






1.Understanding encryption(了解加密)
密码学是信息安全专业人员可以使用的最重要的控制措施之一,加密可以保护敏感信息在许多不同的环境中免遭未经授权的披露,而许多其他安全功能依赖于加密技术才能正常工作。密码学是使用数学算法将信息转换为未经授权的个人无法读取的形式,但未经授权的个人有能力将其转换回可读的形式。
密码学依赖于两个基本操作:
Encryption(加密):将信息从其纯文本形式转换为不可读的加密版本,称为密文
Decryption(解密):使用算法执行反向转换,将加密信息转换回纯文本形式
算法:算法只是为获得结果而遵循的一组数学指令,将算法视为数学公式,算法与计算机代码非常相似,实际上,计算机代码往往是为了实现数学算法而设计的,下面是一种基本算法:
该算法皆在将温度从华氏度转换为摄氏度,该算法有一个输入,即以华氏度为单位的温度,然后通过一系列步骤获取此输入,首先,它从该输入中减去32,然后,将结果乘以5,之后将该结果除以9,这提供了最终结果,即我们的输出,即以华氏度为单位输入的温度的摄氏度等效值。加密算法的工作方式相似,只是步骤不同。加密算法有两个输入:
P,the plaintext message(纯文本消息)
K,the encryption key(加密密钥)
然后他们执行一系列步骤,使用加密密钥转换纯文本消息,然后,加密算法有一个输出,即加密的密文消息:
C,the encrypted ciphertext
解密算法执行相反的操作,它们还有两个输入,即加密消息(也称为密文)和解密密钥:
C,the ciphertext(加密消息,也称为密文)
K,the decryption key(解密密钥)
然后,该算法执行一系列步骤,使用解密密钥将密文转换回纯文本,然后返回纯文本消息作为输出
以上这些是密码学的基本概念
2.Symmetric and asymmetric cryptography(对称和非对称加密)
加密算法的两个主要类别是对称算法和非对称算法:
Symmetric Encryption(对称加密算法,也称为共享密钥加密算法):加密和解密操作使用相同的密钥,如果一个用户使用密钥apple加密消息,则另一个用户将不得不使用相同的密钥解密消息
Asymmetric Encryption(非对称加密算法):使用不同的密钥进行加密和解密,这些算法也称为公钥加密,它们使用密钥对的概念
下图将更加深入的了解对称加密
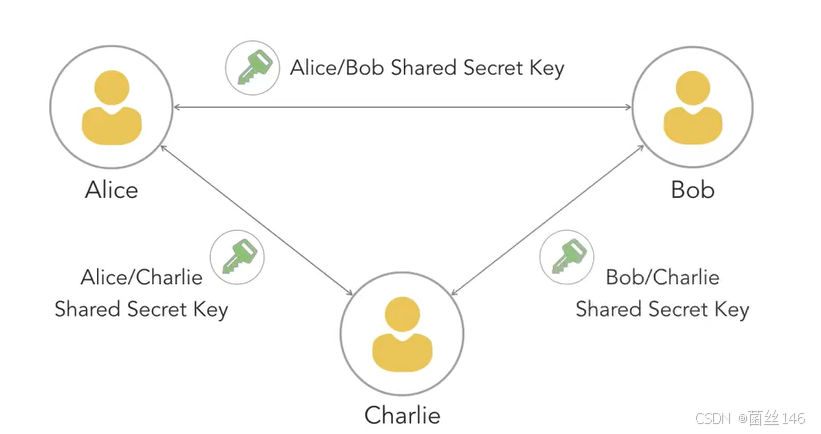
图注:可以将共享密钥视为消息的密码,如果A和B希望彼此交流,他们都知道相同的共享密钥,则可以使用该密钥相互交换加密消息,当只有两个人参与交流时,这非常有效,他们可以简单地就加密密钥达成一致,然后相互使用。如果有三个人参与其中,就需要稍微改变一下,A和B仍然可以使用他们共享的密钥私下相互交流,但是现在C也希望能够加入与A或B交流,小组中的每个人都希望能够与小组中的任何其他成员进行私下交流。A已经有了与B交流的方法,但接下来需要添加第二个密钥,让A可以与C私下交流,同时,B和C需要第三把密钥相互通信,为了能让三个人沟通,就需要三把密钥,随着团队的规模越来越大,就需要越来越多的密钥来促进他们的交流,以下图为例
