






演示异常的出现
# 通过open,读取一个不存在的文件
f = open("D:/abc.txt", "r", encoding="UTF-8")
异常的捕获
try:
f = open("D:/123.txt", "r", encoding="UTF-8")
except Exception as e:
print("出现异常了")
f = open("D:/123.txt", "w", encoding="UTF-8")
else:
print("好高兴,没有异常。")
finally:
print("我是finally,有没有异常我都要执行")
f.close()
异常的传递
def func1():
print("func1 开始执行")
num = 1 / 0 # 肯定有异常,除以0的异常
print("func1 结束执行")
# 定义一个无异常的方法,调用上面的方法
def func2():
print("func2 开始执行")
func1()
print("func2 结束执行")
# 定义一个方法,调用上面的方法
def main():
try:
func2()
except Exception as e:
print(f"出现异常了,异常的信息是:{e}")
main()
模块的导入
from time import sleep
# 使用import导入time模块使用sleep功能(函数)
# import time # 导入Python内置的time模块(time.py这个代码文件)
# print("你好")
# time.sleep(5) # 通过. 就可以使用模块内部的全部功能(类、函数、变量)
# print("我好")
# 使用from导入time的sleep功能(函数)
# from time import sleep
# print("你好")
# sleep(5)
# print("我好")
# 使用 * 导入time模块的全部功能
# from time import * # *表示全部的意思
# print("你好")
# sleep(5)
# print("我好")
# 使用as给特定功能加上别名
# import time as t
# print("你好")
# t.sleep(5)
# print("我好")
from time import sleep as sl
print("你好")
sl(5)
print("我好")
自定义模块
# 导入自定义模块使用
# import my_module1
# from my_module1 import test
# test(1, 2)
# 导入不同模块的同名功能
# from my_module1 import test
# from my_module2 import test
# test(1, 2)
# __main__变量
# from my_module1 import test
# __all__变量
from my_module1 import *
test_a(1, 2)
# test_b(2, 1)
包
创建一个包
# 导入自定义的包中的模块,并使用
# import my_package.my_module1
# import my_package.my_module2
#
# my_package.my_module1.info_print1()
# my_package.my_module2.info_print2()
# from my_package import my_module1
# from my_package import my_module2
# my_module1.info_print1()
# my_module2.info_print2()
# from my_package.my_module1 import info_print1
# from my_package.my_module2 import info_print2
# info_print1()
# info_print2()
# 通过__all__变量,控制import *
from my_package import *
my_module1.info_print1()
my_module2.info_print2()
json数据格式
演示JSON数据和Python字典的相互转换
"""
import json
# 准备列表,列表内每一个元素都是字典,将其转换为JSON
data =
[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]
json_str = json.dumps(data, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 准备字典,将字典转换为JSON
d = {"name":"周杰轮", "addr":"台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
