







逆向的第一步就是反编译。首先了解一下逆向工具 apktool ,按文档介绍运行最简单的命令 “apktool d 探探.apk -o tantan” 后,终端报错 Not a valid dex magic value: cf 77 4c c7 9b 21 01 cd 。字面意思不难看出是dex 的魔数值不正确。说到魔数我最先想到的是 jvm class 的4位魔数0xCAFEBABE ( cafe babe ? ) , 而dex的魔数是由8位组成 ,魔数的前3位分别为 64 65 78转换字符串为dex 第4位为0A 转换字符串为\n,后续三位为版本号 最后一位为0 。查看log后发现是解析到assets/A3AEECD8.dex 后报错,经查询后得知此dex为腾讯X5内核的webview所用, 由于此dex加密后更改了魔数,所以apktool 不能识别。我们想要绕过这个crash需要在命令后拼接 --only-main-classes,大意为仅反编译根目录下的dex,忽略其他文件夹。
为了更方便的回编译(后续会提到),我们还需要忽略资源文件也就是 resources.arsc。原因是无论正编译或是反编译,资源的整合都是由Android提供的扩展工具aapt/aapt2 完成。因为逆向环境和正向开发环境不一致,resources.arsc 解码后会造成部分文件丢失,回编译时aapt/aapt2打包生成的压缩文件与索引不对应导致回编译失败,所以需要在命令后拼接 -r至此 一个完整的反编译命令为 “apktool d 探探.apk -o tantan --only-main-classes -r”
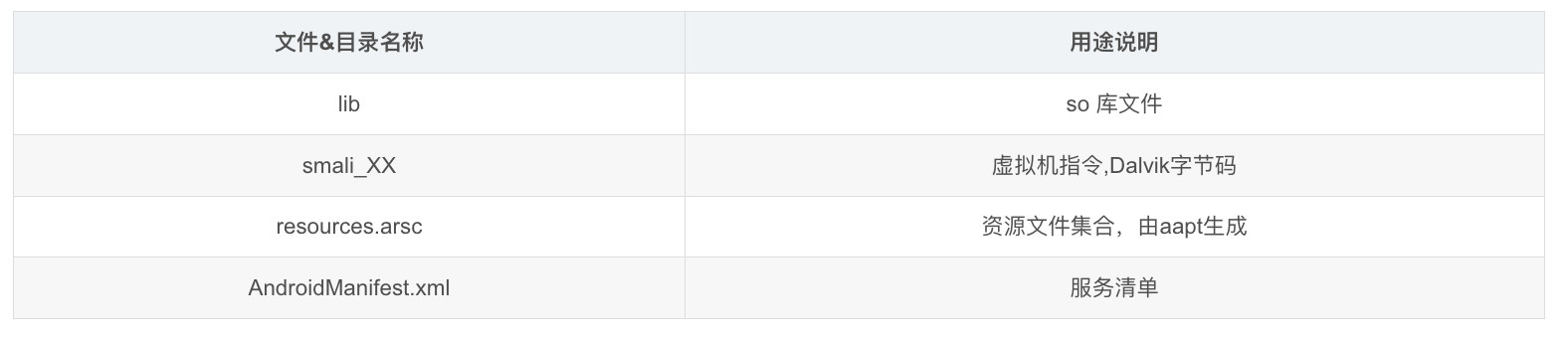
