






前言
正则化通过约束模型的复杂度来防止过拟合,提高模型的泛化能力,可以根据具体问题和数据集的特点选择合适的正则化技术和参数设置。
常用的正则化方法,包括L1正则化(Lasso Regularization)、L2正则化(Ridge Regularization)和Dropout等。其中,L1正则化实现特征选择和模型稀疏化,L2正则化使权重值尽可能小,而Dropout则通过随机丢弃神经元来减少神经元之间的共适应性。
资料获取
为了方便大家学习,我整理了PyTorch全套学习资料,包含配套教程讲义和源码
除此之外还有100G人工智能学习资料
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集。更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
需要的兄弟可以按照这个图的方式免费获取
一、正则化
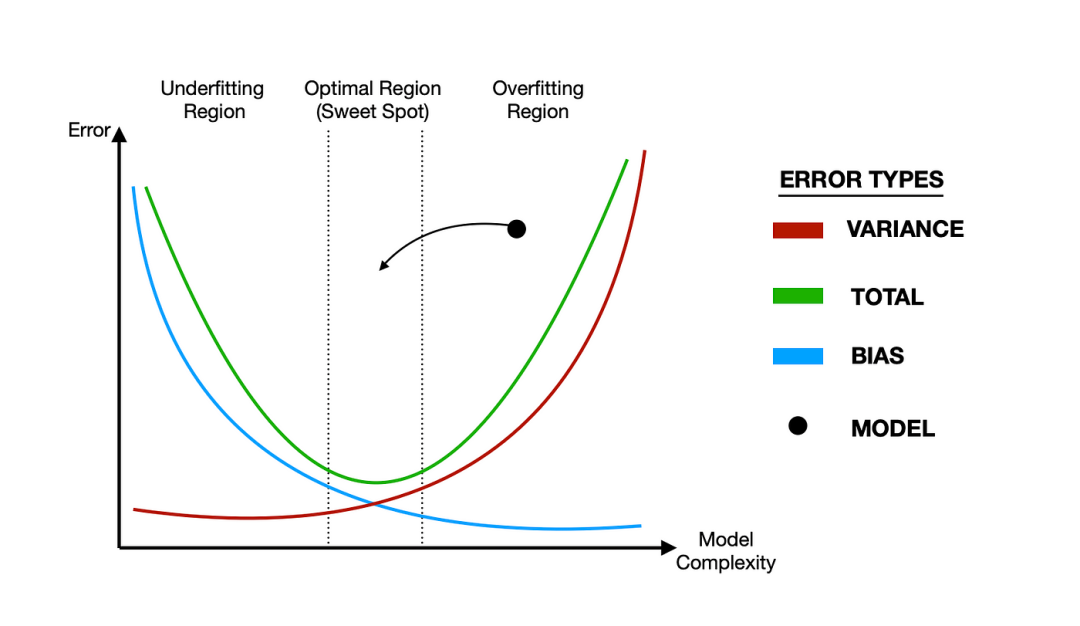
正则化(Regularization)是什么?正则化是一种减少模型过拟合风险的技术。
当模型在训练数据上表现得太好时,它可能会学习到训练数据中的噪声或随机波动,而不是数据中的基本模式。这会导致模型在未见过的数据上表现不佳,即过拟合。
正则化的目的是通过引入额外的约束或惩罚项来限制模型的复杂度,从而提高模型在未知数据上的泛化能力。
如何实现正则化?
