




大家好!我是大聪明-PLUS!
如果您有使用 Web 服务器的经验,您可能遇到过典型的“地址已被使用”(EADDRINUSE)情况。
本文不仅会详细介绍判断这种情况是否会在不久的将来发生的先决条件(为此,查看打开的套接字列表就足够了),而且还会解释如何跟踪内核中的特定代码路径(发生此类检查的地方)。
如果您只是好奇 socket(2)系统调用究竟如何工作以及所有这些套接字究竟存储在哪里,那么请务必阅读本文直到最后!

❯ socket有什么用处?
套接字是一种用于在不同机器上运行的进程之间进行通信的结构,这种通信通过网络进行,而网络是所有这些进程的底层网络。套接字有时也用于在同一主机上运行的进程之间进行通信(在本例中,我们指的是 Unix 套接字)。
《计算机网络:自上而下的方法》一书中给出了一个非常准确的类比,它阐明了套接字的本质,给我留下了深刻的印象。
从 最 一般的意义上讲,你可以把计算机想象成一座有很多门的“房子”。
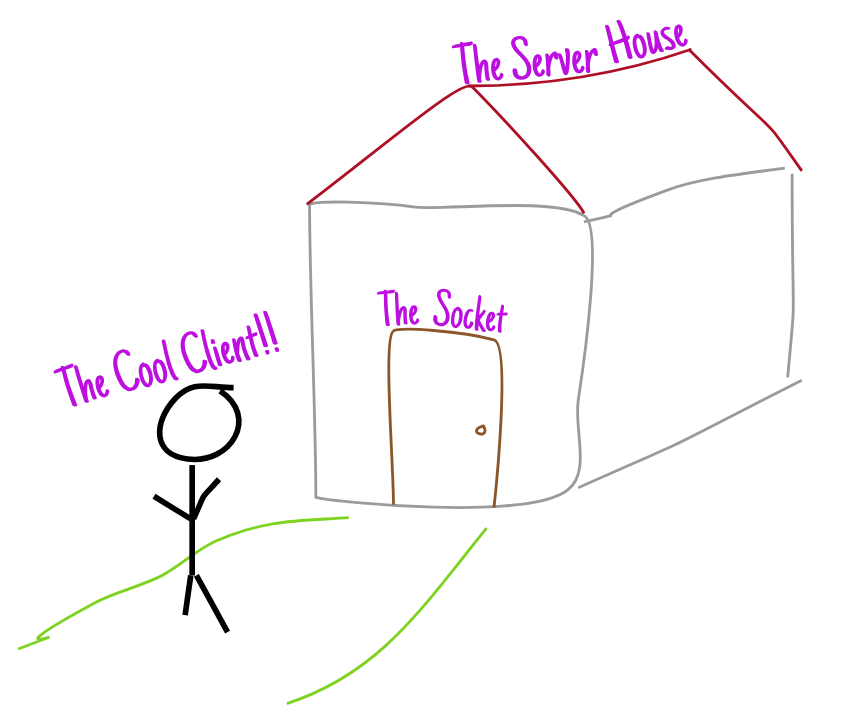
在这里,每一扇门都是一个插座,顾客一靠近,就可以“敲”一下。
敲门后(发送数据包 SYN),房屋会立即自动发出响应(SYN+ACK),然后进行自我认证(是的,这就是带有“智能门”的智能房屋)。
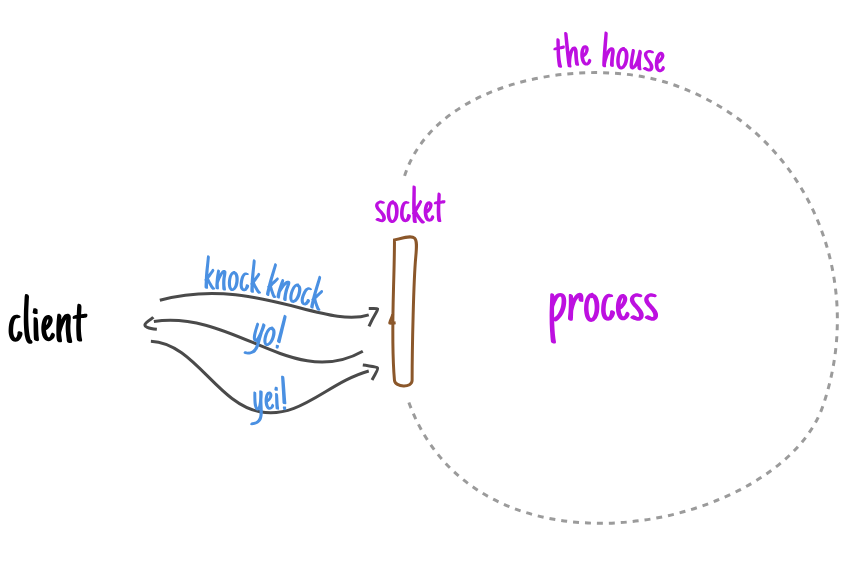
与此同时,虽然这个过程本身只是在家里进行,但“智能家居”本身会协调客户的工作并创建两个队列:一个队列用于仍在与房屋交换问候的人,另一个队列用于已经完成问候阶段的人。
一旦这些顾客进入第二队列,流程就会让他们进去。
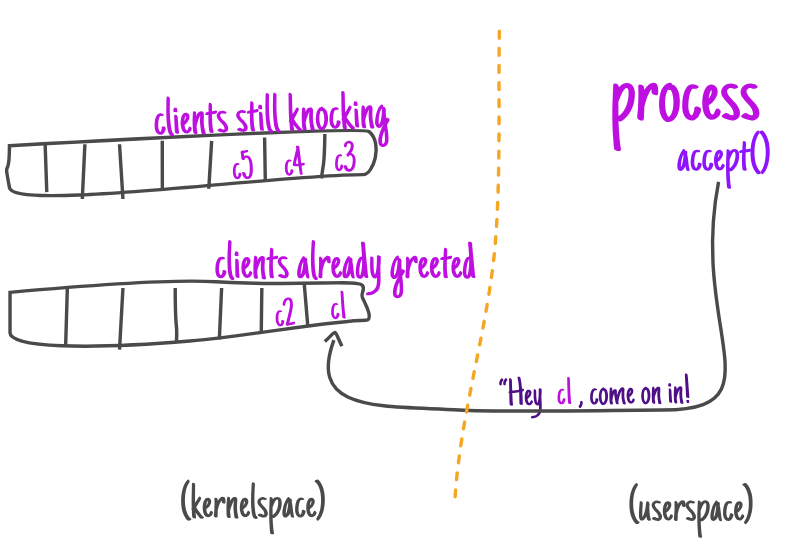
一旦连接被接受(客户端被告知加入),服务器就可以与客户端通信,根据需要发送和接收数据。
这里值得注意的是,客户端实际上“被禁止”进入房子。服务器在房子里创建了一个“私人门”(客户端套接字),然后通过它与客户端进行通信。
如果您逐步了解如何使用 C 实现 TCP 服务器,那么本文将更容易理解。如果您还不熟悉这个主题,请务必阅读文章“实现 TCP 服务器”。
❯ 我可以在哪里找到我的系统上可用的套接字列表?
一旦你很好地理解了 TCP 连接的建立方式,我们就可以“进入房子”,探索机器是如何创建这些“门”(套接字)的。我们还会了解房子里有多少扇门,以及每扇门的状态(关闭还是打开)。
为了做到这一点,让我们以一个仅创建套接字(门!)但不执行任何操作的服务器为例。
// socket.c
#include <stdio.h>
#include <sys/socket.h>
int main(int argc, char** argv)
{
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (err == -1) {
perror("socket");
return err;
}