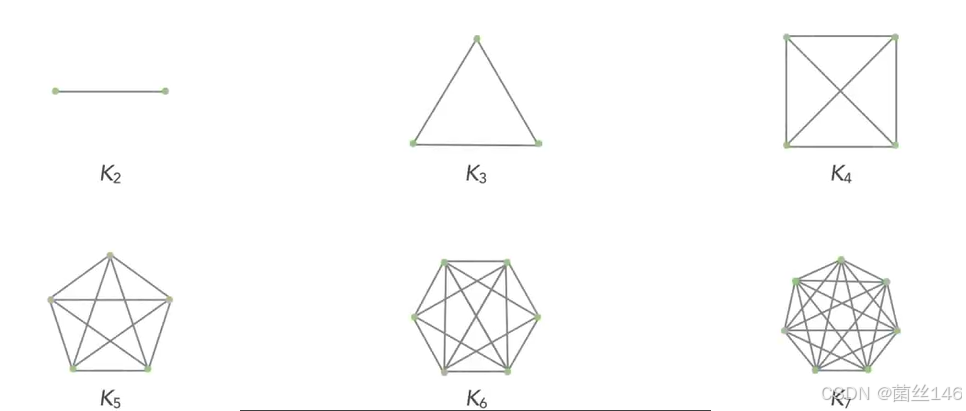
下图公式可以计算对称加密所需的密钥数量
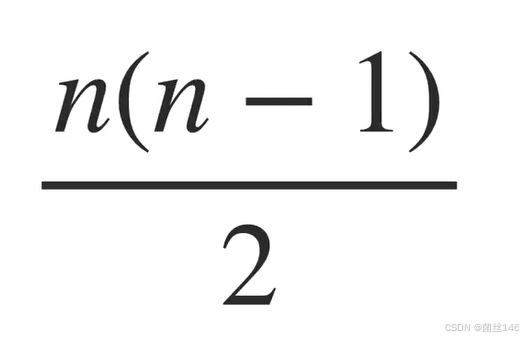
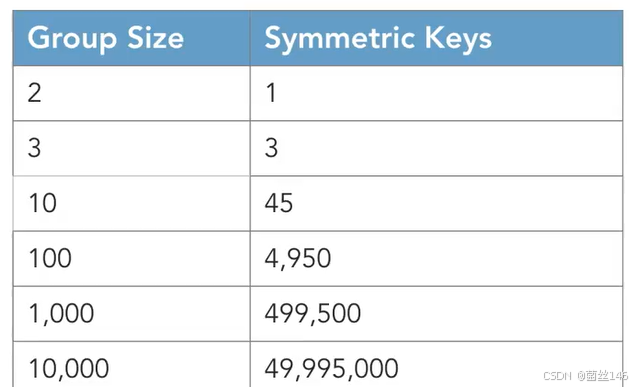
图注:其中n是想要交流的人数,将n乘以n减1,然后将结果除以2,当我们进行数学计算并发展到更大的组时,对称密码学开始需要数量难以管理的密钥
非对称密码学通过使用密钥对的概念解决了这个问题,每个用户都会得到两个密钥,一个是他们可以自由分发给他们希望与之通信的任何人的公钥,另一个是他们保密的私钥,在非对称加密中,使用一对中的一个密钥加密的任何内容都可以使用同一对中的另一个密钥进行解密。对于正常的通信,消息的发送者将使用接收者的公钥对其进行加密,该公钥是公开的,然后,接收者将使用他们的私钥来解密消息
请记住,在非对称加密中,密钥必须来自同一对
非对称加密比对称加密慢,但它解决了为大型组织创建密钥的问题,只需要每个用户两个密钥
3.Goals of cryptography(密码学的目标)
Confidentiality(机密性):密码学最常见的目标是保持机密性,机密性确保未经授权的个人无法访问敏感信息,当我们使用密码学来保护信息的机密性时,我们会考虑三种不同的数据状态,在这些状态下,数据可能会暴露在窥探之下
Date at Rest(静态数据):静态数据是存储在硬盘驱动器或其他存储设备上的数据,我们可以使用加密来保护存储的数据,以便即使设备丢失或被盗,它也会受到保护

Data in Transit(传输中的数据):传输中的数据是通过网络在两个系统之间发送的,我们使用加密来保护传输中的数据,以便即使有人窃听网络通信,它也能受到保护

Data in Use(内存中的数据):使用中的数据位于内存中,应用程序正在积极使用内存中的数据,我们可以使用加密来保护这些数据,防止其他进程或个人访问

Integrity(完整性):密码学的第二个目标是完整性,完整性可防止未经授权修改的消息
Authentication(身份验证):密码学的第三个目标是身份验证,许多验证用户身份的系统都有依赖于加密的使用
Obfuscation(混淆):密码学的第四个目标是混淆,有时我们想让任何人(包括我们自己)都无法理解数据,使数据难以理解的行为是混淆
Non-Repudiation(不可否认):密码学的最终目标是不可否认性,不可否认性意味着消息的接收者可以向独立的第三方证明该消息确实来自被指控的发送者,用于实现不可否性的技术称为数字签名,不可否认性仅适用于非对称加密算法
请记住,在对称密码学中,发送方和接收方都知道并使用相同的密钥