上图是对解码后的探探工程主目录做的简要说明,我们单独分析 AndroidManifest.xml 后可知道探探的包名为 com.p1.mobile.putong ,所以我们需要重点关注此包下的文件夹或文件因为我们阅读的是dalvik字节码,所以需要对其指令集有所了解。 探探的工程“源码”全部都存放于smali_XX 文件中,下面我们以程序入口作为案例梳理一下应用初始化流程。首先打开AndroidManifest.xml 后找到application标签确定源码路径,源码存放于./tantan/smali_classes2/com/p1/mobile/putong/app/TantanApp.smali。
主要分析 application 中onCreate 和 attachBaseContext 两个方法。 代码如下:
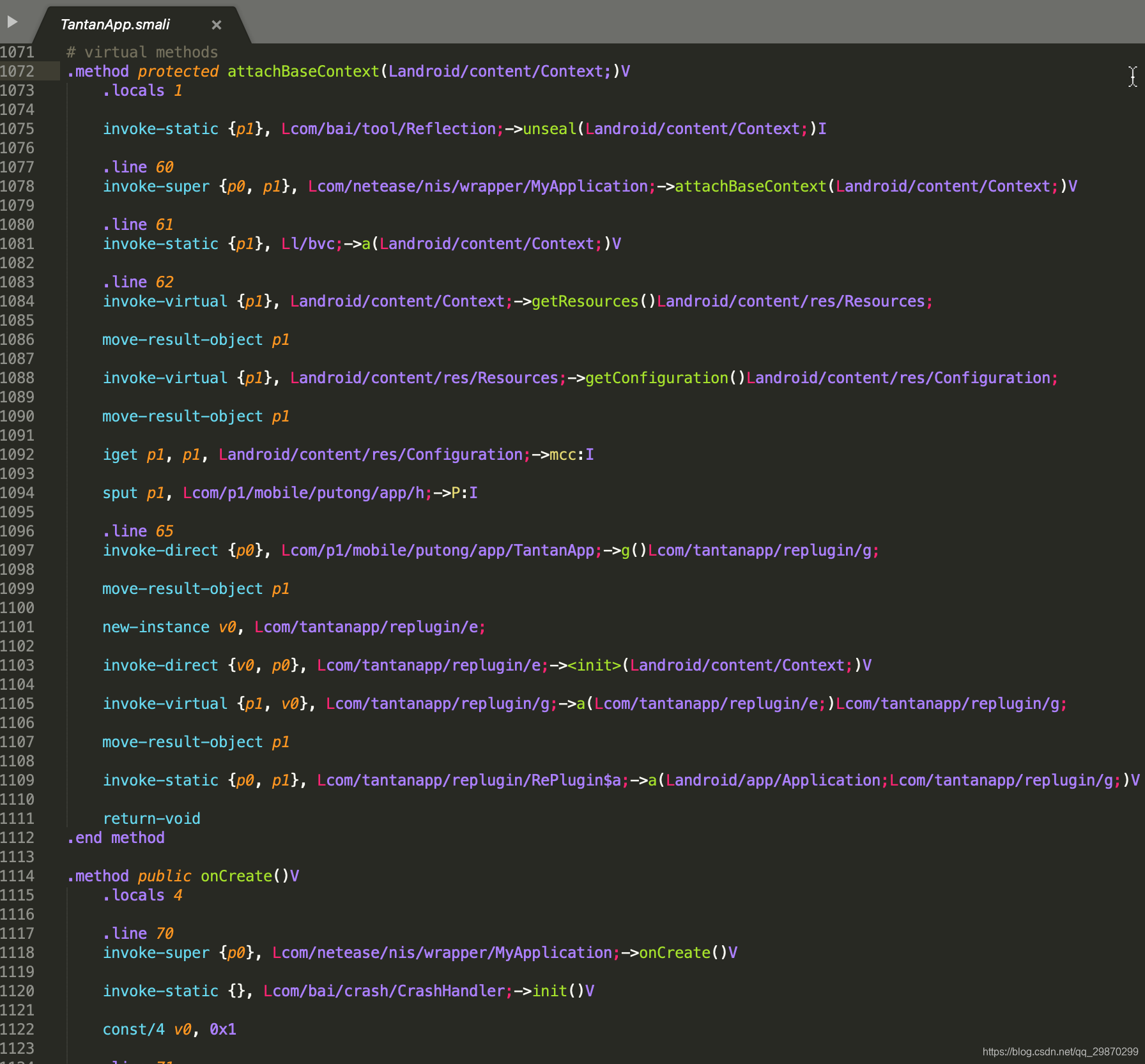
第一眼看完后后除了知道这个类名是TantanApp之外,好像无法再获得更多信息。所以分析代码这个步骤完全是考验耐力,不过不要退缩,我们只要遵循一些技巧,就可以大幅减少工作量。由于分析过程比较繁琐,这里就不结合具体代码了,只做一些理论总结: 从目标 API 开始入手,跟踪执行流程、只分析涉及代码块,缩小分析范围、尝试搜索一些关键词或者log 日志 。
切记不要在茫茫代码中迷失自我
入口方法初始化流程如下:
验证逆向思路的可行性
在逆向分析的过程中,我们需要注入自定义的代码,用于辅助定位源码或获取上下文的变量值,方便我们调试应用。首先看下对探探Apk注入方法后的效果:
如图所示,注入分为两部分
在打开启动页时 ,添加了一个广告页。在登录时,对登录方法进行拦截
新增广告页