sleep(3600);
return 0;
}
在底层,这样一个简单的系统调用运行了一大堆内部方法(下一节将详细介绍),最终将允许我们查找有关写入三个不同文件的活动套接字的信息: /proc/<pid>/net/tcp、 /proc/<pid>/fd和 /proc/<pid>/net/sockstat。
该目录 fd 列出了进程打开的文件,而文件本身则/proc/<pid>/net/tcp 报告了与该进程的网络命名空间关联的当前活动的 TCP 连接(处于各种状态)。或者,该文件 sockstat也可以被视为一种摘要。
从目录 fd 开始,可以注意到,调用之后, socket(2) 套接字文件描述符出现在类似描述符的列表中:
./socket.out &
[2] 21113
ls -lah /proc/21113/fd
dr-x------ 2 ubuntu ubuntu 0 Oct 16 12:27 .
dr-xr-xr-x 9 ubuntu ubuntu 0 Oct 16 12:27 ..
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 0 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 1 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 2 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 3 -> 'socket:[301666]'
考虑到 socket(2) 简单的调用不会建立任何 TCP 连接,我们不会从中找到或收集任何重要信息/proc/<pid>/net/tcp。
从摘要(sockstat)中,我们可以猜测分配的 TCP 套接字数量正在逐渐增加:
cat /proc/21424/net/sockstat
sockets: used 296
TCP: inuse 3 orphan 0 tw 4 alloc 106 mem 1
UDP: inuse 1 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0
为了确保这个数字在我们工作时确实会增加 alloc ,让我们修改上面的代码并尝试一次分配 100 个套接字:
+ for (int i = 0; i < 100; i++) {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (err == -1) {
perror("socket");
return err;
}
+ }
现在,通过再次检查此参数,让我们确保分配数确实增加了:
cat /proc/21456/net/sockstat
bigger than before!
|
sockets: used 296 .----------.
