







1. 概述
Kmalloc相关代码主要在slab中,作用很简单,看函数注释:
* kmalloc - allocate kernel memory
* @size: how many bytes of memory are required.
* @flags: describe the allocation context
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
用于在kernel中为object申请小于一页的内存。object就是经常会用到的一些结构体,如task_struct。提前将内存分割成不同大小的块,用于一些常用的内存请求,尽可能避免了外部内存碎片,要知道从伙伴系统申请内存至少都要一页,就是4kb,这对于一些可能只需要几字节的需求来说太大了!具体可以去看下slab和伙伴系统的原理,这里不做详述。
2. 代码详解
#define kmalloc(...) alloc_hooks(kmalloc_noprof(__VA_ARGS__))
主要实现在kmalloc_noprof中,alloc_hook是hook了这个函数,在执行完kmalloc_noprof后会做一些后续操作
static __always_inline __alloc_size(1) void *kmalloc_noprof(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size) && size) {
unsigned int index;
if (size > KMALLOC_MAX_CACHE_SIZE)
return __kmalloc_large_noprof(size, flags);
index = kmalloc_index(size);
return __kmalloc_cache_noprof(
kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index],
flags, size);
}
return __kmalloc_noprof(size, flags);
}
__builtin_constant_p(size)是判断size是否是编译时常量,是的话可以减少一些判断,来优化性能。不管是否是编译时常量,最终对于大内存(size > 2*page)来说,都会走伙伴系统那一路,最终实现是___kmalloc_large_node,对于小内存的申请,最终会走到slab分配器,实现函数是:slab_alloc_node。前期的调用流程图如下,我用蓝色标记除了size是编译时常量需要执行的函数,红色是非常量需要额外执行的函数,我们看下具体有什么差别。
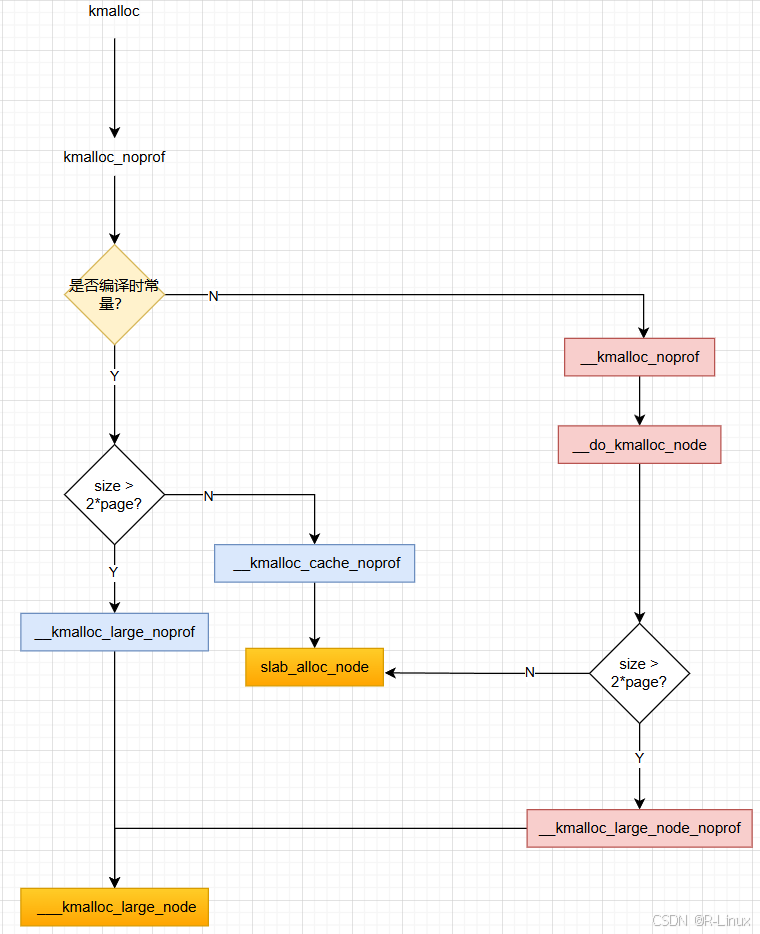
大页申请:__kmalloc_large_noprof
void *__kmalloc_large_noprof(size_t size, gfp_t flags)
{
void *ret = ___kmalloc_large_node(size, flags, NUMA_NO_NODE);
trace_kmalloc(_RET_IP_, ret, size, PAGE_SIZE << get_order(size),
flags, NUMA_NO_NODE);
return ret;
}
可以看到,什么都没做,直接就调用了___kmalloc_large_node
slab申请:__kmalloc_cache_noprof
void *__kmalloc_cache_noprof(struct kmem_cache *s, gfp_t gfpflags, size_t size)
{
void *ret = slab_alloc_node(s, NULL, gfpflags, NUMA_NO_NODE,
_RET_IP_, size);
trace_kmalloc(_RET_IP_, ret, size, s->size, gfpflags, NUMA_NO_NODE);
ret = kasan_kmalloc(s, ret, size, gfpflags);
return ret;
}
也是一样,直接就调用了slab_alloc_node
再来看size非常量的情况,主要是额外调用了__kmalloc_noprof和__do_kmalloc_node,且对于大页还调用了__kmalloc_large_node_noprof,看下这三个函数做了哪些事情
void *__kmalloc_noprof(size_t size, gfp_t flags)
{
return __do_kmalloc_node(size, NULL, flags, NUMA_NO_NODE, _RET_IP_);
}
void *__do_kmalloc_node(size_t size, kmem_buckets *b, gfp_t flags, int node,
unsigned long caller)
{