启动页的源代码码路径为 ./tantan/smali_classes2/com/p1/mobile/putong/account/ui/welcome/WelcomeAct.smali,在 onCreate 生命周期内,跳转一个广告Activity即可。但由于广告Activity没有在 AndroidManifest.xml 中注册,我们选择通过Hook ActivityManagerService、PackageManagerService 等绕过系统检测,此处不对 Hook 的内容与原理做延伸。
登录方法拦截
登录页的源代码路径为 ./tantan/smali_classes2/com/p1/mobile/putong/account/ui/accountnew/loginopt/act/PhoneNumberLoginOptAct.smali。此页面通过分析可以得出是典型的mvp 模式,此Activity 只做数据传递的桥梁,view 是由 l/byb 维护 ,presenter 是由 l/bxt 维护。点击事件在 byb 类下的 protected e()V 中注册,点击登录按钮后事件流转到 byb 类下的 public o()V,在此处我们弹出对应的拦截框即可。并且在此处也可以拿到登录传递的参数,可做进一步的其他分析
登录拦截代码
以登录方法为例,插入代码如下: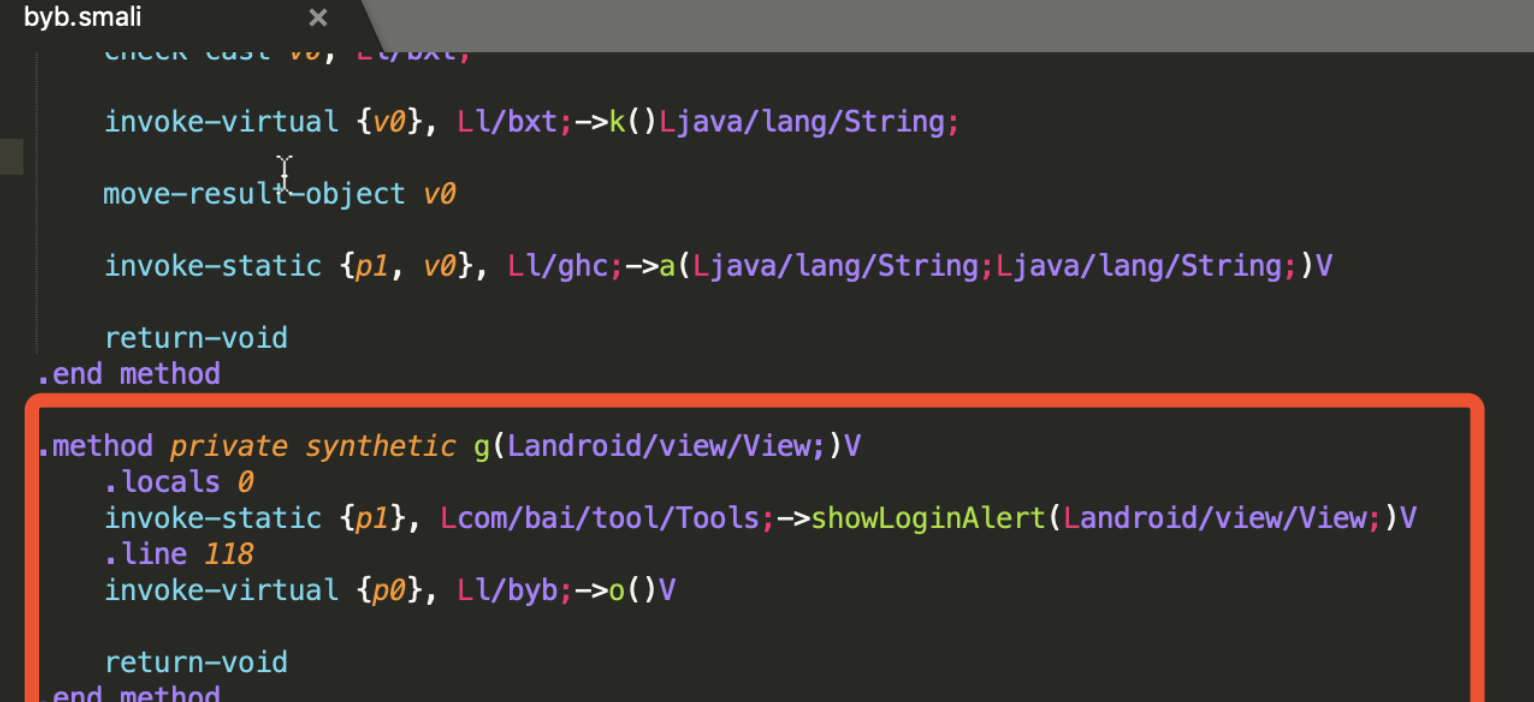
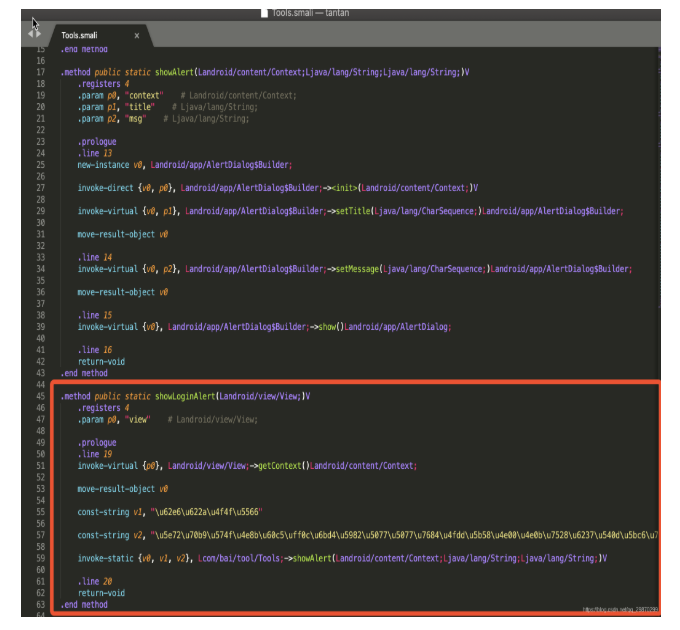
回编译
方法插入完成后,下一步就是二次打包也就是回编译。运行命令 “apktool b tantan” 生成新的apk ,因为此时的apk 没有签名无法安装使用,所以在这里我们采用jdk 工具 jarsigner 对新apk 进行签名。在回编译的过程中我们需要注意dex方法数超过65535的问题,在插入代码时我们要尽可能的将新代码分布到多个smali_XX文件夹内以确保单个dex方法数不超过系统限制。