TCP: inuse 3 orphan 0 tw 4 | alloc 207| mem 1
UDP: inuse 1 mem 0 *----------*
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0
❯ 当执行套接字系统调用时,底层究竟发生了什么?
socket(2) 就像一个工厂,生产用于处理此类套接字上的操作的基本结构。
使用 iovisor/bcc,您可以最大深度地跟踪 sys_socket 堆栈中发生的所有调用,并根据这些信息了解每个步骤。
| socket()
|--------------- (kernel boundary)
| sys_socket
| (socket, type, protocol)
| sock_create
| (family, type, protocol, res)
| __sock_create
| (net, family, type, protocol, res, kern)
| sock_alloc
| ()
˘
从 sys_socket 本身开始,这个系统调用包装器是内核空间中接触到的第一层。在这一层,系统调用会执行各种检查,并准备一些标志以供后续调用使用。
一旦执行了所有初步检查,调用就会struct socket在其自己的堆栈上分配一个指向结构的指针,该结构包含有关套接字的非协议细节:
SYSCALL_DEFINE3(socket,
int, family,
int, type,
int, protocol)
{
struct socket *sock;
int retval, flags;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
struct socket {
socket_state state;
short type;
unsigned long flags;
struct sock* sk;
const struct proto_ops* ops;
struct file* file;
// ...
};
鉴于我们目前正在创建一个套接字,并且可以从各种协议类型和协议族(例如 UDP、UNIX 和 TCP)中进行选择,因此 struct socket 该套接字包含一个接口 ( struct proto_ops*),该接口定义了套接字实现的基本结构。这些结构与类型和协议族无关,此操作通过调用以下方法启动: sock_create。
int __sock_create(struct net *net,
int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
return -ENFILE;
}
sock->type = type;
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
// ...
}
继续这项详细的研究,让我们仔细看看如何struct socket 使用该方法 提取结构sock_alloc()。
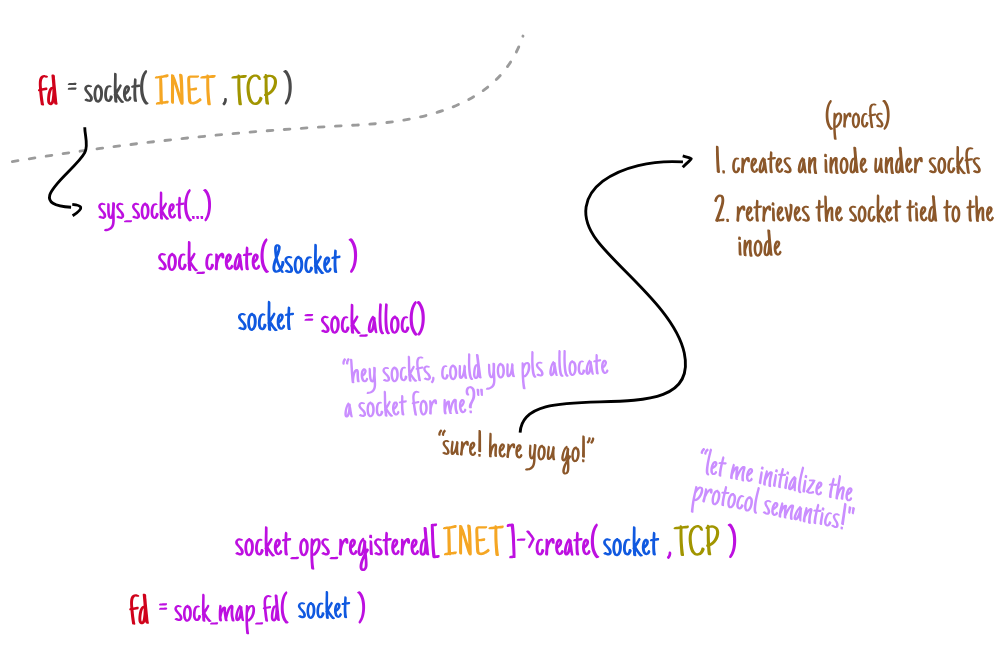
❯此方法的目的是分配两个实体:一个新的 inode 和一个套接字对象。
它们在文件系统级别上连接 sockfs,这不仅负责跟踪整个系统的套接字信息,而且还提供了一个转换层,通过该转换层,正常的文件系统调用(例如 write(2))和网络堆栈(无论这种通信发生在哪个底层域)都可以进行通信。
sock_alloc_inode通过监视负责分配索引描述符的 方法的操作 sockfs,我们可以观察到整个过程是如何组织的:
trace -K sock_alloc_inode
22384 22384 socket-create.out sock_alloc_inode
sock_alloc_inode+0x1 [kernel]
new_inode_pseudo+0x11 [kernel]
sock_alloc+0x1c [kernel]
__sock_create+0x80 [kernel]
sys_socket+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
inode = new_inode_pseudo(sock_mnt->mnt_sb);
if (!inode)
return NULL;
sock = SOCKET_I(inode);
inode->i_ino = get_next_ino();
inode->i_mode = S_IFSOCK | S_IRWXUGO;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_op = &sockfs_inode_ops;
this_cpu_add(sockets_in_use, 1);
return sock;
}
static struct inode *sock_alloc_inode(
struct super_block *sb)
{
struct socket_alloc *ei;
struct socket_wq *wq;
ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL);
