合,而卷积层不容易过拟合。注意,Dropout并不是本论文首次提出的。
AlexNet设置的dropout参数为0.5,AlexNet使用的是 Scale at Training 的 Dropout 实现方式。在训练时,AlexNet通过在前向传播的过程中随机将一部分神经元的输出置为零,实现了Dropout。在测试时,AlexNet不再使用Dropout,而是在训练时的基础上将权重按照训练时的概率进行缩放,以保持一致性。
Dropout为什么能够解决过拟合:
(1)减少过拟合: 在标准的神经网络中,网络可能会过度依赖于一些特定的神经元,导致对训练数据的过拟合。Dropout通过随机丢弃神经元,迫使网络学习对于任何单个神经元的变化都要更加鲁棒的特征表示,从而减少了对训练数据的过度拟合。
(2)取平均的作用: 在训练过程中,通过丢弃随机的神经元,每次前向传播都相当于在训练不同的子网络。在测试阶段,不再进行Dropout,但是通过保留所有的权重,网络结构变得更加完整。因此,可以看作是在多个不同的子网络中进行了训练,最终的预测结果相当于对这些子网络的输出取平均。这种“综合取平均”的策略有助于减轻过拟合,因为一些互为反向的拟合会相互抵消。
4 结构组件介绍
4.1 卷积
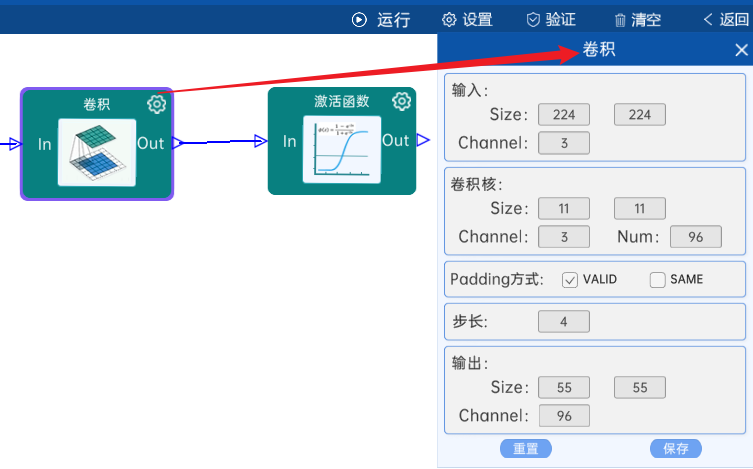
输入特征矩阵是(224 x 224 x 3),本层卷积核的宽、高、通道、个数是(11 x 11 x 3 x 96),步长为4,padding方式为VALID,经过计算可知,输出特征矩阵为(55 x 55 x 96)。
本层之后要经过ReLU激活函数,如下图:
4.2 池化-降采样
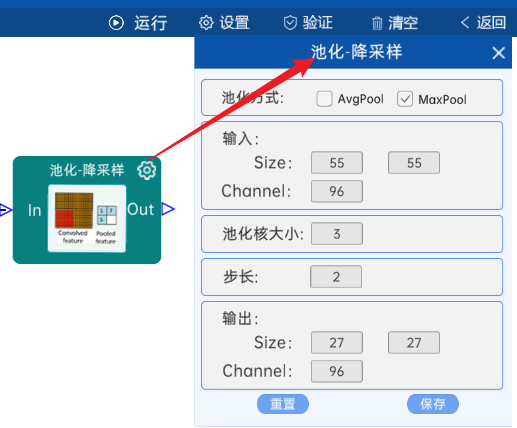
池化方式为MaxPool,输入特征矩阵是(55 x 55 x 96),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(27 x 27 x 96)。如下图:
4.3 卷积
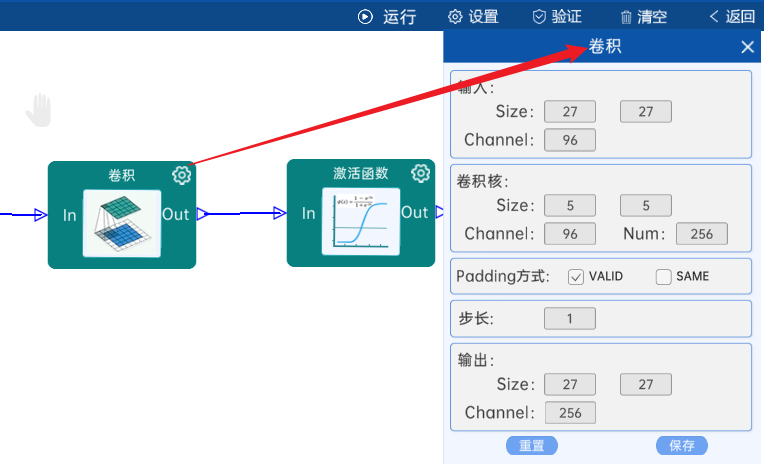
输入特征矩阵是(27 x 27 x 96),本层卷积核的宽、高、通道、个数是(5 x 5 x 96 x 256),步长为1,padding方式为Same,经过计算可知,输出特征矩阵为(27 x 27 x 256)。
本层之后要经过ReLU激活函数,如下图:
4.4 池化-降采样
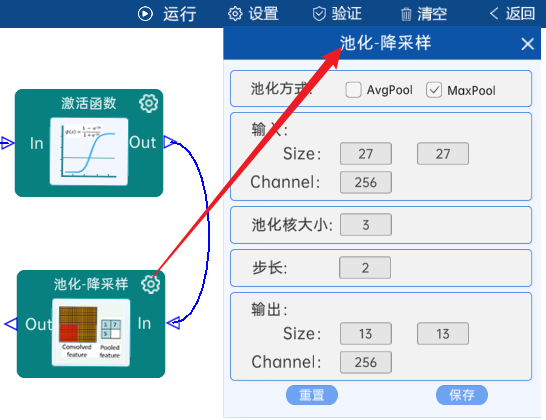
池化方式为MaxPool,输入特征矩阵是(27 x 27 x 256),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(13 x 13 x 256)。如下图:
4.5 卷积
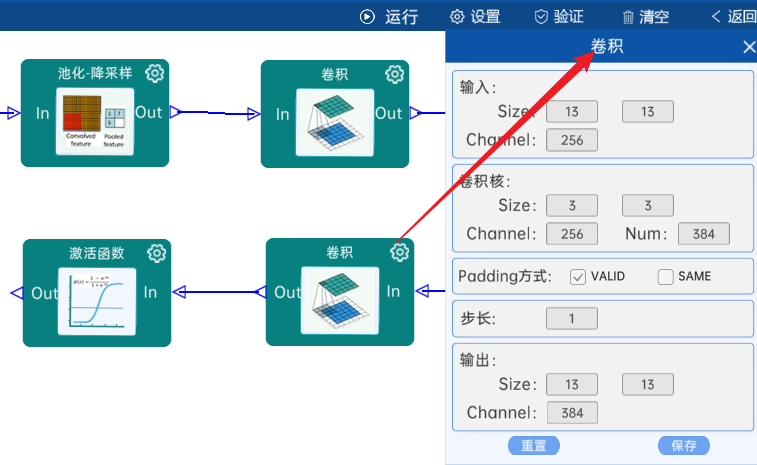
输入特征矩阵是(13 x 13 x 256),本层卷积核的宽、高、通道、个数是(3 x 3 x 256 x 384),步长为1,padding方式为VALID,经过计算可知,输出特征矩阵为(13 x 13 x 384)。
本层之后要经过ReLU激活函数,如下图:
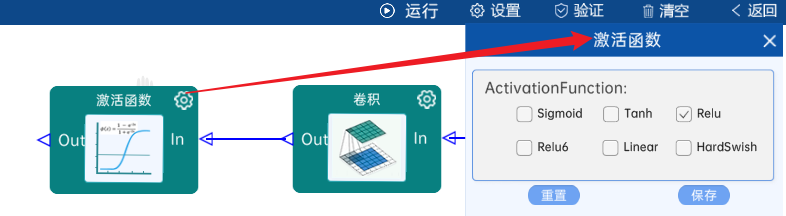
4.6 卷积
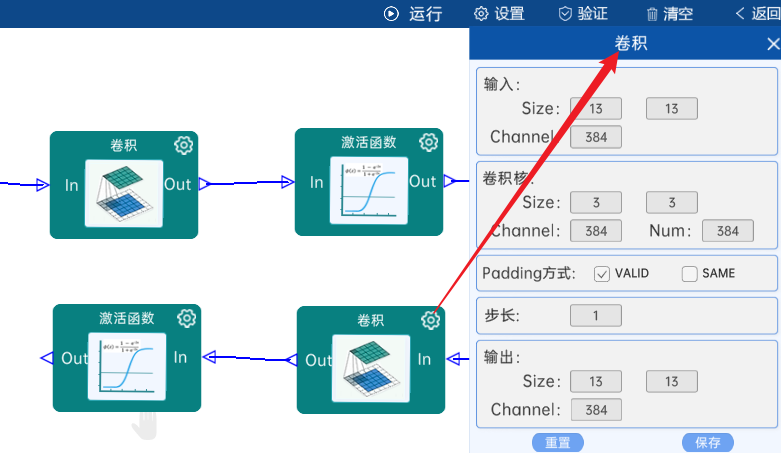
输入特征矩阵是(13 x 13 x 384),本层卷积核的宽、高、通道、个数是(3 x 3 x 384 x 384),步长为1,padding方式为VALID,经过计算可知,输出特征矩阵为(13 x 13 x 384)。
本层之后要经过ReLU激活函数,如下图:
4.7 卷积
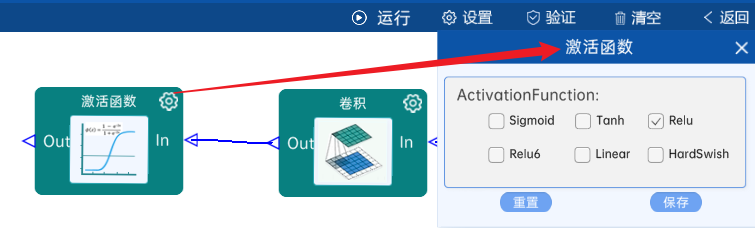
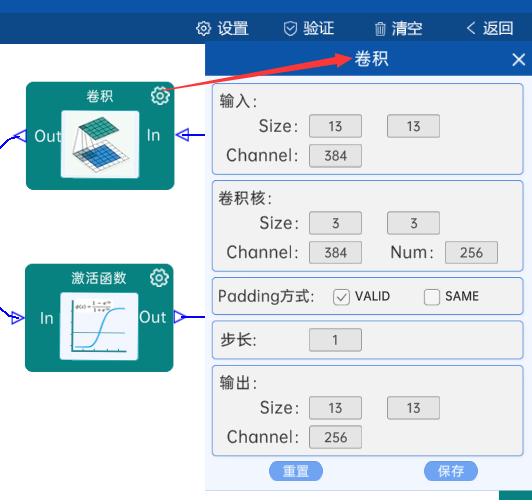
输入特征矩阵是(13 x 13 x 384),本层卷积核的宽、高、通道、个数是(3 x 3 x 384 x 256),步长为1,padding方式为VALID,经过计算可知,输出特征矩阵为(13 x 13 x 256)。
本层之后要经过ReLU激活函数,如下图:
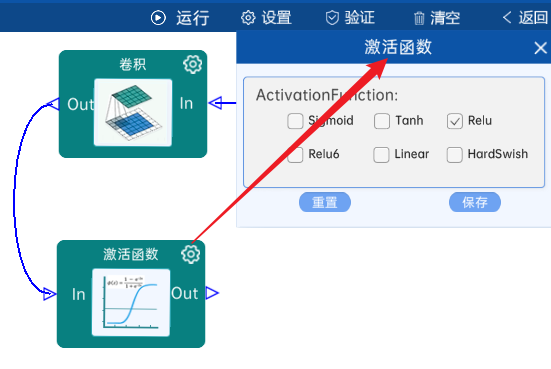
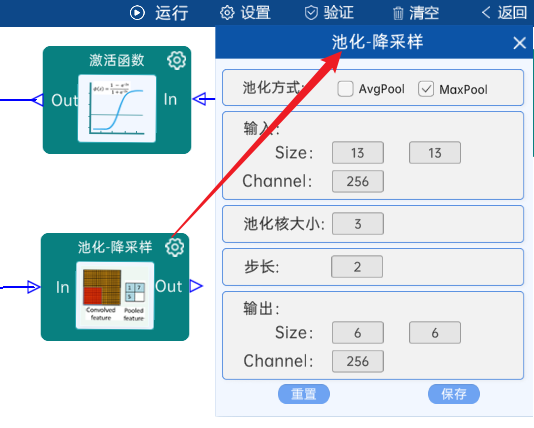
4.8 池化-降采样
池化方式为MaxPool,输入特征矩阵是(13 x 13 x 256),池化核大小为3,步长为2,经过计算可知,输出特征矩阵为(6 x 6 x 256)。如下图:
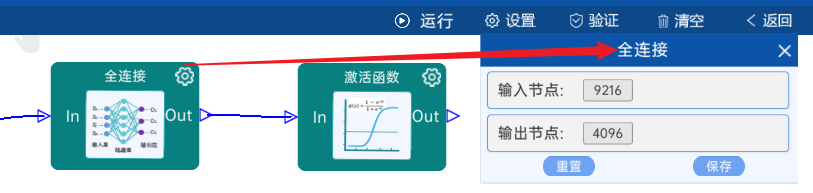
4.9 全连接
输入节点是9216,输出节点为4096,后面跟ReLU激活函数。如下图:
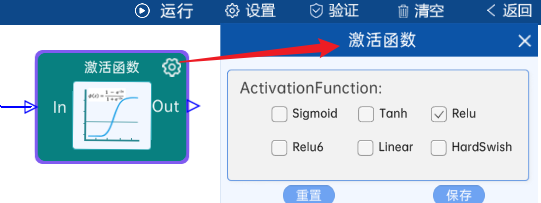
4.10 全连接
输入节点是4096,输出节点为4096,后面跟ReLU激活函数。如下图:
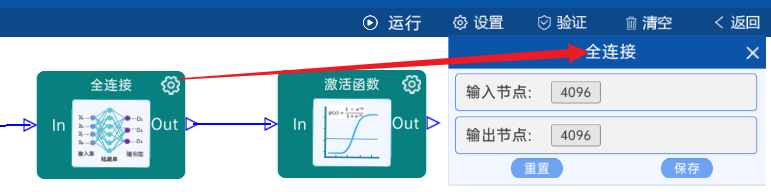
4.11 全连接
输入节点是4096,输出是ImageNet数据集,所以输出节点为1000。如下图:
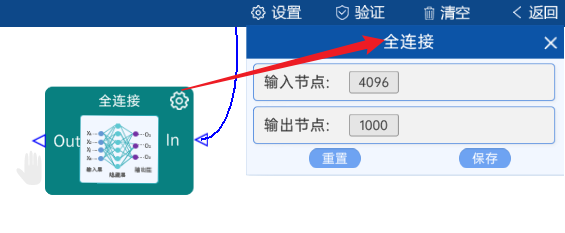
4.12 Softmax
最后通过Softmax实现将多分类的输出值转换为范围在[0, 1]和为1的概率分布。
代码
import random
from torchvision import transforms
import torch
import numpy as np
#PYTHON IMAHEING LIBRARY
from PIL import Image
# os就是“operating system”的缩写,
# 顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口
import os
#定义函数设置随机数种子,主要作用用于结果的可复现。
def setup_seed(seed):
# 设置numpy的随机数种子
np.random.seed(seed)
# 设置python的随机数种子
random.seed(seed)
# 在pyhton中通过os.environ可以获取有关系统的各种信息
os.environ["PYTHONHASHSEED"]=str(seed)
#设置torch的随机数种子 固定cpu的随机数种子
torch.manual_seed(seed)
#设置一下GPU的随机数
if torch.cuda.is_available():
# 为当前GPU设置种子用于生成随机数,以使得结果的确定的
torch.cuda.manual_seed(seed)
#为所有GPU设置种子,固定所有GPU随机种子(多卡场景)
torch.cuda.manual_seed_all(seed)
# 设置cudnn:cudnn中对卷积操作进行优化
# 如果需要保证可重复性,可使用如下设置
# 确保每次运行使用相同的卷积算法:通过设置 benchmark=False,cuDNN 不再进行算法搜索,
# 而是使用默认或预定义的算法,从而保证每次前向 / 反向传播的计算路径一致
torch.backends.cudnn.benchmark=False