struct kmem_cache *s;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) {
ret = __kmalloc_large_node_noprof(size, flags, node);
trace_kmalloc(caller, ret, size,
PAGE_SIZE << get_order(size), flags, node);
return ret;
}
if (unlikely(!size))
return ZERO_SIZE_PTR;
s = kmalloc_slab(size, b, flags, caller);
ret = slab_alloc_node(s, NULL, flags, node, caller, size);
ret = kasan_kmalloc(s, ret, size, flags);
trace_kmalloc(caller, ret, size, s->size, flags, node);
return ret;
}
void *__kmalloc_large_node_noprof(size_t size, gfp_t flags, int node)
{
void *ret = ___kmalloc_large_node(size, flags, node);
trace_kmalloc(_RET_IP_, ret, size, PAGE_SIZE << get_order(size),
flags, node);
return ret;
}
对于大页的申请来说没看到太大不同,都是指定size,flag,NUMA_NO_NODE;对于slab来说,由于在编译期间就知道size,所以直接index是已知的,也就能知道使用哪个kmem_cache,通过这里确定kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index]。这里就是简单的查表,编译期间就确定了,不需要运行时再通过size来实时查找,性能会好一些。而对于size不是编译时常量的情况,kmem_cache是通过函数kmalloc_slab来确定的
/*
* Find the kmem_cache structure that serves a given size of
* allocation
*
* This assumes size is larger than zero and not larger than
* KMALLOC_MAX_CACHE_SIZE and the caller must check that.
*/
static inline struct kmem_cache *
kmalloc_slab(size_t size, kmem_buckets *b, gfp_t flags, unsigned long caller)
{
unsigned int index;
if (!b)
b = &kmalloc_caches[kmalloc_type(flags, caller)];
if (size <= 192)
index = kmalloc_size_index[size_index_elem(size)];
else
index = fls(size - 1);
return (*b)[index];
}
由于传入的kmem_buckets是NULL,所以这里通过flags设定bucket。对于size < 192的情况,不直接用2的倍数来计算index(因为这样算太浪费内存了),所以需要一个单独的映射表,如下图,是以8byte为增量。
u8 kmalloc_size_index[24] __ro_after_init = {
3, /* 8 */
4, /* 16 */
5, /* 24 */
5, /* 32 */
6, /* 40 */
6, /* 48 */
6, /* 56 */
6, /* 64 */
1, /* 72 */
1, /* 80 */
1, /* 88 */
1, /* 96 */
7, /* 104 */
7, /* 112 */
7, /* 120 */
7, /* 128 */
2, /* 136 */
2, /* 144 */
2, /* 152 */
2, /* 160 */
2, /* 168 */
2, /* 176 */
2, /* 184 */
2 /* 192 */
};
否则就用fls来计算size对应的index,fls函数用来查找无符号整数最高有效位的索引。__builtin_clz函数是用来统计前置0的数量的。
比如x = 2, 二进制为0000 0000 … 0010, 前面有连续30个0,__builtin_clz计算结果为30,sizeof(x) * 8 - __builtin_clz(x) = 32 - 30 = 2
/**
* fls - find last (most-significant) bit set
* @x: the word to search
*
* This is defined the same way as ffs.