# 将JSON字符串转换为Python数据类型[{k: v, k: v}, {k: v, k: v}]
s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]'
l = json.loads(s)
print(type(l))
print(l)
# 将JSON字符串转换为Python数据类型{k: v, k: v}
s = '{"name": "周杰轮", "addr": "台北"}'
d = json.loads(s)
print(type(d))
print(d)
_pyecharts基础入门
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])
# 设置全局配置项set_global_opts来设置,
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True),
)
# 通过render方法,将代码生成为图像
line.render()
折线图开发
ata, la# 处理数据
f_us = open("D:/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容
f_jp = open("D:/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容
f_in = open("D:/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容
# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
# 去掉不合JSON规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][
# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_dbel_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
# 设置全局选项
line.set_global_opts(
# 标题设置
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
地图可视化的基本使用
准备地图对象
map = Map()
# 准备数据
data = [
("北京", 99),
("上海", 199),
("湖南", 299),
("台湾", 399),
("广东", 499)
]
# 添加数据
map.add("测试地图", data, "china")
# 设置全局选项
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 9, "label": "1-9", "color": "#CCFFFF"},
{"min": 10, "max": 99, "label": "10-99", "color": "#FF6666"},
{"min": 100, "max": 500, "label": "100-500", "color": "#990033"}
]
)
)
# 绘图
map.render()
基础柱状图开发
from pyecharts.charts import Bar
from pyecharts.options import LabelOpts
# 使用Bar构建基础柱状图
bar = Bar()
# 添加x轴的数据
bar.add_xaxis(["中国", "美国", "英国"])
# 添加y轴数据
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
# 反转x和y轴
bar.reversal_axis()
# 绘图
bar.render("基础柱状图.html")
# 反转x轴和y轴
# 设置数值标签在右侧
基础时间线柱状图开发
bar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国"])
bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国"])
bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(["中国", "美国", "英国"])
bar3.add_yaxis("GDP", [70, 60, 60], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
# 构建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 在时间线内添加柱状图对象
timeline.add(bar1, "点1")