重新签名后,新的签名与原探探签名会不一致,这样会导致某些第三方服务异常 例如百度地图、微信登录支付等。解决此问题可以尝试修改sdk 内获取应用签名方法,强制返回探探应用原签名。但有些服务把获取签名方法放到了native 侧,所以需要一些arm 汇编知识修改so,具体方法在此处就不做延伸。
安全漏洞
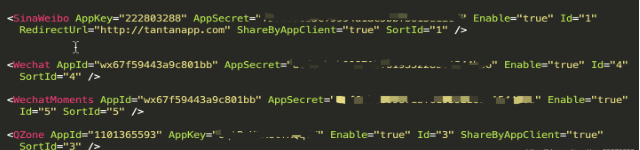
由于探探的微信或其他第三方平台的key 和 秘钥是明文写到客户端内,所以我们可以自由使用。如果我是一个破坏者我会新建一个工程 ,包名与探探包名保持一致,并且对微信校验签名方法hook ,强制返回探探的应用签名即可使用探探的身份进行微信授权登录等。极端点还可以使用探探的身份做一些违反微信社区要求的操作,这样会导致探探的线上设备全部被微信封禁。
在Dubbo里头,对多个协议进行了支持。如:DubboProtocol、GRpcProtocol、RmiProtocol、HessianProtocol、HttpProtocol、WebService、ThriftProtocol等多种协议。本文主要探探Dubbo协议的庐山真面目。
Dubbo协议报文
如图所示:
整个协议的设计参考了TCP/IP协议,协议的报文大小为16字节,内容包含了魔法数、报文的类型(request|response),全局请求ID等等。
前两个字节(0~15位):分别表示魔法数高低位。
如果有使用过IO网络开发的朋友,一般接触到一个比较经典的问题,那就是粘包/解包又叫拆包的问题。最常见的解决方案是通过添加一些特殊符号来表示内容是否读取完整性,如用回车、换行、固定长度和特殊分隔符等进行处理。而Dubbo就是用特殊符号exdabb魔法数来分割处理粘包问题的。
第三个字节(16~23位):