* Note fls(0) = 0, fls(1) = 1, fls(0x80000000) = 32.
*/
static __always_inline int fls(unsigned int x)
{
return x ? sizeof(x) * 8 - __builtin_clz(x) : 0;
}
2.1 大页申请:___kmalloc_large_node
* 为了避免不必要的开销,大内存分配请求直接通过页分配器(page allocator)处理。
* 我们使用 __GFP_COMP 标志,因为在 kfree 时需要知道分配的内存页的阶数(order),
* 以便正确释放内存页。
*/
static void *___kmalloc_large_node(size_t size, gfp_t flags, int node)
{
struct folio *folio; // 用于管理分配的内存页
void *ptr = NULL; // 分配的内存指针
unsigned int order = get_order(size); // 计算所需的内存页阶数
// 检查 flags 是否包含不兼容的标志,并进行修复
if (unlikely(flags & GFP_SLAB_BUG_MASK))
flags = kmalloc_fix_flags(flags);
// 添加 __GFP_COMP 标志,表示分配的内存是复合页(compound page)
flags |= __GFP_COMP;
// 在指定的 NUMA 节点上分配内存页
folio = (struct folio *)alloc_pages_node_noprof(node, flags, order);
if (folio) {
// 获取分配的内存页的起始地址
ptr = folio_address(folio);
// 更新 LRU 统计信息,标记分配的内存页为不可回收的 slab 内存
lruvec_stat_mod_folio(folio, NR_SLAB_UNRECLAIMABLE_B,
PAGE_SIZE << order);
}
// 使用KASAN检查大内存分配
ptr = kasan_kmalloc_large(ptr, size, flags);
// 在 KASAN 之后调用 kmemleak 钩子函数,因为 ptr 可能被标记
kmemleak_alloc(ptr, size, 1, flags);
// 使用 KMSAN(内核内存消毒器)检查大内存分配
kmsan_kmalloc_large(ptr, size, flags);
return ptr; // 返回分配的内存指针
}
/*
* 分配内存页,优先选择给定的节点 nid。当 nid == NUMA_NO_NODE 时,
* 优先选择当前 CPU 的最近节点。否则,节点必须有效且在线。
*/
static inline struct page *alloc_pages_node_noprof(int nid, gfp_t gfp_mask,
unsigned int order)
{
// 如果 nid 是 NUMA_NO_NODE,则选择当前 CPU 的最近节点
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
// 调用__alloc_pages_node_noprof 进行内存页分配
return __alloc_pages_node_noprof(nid, gfp_mask, order);
}
static inline struct page *
__alloc_pages_node_noprof(int nid, gfp_t gfp_mask, unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);
warn_if_node_offline(nid, gfp_mask);
return __alloc_pages_noprof(gfp_mask, order, nid, NULL);
}
__alloc_pages_noprof就是伙伴系统分配器的核心函数了
/*
* @gfp: 分配标志
* @order: 内存页的阶数,表示分配 2^order 个连续的内存页
* @preferred_nid: 优先选择的 NUMA 节点
* @nodemask: 节点掩码,限制内存分配的范围
*
* 该函数是内核中用于分配内存页的核心函数,支持 NUMA 节点和节点掩码的限制。
* 首先尝试从空闲列表中快速分配内存页,如果失败则进入慢速路径。
*/
struct page *__alloc_pages_noprof(gfp_t gfp, unsigned int order,