timeline.add(bar2, "点2")
timeline.add
# 自动播放设置
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
# 绘图是用时间线对象绘图,而不是bar对象了
timeline.render("基础时间线柱状图.html")
拓展知识点-列表的sort方法
my_list = [["a", 33], ["b", 55], ["c", 11]]
# 排序,基于带名函数
# def choose_sort_key(element):
# return element[1]
#
# my_list.sort(key=choose_sort_key, reverse=True)
# 排序,基于lambda匿名函数
my_list.sort(key=lambda element: element[1], reverse=True)
print(my_list)
GDP动态柱状图开发
# 读取数据
f = open("D:/1960-2019全球GDP数据.csv", "r", encoding="GB2312")
data_lines = f.readlines()
# 关闭文件
f.close()
# 删除第一条数据
data_lines.pop(0)
# 将数据转换为字典存储,格式为:
# { 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... }
# { 1960: [ [美国, 123], [中国,321], ...... ], 1961: [ [美国, 123], [中国,321], ...... ], ...... }
# 先定义一个字典对象
data_dict = {}
for line in data_lines:
year = int(line.split(",")[0]) # 年份
country = line.split(",")[1] # 国家
gdp = float(line.split(",")[2]) # gdp数据
# 如何判断字典里面有没有指定的key呢?
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country, gdp])
# print(data_dict[1960])
# 创建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 排序年份
sorted_year_list = sorted(data_dict.keys())
for year in sorted_year_list:
data_dict[year].sort(key=lambda element: element[1], reverse=True)
# 取出本年份前8名的国家
year_data = data_dict[year][0:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) # x轴添加国家
y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据
# 构建柱状图
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
# 反转x轴和y轴
bar.reversal_axis()
# 设置每一年的图表的标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
)
timeline.add(bar, str(year))
# for循环每一年的数据,基于每一年的数据,创建每一年的bar对象
# 在for中,将每一
pymysql_数据插入
from pymysql import Connection
# 构建到MySQL数据库的链接
conn = Connection(
host="localhost", # 主机名(IP)
port=3306, # 端口
user="root", # 账户
password="123456", # 密码
autocommit=True # 自动提交(确认)
)
# print(conn.get_server_info())
# 执行非查询性质SQL
cursor = conn.cursor() # 获取到游标对象
# 选择数据库
conn.select_db("world")
# 执行sql
cursor.execute("insert into student values(10002, '林俊节', 31, '男')")
# # 通过commit确认
# conn.commit()
# 关闭链接
conn.close()
data_define
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
def to_json(self):
