






✨️ 概述
DrissionPage® 是一个基于 Python 的网页自动化工具。
既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
功能强大,语法简洁优雅,代码量少,对新手友好。
控制浏览器
电脑必须安装谷歌浏览器,或者chrome内核浏览器:比如edge,qq浏览器等(dp版本大于4.1)#从dp库导入chromium
from DrissionPage import Chromium
#连接浏览器并创建浏览器对象
browser = Chromium()
#通过浏览器对象创建一个新标签页,新标签页访问百度网址
tab = browser.new_tab('https://www.baidu.com')启动浏览器前的配置
此案例有权限问题无法修改浏览器路径
#从dp库导入chromium
from DrissionPage import Chromium
#ChromiumOptions 类专门用于配置启动浏览器之前的参数
from DrissionPage import ChromiumOptions
#创建浏览器启动配置对象
options = ChromiumOptions()
#配置浏览器启动的选项
#设置浏览器路径
options.set_browser_path(r'"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"')
#忽略证书错误 比如https 没有s 谷歌浏览器会报错 加上这个可以忽略掉此错误
options.ignore_certificate_errors
#禁用图片
options.no_imgs()
#无头模式
options.headless(False)
#设置浏览器debug端口 比如我想从其他调试浏览器端口进入
#options.set_local_port(9696)
# 设置启动时最大化
options.set_argument('--start-maximized')
# 设置初始窗口大小
options.set_argument('--window-size', '800,600')
#此方法用于清空已设置的arguments参数。
options.clear_arguments()
#把创建的options对象传入browser对象
browser = Chromium(options)
#获取标签页对象打开网址
tab = browser.new_tab('https://www.baidu.com')操作标签页
browser.latest_tab --- 最新标签页(最后打开的标签页)
from DrissionPage import Chromium
# 创建一个Chromium浏览器实例
browser = Chromium()
# 打开一个新的标签页,访问百度
tab1 = browser.new_tab('https://www.baidu.com')
# 打开一个新的标签页,访问必应
tab2 = browser.new_tab('https://www.bing.com')
# 获取最新打开的标签页
tab3 = browser.latest_tab
# 打印百度标签页的标题
print(tab1.title)
# 打印必应标签页的标题
print(tab2.title)
# 打印最新标签页的标题
print(tab3.title)
# 关闭浏览器的最新标签页
browser.latest_tab.close()标签页没有Selenium所谓的焦点的概念,多个标签页可以并行操作,所以可以多线程同时打开多个标签页
#标签页没有Selenium所谓的焦点的概念,多个标签页可以并行操作,所以可以多线程同时打开多个标签页
# 导入ThreadPoolExecutor类,用于创建和管理一个线程池
from concurrent.futures import ThreadPoolExecutor
def open_url(browser, url):
"""
打开指定的URL。
:param browser: 浏览器实例,用于打开URL。
:param url: 需要打开的网址字符串。
"""
browser.new_tab(url)
# 定义一个包含多个中文网站URL的列表
chinese_websites=[
"https://www.taobao.com",
"https://www.jd.com",
"https://www.tmall.com"
]
# 使用ThreadPoolExecutor来并发打开URL,最大工作线程数设置为3
with ThreadPoolExecutor(max_workers=3) as executor:
# 遍历网址列表,提交任务到线程池
for url in chinese_websites:
executor.submit(open_url, browser, url)元素定位之普通元素定位
第一种:文本内容定位 tab.ele('文库')
-