int preferred_nid, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW; // 允许分配内存到低水位线
gfp_t alloc_gfp; // 实际用于分配的 gfp_t 标志
struct alloc_context ac = { }; // 分配上下文
/*
* 检查 order 是否合法,如果超过 MAX_PAGE_ORDER 则返回 NULL。
*/
if (WARN_ON_ONCE_GFP(order > MAX_PAGE_ORDER, gfp))
return NULL;
// 过滤掉不允许的 gfp 标志
gfp &= gfp_allowed_mask;
/*
* 继承当前上下文的gfp,主要是对于nofs和noio的处理。
* 防止在fs操作发起的内存申请中再调用fs相关操作以引起死锁,io操作同理。
* 此外还有对PF_MEMALLOC_PIN的检查,如果设定了这个,就要保证不会从可移动区域分配,
* 因为有些内存分配请求需要确保是内存位置是固定的,不能被迁移或回收。如DMA缓冲区
*/
gfp = current_gfp_context(gfp);
alloc_gfp = gfp;
/*
* 准备分配上下文,包括可选的cpu、zone、迁移类型等。
* 另外如果该页可能会被写入,还会设置脏页平衡的flag。
*/
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))
return NULL;
/*
* 首次尝试分配,尽量不要导致内存碎片
*/
alloc_flags |= alloc_flags_nofragment(zonelist_zone(ac.preferred_zoneref), gfp);
/* 第一次分配尝试:从空闲列表中获取内存页 */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))
goto out;
/*
* 如果快速路径分配失败,则进入慢速路径,gfp要重新设置了。
*/
alloc_gfp = gfp;
ac.spread_dirty_pages = false;
/*
* 恢复原始的 nodemask
*/
ac.nodemask = nodemask;
// 慢速路径分配
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);
out:
/*
* 如果启用了内存控制组(memcg),并且分配标志包含 __GFP_ACCOUNT,
* 则对分配的内存页进行计费。如果计费失败,则释放内存页并返回 NULL(说明该group中申请的内存已经超量了)。
*/
if (memcg_kmem_online() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);
kmsan_alloc_page(page, order, alloc_gfp);
return page;
}
2.1.1 快速分配
首先会尝试快速分配,因为是首次尝试,所以条件会卡的比较严,要满足内存水位线、避免产生内存碎片、尽量在本CPU上分配等,如果分配失败了,就会放宽这些限制重新尝试。
分配函数是get_page_from_freelist,大致有三个部分,我们分开看:
- 寻找合适的zone;
- 判断内存水位;
- 尝试在zone上分配内存
寻找合适的zone:
retry:
/*
* 设置nofragment,尽量不产生内存碎片
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
/*
*如果设置了cpuset,当前zone又不在cpuset中,直接尝试下一个zone
*/
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* 如果设置了spread_dirty_pages,我们希望脏页比较均衡的分散在各个zone中,
* 所以这里检测如果脏页已经太多了,就直接尝试下一个zone吧
*/
if (ac->spread_dirty_pages) {
if (last_pgdat != zone->zone_pgdat) {
last_pgdat = zone->zone_pgdat;
last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat);
}
if (!last_pgdat_dirty_ok)
continue;
}
/*
*如果当前已经在较远的zone上分配了,那先把nofragment限制取消,重新尝试在最优zone上分配(一般是当前cpu上的),
*因为局部性要比避免碎片化更重要(可以保证热缓存,性能优先!)