正则化是通过在损失函数中添加一个正则项来实现的,这个正则项是基于模型参数而构建的。
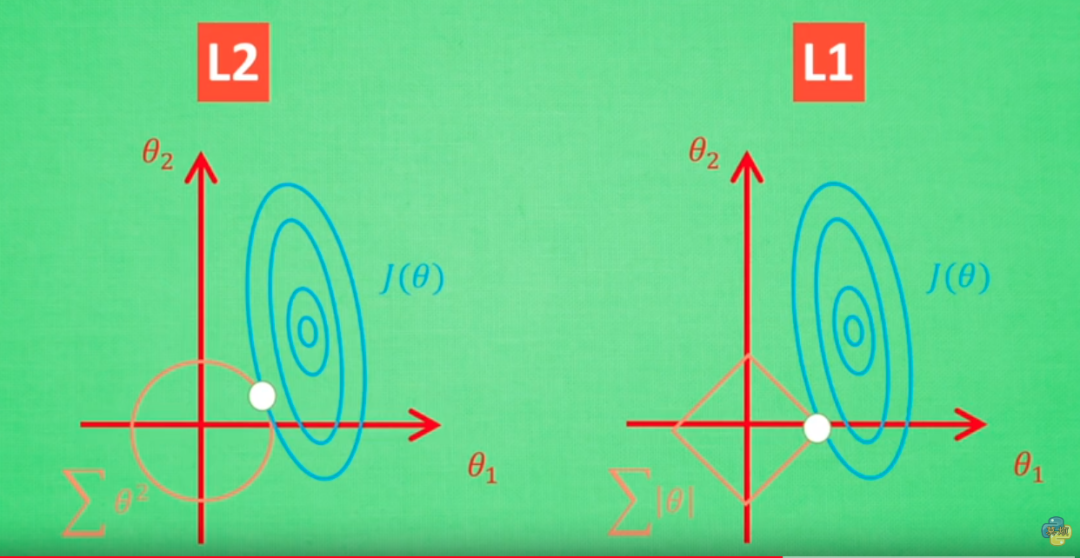
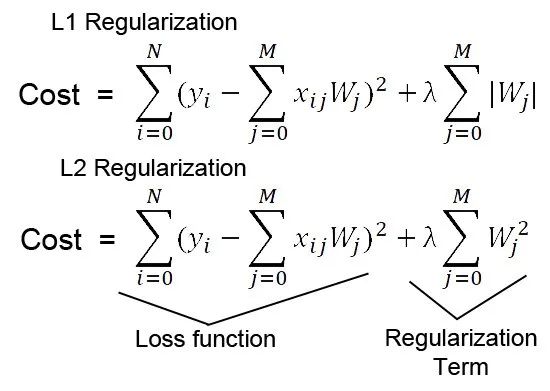
L1正则化在损失函数L中添加L1正则项,得到新的损失函数L_new = L + λ∑|w_i|,其中λ是正则化系数,w_i是模型参数。
L2正则化则在损失函数L中添加L2正则项,得到新的损失函数L_new = L + λ∑w_i^2,其中λ是正则化系数,w_i是模型参数。
在训练过程中,L1正则化、L2正则化都是通过优化算法最小化损失函数L_new,从而实现对模型参数的约束。
二、常用的正则化
常用的正则化有哪些?常用的正则化方法主要包括L1正则化(产生稀疏权重)、L2正则化(减少权重大小)、Dropout(随机丢弃神经元)、数据增强(扩充数据集)以及提前停止(监控验证误差)等,它们各自通过不同机制减少模型过拟合风险。
1. L1正则化(Lasso)
-
方法:在损失函数中添加模型参数绝对值之和作为惩罚项。
-
特点:倾向于产生稀疏权重矩阵,即部分特征权重为零,有助于特征选择。
-
def l1_regularization(model, lambda_l1): l1_loss = 0 for param in model.parameters(): l1_loss += torch.norm(param, p=1) # 绝对值之和 return lambda_l1 * l1_loss # 训练时修改loss计算 loss = criterion(outputs, labels) + l1_regularization(model, 0.001)
2. L2正则化(Ridge)
-
方法:在损失函数中添加模型参数平方和作为惩罚项。
-
特点:倾向于使权重值均匀分布且较小,有助于防止模型过于复杂,减少过拟合。
-
def l2_regularization(model, lambda_l2): l2_reg = torch.tensor(0.0) for param in model.parameters(): l2_reg += torch.norm(param, p=2) # 平方和 return lambda_l2 * l2_reg # 在训练循环中手动添加 loss = criterion(outputs, labels) + l2_regularization(model, 0.001)
3. Dropout:
-
方法:在神经网络训练过程中随机丢弃一部分神经元。
-
特点:减少了神经元之间的复杂共适应性,提高了模型的泛化能力。
import torch
import torch.nn as nn
class DropoutNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 512)
self.dropout = nn.Dropout(p=0.5) # 50%失活概率
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x) # 训练时激活dropout
return self.fc2(x)4. 数据增强(Data Augmentation):
-
方法:虽然不是直接对模型进行正则化,但通过对输入数据进行变换(如旋转、缩放、平移等)来扩充数据集。
-
特点:提高了模型的泛化能力,减少了过拟合的风险。
from torchvision import transforms
# 训练集增强组合
train_transform = transforms.Compose([
transforms.Resize(256), # 调整尺寸
transforms.RandomCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(15), # 随机旋转(-15°~15°)
transforms.ColorJitter( # 颜色抖动
brightness=0.2,
contrast=0.2,
saturation=0.2
),
transforms.ToTensor(), # 转为张量
transforms.Normalize( # 标准化
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 验证集处理(无随机增强)
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
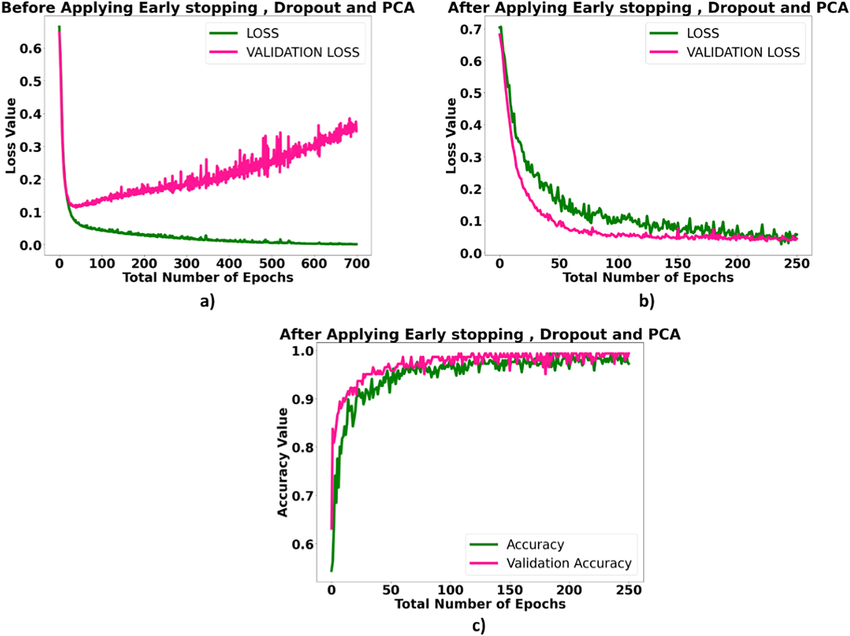
])5. 提前停止(Early Stopping):
-
方法:在训练过程中监测验证集上的误差变化。
-
特点:当验证集误差在一段时间内没有进一步改善时,停止训练并返回使验证集误差最低的模型。
# 监控验证准确率
early_stopping = AdvancedEarlyStopping(mode='max', patience=7)
for epoch in epochs:
# ...训练步骤...
val_acc = evaluate_accuracy(model, val_loader)
early_stopping(val_acc)
if early_stopping.early_stop:
break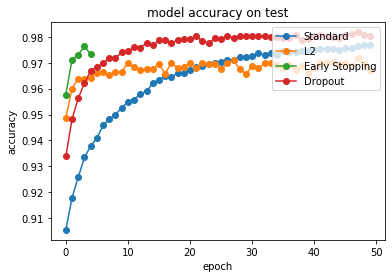


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