d = {"date": self.date, "order_id": self.order_id, "money": self.money, "province": self.province}
import json
return json.dumps(d)
file_define
class FileReader:
def read_data(self) -> list[Record]:
"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
f.close()
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
def read_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
d
闭包
def account_create(initial_amount=0):
def atm(num, deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num}, 账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"取款:-{num}, 账户余额:{initial_amount}")
return atm
atm = account_create()
atm(100)
atm(200)
atm(100, deposit=False)
_装饰器
def outer(func):
def inner():
print("我睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1, 5))
工厂模式
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class PersonFactory:
def get_person(self, p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
_多线程编程
def sing(msg):
print(msg)
time.sleep(1)
def dance(msg):
print(msg)
time.sleep(1)
if __name__ == '__main__':
# 创建一个唱歌的线程
sing_thread = threading.Thread(target=sing, args=("我要唱歌 哈哈哈", ))
# 创建一个跳舞的线程
dance_thread = threading.Thread(target=dance, kwargs={"msg": "我在跳舞哦 啦啦啦"})
# 让线程去干活吧
sing_thread.start()
dance_thread.start()
socket编程_服务端开发
import socket
# 创建Socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost", 8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受的链接数量
# 等待客户端链接
# result: tuple = socket_server.accept()
# conn = result[0] # 客户端和服务端的链接对象
# address = result[1] # 客户端的地址信息
conn, address = socket_server.accept()
# accept方法返回的是二元元组(链接对象, 客户端地址信息)
# 可以通过 变量1, 变量2 = socket_server.accept()的形式,直接接受二元元组内的两个元素
# accept()方法,是阻塞的方法,等待客户端的链接,如果没有链接,就卡在这一行不向下执行了
print(f"接收到了客户端的链接,客户端的信息是:{address}")
while True:
# 接受客户端信息,要使用客户端和服务端的本次链接对象,而非socket_server对象
data: str = conn.recv(1024).decode("UTF-8")
# recv接受的参数是缓冲区大小,一般给1024即可
# recv方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 发送回复消息
msg = input("请输入你要和客户端回复的消息:")
if msg == 'exit':
break
conn.send(msg.encode("UTF-8"))
# 关闭链接
conn.close()
socket_server.close()
递归
import os
def test_os():
"""演示os模块的3个基础方法"""
print(os.listdir("D:/test")) # 列出路径下的内容