*/
if (no_fallback && nr_online_nodes > 1 &&
zone != zonelist_zone(ac->preferred_zoneref)) {
int local_nid;
local_nid = zonelist_node_idx(ac->preferred_zoneref);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
cond_accept_memory(zone, order);
/*
* ZONE_BELOW_HIGH代表空闲页已经低于高水位线,代表该zone中内存较少,跳转到check_alloc_wmark进一步检查处理
* 否则,空闲页高于高水位线,直接尝试在当前zone上分配
*/
if (test_bit(ZONE_BELOW_HIGH, &zone->flags))
goto check_alloc_wmark;
mark = high_wmark_pages(zone);
if (zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask))
goto try_this_zone;
else
set_bit(ZONE_BELOW_HIGH, &zone->flags);
水位线检查:
check_alloc_wmark:
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
int ret;
//有些特殊情况会无视内存水位线,直接尝试申请
if (cond_accept_memory(zone, order))
goto try_this_zone;
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (deferred_pages_enabled()) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
/* 如果有设置ALLOC_NO_WATERMARKS,则直接无视水位线,尝试分配 */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
/*后面涉及到内存回收,所以如果已经设定过不允许reclaim,就直接尝试下一个zone了*/
if (!node_reclaim_enabled() ||
!zone_allows_reclaim(zonelist_zone(ac->preferred_zoneref), zone))
continue;
/*执行内存回收*/
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags))
goto try_this_zone;
continue;
}
}
尝试在选定的zone上分配内存
try_this_zone:
/*最终执行分配动作的函数,优先从per-cpu list中分配,如果失败的话,从buddy system分配
*分配过程中从当前申请的order开始便利,找到可以满足分配请求的最小order
*/
page = rmqueue(zonelist_zone(ac->preferred_zoneref), zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* 如果是highatomic的内存申请,考虑将这部分以及周围的内存预留,
* 以确保后续可以满足highatomic的内存申请
*/
if (unlikely(alloc_flags & ALLOC_HIGHATOMIC))
reserve_highatomic_pageblock(page, order, zone);
return page;
} else {
if (cond_accept_memory(zone, order))
goto try_this_zone;
/* Try again if zone has deferred pages */
if (deferred_pages_enabled()) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
至此就是快速路径的page alloc就完成了,如果没有申请到,就会进到慢速路径:__alloc_pages_slowpath,里面会涉及到内存规整、内存回收等一系列复杂逻辑,这里先不继续展开了。。。
2.2 slab申请:slab_alloc_node
static __fastpath_inline void *slab_alloc_node(struct kmem_cache *s, struct list_lru *lru,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
void *object;
bool init = false; // 是否需要初始化对象
// 初始化 slab 缓存
s = slab_pre_alloc_hook(s, gfpflags);
if (unlikely(!s))
return NULL;
// 尝试从 KFENCE 分配对象(Kfence是一种内核内存错误检测机制)
object = kfence_alloc(s, orig_size, gfpflags);
if (unlikely(object))
goto out;
// slab慢速分配路径
object = __slab_alloc_node(s, gfpflags, node, addr, orig_size);
// 如果需要,清除对象的空闲指针
maybe_wipe_obj_freeptr(s, object);
// 检查是否需要在分配时初始化对象
init = slab_want_init_on_alloc(gfpflags, s);
out:
/*
* 当 init 为 true 时(例如 kzalloc 系列函数),
* 可能只将 @orig_size 字节清零,而不是 s->object_size。
* 如果由于 memcg_slab_post_alloc_hook() 失败,
* 则 object 被设置为 NULL。
*/
slab_post_alloc_hook(s, lru, gfpflags, 1, &object, init, orig_size);
return object;
}
__slab_alloc_node是slab慢速分配路径,主要包含以下逻辑:
- 先从传入的kmem_cache中获取slab
- 如果成功获取到有效slab,则从slab中拿到freelist,并返回。
- 如果没有拿到slab,就要从cpu partition或node partition重新申请一个slab,如果成功申請到就返回(2),如果沒申請到,就要从重新申请一些内存用于slab分配器了(通过调用
alloc_pages或__alloc_pages_node),申请的slab初始化好后返回(2) - 经过第三步还是没有申请到的话,申请失败,返回NULL
2.2.1 __slab_alloc_node
获取slab
从当前kmem_cache中获取slab如果获取到了就跳转到load_freelist拿所需的object;如果没有slab,就要重新申请一个slab(new_slab);如果获取到slab,但是slab与当前node不匹配,或者是slab中没有freelist,就要将其标记为无效slab,后续不会再从这个slab上申请(deactivate_slab)
reread_slab:
// 读取当前 CPU 的 slab 缓存
slab = READ_ONCE(c->slab);
if (!slab) {
/*
* 如果之前有设定优先从指定node中获取,由于该node中已经没有可用slab了,就先取消这个限制
*/
if (unlikely(node != NUMA_NO_NODE &&
!node_isset(node, slab_nodes)))
node = NUMA_NO_NODE;
goto new_slab; // 跳转到 new_slab,分配新的 slab
}
// 到这里说明kmem_cache中有空闲slab,检查 slab 是否与指定的 NUMA 节点匹配
if (unlikely(!node_match(slab, node))) {
/*
* 如果node不匹配,但node约束仍然有效,则跳转到 deactivate_slab,将这个slab标记为无效。