原理:这种定位方式是基于元素的文本内容进行查找。它会在页面中搜索所有包含指定文本(这里是 “文库”)的元素,并返回第一个匹配的元素。
-
优点:非常直观和简单,适用于通过元素显示的文本来定位元素的场景,尤其当元素没有明确的 ID、类名等属性时,使用文本内容定位是一种有效的方法。
-
缺点:不够精确,因为可能存在多个元素包含相同的文本内容。而且如果页面上的文本发生变化,定位可能会失效。
-
适用场景:适用于元素文本具有唯一性且比较稳定的情况,例如按钮、链接等元素的文本通常是固定的,可以使用这种方式定位。
第二种:ID 属性定位 tab.ele('@id=kw')
-
原理:通过元素的
id属性来定位元素。在 HTML 中,id属性是唯一的,每个元素的id值在页面中应该是独一无二的。因此,使用id属性定位可以准确地找到特定的元素。 -
优点:定位精确,效率高。由于
id的唯一性,使用id属性定位可以快速准确地找到目标元素,并且不容易受到页面结构变化的影响。 -
缺点:如果页面的 HTML 代码中没有为目标元素设置
id属性,或者id属性值被动态修改,这种定位方式就会失效。 -
适用场景:适用于页面中具有唯一
id属性的元素,如输入框、特定的按钮等。在大多数情况下,优先使用id属性定位可以提高代码的稳定性和可维护性。
第三种:属性组合定位 tab.ele('tag:input@@type=submit@@value=百度一下')
-
原理:这是一种组合定位方式,它结合了元素标签名和多个属性来定位元素。在这个例子中,它会查找标签名为
input,type属性值为submit,value属性值为百度一下的元素。 -
优点:定位更加精确,可以通过多个条件来筛选元素,适用于需要根据多个属性来确定唯一元素的场景。
-
缺点:代码相对复杂,需要了解元素的多个属性信息。而且如果页面的 HTML 结构或属性值发生变化,定位可能会失效。
-
适用场景:当仅使用单个属性无法准确定位元素时,可以使用属性组合定位。例如,页面上可能有多个
input元素,通过结合type和value属性可以更准确地找到目标按钮。
第四种:XPath 定位 tab('xpath:/html/body/div[1]/div[1]/div[5]/div[2]/div/form/span[2]/input')
-
原理:XPath 是一种用于在 XML 或 HTML 文档中定位节点的语言。这里使用的是绝对 XPath,从文档的根节点(``)开始,按照元素的层级结构和索引来精确描述元素的位置。
-
优点:定位能力强大,可根据元素的层级、属性、文本内容等多种信息定位,灵活性高。可以处理复杂的页面结构和动态元素。
-
缺点:代码复杂且难以维护,绝对 XPath 对页面结构变化非常敏感,一旦页面结构有改动,定位就会失效。而且相比其他定位方式,性能可能稍差,因为需要遍历整个 DOM 树来匹配。
-
适用场景:当元素没有明显的 ID、类名等属性,或者需要根据元素的相对位置定位时使用。不过更推荐使用相对 XPath 来提高稳定性。
xpath如图获取
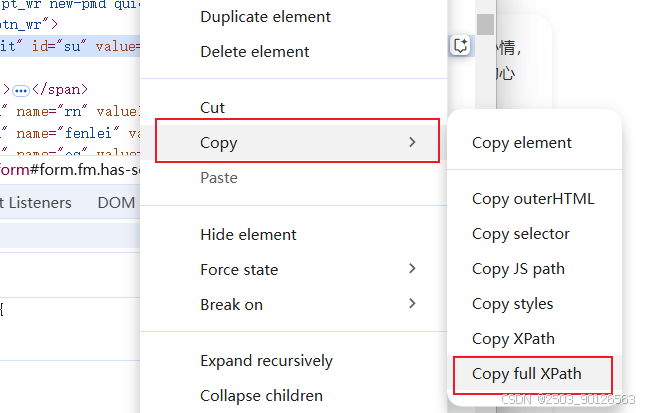
绝对 XPath 对页面结构变化非常敏感,推荐使用相对 XPath 来提高代码的稳定性。例如,如果要定位
value属性为百度一下的input元素,可以使用以下相对 XPath 表达式:
关于xpath还有一种优化写法:
search_button = tab('xpath://input[@value="百度一下"]')
search_button.click()其中元素是根据这些来填写

from DrissionPage import Chromium
# 创建Chromium浏览器实例
browser = Chromium()
# 打开新标签页并导航到指定URL
tab = browser.new_tab('https://www.baidu.com')
# 查找并点击页面上的"文库"按钮
wenku_button = tab.ele('文库')
wenku_button.click()
# 在搜索框中输入'python'
input_box = tab.ele('@id=kw')
input_box.input('python')
# 查找并点击搜索按钮
search_button = tab.ele('tag:input@@type=submit@@value=百度一下')
search_button.click()
# xpath定位搜索按钮并点击,开始搜索
search_button = tab('xpath:/html/body/div[1]/div[1]/div[5]/div[2]/div/form/span[2]/input')
search_button.click()
# 定位并点击具有特定值的搜索按钮
search_button = tab('xpath://input[@value="百度一下"]')
search_button.click()元素定位之iframe定位
iframe元素是一种特殊的定位元素,用于网页嵌套的元素。
<iframe>是什么?