torch.backends.cudnn.deterministic = True # 设置cuDNN为确定性算法,确保数值结果严格相同。
#设置随机数种子
setup_seed(0)
if torch.cuda.is_available():
#"cuda"这个字符串必须传入torch.device否则不起作用
device=torch.device("cuda")
print("CUDA is available ,Using GPU")
else:
device=torch.device("cpu")
print("CUDA is not available ,Using CPU")
#模型搭建
import torch.nn.functional as F
import torch.nn as nn
from torchsummary import summary
from torch.utils.data import DataLoader,Dataset
#处理图片数据
class CatDogDataset(Dataset):
#tranform 单纯的数据出来
def __init__(self,data_dir,mode='train',split_n=0.9,tranform=None):
self.data_dir=data_dir
self.mode=mode
self.split_n=split_n
self.tranform = tranform
# 存储所有图片的路径和标签,在DataLoader中通过index读取样本
self.data_info=self._get_img_info()
#__len__:返回数据集的大小
def __len__(self):
if len(self.data_info)==0:
raise Exception("\ndata_dir:{} is a empty dir ! please cheackout dir ")
return len(self.data_info)
def __getitem__(self, item):
path_img,label=self.data_info[item]
img = Image.open(path_img).convert('RGB')
if self.tranform is not None:
#使用传入的transform处理图片转成指定的尺寸和tensor 还进行归一化
img=self.tranform(img)
return img,label
def _get_img_info(self):
# os.listdir 列出文件夹下的内容
img_names=os.listdir(self.data_dir)
#过滤出以.jpg结尾的文件
img_names=list(filter(lambda x:x.endswith('.jpg'),img_names))
# 将图片打乱顺序 ,没有返回值 原地打乱
random.shuffle(img_names)
#分类的活 获取类别标签
img_labels = [0 if n.startswith('cat') else 1 for n in img_names]
#划分训练数据集
split_index=int(len(img_labels)*self.split_n)
if self.mode == "train":
img_set=img_names[:split_index]
label_set = img_labels[:split_index]
else:
img_set = img_names[split_index:]
label_set = img_labels[split_index:]
#获取图片的绝对路径