当我们使用密码学时,还必须记住,加密操作在数学上很复杂,需要计算时间来处理,这使我们在资源限制和我们实现的安全级别之间做出权衡,一般来说,我们的加密算法越强大,我们需要加密和解密数据的处理能力就越大
4.Choosing encryption algorithms(选择加密算法)
加密非常复杂,它使用复杂的数学技术,即使是算法中最小的缺陷也会使该算法不安全,出于这个原因,除非你真的、真的知道你在做什么,否则你永远不应该尝试构建自己的加密算法,你不会试图对自己进行心脏手术,也不要尝试构建自己的加密算法,同样,如果供应商声称他们的软件使用专有加密算法进行保护,并且他们不会分享详细信息,请以应有的怀疑态度看待该声明,这是一个很大的危险信号
事实上,拥有秘密加密算法的想法与网络安全专业人员所持有的原则背道而驰,以至于我们创造了一个术语来描述这种方法,我们称之为“通过隐蔽性实现安全性”,这意味着算法的安全性来自于这样一个事实,即没有人知道它是如何工作的,通过隐蔽性实现安全性是一个诽谤性的术语,而不是您希望听到用来描述您自己的安全方法的东西,出于同样的原因,应该选择经过验证的加密算法,加密算法的详细信息通常会被发布并开放供安全社区检查,这种公开审查过程很重要,因为它允许数学家和密码学家审查算法的细节,并确保它设计良好,没有可能允许无意访问信息的后门
当选择加密算法时,可以选择加密密钥的长度,并非所有算法都允许这样做,因此有些算法具有固定长度的密钥,但是如果能够选择密钥长度,则密钥越长,信息就越安全,但是随着密钥的长度越长,算法的性能就会下降,选择长度越长的密钥就是在以安全性换取速度,并做出一个经典的决策,该决策必须在安全约束与可用资源之间取得平衡,选择一把长的密钥很重要,因为它会使别人更难猜出你用过的密钥,当选择加密方法时,需要执行自己的成本效益分析,并选择一个密钥长度,以平衡安全目标与加密和解密的速度
5.The cryptographic lifecycle(加密生命周期)
加密算法和用于保护受加密算法保护的信息的密钥是任何安全程序中最重要的组成部分之一,网络安全专业人员必须对加密生命周期有深刻的理解,以便随着组织的安全需求和威胁环境的变化,更好地选择、维护和停用算法的使用。随着加密算法的老化,它们通常会变得不安全,要么是因为研究人员发现了其实现中的缺陷,要么是因为他们使用的关键环节容易受到暴力攻击;因此,必须采用一种生命周期加密方法,在算法变得不安全时逐步淘汰算法。
下图提供一个五阶段的加密生命周期,组织应该将该生命周期应用于其他企业中的任何加密使用
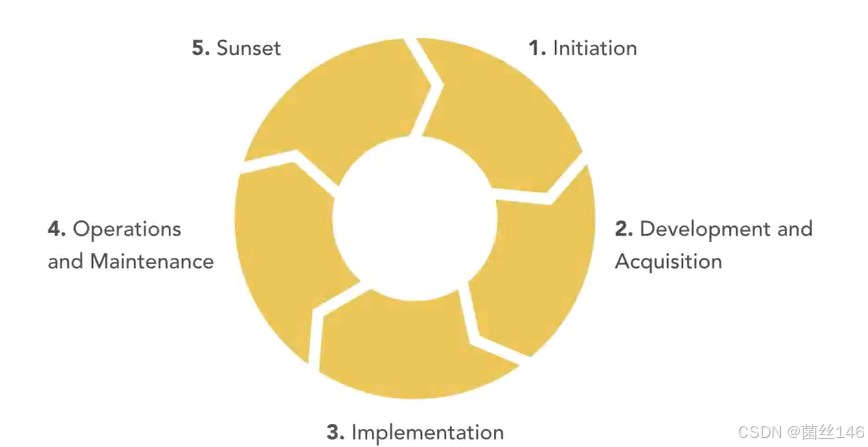
第一阶段是启动,在此阶段,组织意识到它需要一个新的加密系统,并收集了该系统的要求,这应包括组织的特定机密性、完整性和可用性目标,这些目标基于将要保护的信息的敏感性
在第二阶段,组织开发或更有可能获得加密系统,组织找到满足其目标的软件、硬件和算法的适当组合