16号位:是否为双向的RPC调用(比如方法调用有返回值),0为Response(响应类型), 1为 Request(请求请类型)
17号位:表示该请求需要往返(其实就是请求-响应的过程)。仅在第16位被设为1的情况下有效, 0为单向调用,1为双向调用。(这里我的理解是,客户端发送一个需要返回响应数据请求后,服务端此时需要进行响应,于是将16号位标记位1,同时,服务端该响应需要客户端也进行一次响应,此时就会将17号位设置为1)
18号位:表示事件类型,0为当前数据包是请求或响应包,1为当前数据包是心跳包,用于保持TCP连接
19~23号位:序列化id号,表示采用哪种方式进行序列化。它的编号和对应的序列化方式如下:
– 2: 为 Hessian2Serialization
– 3: 为 JavaSerialization
– 4: 为 CompactedJavaSerialization
– 6: 为 FastJsonSerialization
– 7: 为 NativeJavaSerialization
– 8: 为 KryoSerialization
– 9: 为 FstSerialization,FST 是一个 Java 快速对象序列化开发包
第四个字节(24~31位):表示响应状态。如20表示响应正常,30为客户端超时,31为服务端超时…
第5~12个共8个字节(32 ~ 95位):存储RPC请求的唯一 id,用来将请求和响应做关联。
第13~16个共4个字节存(96 ~ 127位)存储一些需要进行检验的内容:
Dubbo版本号、服务接口名、服务接口版本、方法名、参数类型、方法参数值和请求额外参
关于全局请求id
根据上述报文,第5~12个共8个字节(32 ~ 95位)表示RPC请求的唯一 id,那它如何用来将请求和响应做关联?