path_img_set=[os.path.join(self.data_dir,n) for n in img_set]
# print(path_img_set)
data_info =[(n,l) for n,l in zip(path_img_set,label_set)]
return data_info
# print(data_info)
# print('s')
#主要作用是串联多个图片变换的操作
#transforms.Resize变换图片的尺寸
#transforms.ToTensor()转化为tensor
# transforms.Normalize 归一化
norm_mean=(0.5,0.5,0.5)
norm_std = (0.5, 0.5, 0.5)
train_transform=transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean,norm_std)])
test_transform=transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean,norm_std)])
#AlexNet Model
class AlexNetModel(nn.Module):
def __init__(self):
super(AlexNetModel,self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2)
self.pool2=nn.MaxPool2d(kernel_size=3,stride=2)
self.conv3=nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,stride=1,padding=2)
self.pool4=nn.MaxPool2d(kernel_size=3,stride=2)
self.conv5 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.pool8 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten=nn.Flatten(start_dim=1,end_dim=-1)
self.f9 = nn.Linear(in_features=9216, out_features=4096)
self.f10 = nn.Linear(in_features=4096, out_features=4096)
# 这里只有猫和狗两类
self.output = nn.Linear(in_features=4096, out_features=2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool2(x)
x = F.relu(self.conv3(x))
x = self.pool4(x)
x = F.relu(self.conv5(x))
x = F.relu(self.conv6(x))
x = F.relu(self.conv7(x))
x = self.pool8(x)
x = self.flatten(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
x = F.dropout(x, p=0.5)
x = self.f10(x)
x = F.dropout(x, p=0.5)
output = self.output(x)
return output