从第二阶段进入第三阶段,即实施和评估,在该阶段,他们配置自己的系统以供使用,并评估它是否正确满足组织的安全目标
一旦加密系统投入使用,它就会进入生命周期、操作和维护的第四阶段,在该阶段,该组织确保加密系统的持续安全运行
最后,当系统不再可行以继续长期使用时,组织将过渡到第五阶段,即日落,在此阶段,组织将停止使用该系统,并销毁或存档敏感材料,例如它与系统一起使用的密钥
6.Data de-identification(数据去识别化)
Deidentification(去标识化):在数据集中移动并删除可能单独识别的数据过程,然而,简单的数据去标识化往往不足以完全保护信息,需要更加小心地保护数据,而不是简单地删除明显的标识符,不仅需要对数据进行去标识化,还需要对我们的数据进行匿名化处理,使得某个人几乎不可能弄清楚一个人的身份
HIPAA标准包括一个严格的匿名数据流程,该流程在分析社区中被广泛接受,它提供了两种清除数据集的途径
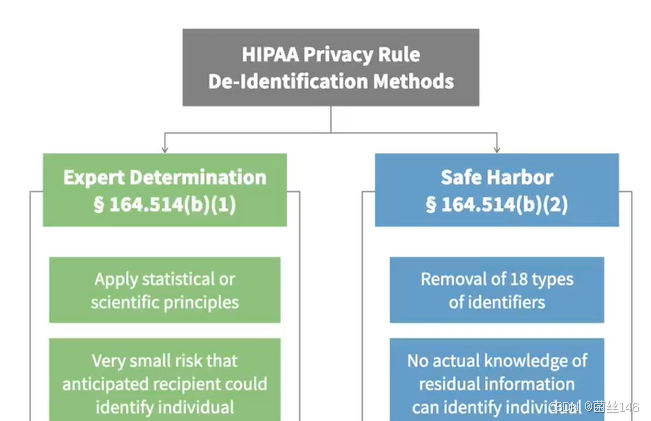
首先,可以让统计学家分析数据集,并验证它不太可能披露个人的身份,这一途径需要获得专业统计学家的帮助,并且确实包括意外披露的可能性,或者,可以选择使用安全港方法,该方法需要从数据集中删除18个数据元素,这些元素可能会相互结合以揭示个人的身份,可以参考美国卫生与公众服务部网站上仔细阅读https://www.hhs.gov/hipaa/for-professionals/privacy/index.html
无论选择哪种方法进行数据去标识化和匿名化,确保已经仔细考虑这个问题,并且正在采取适当的措施来保护数据主体的隐私
标注:博主个人觉得在如今大数据信息被滥用的时代下,HIPAA标准真的很值得参考借鉴,以作为保护我们个人隐私的一种方法
7.Data obfuscation(数据混淆)
从数据集中删除数据的另一种方法是将其转换为无法检索原始信息的格式,这是一个称为数据混淆的过程,我们可以使用多种工具来协助此过程,如下:
Hashing(哈希值):使用哈希函数将数据集中的值转换为哈希值,这些是单向函数,如果对数据元素应用强哈希函数,可以用哈希值替换文件中的值,不可能直接从哈希值中检索原始值,利用哈希值的方法有一个主要缺陷,如果有人有一个字段的可能值列表,他们就可以进行彩虹表攻击,在这种攻击中,攻击者计算这些候选值的哈希值,然后检查数据文件中是否存在这些哈希值
Salting(加盐):加盐是一种技术,它通过在哈希之前将文本与随机选择的值相结合来提高哈希的安全性,使用随机值加盐使得哈希的预计算变得不可能,并组织了彩虹表的使用
Tokenization(标记化):在标记化中,敏感值使用查找表替换为唯一标识符
Masking(屏蔽):在许多情况下,我们根本不需要重新识别数据,可以使用一种称为屏蔽的方法编辑文件中的信息,这将用空白值替换敏感信息

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