# print(os.path.isdir("D:/test/a")) # 判断指定路径是不是文件夹
# print(os.path.exists("D:/test")) # 判断指定路径是否存在
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中使用递归的方式,获取全部的文件列表
:param path: 被判断的文件夹
:return: list,包含全部的文件,如果目录不存在或者无文件就返回一个空list
"""
print(f"当前判断的文件夹是:{path}")
file_list = []
if os.path.exists(path):
for f in os.listdir(path):
new_path = path + "/" + f
if os.path.isdir(new_path):
# 进入到这里,表明这个目录是文件夹不是文件
file_list += get_files_recursion_from_dir(new_path)
else:
file_list.append(new_path)
else:
print(f"指定的目录{path},不存在")
return []
return file_list
if __name__ == '__main__':
print(get_files_recursion_from_dir("D:/test"))
def a():
a()
文献综述
人工智能在医学CT图像重建中的研究进展
1.深度学习对医学CT图像重建的应用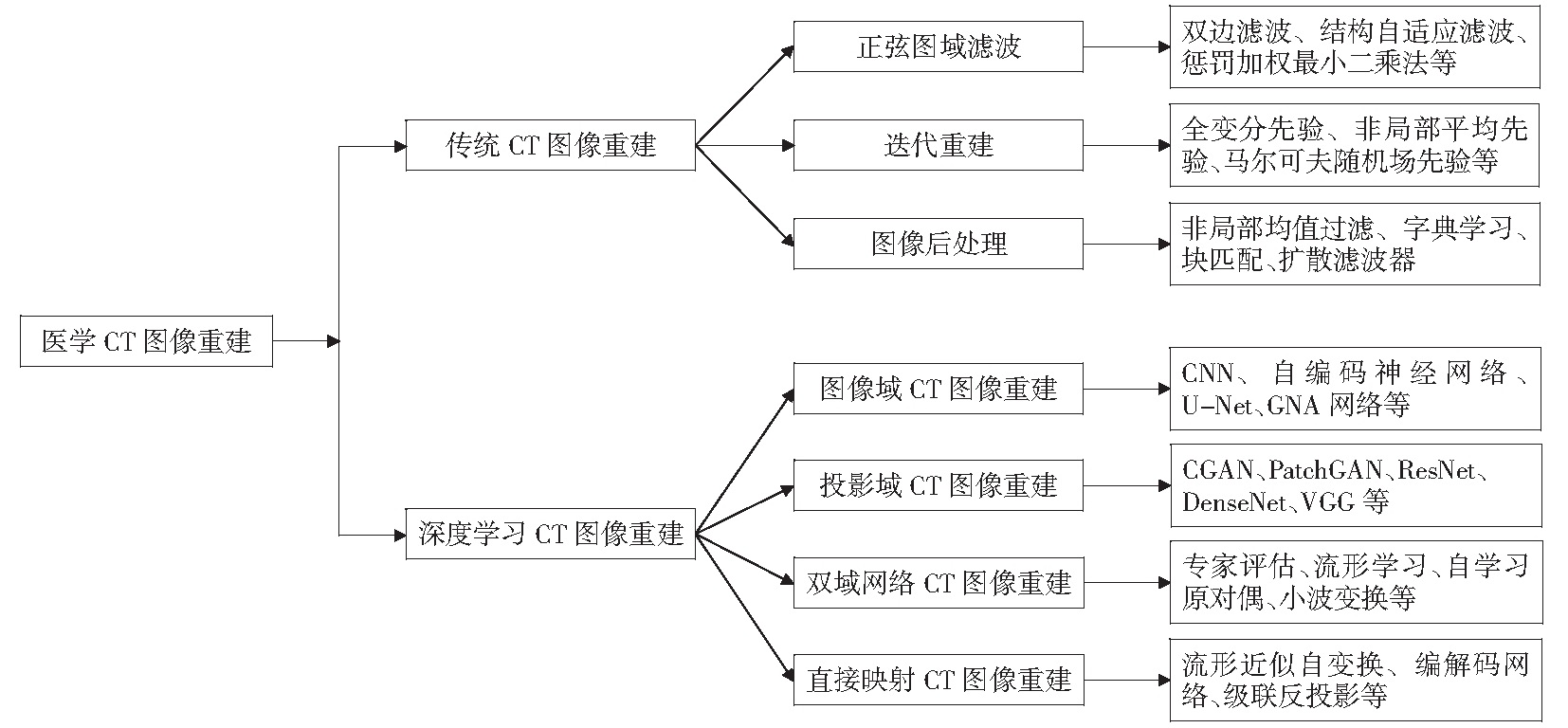
2.深度学习重建算法的分类:对原始数据进行预处理的投影域CT图像重建、图像后处理的图像域CT图像重建、双域网络CT图像重建以及直接映射CT图像重建。
3.CT图像成像原理:y=A(F(x),N),其中,F(·)代表成像物理结构进行建模的正向操作运算,一般包括雷登变换(Radon)或傅里叶变换,它可以是线性操作,也可以是非线性操作,具体取决于成像模式。A表示噪声和信号之间的相互作用。图像重建还是一个不确定的问题,因为测量值(M)往往比未知数(N)少得多。
4.传统方法在CT图像重建中的应用
a.正弦图域滤波方法:主要目的是从低剂量X射线束获得的CT原始数据中滤除噪声,通过直接对反投影前形成的原始投影数据进行重建,可以准确地计算噪声统计量并进行有效重建。
b.迭代重建方法:迭代重建方法基于成像系统的物理、传感器和噪声统计的更复杂的模型,将传感器域(原始测量数据)中数据的统计特性、图像域中的先验信息,有时还将成像系统的参数组合到其损失函数中。
c.图像后处理重建方法:图像后处理重建算法直接应用于CT图像,而不是原始投影数据,相比于迭代重建方法,它的重建速度非常快,而且不需要供应商提供原始数据,它可以很轻松地集成到CT设备的工作流程中。
4.深度学习在ct图像重建中的应用
深度学习是人工智能的一个分支学科,它利用经验自动学习和改进应用程序,通过构建深度神经网络处理各种任务。深度学习模型由多层特征表示(除了输入层和输出层之外的多个隐藏层)组成,从原始输入开始通过多层网络提取不同抽象层次的特征表示,从而使复杂函数的学习成为可能[35];它的关键特征是利用所提供的数据样本自动学习用于特征提取的所有参数,与人工特征方法相比,可以更好地针对特定问题进行自我优化。当输入是图像时,低层特征通常表示图像中的边缘和轮廓,而高层特征通常是语义特征。
5.深度学习的ct图像重建的四个子类:投影域CT图像重建、图像域CT图像重建、双域网络CT图像重建和直接映射CT图像重建。图2描述了深度学习方法用于CT图像重建的四个子类。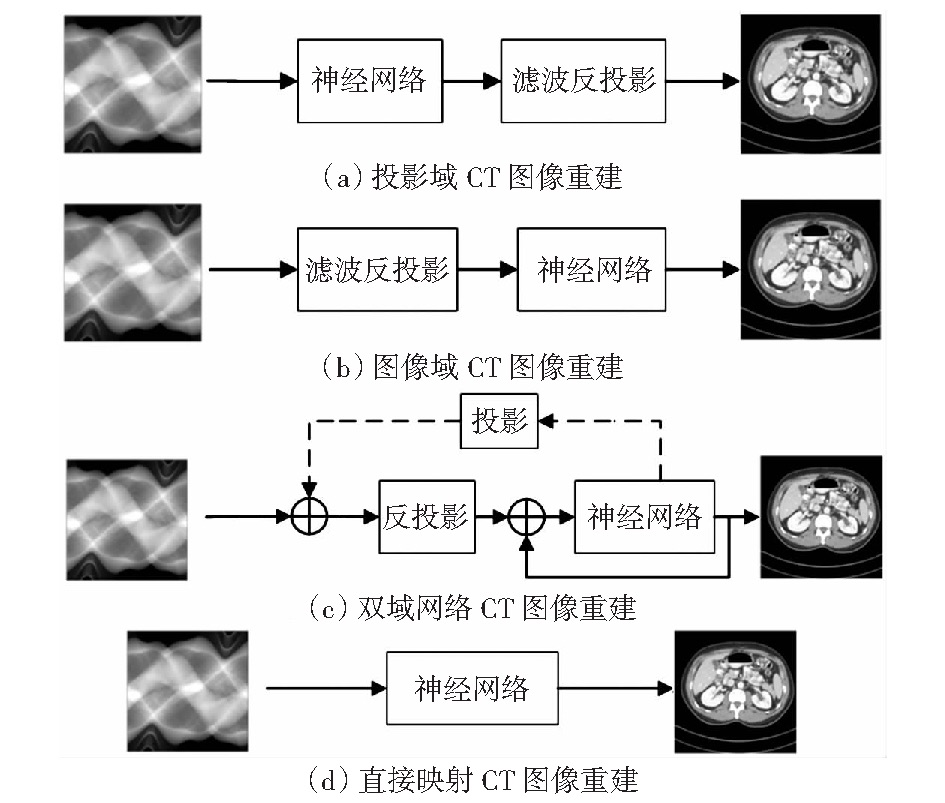
6.投影域CT图像重建
主要目标是利用深度学习模型估计在信号采集阶段没有采集到的缺失部分,以便将更完整的信号信息输入到滤波反投影层进行重建过程。LIANG et al[40]提出一种深度残差卷积神经网络,用于在滤波反投影重建图像的同时,从未测量的视图进行精确的全视图估计。
7.深度学习对CT图像重建的具体影响
a.深度学习模型能够从不完整或低剂量的投影数据中估计缺失部分,从而生成更完整的信号信息,输入到滤波反投影层进行高质量重建。 深度学习方法可以恢复更多重要的图像细节(如纹理信息),减少条纹伪影,并提高重建图像的清晰度和分辨率。
b.深度学习模型通过优化算法设计(如深度残差卷积神经网络、注意残余密集卷积神经网络等),可以在保证重建质量的同时显著加快重建速度。 一些框架(如FU et al[45]提出的不完全数据重建框架)通过减少参数数量和优化计算流程,进一步提升了重建效率。
8.深度学习方法在投影域CT重建中的应用
9.深度学习方法在图像域CT重建中的应用



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