首先,要理解为何需要这个东西。我们知道Dubbo在处理请求的时是利用线程池来做处理的,而对于客户端而言,如果是并发的调用服务,由于Duboo采用了自定义的Dubbo协议,那就需要自己处理好 请求-响应 的对应关系。所以需要这个RPC请求的唯一 id。
客户端并发请求,dubbo内部使用DefaultFuture(继承了CompletableFuture) 对象的get方法进行等待。
在请求发起时,内部会创建Request对象,这个时候会被分配一个唯一 id, DefaultFuture可以从Request对象中获取id,并将关联关系存储到静态HashMap中。
当客户端收到响应时,会根据Response对象中的id,从Futures集合中查找对应 DefaultFuture对象,并唤醒对应的线程并通知结果。
客户端也会启动一个定时扫描线程去 探测超时没有返回的请求。
流程
编码
Dubbo中所有编解码层实现都应该继承自Exchangecodec,当Dubbo协议编码请求对象时,会调用ExchangeCodec#encode 方法。根据消息类型的不同实例,执行对应的方法。
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
if (msg instanceof Request) {
encodeRequest(channel, buffer, (Request) msg);
} else if (msg instanceof Response) {
encodeResponse(channel, buffer, (Response) msg);
} else {
super.encode(channel, buffer, msg);
}
}
以encodeRequest*方法为例子:
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
// 获取指定或默认的序列化协议(Hessian2)
Serialization serialization = getSerialization(channel, req);
// header. 构造16字节的头部
byte[] header = new byte[HEADER_LENGTH];
// set magic number. 占用两个字节存储魔法数
Bytes.short2bytes(MAGIC, header);
// 分别存储请求标志和序列化协议序号 第3个字节(16位和19〜23位,序列化id号最大为9即1001, 单目前有5个位置
// 可用来表示序列化,多出来的一个位,个人认为是预留而用的) 10000000 | 1001
// set request and serialization flag.
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
// 设置请求/响应标记
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
// 设置事件
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// 设置全局请求id
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// 编码请求体数据, 获取写入的索引
// encode request data.
int savedWriteIndex = buffer.writerIndex();
// 跳过buffer头部16个字节, 用于序列化消息化
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
// 判断请求事件是否为心跳事件
if (req.isHeartbeat()) {
// heartbeat request data is always null
bos.write(CodecSupport.getNullBytesOf(serialization));
} else {
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
// 如果不为事件类型, 执行序列化
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
// 检查编码后的报文是否超过大小限制,默认是8M
checkPayload(channel, len);
// 消息长度写入头部, 第12个字节的偏移量(96〜127位)
Bytes.int2bytes(len, header, 12);
// write, 定位指针到报文头部开始位置|
buffer.writerIndex(savedWriteIndex);
// 写入头不
buffer.writeBytes(header); // write header.
// 定位指针到消息结束的位置
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
不同序列化方式通过重写encodeRequestData方法进行事先,以DubboCode为例:
其中,从 RpcInvocation inv = (RpcInvocation) data,可以推测出进入这个方法的data类型是RpcInvocation类型的,要么是其本身实例,要么是其孙子类型的实例。再联想之前写dubbo消费端和服务端的交互流程就不难理解了,因为每次请求都被封装成一个invoker实例。
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
// 这里是强制转换为RpcInvocation类型
RpcInvocation inv = (RpcInvocation) data;
// 写入版本信息
out.writeUTF(version);
// https://github.com/apache/dubbo/issues/6138
// 写入调用接口
String serviceName = inv.getAttachment(INTERFACE_KEY);
if (serviceName == null) {
serviceName = inv.getAttachment(PATH_KEY);
}
out.writeUTF(serviceName);
// 写入接口指定的版本
out.writeUTF(inv.getAttachment(VERSION_KEY));
// 写入方法名、参数类型
out.writeUTF(inv.getMethodName());
out.writeUTF(inv.getParameterTypesDesc());
Object[] args = inv.getArguments();
// 写入参数值
if (args != null) {
for (int i = 0; i < args.length; i++) {
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
}
out.writeAttachments(inv.getObjectAttachments());
}
解码
当服务端读取流进行解码时,会触发 ExchangeCodec#decode方法。
@Override
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
int readable = buffer.readableBytes();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
// 最多读取16个字节的内容, 即头部
buffer.readBytes(header);
return decode(channel, buffer, readable, header);
}
解码的时候,会事先处理头部,之前我们分析过Dubbo协议通过魔法数高低位来处理粘包等现象的,这里我们可以看到具体的处理方式。
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number.