*/
if (!node_isset(node, slab_nodes)) {
node = NUMA_NO_NODE;
} else {
stat(s, ALLOC_NODE_MISMATCH); // 记录节点不匹配的统计信息
goto deactivate_slab; // 跳转到 deactivate_slab,停用当前 slab
}
}
/*
* 检查 slab 是否与分配标志中的 PFMEMALLOC 标志匹配。
* 这个flag是用于内存管理系统在紧急时使用,普通进程不应该携带这个flag,或不应该申请带有该flag的内存
*/
if (unlikely(!pfmemalloc_match(slab, gfpflags)))
goto deactivate_slab; // 跳转到 deactivate_slab,停用当前 slab
/*
* 再检查一下slab是否等于c->slab,因为期间可能被调度出去,c->slab发生改变
*/
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(slab != c->slab)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab; // 如果 slab 已更改,则重新读取 slab
}
// 获取当前 slab 的空闲列表
freelist = c->freelist;
if (freelist)
goto load_freelist; // 如果空闲列表不为空,则跳转到 load_freelist
// 如果空闲列表为空,则从 slab 中获取新的空闲列表
freelist = get_freelist(s, slab);
if (!freelist) {
// 如果无法获取空闲列表,则停用当前 slab
c->slab = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
stat(s, DEACTIVATE_BYPASS); // 记录停用 slab 的统计信息
goto new_slab; // 跳转到 new_slab,分配新的 slab
}
stat(s, ALLOC_REFILL); // 记录重新填充空闲列表的统计信息
从slab中获取freelist
主要是更新当前kmem_cache的freelist和tid,并返回freelist中第一个对象
load_freelist:
// 这里要拿freelist了,必须持锁
lockdep_assert_held(this_cpu_ptr(&s->cpu_slab->lock));
/*
* freelist 指向要使用的对象列表。
* slab 指向从中获取对象的 slab。
* 该 slab 必须被冻结(frozen)
*/
VM_BUG_ON(!c->slab->frozen);
// 更新当前 CPU 的空闲列表
c->freelist = get_freepointer(s, freelist);
// 更新当前 CPU 的tid
c->tid = next_tid(c->tid);
// 释放当前 CPU 的 slab 锁
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
// 返回空闲列表中的第一个对象
return freelist;
deactivate_slab
当前slab中已经没有可用的空闲对象了,或者当前slab与node不匹配时,我们需要停用这个slab
deactivate_slab:
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (slab != c->slab) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab;
}
freelist = c->freelist;
c->slab = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
deactivate_slab(s, slab, freelist);
分配新的 per cpu partition slab
如果设定了CONFIG_SLUB_CPU_PARTIAL,就可以支持分配per-cpu的半空slab
#ifdef CONFIG_SLUB_CPU_PARTIAL
while (slub_percpu_partial(c)) {
local_lock_irqsave(&s->cpu_slab->lock, flags);
if (unlikely(c->slab)) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
goto reread_slab;
}
if (unlikely(!slub_percpu_partial(c))) {
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
/* we were preempted and partial list got empty */
goto new_objects;
}
slab = slub_percpu_partial(c);
slub_set_percpu_partial(c, slab);
if (likely(node_match(slab, node) &&
pfmemalloc_match(slab, gfpflags))) {
c->slab = slab;
freelist = get_freelist(s, slab);
VM_BUG_ON(!freelist);
stat(s, CPU_PARTIAL_ALLOC);
goto load_freelist;
}
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
slab->next = NULL;
__put_partials(s, slab);
}
#endif
分配新的object
如果不支持CONFIG_SLUB_CPU_PARTIAL,就从全局的node kmem_cache中申请新的 partition slab。如果申请到了,重新尝试load slab,如果没有的话,就需要从页分配器申请内存,初始化一个新的slab,返回新初始化好的freelist;如果从页分配器申请内存也失败了,就说明没有合适的内存可用了,直接return NULL,申请失败
new_objects:
pc.flags = gfpflags;
/*
* When a preferred node is indicated but no __GFP_THISNODE
*
* 1) try to get a partial slab from target node only by having
* __GFP_THISNODE in pc.flags for get_partial()
* 2) if 1) failed, try to allocate a new slab from target node with
* GPF_NOWAIT | __GFP_THISNODE opportunistically
* 3) if 2) failed, retry with original gfpflags which will allow
* get_partial() try partial lists of other nodes before potentially
* allocating new page from other nodes
*/
if (unlikely(node != NUMA_NO_NODE && !(gfpflags & __GFP_THISNODE)
&& try_thisnode))
pc.flags = GFP_NOWAIT | __GFP_THISNODE;
pc.orig_size = orig_size;
slab = get_partial(s, node, &pc);
if (slab) {
if (kmem_cache_debug(s)) {
freelist = pc.object;
/*
* For debug caches here we had to go through
* alloc_single_from_partial() so just store the
* tracking info and return the object.