def test_eval(test_loader,model,loss_fn,state_of_the_art_acc):
#评估模型
model.eval()
# 使用上下文
total_label_num = 0
correct_num = 0
# 获得预测标签
predicted_labels = []
# 获得真实的标签
true_labels = []
total_loss = 0
#with 表示上下文
#torch.no_grad() 表示不需要梯度更新
with torch.no_grad():
for batch, (x_test_images, y_test_label) in enumerate(test_loader):
# 将数据和标签加入GPU或者CPU中
x_test_images = x_test_images.to(device)
y_test_label = y_test_label.to(device)
y_pre = model(x_test_images)
# 计算损失
test_loss = loss_fn(y_pre, y_test_label)
total_loss += test_loss
# 计算准确率
_, predicted = torch.max(y_pre, dim=1)
total_label_num = total_label_num + len(y_test_label)
# 计算预测正确的数值
correct_num = correct_num + torch.sum(predicted == y_test_label).item()
# 绘制混淆矩阵
# 将结果放到CPU上
predicted_labels.extend(predicted.detach().cpu().numpy())
#detach().cpu().numpy() 表示从计算图上分离出来放到cpu转成numpy
true_labels.extend(y_test_label.detach().cpu().numpy())
avg_test_loss = total_loss / (len(test_loader))
# 计算准确度acc
acc = (correct_num / total_label_num) * 100
if (acc > state_of_the_art_acc):
state_of_the_art_acc = acc
# 需要把model文件夹提前新建出来
torch.save(model.state_dict(), f'model/model_best.pth')
print(f"ACC:{acc}%")
# 计算混淆矩阵
# 导入混淆矩阵
from sklearn.metrics import confusion_matrix
all_labels = [0, 1] # 根据你的实际情况修改
conf_matrix = confusion_matrix(np.array(true_labels), np.array(predicted_labels),labels=all_labels)
# 使用热力图画混淆矩阵
import seaborn as sns
sns.heatmap(conf_matrix, annot=True, cmap='Blues')
# plt.xlabel("predict")
# plt.ylabel("true")
# plt.show()
return state_of_the_art_acc
if __name__=="__main__":
Batch_Size = 2
lr = 0.01
epoches = 100
# 使用acc来筛选最好的模型
state_of_the_art_acc = 0