// 处理首部不为魔法数的情况, 正常来说, 一个报文的0、1字节是魔法数高低位
// 但有时因为网络等问题, 会出现粘包等现象, 这时就要根据魔法数位置进行处理了
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
// 如果此时头部长度还是小于可读内容长度, 表示还可以进行数据读取
if (header.length < readable) {
// 重新分配header空间
header = Bytes.copyOf(header, readable);
// 将剩余数据读入到header中
buffer.readBytes(header, length, readable - length);
}
// 遍历header,找到一个header[i]为魔法数高位且header[i+1]为魔法数地位的位置
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
// 将buffer读索引重新指回 Dubbo报文开头处(Oxdabb)
buffer.readerIndex(buffer.readerIndex() - header.length + i);
// 将流起始处至下一个Dubbo 报文之间的数据放到header中
header = Bytes.copyOf(header, i);
break;
}
}
// 解析header数据
return super.decode(channel, buffer, readable, header);
}
// check length.
// 在正常场景中解析时, 如果小于16字节, 需要更多数据进入缓冲区
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length.
// 提取头部存储的报文长度, 偏移量为12字节
int len = Bytes.bytes2int(header, 12);
// When receiving response, how to exceed the length, then directly construct a response to the client.
// see more detail from https://github.com/apache/dubbo/issues/7021.
// 但数据过长时, 直接返回
Object obj = finishRespWhenOverPayload(channel, len, header);
if (null != obj) {
return obj;
}
// 并校验长度是 否超过限制
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
// 继续校验是否可以读取完整Dubbo报文,否则期待更多数据
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
// 解码消息体
return decodeBody(channel, is, header);
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is);
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
}
以Dubbo协议为例子,它的解码继承了这个类实现,但在解析消息体时,Dubbo 协议重写了 decodeBody方法。
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
// 获取第三个字节, 这里包含着请求响应、事件、序列化id等信息
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// get request id.
// 获取全局请求id
long id = Bytes.bytes2long(header, 4);
// 若为0, 表示响应类型为单向调用
if ((flag & FLAG_REQUEST) == 0) {
// decode response.
Response res = new Response(id);
/**
* 省略
*/
return res;
} else {
// decode request.
// 创建Request对象并设置全局请求id
Request req = new Request(id);
req.setVersion(Version.getProtocolVersion());
req.setTwoWay((flag & FLAG_TWOWAY) != 0);
if ((flag & FLAG_EVENT) != 0) {
req.setEvent(true);
}
try {
Object data;
// 如果是事件类型,例如心跳,报文是没有消息体的
if (req.isEvent()) {
byte[] eventPayload = CodecSupport.getPayload(is);
if (CodecSupport.isHeartBeat(eventPayload, proto)) {
// heart beat response data is always null;
data = null;
} else {
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), new ByteArrayInputStream(eventPayload), proto);
data = decodeEventData(channel, in, eventPayload);
}
} else {
DecodeableRpcInvocation inv;
// 根据请求参数判断是立刻解码还是延迟到线程池中去, 等待解码
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
inv = new DecodeableRpcInvocation(channel, req, is, proto);
inv.decode();
} else {
// 放到业务线程池中去
inv = new DecodeableRpcInvocation(channel, req,
new UnsafeByteArrayInputStream(readMessageData(is)), proto);
}
data = inv;
}
req.setData(data);
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode request failed: " + t.getMessage(), t);
}
// bad request
req.setBroken(true);
req.setData(t);
}
return req;
}
}
根据上述解码后返回类型,我们可以知道这是一个DecodeableRpcInvocation 类的实例,具体的解码流程其实就是读取出相关的参数类型、参数值、方法名等信息,并赋值到DecodeableRpcInvocation 中的各个属性中去。