*/
if (s->flags & SLAB_STORE_USER)
set_track(s, freelist, TRACK_ALLOC, addr);
return freelist;
}
freelist = freeze_slab(s, slab);
goto retry_load_slab;
}
slub_put_cpu_ptr(s->cpu_slab);
slab = new_slab(s, pc.flags, node);
c = slub_get_cpu_ptr(s->cpu_slab);
if (unlikely(!slab)) {
if (node != NUMA_NO_NODE && !(gfpflags & __GFP_THISNODE)
&& try_thisnode) {
try_thisnode = false;
goto new_objects;
}
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
stat(s, ALLOC_SLAB);
if (kmem_cache_debug(s)) {
freelist = alloc_single_from_new_slab(s, slab, orig_size);
if (unlikely(!freelist))
goto new_objects;
if (s->flags & SLAB_STORE_USER)
set_track(s, freelist, TRACK_ALLOC, addr);
return freelist;
}
/*
* No other reference to the slab yet so we can
* muck around with it freely without cmpxchg
*/
freelist = slab->freelist;
slab->freelist = NULL;
slab->inuse = slab->objects;
slab->frozen = 1;
inc_slabs_node(s, slab_nid(slab), slab->objects);
if (unlikely(!pfmemalloc_match(slab, gfpflags))) {
/*
* For !pfmemalloc_match() case we don't load freelist so that
* we don't make further mismatched allocations easier.
*/
deactivate_slab(s, slab, get_freepointer(s, freelist));
return freelist;
}
重新加载slab
经过前面一系列努力,终于申请到了新的slab,如果发现旧的slab不为空,就需要刷新一下,停用旧的slab,将其更新为新申请到的slab,然后重新尝试load_freelist
retry_load_slab:
// 获取当前 CPU 的 slab 锁,并保存中断状态
local_lock_irqsave(&s->cpu_slab->lock, flags);
// 如果当前 CPU 的 slab 缓存不为空,则需要刷新旧的 slab 缓存
if (unlikely(c->slab)) {
void *flush_freelist = c->freelist; // 保存当前 CPU 的空闲列表
struct slab *flush_slab = c->slab; // 保存当前 CPU 的 slab
// 清空当前 CPU 的 slab 缓存
c->slab = NULL;
c->freelist = NULL;
c->tid = next_tid(c->tid);
// 释放当前 CPU 的 slab 锁
local_unlock_irqrestore(&s->cpu_slab->lock, flags);
// 停用旧的 slab 缓存
deactivate_slab(s, flush_slab, flush_freelist);
stat(s, CPUSLAB_FLUSH);
// 重新尝试加载 slab
goto retry_load_slab;
}
// 将新的 slab 设置为当前 CPU 的 slab 缓存
c->slab = slab;
// 跳转到 load_freelist,加载空闲列表
goto load_freelist;
3. 总结
kmalloc是一个总的kernel内存申请的调用接口,根据申请内存的大小来判断是从伙伴系统申请还是从slab分配器申请。
大于2page的内存申请会走伙伴系统那一路,最终调用__alloc_pages_noprof,再合适的zone上分配符合gfp flag的内存,如果首次分配没有成功,就会进入到慢速路径,涉及到内存规整和内存回收。
小于2page的内存申请会走slab分配器,先直接从当前cpu的partition list中申请,如果没有的话就从全局的slab list中申请,还没有的话就要从页分配器申请一些内存,在初始化为新的slab供slab分配器使用

















 6055
6055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