BASE_DIR=os.path.dirname(os.path.abspath(__file__))
data_dir = os.path.join(BASE_DIR, 'train')
# 准备数据集
train_data = CatDogDataset(data_dir=data_dir,mode="train", tranform=train_transform)
#dataloader 加载数据
train_loader=DataLoader(dataset=train_data,batch_size=Batch_Size,shuffle=True)
# 准备测试数据集
test_data = CatDogDataset(data_dir=data_dir, mode="test", tranform=test_transform)
# 使用dataloader加载
test_loader = DataLoader(test_data, batch_size=Batch_Size, shuffle=False)
#.to(device)表示将模型放到device
model=AlexNetModel().to(device)
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#定义优化器
optimizer = torch.optim.Adam(model.parameters(),lr=lr)
#迭代
for epoch in range(1, epoches + 1):
total_loss = 0
#enumerate 表示将train_loader的数据不仅要取出来,还要加一个编号
for batch,(x_images,y_label) in enumerate(train_loader):
# 将数据和标签加入到GPU或者cpu中
x_images = x_images.to(device)
y_label = y_label.to(device)
y_pre = model(x_images)
# 计算损失
loss = loss_fn(y_pre, y_label)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
total_loss = total_loss + loss
print(f"epoch:{epoch},iter{batch}/{len(train_loader)},loss:{loss}")
return_acc = test_eval(test_loader, model, loss_fn, state_of_the_art_acc)
state_of_the_art_acc = return_acc
# 计算平均损失
avg_loss = total_loss / (len(train_loader))
# 评估模型
# test_eval(test_loader,model,loss_fn,state_of_the_art_acc)
# print(state_of_the_art_acc)
# 模型保存
# if epoch %10==1:
# 需要把model文件夹提前新建出来
# torch.save(model.state_dict(),f'model/model_{epoch}.pth')
print(f"epoch:{epoch}/{epoches},avg_loss:{avg_loss}")
print(BASE_DIR)

















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