<iframe>是 HTML 标签,用于在网页里嵌入另一个 HTML 文档。它能嵌入外部网页(如地图、视频),实现页面模块化和跨域通信。优点是内容独立、可复用、加载可控;缺点有性能差、样式布局难统一、影响 SEO。还存在安全风险 可用 sandbox 属性限制。
1. 专用框架定位法
iframe = tab.get_frame('t:iframe')
定位原理:
-
get_frame是专门用于获取框架(包括和)的方法。't:iframe'是一种元素定位表达式,t:表示通过标签名来定位,这里即定位标签名为iframe的元素。该方法会返回匹配条件的第一个 `` 框架对象,并且它会按照框架相关的逻辑进行查找和处理,确保返回的是一个有效的框架实例。
特点:
-
规范性高:这种方式是专门针对框架元素的定位方法,语义明确,代码的可读性和规范性较好,能够清晰地表明你是在获取一个框架元素。
-
功能完整:使用
get_frame方法获取的框架对象,在后续操作中可以完整地使用框架相关的功能和属性,例如可以方便地在该框架内继续定位元素、执行操作等。
试用场景:
-
当你明确要操作
<iframe>元素,并且希望代码具有较高的规范性和可读性时,推荐使用这种方式
# 创建Chromium浏览器实例
browser = Chromium()
# 打开一个新的标签页,访问指定的URL
tab = browser.new_tab('https://drissionpage.cn/demos/iframe_diff_domain.html')
# 获取页面中的iframe元素,使用最规范的方式
iframe = tab.get_frame('t:iframe') #最规范
# 在iframe中找到指定文本的元素,并打印
ele = iframe.ele('网易首页')
print(ele)2. 通用元素定位法
iframe = tab.ele('t:iframe')
定位原理:
-
ele方法是一个通用的元素定位方法,可以用于定位页面中的各种元素。同样,'t:iframe'表示通过标签名iframe来定位元素。该方法会返回匹配条件的第一个元素对象,这里返回的是 `` 元素对象。
特点:
-
简洁性好:使用通用的元素定位方法,代码简洁,不需要额外记忆专门的框架定位方法。
-
兼容性好:由于
ele是通用方法,在不同的场景下使用较为一致,对于已经熟悉该方法的开发者来说,使用起来更加顺手。
适用场景:
-
当你希望代码尽可能简洁,并且对框架的特殊处理需求不多时,可以选择这种方式。但需要注意的是,返回的是普通元素对象,在使用一些框架特定功能时可能需要进行额外的转换或处理。
# 创建Chromium浏览器实例
browser = Chromium()
# 打开一个新的标签页,访问指定的URL
tab = browser.new_tab('https://drissionpage.cn/demos/iframe_diff_domain.html')
# 获取页面中的iframe元素,使用最简洁的方式
iframe = tab.ele('t:iframe') #最简洁
# 在iframe中找到指定文本的元素,并打印
ele = iframe('网易首页')
print(ele)3.元素列表索引定位法
iframe = tab.eles('t:iframe')[0]
定位原理:
-
eles方法用于获取页面中所有匹配条件的元素列表。't:iframe'表示通过标签名iframe来定位元素,然后通过索引[0]从元素列表中取出第一个<iframe>元素对象。
特点:
-
成功率高:当页面中可能存在多个
元素,并且不确定使用其他方法是否能准确获取到目标时,使用eles方法可以先获取所有的 `` 元素,再通过索引选择需要的元素,从而提高定位的成功率。 -
灵活性强:可以根据实际情况选择不同索引的
元素,适用于需要处理多个元素的场景。
适用场景:
-
当页面中存在多个
元素,且你需要根据具体情况选择特定的元素时,这种方式更加合适。
# 创建Chromium浏览器实例
browser = Chromium()
# 打开一个新的标签页,访问指定的URL
tab = browser.new_tab('https://drissionpage.cn/demos/iframe_diff_domain.html')
# 获取页面中的iframe元素列表,使用成功率最高的方式
iframe = tab.eles('t:iframe')[0] #成功率最高
# 在iframe中找到指定文本的元素,并打印
ele = iframe('网易首页')
print(ele)代码运行控制台效果:



















 4225
4225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