public Object decode(Channel channel, InputStream input) throws IOException {
// 整个解码严格按照客户端写数据顺序来处理
// 获取序列化协议
ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
.deserialize(channel.getUrl(), input);
this.put(SERIALIZATION_ID_KEY, serializationType);
// 读取框架版本
String dubboVersion = in.readUTF();
request.setVersion(dubboVersion);
setAttachment(DUBBO_VERSION_KEY, dubboVersion);
// 读取调用接口及版本
String path = in.readUTF();
setAttachment(PATH_KEY, path);
String version = in.readUTF();
setAttachment(VERSION_KEY, version);
// 读取方法名称、参数类型
setMethodName(in.readUTF());
String desc = in.readUTF();
setParameterTypesDesc(desc);
try {
// 参数从JVM获取相关配置, 是否需要对序列化的内容做安全校验
if (ConfigurationUtils.getSystemConfiguration().getBoolean(SERIALIZATION_SECURITY_CHECK_KEY, false)) {
CodecSupport.checkSerialization(path, version, serializationType);
}
Object[] args = DubboCodec.EMPTY_OBJECT_ARRAY;
Class<?>[] pts = DubboCodec.EMPTY_CLASS_ARRAY;
if (desc.length() > 0) {
// if (RpcUtils.isGenericCall(path, getMethodName()) || RpcUtils.isEcho(path, getMethodName())) {
// pts = ReflectUtils.desc2classArray(desc);
// } else {
// 获取接口服务信息
ServiceRepository repository = ApplicationModel.getServiceRepository();
ServiceDescriptor serviceDescriptor = repository.lookupService(path);
if (serviceDescriptor != null) {
// 获取方法描述信息, 像参数类型、返回类型等
MethodDescriptor methodDescriptor = serviceDescriptor.getMethod(getMethodName(), desc);
if (methodDescriptor != null) {
pts = methodDescriptor.getParameterClasses();
this.setReturnTypes(methodDescriptor.getReturnTypes());
}
}
// 如果存储方法描述信息的pts 为空,
if (pts == DubboCodec.EMPTY_CLASS_ARRAY) {
// 如果不是泛化调用或者echo方式调用, 抛出异常: 找不到该服务
if (!RpcUtils.isGenericCall(desc, getMethodName()) && !RpcUtils.isEcho(desc, getMethodName())) {
throw new IllegalArgumentException("Service not found:" + path + ", " + getMethodName());
}
pts = ReflectUtils.desc2classArray(desc);
}
// }
args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
try {
// 遍历读取参数值
args[i] = in.readObject(pts[i]);
} catch (Exception e) {
if (log.isWarnEnabled()) {
log.warn("Decode argument failed: " + e.getMessage(), e);
}
}
}
}
setParameterTypes(pts);
// 这里读取对象类型的参数
Map<String, Object> map = in.readAttachments();
if (map != null && map.size() > 0) {
Map<String, Object> attachment = getObjectAttachments();
if (attachment == null) {
attachment = new HashMap<>();
}
attachment.putAll(map);
setObjectAttachments(attachment);
}
//decode argument ,may be callback
// 如果需要回调还需要创建务端创建 reference 代理实例
for (int i = 0; i < args.length; i++) {
args[i] = decodeInvocationArgument(channel, this, pts, i, args[i]);
}
setArguments(args);
String targetServiceName = buildKey((String) getAttachment(PATH_KEY),
getAttachment(GROUP_KEY),
getAttachment(VERSION_KEY));
setTargetServiceUniqueName(targetServiceName);
} catch (ClassNotFoundException e) {
throw new IOException(StringUtils.toString("Read invocation data failed.", e));
} finally {
if (in instanceof Cleanable) {
((Cleanable) in).cleanup();
}
}
return this;
}

















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