if (!ei)
return NULL;
wq = kmalloc(sizeof(*wq), GFP_KERNEL);
if (!wq) {
kmem_cache_free(sock_inode_cachep, ei);
return NULL;
}
ei->socket.state = SS_UNCONNECTED;
ei->socket.flags = 0;
ei->socket.ops = NULL;
ei->socket.sk = NULL;
ei->socket.file = NULL;
return &ei->vfs_inode;
}
❯ 套接字和资源限制
假设可以使用文件描述符从用户空间引用文件系统 inode,则会出现以下情况:在我们设置了所有基本内核结构之后,它会为用户生成一个文件描述符。
如果您曾经想过为什么socket(2)在使用时可能会出现“打开太多文件”错误,这全都归因于这些资源限制检查:
static int
sock_map_fd(struct socket* sock, int flags)
{
struct file* newfile;
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0)) {
sock_release(sock);
return fd;
}
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
❯ 计算系统中的socket数量
如果您一直密切关注 sock_alloc调用的作用,我想指出它实际上增加了当前“正在使用”的套接字的数量。
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
// ....
this_cpu_add(sockets_in_use, 1);
return sock;
}
由于 this_cpu_add 是一个宏,您可以查看其定义以了解有关它的更多信息:
现在,考虑到我们不断向 中添加套接字 sockets_in_use,我们至少可以假设为/proc/net/sockstat注册的方法 将使用这个值——事实上,情况确实如此。这也意味着我们将把每个 CPU 核心上注册的所有值加起来:
static int sockstat_seq_show(struct seq_file *seq, void *v)
{
struct net *net = seq->private;
unsigned int frag_mem;
int orphans, sockets;
orphans = percpu_counter_sum_positive(&tcp_orphan_count);
sockets = proto_sockets_allocated_sum_positive(&tcp_prot);
socket_seq_show(seq);
seq_printf(seq, "TCP: inuse %d orphan %d tw %d alloc %d mem %ld\n",
sock_prot_inuse_get(net, &tcp_prot), orphans,
atomic_read(&net->ipv4.tcp_death_row.tw_count), sockets,
proto_memory_allocated(&tcp_prot));
// ...
seq_printf(seq, "FRAG: inuse %u memory %u\n", !!frag_mem, frag_mem);
return 0;
}
❯ 那么命名空间呢?
您可能已经注意到,与命名空间相关的代码缺少任何逻辑来计算当前分配了多少个套接字。
这一点最初让我非常惊讶,因为我以为命名空间在网络栈中使用最为频繁。但事实证明也有例外。
这里的要点是:您可以创建一组套接字,查看 sockstat,然后创建一个网络命名空间,进入它,然后发现虽然我们没有一次看到来自整个系统的 TCP 套接字(这就是命名空间分隔的工作方式!),但我们仍然可以看到系统中分配的套接字总数(就好像没有命名空间一样)。
./sockets.out
cat /proc/net/sockstat
sockets: used 296
TCP: inuse 5 orphan 0 tw 2 alloc 108 mem 3
UDP: inuse 1 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0
ip netns add namespace1
ip netns exec namespace1 /bin/bash
TCP: inuse 0 orphan 0 tw 0 alloc 108 mem 3
UDP: inuse 0 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0
❯ 综上所述
回顾我所取得的成就,真是妙趣横生。我深入研究内核的内部原理,仅仅是因为我对它的工作原理感到好奇/proc。最终,我找到了一些答案,帮助我理解日常工作中遇到的特定函数的行为。

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









